本文主要是介绍容联AI实现「数据自动化打标」和「测试集自动提取」,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
尊敬的用户:
本周迎来容联AI Call产品又一次更新,本次更新重点丰富自学习平台的功能,旨在让运营更智能,提高运营整体工作效率,实现【数据自动打标】,自动将原始数据进行数据清洗、数据标注、数据分类,有效缩短了数据标注工期。同时,打破传统测试集数据手动拆分方式,实现【测试集数据自动提取】,数据提取更科学,评测结果更真实。
如下为V5.1.1本次更新内容:
升级说明
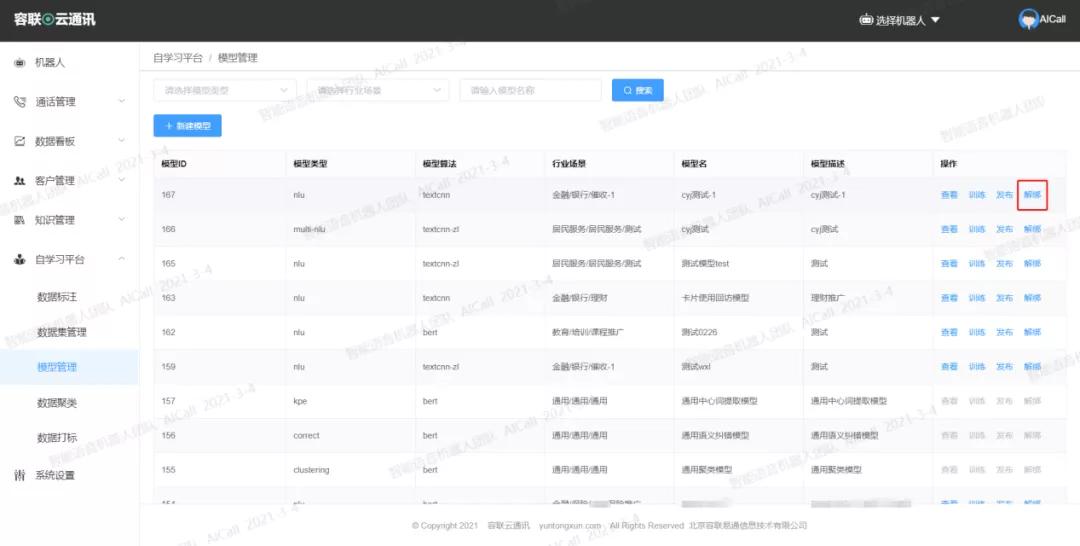
1、打通线上「数据集」一体化流程
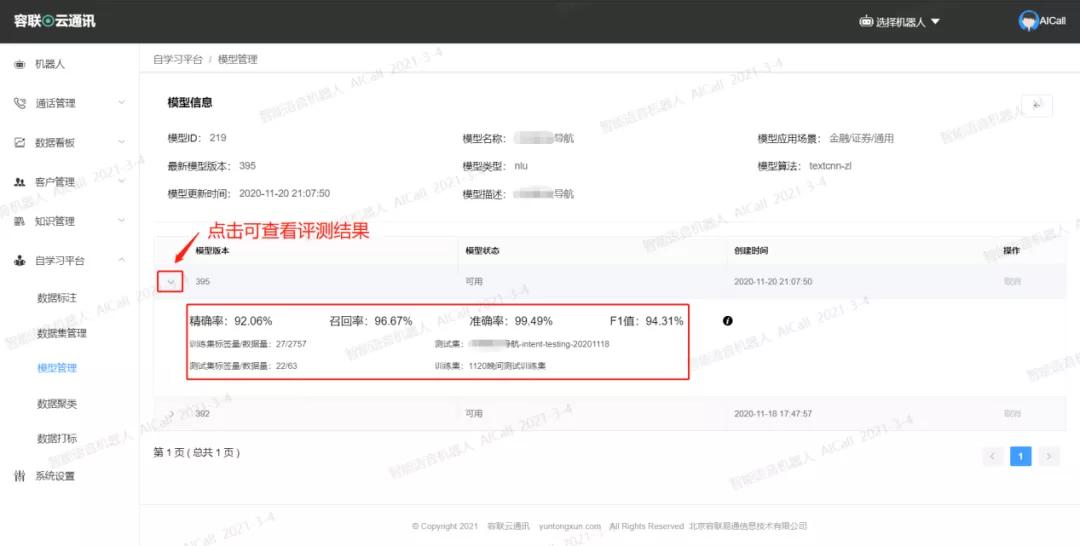
数据集上传、模型训练、模型评测、模型发布和解绑,都可以在自学习平台完成,打通线上数据集管理、模型训练、模型评测、模型发布一体化流程。
2、数据自动打标功能
针对海量数据,通过人工对数据进行标注,无法保证高效的完成数据清洗标注以及数据分类。本次自学习平台新增数据自动打标动能,仅需上传原始数据集文件,系统按照配置策略,自动将原始数据进行数据清洗、数据标注、数据分类,人工仅需完成简单的复检,即可将数据用于模型训练,有效缩短了数据标注工期。
这篇关于容联AI实现「数据自动化打标」和「测试集自动提取」的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







