本文主要是介绍【人工智能】机器学习、深度学习、强化学习相关的核心技术,以及这些技术在促进人工智能发展、优化经济效益、解决社会问题等方面所扮演的角色、意义和作用,并探讨未来可能的发展方向,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.简介
- 2.人工智能基础知识
- 一、机器学习简介
- 机器学习是什么
- 机器学习的显著特征
- 机器学习的核心原理
- 二、人工智能的核心概念与特点
- 三、人工智能的研究方向
- (一)机器学习方向
- (1)监督学习
- (a)监督回归
- (I)线性回归
- (II)逻辑回归
- (III)岭回归
- (IV)套索回归
- (b)监督分类
- (I)支持向量机
- (II)k近邻
- (III)朴素贝叶斯
- (IV)最大熵模型
- (V)最大风险模型
- (c)半监督学习
- (I)有监督的核学习
- (II)深度无监督学习
- (III)EM算法
- (2)非监督学习
- (I)聚类
- (II)特征降维
- (III)关联规则挖掘
- (IV)异常检测
- (3)半监督与无监督综合学习
- (I)混合模型
- (II)深度学习
- 四、人工智能未来可能的发展方向
- 五、AI agent 与 通用人工智能
- 概念
- 挑战
作者:禅与计算机程序设计艺术
1.简介
2019年是机器学习、深度学习、强化学习领域的鼎盛年份,各类应用的火爆让人们发现了这个领域的巨大潜力,但同时也带来了新的挑战——数据量的急剧增长,复杂性的增加,训练效率的降低,如何提高效率更是困难重重。这是一个需要长期努力的难题。
本文向读者阐述机器学习、深度学习、强化学习相关的核心技术,以及这些技术在促进人工智能发展、优化经济效益、解决社会问题等方面所扮演的角色、意义和作用,并探讨未来可能的发展方向。
2.人工智能基础知识
一、机器学习简介
机器学习是什么
机器学习(Machine Learning)是人工智能的核心分支,其目的是开发计算机程序,使得电脑具备“学习”能力,从而可以对未知的数据进行预测或决策。与其他工程技术相比,机器学习具有以下几个显著特征:
① 大数据量与多样性:机器学习方法经过长时间积累,已经能够处理海量的数据,从各种来源、形式、种类的数据中提取知识和模式。这使得机器学习技术成为了处理复杂大数据时代的重要工具。
② 模型可解释性:机器学习模型不仅会对输入数据的结构进行学习,还可以通过分析输出结果和相关变量之间的关系,来评估模型的有效性和鲁棒性。通过这种方式,机器学习模型往往可以帮助科学家和工程师理解数据并提升产品效果。
③ 自动化:由于机器学习模型的训练过程需要大量的人工交互和反复试错,因此,它的开发过程被自动化程度越来越高。越来越多的商业公司,如谷歌、亚马逊、微软、IBM等,都在研究如何将机器学习技术应用到其产品的自动化上。
④ 泛化能力:机器学习模型可以运用新数据进行更新和迭代,因此,它可以在不同的环境和场景下进行预测。这对于解决实际问题来说至关重要。例如,一个识别图像中的人脸的模型,就可以用于检测其他视觉对象,如汽车、飞机、卡车等。
机器学习的显著特征
机器学习(Machine Learning)是人工智能的核心分支,旨在开发计算机程序,使计算机具备从数据中学习和自动改进的能力,以便对未知的数据进行预测或决策。机器学习具有以下几个显著特征。
-
大数据量与多样性:
机器学习方法经过长时间的积累和发展,已经能够处理海量的数据,包括来自各种来源、形式和种类的数据。这些数据可以是结构化的数据(如表格数据),也可以是非结构化的数据(如文本、图像、音频等)。机器学习技术使得我们能够从这些数据中提取知识和模式,以便进行预测、分类、聚类等任务。在处理复杂大数据时代,机器学习成为了重要的工具。 -
模型可解释性:
机器学习模型不仅可以对输入数据的结构进行学习,还可以通过分析输出结果和相关变量之间的关系,来评估模型的有效性和鲁棒性。这种模型可解释性使得科学家和工程师可以更好地理解数据,并对模型进行解释和调整,以提升产品效果。例如,对于图像分类任务,机器学习模型可以告诉我们哪些特征对于分类是重要的,从而帮助我们理解模型的决策过程。 -
自动化:
机器学习模型的训练过程通常需要大量的人工交互和反复试错。然而,随着技术的发展,越来越多的工作正在自动化。例如,自动化机器学习(AutoML)的研究旨在开发能够自动选择和调整模型架构、优化超参数、处理特征工程等任务的算法和工具。这样的自动化技术可以降低机器学习的门槛,使更多的人能够应用机器学习技术,而不需要深入了解其底层原理。 -
泛化能力:
机器学习模型具有良好的泛化能力,即它们可以在未见过的数据上进行预测和决策。这是机器学习的一个核心目标,因为我们通常希望通过模型对现实世界中的新数据进行预测和推理。机器学习模型通过从训练数据中学习数据的模式和规律,可以对新数据进行泛化。这使得机器学习在各种实际问题中得到了广泛应用。例如,训练一个图像分类模型可以识别人脸,但该模型也可以用于检测其他视觉对象,如汽车、飞机、卡车等。
机器学习的核心原理
机器学习的核心原理包括以下几个方面:
-
数据表示和特征提取:
在机器学习中,数据的表示和特征提取是非常重要的步骤。数据表示是指将原始数据转换为机器学习算法可以处理的形式,如向量或矩阵。特征提取则是从数据中提取出具有代表性和区分性的特征,以便模型能够更好地学习和进行预测。好的特征表示和提取可以显著影响机器学习模型的性能。 -
模型选择和训练:
机器学习模型是根据给定的数据和任务选择的。常见的机器学习模型包括线性回归(Linear Regression)、决策树(Decision Tree)、支持向量机(Support Vector Machines)、神经网络(Neural Networks)等。模型的选择取决于数据的特征和任务的要求。模型的训练是指通过将模型应用于训练数据并根据实际输出进行调整的过程。训练的目标是使模型能够对新的未见数据进行准确预测。 -
损失函数和优化算法:
损失函数用于衡量模型预测结果与实际结果之间的差异。优化算法被用于最小化损失函数,以调整模型的参数和权重,使模型能够更好地拟合训练数据。常见的优化算法包括梯度下降(Gradient Descent)和其变种,如随机梯度下降(Stochastic Gradient Descent)和批量梯度下降(Batch Gradient Descent)。
下面是梯度下降算法和其变种的数学公式:
- 梯度下降(Gradient Descent):
梯度下降算法通过迭代更新模型的参数,以最小化损失函数。对于每个参数 θi,更新公式如下:
θ i = θ i − α ∂ ∂ θ i J ( θ ) \theta_i = \theta_i - \alpha \frac{\partial}{\partial \theta_i} J(\theta) θi=θi−α∂θi∂J(θ)
其中,α是学习率(learning rate),决定了每次迭代更新的步长。J(θ)是损失函数。
- 随机梯度下降(Stochastic Gradient Descent,SGD):
随机梯度下降是梯度下降的一种变种,它在每次迭代中只使用一个样本来更新参数。对于每个训练样本 (x, y),更新公式如下:
θ i = θ i − α ∂ ∂ θ i J ( θ ; x , y ) \theta_i = \theta_i - \alpha \frac{\partial}{\partial \theta_i} J(\theta; x, y) θi=θi−α∂θi∂J(θ;x,y)
其中,J(θ; x, y)是针对单个样本的损失函数。
- 批量梯度下降(Batch Gradient Descent):
批量梯度下降是梯度下降的另一种变种,它在每次迭代中使用整个训练集来更新参数。对于训练集中的所有样本 (x, y),更新公式如下:
θ i = θ i − α 1 m ∑ j = 1 m ∂ ∂ θ i J ( θ ; x ( j ) , y ( j ) ) \theta_i = \theta_i - \alpha \frac{1}{m} \sum_{j=1}^{m} \frac{\partial}{\partial \theta_i} J(\theta; x^{(j)}, y^{(j)}) θi=θi−αm1j=1∑m∂θi∂J(θ;x(j),y(j))
其中,m是训练集的样本数量。
这些公式描述了梯度下降算法和其变种中参数的更新方式。通过迭代更新参数,并根据损失函数的梯度方向进行调整,这些优化算法可以逐步优化模型的参数和权重,以减小预测结果与实际结果之间的差异。
-
模型评估和调优:
在训练完成后,需要对模型进行评估和调优。评估模型的常用指标包括准确率、精确率、召回率、F1分数等。如果模型的性能不满足要求,可以进行调优,包括调整模型的超参数、增加训练数据、改进特征表示等。 -
防止过拟合和泛化能力:
过拟合是指模型在训练数据上表现很好,但在新数据上表现较差的现象。为了防止过拟合,可以采用一些技术,如正则化、交叉验证、早停等。泛化能力是指模型对新数据的适应能力,通过合理的模型选择、特征提取和调优,可以提高模型的泛化能力。
总结起来,机器学习是人工智能的核心分支,具有大数据量与多样性、模型可解释性、自动化和泛化能力等特征。核心原理包括数据表示和特征提取、模型选择和训练、损失函数和优化算法、模型评估和调优,以及防止过拟合和提高泛化能力。机器学习的发展和应用为我们解决复杂的大数据问题提供了强大的工具和方法。
二、人工智能的核心概念与特点
人工智能(Artificial Intelligence,AI)是指由机器所表现出的智能,涵盖计算机和人类的智能功能,包括认知、推理、行为等。人工智能有两种主要的研究方向,即机器学习与深度学习。
① 机器学习(Machine Learning):机器学习的目标是通过与经验数据进行不断学习,从数据中找出规律、改善性能的方式,来模仿人类的学习行为,从而让机器具备学习能力。机器学习方法经过长时间积累,已经能够处理海量的数据,从各种来源、形式、种类的数据中提取知识和模式。机器学习技术如支持向量机、K-近邻、朴素贝叶斯等,都是机器学习的一个重要分类。
② 深度学习(Deep Learning):深度学习是机器学习的一种子集,旨在处理多层次抽象的神经网络结构,通过对数据的高级表示学习系统的内部表示形式,发现数据的内在结构并建模学习其特性。深度学习技术如卷积神经网络、循环神经网络、递归神经网络、梯度下降法等,都是深度学习的一个重要分类。
③ 强化学习(Reinforcement Learning):强化学习(RL)是机器学习的一种子集,旨在基于马尔可夫决策过程,采用动态策略的形式,在一个环境中学习最优的动作序列,以最大化奖励信号。强化学习技术如Q-学习、策略梯度法、蒙特卡洛树搜索等,都是强化学习的一个重要分类。
④ 概念学习(Concept Learning):概念学习的目标是在给定输入的情况下,自动地学习其背后的概念。概念学习可以用来表示、分类、检索、压缩、描述数据、生成句子或图形等,有助于计算机理解和利用数据。
⑤ 对话系统(Dialogue System):对话系统是一种基于机器学习的聊天机器人技术,通过对话的方式与用户进行交流。通过自动构造匹配的回答、分析对话历史记录、学习用户的兴趣爱好、提升交互质量等,对话系统可以减少人工参与造成的错误率和疲劳,提升人机沟通的效率。
⑥ 认知神经网络(Cognitive Neural Network):认知神经网络(CNN)是人工智能的关键技术之一,可以理解输入的图像、文本、语音等信息,并通过分析其内容实现智能的决策。CNN的主要思想是建立一系列的抽象层,然后利用神经网络来对抽象层进行学习、处理和更新,最终达到智能的目的。
⑦ 感知器网络(Perceptron Networks):感知器网络是一种简单、轻量级的机器学习算法,是构建神经网络的基础。它利用线性激活函数和梯度下降法进行训练,属于线性分类器。感知器网络的输入、权值和偏置组成一个感知器,当输入的特征与权值的乘积大于偏置时,感知器激活;否则,保持静止不动。
⑧ 遗传算法(Genetic Algorithms):遗传算法(GA)是一种进化算法,它通过模拟自然界中生物的进化过程,模拟出适应度较高的个体,保留个体的基因并变异产生后代。遗传算法的主要特点是自然选择,能够在高维空间搜索全局最优解。
三、人工智能的研究方向
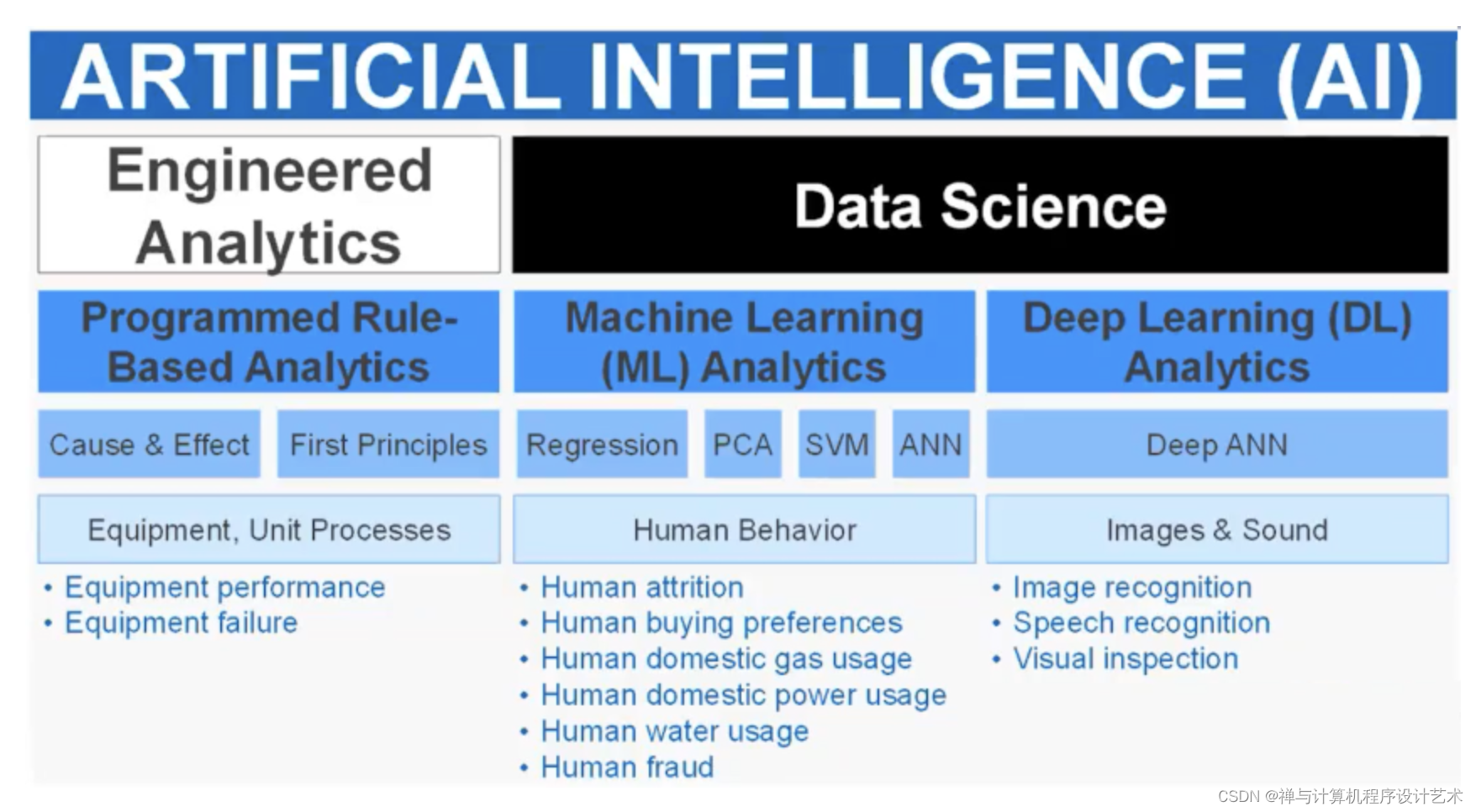
(一)机器学习方向
(1)监督学习
监督学习(Supervised Learning)是机器学习的一种类型,它关注的是如何给模型提供输入-输出的训练样本,利用这些样本学习得到一个模型,该模型能够对未知数据进行预测或决策。监督学习可以分为监督回归(Regression)、监督分类(Classification)、半监督学习(Semi-Supervised Learning)和强化学习四种类型。
(a)监督回归
监督回归(Regression)是监督学习的一种任务,它假设模型输入与输出之间存在线性关系,并尝试寻找一条曲线或曲面,使得模型能够准确预测输出值。监督回归模型的训练通常依赖于训练数据中的标签(Ground Truth),也就是真实值,以最小化预测误差(Prediction Error)。许多监督回归算法可以归纳为如下几类:
(I)线性回归
线性回归(Linear Regression)是一种简单的监督回归算法,它假设输入变量与输出变量之间是线性关系,即输入变量x的线性组合等于输出变量y。线性回归模型可以表示为:
其中,θ0和θ1分别代表截距项和斜率项。线性回归模型能够很好的捕获直线性关系,但无法捕获非线性关系。
(II)逻辑回归
逻辑回归(Logistic Regression)是一种广义上的监督回归算法,它针对分类问题设计的,可以用于解决两类或者多类别问题。逻辑回归模型的目标是找到一个映射函数f(x),该函数能够将输入变量x转换为连续分布值(通常是0~1之间的一个值)。逻辑回归模型也可以看作线性回归模型加了一个sigmoid函数,其作用是把预测值映射到[0,1]区间。逻辑回归模型可以表示为:
其中,θ为模型参数,h(x)为映射函数。
(III)岭回归
岭回归(Ridge Regression)是一种扩展线性回归模型的监督回归算法,其目标是最小化最小平方加上正则项。正则项刻画了模型的复杂度,控制模型的发生过拟合现象。岭回归模型可以表示为:
其中,λ是正则参数。λ的值越小,表示模型越接近于普通最小二乘法;λ的值越大,表示模型越趋于零均值回归。
(IV)套索回归
套索回归(Lasso Regression)也是一种扩展线性回归模型的监督回归算法,其目标是最小化最小平方加上正则项。套索回归模型引入了一个新的罚项,使得某些系数为零。套索回归模型可以表示为:
其中,α为正则参数。α值越小,表示模型越趋于稀疏;α值越大,表示模型越趋于正常最小二乘法。
(b)监督分类
监督分类(Supervised Classification)是监督学习的另一种任务,它希望模型能够正确分类输入数据。监督分类模型可以分为有限和无限两个类型。有限的监督分类模型要求每个样本都有明确的输出值(类别),如二分类模型,通常是输入数据是否属于两个类别之一。无限的监督分类模型则不需要有明确的输出值,如聚类、异常检测、摘要、翻译、问答回答等。监督分类模型的训练通常依赖于训练数据中的标签,以找到一种能够使样本聚类、分离或分类的方法。
(I)支持向量机
支持向量机(Support Vector Machine, SVM)是监督分类的一种有监督学习算法,它能够学习到输入变量和输出变量之间间隔最大且最靠近分割面的边界,使得输入数据能被正确分类。SVM的基本想法是求解能将正负实例完全分开的超平面。SVM可以表示为:
其中,ω和b为超平面的法向量和截距,ε为松弛变量。
(II)k近邻
k近邻(k-Nearest Neighbors, KNN)是监督分类的一种无监督学习算法,它基于实例与实例之间的距离度量,将实例分为多个类别,根据k个最近邻居的多数类别决定实例的类别。KNN可以认为是一种非参数模型,不需要对输入进行显式的假设。KNN可以表示为:
其中,N为训练集的大小,k为邻居个数,ψ为距离函数,x为输入实例,x_i为第i个训练实例,y_i为第i个训练实例对应的输出值,D为训练数据集。
(III)朴素贝叶斯
朴素贝叶斯(Naive Bayes, NB)是监督分类的一种有限的无监督学习算法,它假定特征之间相互独立。NB的基本想法是根据特征条件概率的假设,建立后验概率模型,然后基于此模型进行分类。NB可以表示为:
其中,P(y)为先验概率,P(x_i\mid y)为条件概率,通过MLE或者MAP方法求解参数。
(IV)最大熵模型
最大熵模型(Maximum Entropy Model, ME)是监督分类的一种有限的无监督学习算法,其基本想法是最大化训练数据在模型下的无序度。ME可以表示为:
其中,θ为模型参数,λ为正则化参数,C为类别集合,w_{ic}为类别ci的第i个实例的权重,T(x_{ij})为标记函数,A(θ)为惩罚项。
(V)最大风险模型
最大风险模型(Maximum Risk Model, MR)是监督分类的一种有限的无监督学习算法,其基本想法是最大化训练数据的分类损失函数。MR可以表示为:
其中,θ为模型参数,β为健壮风险,N为训练数据集大小。
(c)半监督学习
半监督学习(Semi-Supervised Learning)是监督学习的一种任务,它尝试使用部分标签来训练模型。半监督学习模型可以分为以下三种类型:
(I)有监督的核学习
有监督的核学习(Supervised Kernel Learning)是半监督学习的一种任务,它基于核技巧,利用部分标注数据和未标注数据结合学习模型。有监督的核学习的基本想法是基于核函数将未标注数据映射到低维空间,然后利用标注数据来估计核矩阵。有监督的核学习可以表示为:
其中,φ为基函数,k(·,·)为核函数。
(II)深度无监督学习
深度无监督学习(Unsupervised Deep Learning)是半监督学习的一种任务,它使用无监督方法来学习输入数据的特征,并利用这些特征进行聚类、异常检测等任务。深度无监督学习的基本想法是使用深度学习模型来学习数据的特征表示,然后利用这些表示进行聚类、异常检测等任务。深度无监督学习可以表示为:
其中,θ为模型参数,φ为特征映射函数,γ为特征投影函数。
(III)EM算法
EM算法(Expectation-Maximization algorithm, EM)是半监督学习的一种方法,其基本想法是迭代地优化模型参数,并保证局部收敛性。EM算法可以表示为:
其中,θ为模型参数,φ为特征映射函数,J为迭代次数,X为输入数据,Y为输入数据对应的标签,Z为隐变量。
(2)非监督学习
非监督学习(Unsupervised Learning)是机器学习的另一种类型,它关注于如何对数据进行聚类、结构发现等无监督的学习任务。非监督学习算法可以分为以下几类:
(I)聚类
聚类(Clustering)是非监督学习的一种任务,其目标是将一组数据划分为多个簇,使得同一簇中的数据具有相似的特征。聚类算法可以分为凝聚层次聚类、层次聚类、基于密度的聚类等。凝聚层次聚类(Hierarchical Clustering)是一种迭代的方法,每次合并两个相邻的簇,直至不能继续合并为止。层次聚类(Agglomerative Clustering)是一种典型的树形拓扑划分方法,每次将两个最相似的簇合并为一个簇,直至所有数据点归属于单个簇。基于密度的聚类(Density-Based Clustering)是一种基于密度的方法,首先确定邻域范围,然后找到区域内密度最大的样本作为核心对象。
(II)特征降维
特征降维(Feature Dimensionality Reduction)是非监督学习的一种任务,其目标是降低高维数据到低维数据的表示。特征降维算法可以分为主成分分析(PCA)、线性判别分析(LDA)、核PCA等。主成分分析(Principal Component Analysis)是一种统计方法,它将高维数据投影到低维空间,使得各个维度的方差占比达到最大,即保留原始数据的最大信息。线性判别分析(Linear Discriminant Analysis)是一种统计方法,它基于贝叶斯判别分析,假设数据的协方差矩阵由类内协方差矩阵和类间协方差矩阵构成。核PCA(Kernel Principal Components Analysis)是主成分分析的一种形式,它首先将原始数据映射到一个高维特征空间,再利用核函数将数据投影到低维空间。
(III)关联规则挖掘
关联规则挖掘(Association Rule Mining)是非监督学习的一种任务,其目标是发现数据中普遍存在的联系和模式。关联规则挖掘算法可以分为频繁项集挖掘、关联规则生成、关联规则过滤三个步骤。频繁项集挖掘(Frequent Item Set Mining)是一种基于支持度的算法,它利用数据库中的交易数据和规则集来发现频繁出现的事务集。关联规则生成(Association Rule Generation)是一种基于频繁项集的算法,它生成符合规则的候选集。关联规则过滤(Association Rule Filtering)是一种基于规则的算法,它利用过滤规则集合筛除不符合规则的候选集。
(IV)异常检测
异常检测(Anomaly Detection)是非监督学习的一种任务,其目标是识别异常数据,如网络攻击、欺诈行为等。异常检测算法可以分为基于密度的异常检测、基于模式的异常检测等。基于密度的异常检测(Density-based Anomaly Detection)是一种基于密度的方法,它通过密度分布函数来判断数据点是否异常。基于模式的异常检测(Pattern-based Anomaly Detection)是一种基于模式的方法,它通过模式检测算法来发现异常模式。
(3)半监督与无监督综合学习
半监督与无监督综合学习(Hybrid Unsupervised and Supervised Learning)是机器学习的第三种类型,其目标是结合有监督和无监督学习的能力,解决一些更复杂的问题。半监督与无监督综合学习算法可以分为以下两种类型:
(I)混合模型
混合模型(Mixture Models)是半监督与无监督综合学习的一种方法,其目标是学习多个数据分布的混合模型,并且能够产生高质量的样本。混合模型算法可以分为基于EM的混合模型、混合高斯模型、隶属共轭梯度模型等。基于EM的混合模型(EM-based Mixture Models)是一种迭代的无监督学习算法,它通过极大似然估计估计混合模型的参数。混合高斯模型(Gaussian Mixture Model, GMM)是一种有监督学习算法,它假设输入数据服从多元高斯分布,并且可以使用EM算法来估计参数。隶属共轭梯度模型(BIC-based Mixture Models)是一种有监督学习算法,它借鉴了负责任的分层模型,通过对每个子模型选择合适的数量,来估计模型参数。
(II)深度学习
深度学习(Deep Learning)是半监督与无监督综合学习的一种方法,其目标是学习高度非线性和层次化特征表示。深度学习算法可以分为卷积神经网络(Convolutional Neural Networks, CNNs)、循环神经网络(Recurrent Neural Networks, RNNs)、深度置信网络(Deep Belief Networks, DBNs)等。卷积神经网络(CNNs)是一种深度学习模型,其目标是学习二维或三维图像的局部结构。循环神经网络(RNNs)是一种深度学习模型,其目标是学习序列数据。深度置信网络(DBNs)是一种深度学习模型,其目标是学习可变特征的表示。
四、人工智能未来可能的发展方向

人工智能(Artificial Intelligence,简称AI)是当今科技领域的热门话题之一,其在各个领域展现出巨大的潜力和影响力。随着科技的不断进步和人们对AI的需求不断增加,人工智能的未来发展方向受到了广泛关注。本节将从以下角度探讨人工智能未来可能的发展方向:强化学习、深度学习、自然语言处理、机器人技术、人机交互和伦理问题等。
-
强化学习的发展
强化学习是一种通过试错学习的机器学习方法,近年来取得了显著的进展。未来,强化学习有望在更广泛的领域发挥作用,如自动驾驶、智能游戏、金融交易等。同时,随着硬件技术的不断提升,强化学习算法的训练速度和效果也将得到进一步改善。 -
深度学习的进步
深度学习是一种基于神经网络的机器学习方法,已经在图像识别、语音识别等领域取得了显著成果。未来,深度学习有望进一步扩展到更多领域,如自然语言处理、医疗诊断等。此外,对于深度学习算法的优化和加速也是未来的研究重点,以提高其在大规模数据和复杂任务上的效果和效率。 -
自然语言处理的突破
自然语言处理(Natural Language Processing,简称NLP)是指使计算机能够理解和处理人类语言的技术。未来,NLP有望在智能助手、机器翻译、智能客服等领域取得更大突破。其中,预训练模型和迁移学习等技术将进一步提高NLP的性能和效果。 -
机器人技术的发展
机器人技术是人工智能的重要应用领域之一,未来将迎来更广阔的发展空间。机器人将在工业、医疗、家庭等领域发挥更重要的作用。例如,在工业生产中,智能机器人能够完成更复杂的任务,提高生产效率和质量。在医疗领域,机器人可以辅助医生进行手术操作和康复治疗。在家庭领域,智能机器人将成为人们的家庭助理,提供各种便利服务。 -
人机交互的改进
人机交互是指人类与计算机或机器人之间的信息交流和互动方式。未来,人机交互将更加智能化和自然化。例如,语音识别和语音控制技术的发展使得人们可以通过语音与计算机进行交互。虚拟现实(Virtual Reality,简称VR)和增强现实(Augmented Reality,简称AR)技术的进步将改变人们与计算机和虚拟世界的交互方式。 -
伦理问题的关注
随着人工智能的不断发展和应用,一系列伦理问题也日益凸显出来。例如,隐私保护、数据安全、算法偏见、工作岗位的自动化等。未来,人工智能的发展需要更加注重伦理问题的考量,并制定相关法律和规范,确保人工智能的发展与人类的利益相符。
结论:
人工智能作为一项前沿技术,其未来的发展方向充满了无限的可能性。强化学习、深度学习、自然语言处理、机器人技术、人机交互等领域都将取得巨大的进步和突破。同时,人工智能的发展也需要伦理问题得到足够的关注和解决,以确保其发展对人类的福祉有积极的影响。
五、AI agent 与 通用人工智能
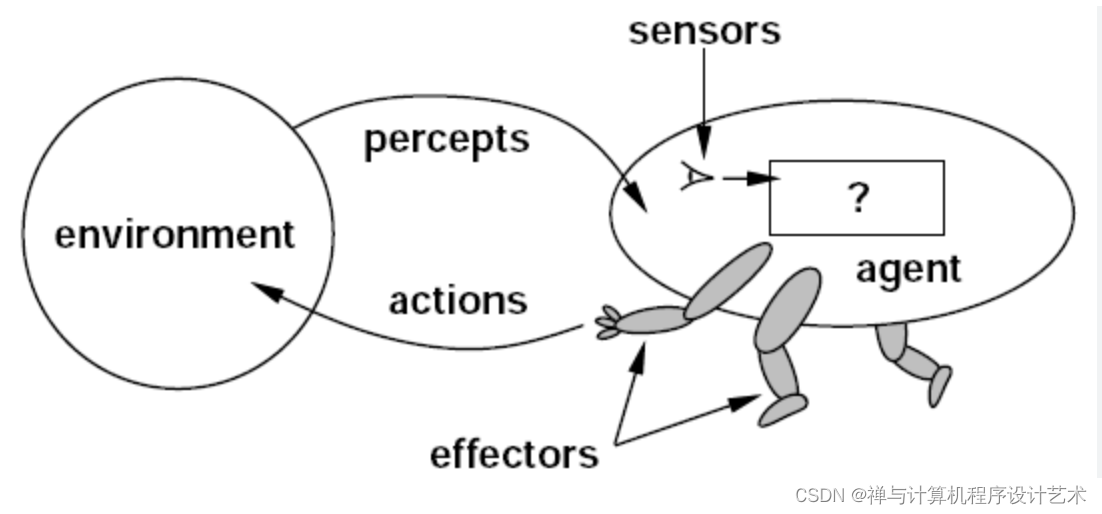
概念
AI agent(人工智能代理)和通用人工智能是人工智能领域的两个重要概念,它们在功能和应用方面有所不同。
AI agent(人工智能代理)是指能够感知环境、学习和自主决策的智能实体。它可以是一个软件程序、一个机器人或者一个虚拟实体。AI agent 通过感知环境中的数据和信息,利用算法和模型进行学习和推理,并根据目标和任务制定决策和行动。AI agent 的设计和应用可以针对特定领域或任务进行优化,例如自动驾驶车辆、智能助手、推荐系统等。AI agent 通常具有较窄的功能范围,专注于解决特定问题或完成特定任务。
通用人工智能是指具备与人类智能相媲美甚至超过人类智能的人工智能系统。通用人工智能的目标是使机器能够像人类一样具有广泛的智能能力,包括理解语言、学习新知识、推理、创造、解决问题等。与AI agent 不同,通用人工智能不仅可以在特定领域或任务中表现出色,而且具备跨领域、全面学习和适应的能力。通用人工智能的实现是人工智能领域的终极目标,但目前仍然是一个具有挑战性的问题,需要解决诸多技术、理论和伦理问题。
AI agent 和通用人工智能之间存在一定的联系和关系。通用人工智能可以看作是AI agent 的最高级别形式,即一个能够在各种任务和领域中表现出智能的综合性代理。在实现通用人工智能之前,研究和开发AI agent 在特定领域中的能力和性能对于推动人工智能的发展和应用具有重要意义。通过不断改进和扩展AI agent 的功能和能力,我们可以逐步迈向通用人工智能的实现。
然而,实现通用人工智能仍然是一个具有挑战性的任务。目前,人工智能领域的研究和发展更多地聚焦于特定领域的问题和应用,如图像识别、自然语言处理等。要实现通用人工智能,需要解决诸多技术挑战,包括推理能力、常识理解、自主学习和灵活性等方面的问题。此外,伦理、安全和社会影响等问题也需要得到充分考虑和解决。
总之,AI agent 和通用人工智能是人工智能领域的两个重要概念。AI agent 是一种能够感知环境、学习和自主决策的智能代理,通常用于解决特定领域或任务。而通用人工智能则是具备与人类智能相媲美的综合性智能系统,其实现是人工智能领域的终极目标,但目前仍面临诸多挑战。通过不断改进和扩展AI agent 的功能和能力,我们可以逐步迈向通用人工智能的实现,推动人工智能的发展和应用。
挑战
AI agent 和通用人工智能的发展都面临以下一些技术挑战:
-
推理和智能决策:AI agent 和通用人工智能需要具备高级推理能力和智能决策能力。这包括能够理解复杂的情境、进行逻辑推理、推断因果关系和处理不完全信息等能力。
-
自主学习和持续改进:AI agent 和通用人工智能需要能够从经验中学习,并不断改进自身的性能和能力。这涉及到机器学习和深度学习算法的发展,以及解决模型遗忘、样本不平衡和领域迁移等问题。
-
知识表示和推理:AI agent 和通用人工智能需要能够有效地表示和推理知识。这包括知识图谱的构建和更新、语义表示的精确性和丰富性、以及在不完整和模糊信息下进行推理和推断的能力。
-
跨领域和跨模态理解:AI agent 和通用人工智能需要具备跨领域和跨模态的理解能力。这涉及到将不同领域的知识和信息进行整合和交互,以及从多种感知模态(如图像、语音和文本)中获取和理解信息。
-
常识和上下文理解:AI agent 和通用人工智能需要具备常识和上下文理解能力。这包括理解日常生活中的常识性知识和推理,以及对话中的上下文理解和推断。
-
灵活性和创造性:AI agent 和通用人工智能需要具备灵活性和创造性。这意味着它们能够从已有知识中生成新的知识、提供创新性的解决方案,并适应新的任务和环境。
-
隐私和安全:AI agent 和通用人工智能的发展需要解决隐私和安全问题。这涉及到保护个人数据的隐私,防止恶意使用和滥用人工智能技术,以及建立可信赖的人工智能系统。
-
伦理和社会影响:AI agent 和通用人工智能的发展需要考虑伦理和社会影响。这包括确保人工智能系统的公平性、透明度和可解释性,以及处理人工智能在就业、隐私、道德和权力分配等方面带来的社会和伦理问题。
这些技术挑战都需要跨学科的研究和合作,涉及到机器学习、自然语言处理、计算机视觉、知识表示与推理、人机交互等多个领域的进展和创新。解决这些挑战将推动AI agent 和通用人工智能的发展,使其能够更好地与人类进行交互并在各个领域发挥作用。
这篇关于【人工智能】机器学习、深度学习、强化学习相关的核心技术,以及这些技术在促进人工智能发展、优化经济效益、解决社会问题等方面所扮演的角色、意义和作用,并探讨未来可能的发展方向的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






