本文主要是介绍PaperNote - UNICORN:基于Provenance的实时APT检测器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文标题:UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats
原文作者:Xueyuan Han∗, Thomas Pasquiery, Adam Batesz, James Mickens∗ and Margo Seltzerx
原文来源:NDSS 2020
原文链接:https://arxiv.org/pdf/2001.01525.pdf
文章目录
- 1 摘要
- 2 简介
- 3 背景
- 3.1 追踪系统调用的挑战
- 3.2 Whole-System Provenance
- 3.3 问题陈述和总结
- 4 威胁模型
- 5 设计
- 5.1 构造Graph直方图
- 5.1.1 Streaming Variant and Complexity
- 5.1.2 由于概念漂移而忽视直方图中的元素
- 5.1.3 入侵检测场景中的适用性
- 5.2 生成简略图(Graph Sketches)
- 5.3 学习进化模型
- 5.4 异常检测
- 6 实现
- 7 评估
- 7.1 UNICORN vs. StreamSpot
- 7.2 DARPA TC Datasets
- 7.3 Supply Chain攻击场景
- 7.4 参数分析
- 7.5 处理速度
- 7.6 CPU & 内存使用
- 7.7 讨论 & 局限性
- 8 相关研究
- 9 总结
1 摘要
本文提出的UNICORN是一种基于异常的APT检测器,可以有效利用数据Provenance进行分析。
从建模到检测,UNICORN均根据APT的独有特性(low-and-slow、0-Days)进行设计。通过广泛且快速的图分析,使用graph sketching技术,UNICORN可以在长时间运行的系统中分析Provenance Graph,从而识别未知、慢速攻击。其中的Provenance graph提供了丰富的上下文和历史信息。
2 简介
对于目前的研究情况,利用恶意软件特征来检测攻击行为的方法,攻击者一旦使用0-Day漏洞,防御者便无计可施;基于系统调用和系统时间的检测方法,由于数据过于密集,使得这些方法难以对长时间的行为模式进行建模。因此,data provenance是一种检测APT更合适的数据。
但是基于provenance的APT检测方法,其难处在于,Provenance Graph的分析是相当耗费计算资源的,这是因为APT的慢速攻击,图的大小也会越来越大。目前检测系统所面临的主要问题包括:
- 静态模型(rfr53)难以捕获长时间的系统行为
- 动态模型(rfr83)可能会被low-and-slow APT进行中毒攻击
- 在主存内进行计算的方法,应对长期运行的攻击表现不佳
基于此,本文提出了UNICORN,使用graph sketching来建立一个增量更新、固定大小的纵向图数据结构。这种纵向性质允许进行广泛的图探索,使得UNICORN可以追踪隐蔽的入侵行为。而固定大小和增量更新可以避免在内存中来表示provenance graph,因此UNICORN具有可扩展性,且计算和存储开销较低。UNICORN在训练过程中直接对系统的行为进行建模,但此后不会更新模型,从而防止攻击者中毒模型。
本文的主要贡献如下:
- 提供了专为APT攻击量身定制的、基于Provenance的异常检测系统。
- 介绍了一种sketch-based、time-weighted的provenance编码,从而可以简洁的概括长时间段内的provenance graph
- 通过模拟和真实的APT攻击来评估UNICORN
- 开源!
3 背景
3.1 追踪系统调用的挑战
- 捕获到的系统调用杂乱分散,因此需要将其关联成data provenance
- data provenance的不可信问题:有些系统调用捕获机制可能会被绕过;race condition;TOCTTOU、TOATTOU、TORTTOU
- 由于一些内核线程不使用系统调用,因此基于Syscall生成的Provenance是一些分散的图,而不是一张系统运行状况的完整图
3.2 Whole-System Provenance
Whole-System Provenance运行在操作系统层面,捕获所有的系统行为和它们之间的交互。通过捕获信息流和因果关系,即使攻击者通过操作内核对象来隐藏自己的行踪也无济于事。
本文使用的CamFlow,采用了Linux Security Modules(LSM)框架来确保高效可靠的信息流记录。LSM可以消除race condition。
3.3 问题陈述和总结
目前使用data provenance的一些研究,其局限性在于
- 预定义边匹配规则,对于0-Day漏洞利用攻击无效
- 分析小部分的provenance graph(而非whole-system)限制了视野
- 系统行为模型难以检测APT:静态模型无法捕获长期运行的系统的行为;动态模型容易遭受中毒攻击
- 基于内存的方法,在执行长期检测上有局限性
于是,UNICORN将系统范围内的APT入侵检测问题,形式化为一个whole-system provenance graph中的实时异常检测问题。首先建立一个已知良性的provenance graph模型,然后再任何时间点,都将从系统开始启动到目前为止所产生的整个的provenance graph与良性模型进行比较,如果偏离了该模型,那么就认为发生了攻击。(典型的abnormal-based)
对于APT检测来说,理想的provenance-based IDS必须满足:
-
连续、高效地分析provenance graph,同时充分利用整个系统provenance graph提供的丰富信息内容
-
在不假设攻击行为的情况下,应考虑系统执行的整个持续时间
-
仅学习正常的系统行为,而不学习攻击者的行为
4 威胁模型
UNICORN的任务是在任何阶段检测到APT攻击。我们假设在受到攻击之前,UNICORN在正常运行期间会完全观察主机系统,并且在此初始建模期间不会发生攻击。
数据收集框架的完整性是UNICORN正确性的核心,因此我们假定所使用的CamFlow中,LSM完整性是可信的
5 设计

- 以带标签的、基于流的provenance graph作为输入:该图由CamFlow生成,每条边是带属性的,整个图是单张、whole-system的偏序DAG
- 在运行时构建内存直方图
- 定期计算固定大小的简略图(graph sketch)
- 将简略图聚类为模型
5.1 构造Graph直方图
我们的目标是有效地比较provenance graph,同时容忍正常执行中的微小变化。 对于算法,我们有两个标准:
- 表示应考虑长期的因果关系
- 必须能够在实时流图数据上实现该算法,以便我们能够在入侵发生时阻止入侵(不仅仅是检测到入侵)。
本文基于同构的一维WL测试,采用了线性时间的、快速的Weisfeiler-Lehman(WL)subtree graph kernel算法。同构性的WL测试及其子树kernel变化,以其对多种图的判别能力而闻名,超越了许多最新的图学习算法(例如,图神经网络)。
对Weisfeiler-Lehman(WL)subtree graph kernel的使用取决于我们构建顶点直方图的能力,捕获围绕每个顶点的图结构。 我们根据增强顶点标签对顶点进行分类,标签描述了顶点的R-hop邻居。
通过迭代标签传播来构建这些增强顶点标签:
- 假设现在有一个完全静态的图,单个重标记步骤将 1)一个顶点的标签、2)所有传入该顶点的边的边的标签、3)所有这些边的源顶点的标签 作为输入;然后为这个顶点输出一个新的标签,表示所有输入标签的聚合。
- 我们对每个顶点重复此过程,然后重复整个过程R次以构造描述R-hop邻居的标签。
- 一旦为图中的每个顶点构造了增强的顶点标签,我们就创建一个直方图,其buckets对应于这些标签。
- 同构性的WL测试基于这些增强顶点标签,比较两个图,如果两个图在相似的标签集上具有相似的分布,则它们是相似的。
下面是该算法的形式化描述:

我们的目标是构建一个直方图,图中的每个元素对应一个唯一的顶点标签,用于捕获顶点的R-hop的in-coming邻居。
5.1.1 Streaming Variant and Complexity
上面的算法仅在新到达的顶点,或在那些邻居被新到达的边所影响的顶点上运行。

5.1.2 由于概念漂移而忽视直方图中的元素
系统行为经常会随着时间变化,会导致streaming provenance graph的基础统计属性发生变化,这种现象我们称之为概念漂移(concept drift)。
逐渐忘记机制:UNICORN通过对直方图元素计数使用指数权重衰减来逐渐消除过时的数据,从而解决了系统行为中的此类变化。 它分配的权重与数据的年龄成反比。
x t x_t xt即为Algorithm.1中23行的 l i ( v ) l_i(v) li(v),当t时刻新的数据条目 x t x_t xt出现时,采用下面的计数方式,其中 w t = e − λ ∆ t w_t = e^{-λ∆t} wt=e−λ∆t
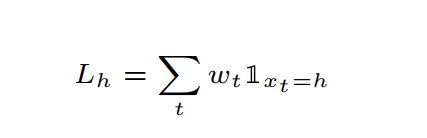
5.1.3 入侵检测场景中的适用性
上述“逐渐忘记”的方法,使得UNICORN可以着眼于当前的系统执行动态,而且那些与当先的object/activity有关系的事件不会被忘记。
5.2 生成简略图(Graph Sketches)
直方图是描述系统执行的简单向量空间图统计量。 但是,与传统的基于直方图的相似性分析不同,UNICORN会随着新边缘的到来不断更新直方图。
本文采用locality sensitive hashing,也称作similarity-preserving data sketching。UNICORN的部署采用了前人的研究成果HistoSketch.
5.3 学习进化模型
在给定graph sketch和相似性度量的情况下,聚类是检测离群点常用的数据挖掘手段。然而传统的聚类方法无法捕获系统不断发展的行为。UNICORN利用其流处理的能力,创建了进化模型,可以捕获系统正常行为的变化。更重要的是,模型的建立是在训练阶段完成的,而不是在部署阶段,因为部署阶段训练模型可能会遭受中毒攻击。
UNICORN在训练期间创建一系列按时间顺序排列的sketches,然后从一个单独的服务器上,使用K-medoids算法将这些sketch序列进行聚类,使用轮廓系数(silhouette coefficient)来确定最优的K值。每个簇表示系统执行的元状态(meta-states),如启动、初始化、稳定状态。然后UNICORN使用所有簇中sketches的时间顺序和每个簇的统计量(如直径、medoid),来生成系统进化的模型。

5.4 异常检测
UNICORN周期性的创建graph sketch,然后将其与在建模阶段学习到的所有子模型进行比对,sketch要么符合当前的状态,要么符合接下来的状态,否则便认为是异常的。因此,我们可能检测到两种类型的异常行为:不符合已经存在的簇;簇之间的转换时无效的。
6 实现
图处理算法使用C++部署GraphChi(vertex-centric 图处理框架);数据解析和建模部分使用Python。
7 评估
评估旨在验证以下问题:
- UNICORN能否在长期运行的系统中,准确地检测APT攻击的异常行为
- 针对APT的特性做出的设计决策有多重要?
- UNICORN的“逐渐忘记”策略是否能更好地理解系统行为?
- 相比于现存的使用静态快照进行聚类的方法,UNICORN的进化模型是否更有效?
- UNICORN是否足够快速,以执行实时监视和检测?
- 在系统执行过程中,UNICORN的内存和CPU使用如何?
数据集采用DARPA TC3的三个APT攻击数据集:Cadets、ClearScope、THEIA
7.1 UNICORN vs. StreamSpot
- SteamSpot数据集(public available)如下

StreamSpot包含6个场景的信息流图,其中5个时良性的。每个场景运行100次,每次生成一个graph。使用Linux的SystemTap日志系统。
我们使用这个数据集将UNICORN与StreamSpot对比,结果如下:


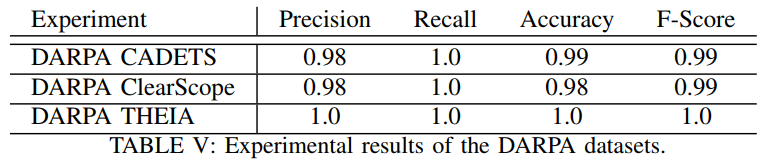
7.2 DARPA TC Datasets

参考文献中有关于者三个DARPA数据集的详细介绍。
本文将良性数据集的90%用于训练,10%用于测试;sketch size为200,R=3,检测结果如下:
7.3 Supply Chain攻击场景
前面的攻击场景无法确保异常行为和正常行为之间的相似性,因此本文在Continuous Integration(CI)平台上单独设计了两个APT攻击场景,并使用CamFlow(v0.5.0)来捕获whole-system provenance,其中每个场景运行了3天。

将125个良性图分成五组进行5折交叉验证,来为正常行为进行建模。下图是实验的设置和结果:


7.4 参数分析
下面通过调整图VII中的各个Baseline参数,来观察性能变化,其中各个参数的概念如下:
- Batch Size(BS):向GraphChi中一次提交的边的数量,它并不影响检测性能
- Hop Count(HC):这定义了用于表征每个顶点的邻域的大小; 它衡量了sketch中特征的表现力。 跳数越大,捕获的上下文信息越多,其中一些可能无关紧要。
- Sketch Size(SS):这是我们的固定大小直方图表示。SS越大,UNICORN可以包含有关演化图的更多信息,从而减少误差。但是,较大的SS最终会导致聚类中的维度灾难。
- Interval of Sketch Generation(SG):这是构造新sketch之间添加到图的边数。较小的SG会使得相邻的sketch之间较为相似,这会产生较高的false negative和较低的recall、accuracy(为何?不应该仅仅是性能开销增大吗?);较大的SG会产生粗粒度的变化,同样使得sketch之间相似度较高
- Weighted Decay Factor(DF):该参数确定了我们忘记过去的比例。

7.5 处理速度
实验环境为Amazon EC2 i3.2xlarge Linux machines with 8 vCPUs and 61GiB of memory.
下图表示了随时间推移处理的边缘总数,以量化UNICORN的处理速度。CamFlow线(蓝色)表示捕获系统生成的边总数,其他线与该线越近,说明运行时性能越好,这意味着UNICORN与捕获系统CamFlow“保持一致”

总体而言,上图表明UNICORN运行时对这些参数相对来说不敏感,这意味着UNICORN可以使用针对检测进行精度优化的参数,执行实时入侵检测。
7.6 CPU & 内存使用
我们针对工作量相对较大(即CI执行内核编译)的系统评估UNICORN的CPU使用率和内存开销。 实验表明,UNICORN具有较低的CPU使用率和内存开销.
下图展示了CPU开销:

下图展示了在两个不同参数下,相同工作负载的内存开销,基本配置中的其他参数不会显着影响内存消耗:

7.7 讨论 & 局限性
- 基于异常的检测
首先,本文假设在UNICORN进行正常行为建模期间,系统是安全的;其次,本文假设存在详尽的、有限的系统行为模式,而且即使在运行过程中没有检测到全部,也检测到了大多数,因此如果如果UNICORN检测到未知的正常行为模式,就会产生误报。
再者,攻击者想要模仿正常行为来绕过UNICORN的检测也是比较难的。
另外,UNICORN监视系统的起点是和两性模型建模的起点是一样的。但是如果因为系统发生了错误而恢复到之前的状态时,就会导致系统状态与模型不匹配。解决这种问题的方法是在系统创建快照的同时保存其模型状态,当系统还原快照时,UNICORN将还原相应的模型状态。(Concept Drift?)
另外,UNICORN还需要定期的重新训练模型。
- 图分析
需要对每个系统调整参数来提升检测性能。本文使用OpenTuner来自动调整。在本文的实验中,对于大多数数据集而言,都可以使用相同的参数
- 异质的主机活动
一些主机只会执行一些预先定义好的任务,UNICORN对这样环境下的主机检测效果较好。然而一些主机会有各种各样的异质性行为,UNICORN没有考虑这一类主机的安全性
8 相关研究
- 基于主机的动态入侵检测
起初,IDS仅仅依靠系统调用来进行建模,但随着攻击技术的提升,检测的准确度也随之下降。所以下一代的IDS在系统调用中加入和“状态”来提供上下文信息。
UNICORN的方法完全不同,基于图的表示和分析在检测APT攻击上具有良好的表现
- 基于图的异常检测
- 基于Provenance的安全分析
有ProTracer、CamQuery、Holmes、SLUETH、Poirot、SAQL
UNICORN不同于传统的基于规则的系统,它是一个不需要专家知识的异常检测系统。
9 总结
本文提出了UNICORN,这是一种实时异常检测系统,它利用整个whole-system data provenance来检测高级持续威胁。 UNICORN通过结构化的Provenance Graph,对系统行为进行建模,Provenance Graph揭示了系统对象之间的因果关系,并在其流到分析管道中时,对其进行有效地汇总来考虑整个图。 我们的评估表明,由此产生的演化模型,可以成功地检测出从不同审计系统捕获的各种APT攻击,包括真实的APT活动,且准确性高、误报率低。
这篇关于PaperNote - UNICORN:基于Provenance的实时APT检测器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![C#实战|大乐透选号器[6]:实现实时显示已选择的红蓝球数量](https://i-blog.csdnimg.cn/direct/cda2638386c64e8d80479ab11fcb14a9.png)







