本文主要是介绍DPT: Deformable Patch-based Transformer for Visual Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DPT: Deformable Patch-based Transformer for Visual Recognition
论文:https://arxiv.org/abs/2107.14467
代码:https://github.com/CASIA-IVA-Lab/DPT
目前,Transformer在计算机视觉方面取得了巨大的成功,但是如何在图像中更加有效的分割patch仍然是一个问题。现有的方法通常是将图片分成多个固定大小的patch,然后进行embedding。本文作者指出固定大小的patch有如下两个缺点:
- 图像中局部结构的破环,如下图(a)所示,固定尺寸(16x16)裁剪patch,很难获取和目标相关的局部目标的完整结构;
- 图像之间的语义信息的不一致。不同图像中的同一对象可能有不同的几何变化(比例、旋转等),固定尺寸裁剪patch可能会捕获不同图像中同一个对象的不一致的语义信息。这些固定尺寸的patches可能会破坏语义信息,导致性能下降。

为了解决这个问题,作者提出了一个可变形的patch(DePatch)模块,它以数据驱动的方式将图像自适应地分割成具有不同位置(position)和大小(scale)的patch,而不是使用固定patch分割方式。通过这个方法,就可以避免原来方法对语义信息的破坏,很好地保留patch中的语义信息。
预备知识: Vision Transformer
Vision transformer由三部分组成:
-
a patch embedding module
patch embedding module 将图片分成固定大小和位置的patches,然后分别将patch输入线性层,生成固定维度的一维向量。假设输入的图片或者特征图A ∈ R H × W × C \in R^{H \times W \times C} ∈RH×W×C,其中H=W,先前的工作是将A分成N个尺寸为 s × s s \times s s×s( s = i n t ( H / N ) s=int(H/\sqrt N) s=int(H/N))的patches,经过线性层后得到向量 z ( i ) 1 < = i < = N {z^{(i)}}_{1<=i<=N} z(i)1<=i<=N。
为了更好地解释patches分割过程,作者重新解释patches模块。每个 z ( i ) {z^{(i)}} z(i)被视为输入图像的一个矩形区域,其中心的点坐标为 ( x c t ( i ) , y c t ( i ) ) (x^{(i)}_{ct},y^{(i)}_{ct}) (xct(i),yct(i)),因为patch尺寸固定为s,所以其左上角坐标为: ( x c t ( i ) − s / 2 , y c t ( i ) − s / 2 ) (x^{(i)}_{ct}-s/2,y^{(i)}_{ct}-s/2) (xct(i)−s/2,yct(i)−s/2),右下角坐标为: ( x c t ( i ) + s / 2 , y c t ( i ) + s / 2 ) (x^{(i)}_{ct}+s/2,y^{(i)}_{ct}+s/2) (xct(i)+s/2,yct(i)+s/2),小patch中每个点又可以表示为 a ^ 1 < = j < = s × s ( i , j ) {\hat{a}^{(i,j)}_{1<=j<=s\times s}} a^1<=j<=s×s(i,j),随后根据公式(1)对patch进行线性处理。
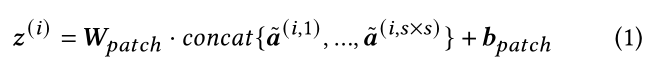
-
multi-head self-attention blocks
-
feed-forward multi-layer perceptrons (MLP)
DePatch Module
为了得到自适应的patches,作者在网络里添加两个可学习的参数location 和scale,其中location使用两个偏移量 ( δ x , δ y ) (\delta_x,\delta_y) (δx,δy)表示初始中心的的偏移量,scale预测patch的高 s h s_h sh,宽 s w s_w sw,根据上述预测的四个参数,我们就可以得到初始patch调整后的左上角和右下角坐标:
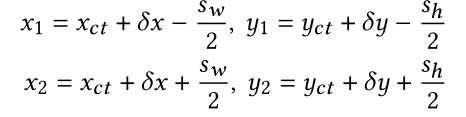
如下图所示,作者使用自适应的patches裁剪得到的区域,可以看到,目标物体的局部区域可以完整的被切分下来。

我们根据上述方法得到的patches尺寸各异,且坐标大多为浮点数,而网络需要固定维度,故作者这里在patch内随机选取 k × k k\times k k×k个点来表示该区域:
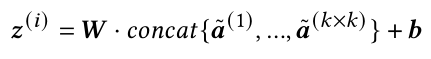
使用双线性插值来获取浮点数坐标下的特征值【关于双线性插值为何是公式(8),可以通过双线性插值的定义推导得到】:

Overall Architecture

作者基于PVT实现了DPT,PVT有四个stage,因此就有四个不同尺度的特征(上图左)。作者将PVT中stage2、stage3、stage4的patch embedding模块换成了DePatch,其他设置保持不变(上图右)。
Experiment
Image Classification
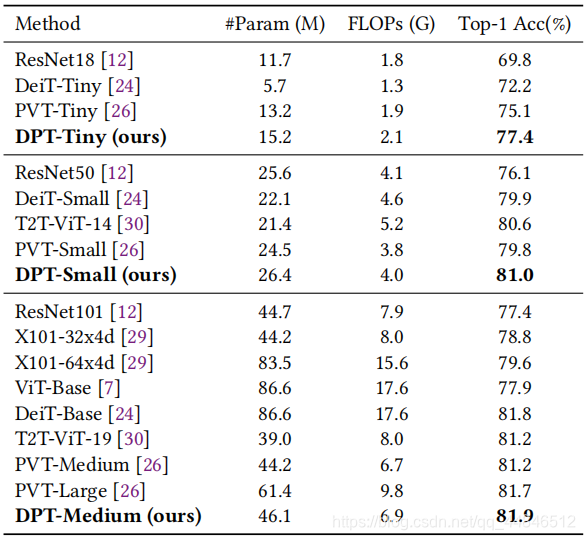
如上表所示,最小的DPT-Tiny获得了77.4%的top-1精度,比相应的baseline PVT模型高出2.3%。DPT-Medium实现了81.9%的top-1精度,甚至优于具有更多参数和计算量的模型,如PVT-Large和DeiT-Base。
Object Detection
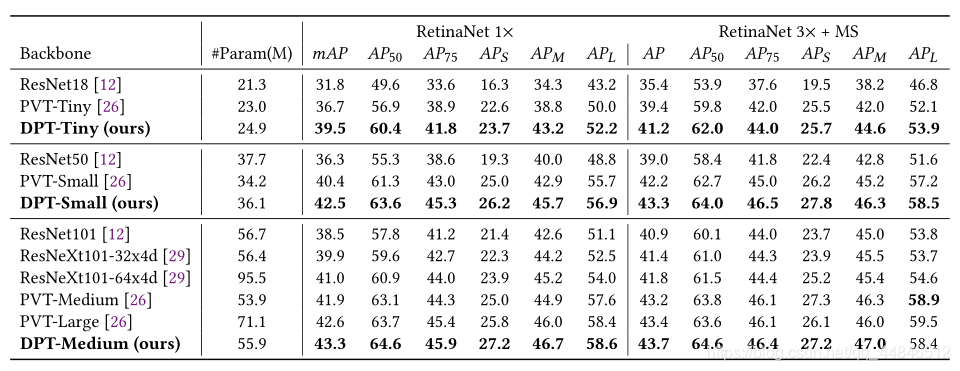
上表比较了DPT与PVT、ResNe(X)t的结果。在相似的计算量下,DPTSmall的性能比PVT-Small好2.1% mAP、比Resnet50好6.2% mAP。

Mask-RCNN上的结果相似。DPT-Small模型在1×schedule下,实现了43.1%的box mAP和39.9%的mask mAP,比PVT-Small高出2.7%和2.1%。
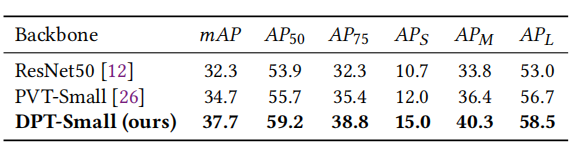
在DETR上,DPT-Small实现了37.7%的box mAP,比PVT-Small高3.0%,比ResNet50高5.4%。
参考:
https://mp.weixin.qq.com/s/v5jCTvoRo-OjhWfzL-LP9w
这篇关于DPT: Deformable Patch-based Transformer for Visual Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[VC] Visual Studio中读写权限冲突](/front/images/it_default.gif)


