本文主要是介绍逐字稿 | 1 ViT论文逐段精读【论文精读】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
标题
摘要
1引言
1.1把 Transformer 用到视觉问题上的一些难处
1.2受到transformer可扩展性的启发,要用一个标准的transformer处理视觉问题,序列长度怎么办?
最相似的过往工作
2结论
3相关工作
4方法
4.1整个对图片的这个预处理:包括加上特殊的字符 CLS 和加上这个位置编码信息,也就是 Transformer 的输入
4.2多头自注意力
4.3消融实验:clstoken
4.5消融实验:位置编码
4.6公式把整体的这个过程总结了一下
4.7模型变体:混合模型
4.8微调
5实验
5.1当它已经在大规模的数据集上进行预训练了,然后在这么多数据集上去做 fine tuning 时候得到的表现
5.2vit到底需要多少数据才能训练的比较好、分析训练成本
5.3可视化分析vit内部的表征
patch embedding
positional embedding
自注意力有没有起作用
5.4如何用自监督的方式去训练一个 vision Transformer
总结
如果说过去一年中在计算机视觉领域哪个工作的影响力最大,那应该非 vision consumer 莫属了,因为它挑战了自从 2012 年 Alexnet 提出以来卷积神经网络在计算机视觉领域里绝对统治的地位。它的结论就是说,如果在足够多的数据上去做预训练,那我们也可以不需要卷积神经网络,直接用一个从自然预言处理那边搬过来的标准的 transmer 也能把视觉问题解决得很好。
而且 vision Transformer 不光是在视觉领域挖了一个大坑,因为它打破了 CV 和 LP 在模型上的这个壁垒,所以在多模态领域也挖了一个大坑。于是,在短短的一年之内,各种基于 vision translora 的工作层出不穷,观众多,论文应该已经有上百篇了,要把它扩展到别的任务的,有对模型本身进行改进的,有对它进行分析的,还有对目标函数或者训练方式进行改进的。基本上是可以说开启了 CV 的一个新时代。
那 vision Transformer 到底效果有多好?我们可以先来看一下 paper with code 这个网站,就是说如果你想知道现在某个领域或者某个数据集表现最好的那些方法有哪些,你就可以来查一下。我们先来看图像分类,在 Imagenet 这个数据集上,排名靠前的全都是基于 vision Transformer。那如果我们换到目标检测这个任务,在 Coco 这个数据集上,我们可以看到排名前几的都是基于 swin Transformer 的。swin Transformer 是今年 ICC V21 的最佳论文,你可以把它想象成是一个多尺度的VIT。当然还有很多领域了,语义分割、实力分割、视频医疗、遥感。基本上可以说 vision Transformer 把整个视觉领域里所有的任务都刷了个遍。但我们今天要读 vision Translora 这篇论文,也不光是因为它效果这么炸裂,还是因为它有很多跟 CNN 很不一样的特性。我们可以先来看一下这篇论文。

这篇论文的题目叫做vision Transformer一些有趣的特性我们可以来看它的图一里举了一些例子,就是说在卷积神经网络 c n 上工作的不太好,但是用出 a n transformer 都能处理很好的例子。比如说第一个就是遮挡,那在这么严重的遮挡情况下,不光是卷积神经网络,其实就是我也很难看得出其中有一只鸟。第二个例子就是数据分布上有所偏移,在这里就是对图片做了一次纹理去除的操作,嗯,所以说导致图片看起来非常魔幻,我也很难看出来其中到底是什么物体。第三个就是说在鸟头的位置加了一个对抗性的patch。第四个就是说把图片打散了以后做排列组合,所以说卷积神经网络也是很难去判断这到底是一个什么物体的。但所有这些例子, vision Transformer 都能处理得很好,所以说鉴于 vision Transformer 的效果这么好,而且它还有这么多有趣的特性,跟卷积神经网络如此不一样,那所以我们今天就来精读一下这篇 vision Transformer 的论文。
标题
那我们先来看一下题目是说一张图片等价于很多 16 * 16 大小的单词,那为什么是 16 * 16?而且为什么是单词?其实它是说把这个图片看作是很多很多的patch,就假如说我们把这个图片然后打成这种方格的形式,每一个方格的大小都是 16 * 16,那这个图片其实就相当于是很多 16 * 16 大小的这个 patch 组成的一个整体。
接下来第二句是 Transformer 去做大规模的图像识别,作者团队来自 Google research 和 Google brain team。
摘要
好,接下来我们看一下摘要是说虽然说现在 Transformer 已经是 NLP 领域自然语言处理领域里的一个标准了,那我们也知道就 Bert model GPT 3,然后或者是 T5 模型,但是用 Transformer 来做 CV 还是很有限的。
在视觉里这个自注意力要是跟卷积神经网络一起用,要就是说去把某一些卷积神经网络里的卷积替换成自注意力,但是还是保持整体的这个结构不变。他说的这整体结构是指比如说我们有一个残差网络 rise 50,它有四个stage,然后 rise 2, rise 3, rise 4, rise 5,那它就说这其实这个 stage 是不变,它只是去取代每一个stage,每一个 block 里的这个操作。而这篇文章就证明了这种对于卷积神经网络的依赖是完全不必要的。
一个纯的 Transformer 直接作用于一系列图像块儿的时候,它也是可以在图像分类这个任务上表现得非常好的,尤其是当在你在大规模的数据集去做预训练,然后又迁移到中小型数据集时,由这个 vision Transformer 能获得跟最好的卷积神经网络相媲美的结果。它这里把 image net Cipher 100V Tab 当作中小型数据集,但其实 image net 对于很多人来说都已经是很大的数据集了。
然后摘要的最后一句话还指出了另外一个好处,他说 Transformer 需要更少的这个训练资源。你乍一听觉得这真的很好,正愁手上两块卡或者 4 块卡训练不动大模型,这就来了一个需要特别少的训练资源就能训练的模型,而且表现还这么好。但其实你想多了,作者这里指的少的训练资源是指 2500 天 TPU V3 的天数,他说的少只是跟更号卡的那些模型去做对比,这个怎么说还是比较讽刺的,就跟某人说,我先定一个小目标,先挣它一个亿。
1引言
那接下来我们来看一下引言说呢,自注意力的这个网络,尤其是 Transformer 已经是自然语言处理里的必选模型了。现在比较主流的方式就是先去一个大规模的数据集上去做预训练,然后再在一些特定领域里的小数据集上去做微调,那其实这个就是 Bert 这边 paper 里提出来的。
接下来说多亏了 transform 的计算高效性和这个可扩展性,现在已经可以训练超过 1000 亿参数的模型了,比如说像 GPT 3。然后最后一句话他是说随着你的这个模型和数据集的增长,我们还没有看到任何性能饱和的现象。这个就很有意思了,因为我们知道很多时候不是你一味的扩大数据集,或者说扩大你的模型就能获得更好的效果的,尤其是当扩大模型的时候,很容易碰到就是过拟合的问题。那对于 Transformer 来说,好像目前还没有观测到这个瓶颈。比如说最近微软和英伟达又联合推出了一个超级大的语言生成模型,叫 Megtron Turing,它已经有 5300 亿的参数了,然后还能在各个任务上继续大幅度提升性能,没有任何性能饱和的现象。
1.1把 Transformer 用到视觉问题上的一些难处
那在继续往下读引言之前,我想先说一下把 Transformer 用到视觉问题上的一些难处。我们先来回顾一下Transformer,假如说我们有一个 transformer 的encoder,好,我们输入是有一些元素,那这里假如说是在自然语言处理这些就是一个句子里的一个一个的单词输出,也是一些元素。 transformer里最主要的操作就是自助力操作,自助力操作就是说每个元素都要跟每个元素去做互动,是两两互相的,然后算得一个attention,就是算得一个自助力的图,而用这个自助力图去做加权平均,然后最后得到这个输出。因为在做自助力的时候,我们是两两相互的,就是说这个计算复杂度是跟这个序列的长度乘方倍的。目前一般在自然语言处理,就是说现在硬件能支持的这个序列长度一般也就是几百或者上千,比如说在 Bert 里,也就是 512 的这个序列长度。
那我们现在换到视觉领域,我们就是想用 Transformer 的话,首先第一个要解决的问题就是如何把一个 2D 的图片变成一个 1D 的序列,或者说变成一个集合。那最直观的方式就是说我们把每个像素点当成这边的这种元素,然后直接把 2D 的图片拉直,然后把这个扔到 Transformer 里,然后自己跟自己学去就好了。但是想法很美好,实现起来复杂度太高。
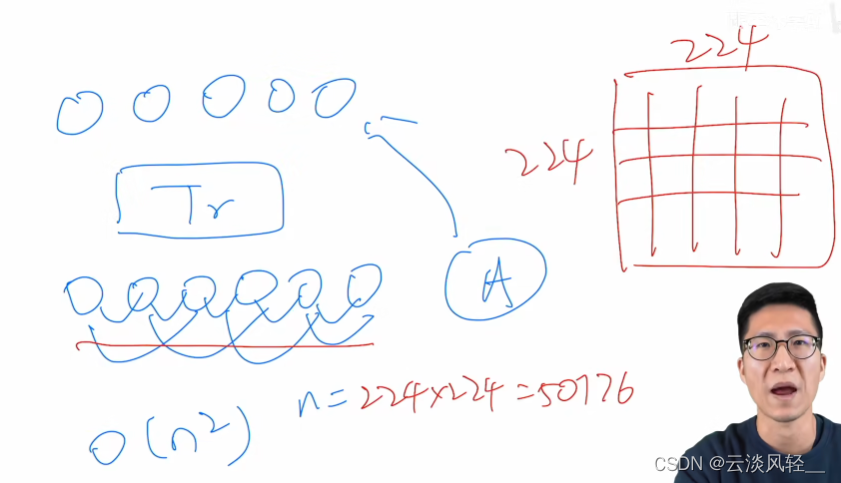
一般来说,在视觉里面,我们训练分类任务的时候,这个图片的输入大小大概是 224 * 224 这么大,那如果把图片里的每一个像素点都直接当成这里的元素来看待,那其实它的序列长度就不是 512 了,那它的序列长度就是 224 * 224 = 50176。因为我们一共就有这么多像素点,一共有5万个像素点,所以这就是序列的长度。那这个序列长度5万其实也就意味着相当是 Bert 序列长度, 512 像 100 倍,所以这个复杂度是相当可怕的。
然后这还只是分类任务,它的图片大小就 24 * 24 这么大,那对于检测或者分割这些任务,现在很多模型的输入都已经是变成 600 * 600 或者或者 800 * 800 或者更大了,那这个计算复杂度就更是高不可攀了。
所以说我们现在回到引言第二段就说,所以说在视觉现在卷积神经网络还是占主导地位的,像这 Alex net 或者Resnet,但是 Transformer 在 LP 领域又这么火,自注意力又这么香,那我计算机视觉那就是想用一下自注意力怎么办?所以说很多工作就是想怎么能把自注意力用到视觉里来。一些工作就是说去把这个卷积神经网络和自注意力混到一起用。另外一些工作就是说整个把卷积神经都换掉了,然后就全用自主遗力。
这些方法其实都在干一个事儿,就是说你不是说序列长度太长,所以导致没办法把 transformer 用到视觉里来吗?那我就想办法去降低这个序列长度。那比如说像这篇论文就是 C a P R E 8 on local network 了,那就是说既然用这个像素点当输入,导致序列长度太长的话,我们就不用图片当这个 Transformer 的直接输入,我们把网络中间的这个特征图当做 Transformer 的输入,那大家都知道,假如说我们要残差网络 rise 50,那其实在它最后一个 stage 到 rise 4 的时候,它的 feature map 的 size 其实就只有 14 * 14 那么大,那 14 * 14 的话你把它拉平其实也就只有 196 个元素。
意思就是说这个序列长度就只有196,这个就是可以接受的范围之内了,所以它就用过这种方式,用特征图当做 Transformer 输入的方式去降低这个序列长度。那像他说的第二个方向,他其实举了两个例子,一个叫做 standalone attention,另外一个是 Excel attention,就是一个是孤立自注意力,一个是轴注意力,那对于这个孤立自注意力他做的什么事?他意思是说你这个复杂度高是来源于你用整张图,那如果我现在不用整张图了,我就用一个 local 的一个window,就我就用一个局部的小窗口,那这个复杂度就是你可以控制,你可以通过控制这个窗口的大小来让这个计算复杂度在你可接受的范围之内,那这个就有点相当于回到卷积那一套操作,因为卷积也是在一个局部的窗口里做的。
那对于这个轴自助力工作,他的意思是说图片的复杂度高是因为它的序列长度是 a n 等于 h 乘w,它是一个 2D 的矩阵,那我们能不能把图片这个 2D 矩阵拆分成两个 1D 的向量,所以它们就是先在高度这个 dimension 上去做一次 self attention,就做一个自助遗力,然后他们再去在这个宽度这个 dimension 上再去做一次自助力,相当于它把一个在 2D 矩阵上进行的自助力操作变成了两个 1D 的顺序的操作,那这样这个计算复杂度就大幅降低了。
然后 vision 创作作者又说这些后一种方式,就是说这个完全用自注意力把卷积操作的这一类工作,他们虽然理论上是非常高效的,但事实上因为他们的这个自制力操作都是一些比较特殊的自制力操作,所以说没有在现在的这个硬件上去加速,所以就会导致你很难去把它训练一个大模型。所以说截止到目前为止,像这种 standalone attention 或者这个 XO attention,它的模型都还没有太大,就是跟这种百亿千亿级别的大transformer模型比还是差得很远。因此最后一句话就是说,在大规模的图像识别上,这个传统的残差网络还是效果最好的。
1.2受到transformer可扩展性的启发,要用一个标准的transformer处理视觉问题,序列长度怎么办?
那介绍完之前的工作,接下来就该讲 vision Transformer 这篇 paper 到底做了什么事了。所以我们可以看到自注意力早已经在计算机视觉里有所应用,而且甚至已经有完全用自驱力去取代卷积操作的工作。所以这篇论文他就换了个角度去讲故事。他说他们是被 Transformer 在 NLP 领域里这个可扩展性所启发,他们想做的就是直接应用于一个标准的Transformer,直接作用于图片,尽量做少的修改,就是不做任何针对视觉任务的特定改变,看看这样的 Transformer 能不能在视觉领域里扩展的很大很好。
如果直接用Transformer,那老问题又回来了,这个这么长的序列长度该怎么办?所以 vision Transformer 是怎么处理的?别人 transformer 是像我们刚才讲的一样,我把一个图片打成了很多patch,每一个 patch 就是 16 * 16。
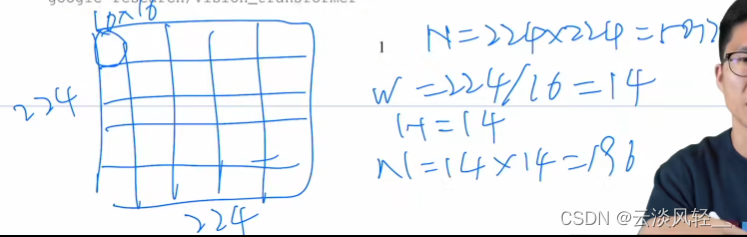
我们来看,假如说这个图片的大小是 r R 4 乘以R24,那刚开始我们算这个 sequence lens 是 R24 乘 R24 等于50176。那现在如果我们换成patch,就是这一个patch,相当于是一个元素,那有效的长宽又会是多少呢?那比如说现在这个宽度就变成了 224 / 16,其实就相当是 14 了,同样高度也就是14,所以说这样的话最后的这个序列长度就变成了 14 * 14 乘以196,意思就是说现在这张图片就只有 196 个元素,那 196 对于普通的 Transformer 来说还是可以接受的这个序列程度。然后我们把这里的每一个 patch 当做一个元素,然后通过一个这个 FC layer 就会得到一个 linear embedding,然后这些就会当做输入传给Transformer。这个时候你其实可以很容易的看出来,一个图片就已经变成一个一个的这样的图片块了。然后你可以把这些图片块儿当成是像 NLP 里的那些单词,就一个句子有多少词,那就相当于是一个图片现在有多少个patch,这就是它题目的意义,一个图片等价于很多 16 * 16 的单词。
最后一句话他说我们训练这个 vision Transformer 是用的有监督的训练。为什么要突出有监督?因为对于 NLP 那边来说的话, consumer 基本上都是用无监督的方式去训练的,要么是用 language modeling,要么是用 mask language modeling,总之都是无监督的训练方式。但是对于视觉来说,大部分的基线网络还都是用这个有监督的训练方式去训练。读到这儿我们可以看出来,这个 vision Transformer 这篇 paper 真的是把视觉当成自然语言处理的任务去做了,尤其是中间的这个模型,它就是用了一个 translora encoder,跟 Bert 是完全一样的。
那如果你已经听过墓神讲解 Bert 这篇论文了,那其实 vision Transformer 这篇论文对你而言没有任何技术难点,这篇论文其实就是想告诉你,用这么简洁的一套框架, Transformer 也能在视觉里起到很好的效果。
最相似的过往工作
那其实大家就会很好奇,这么简单的做法之前难道就没有人想过这么做吗?其实肯定是有人这么做了,那其实vision transformer 这篇论文在相关工作里已经介绍过了,他说跟他们这篇工作最像的其实是一篇 iclear 2020 的paper Cordonnier et al. (2020)。那篇论文是从这个输入图片里去抽这个 2 * 2 的图片。 patch 为什么是 2 * 2?因为那篇论文的作者只在Cipher,而这个数据集上去做了实验,那Cipher 的那些图片都是 32 * 32 的,所以说你只需要抽 2 * 2 的 patch 就够了,如果你抽 16 * 16,那就太大,一旦抽好这个 patch 以后,然后他们就在上面做 self attention。
比如说你一听,那其实这个不就是 vision Transformer 吗?那确实是从技术上而言,它就是 vision Transformer,但是 vision Transformer 的作者告诉你说我们的区别在哪?就我们的工作就是证明了,如果你在大规模的数据集上去做这个预训练的话,就跟 NLP 那边一样,在大规模的语料库上去做预训练,那么我们就能让一个标准的 Transformer 就是不用在视觉上做任何的更改或者特殊的改动,就能取得比现在最好的卷积神经网络还好,或者差不多的结果。同时他们还指出说之前的这个ICLR的这篇论文,他们用的是很小的patch,是 2 * 2 的,所以让他们的模型只能处理那些小的图片。而 vision Transformer 是可以 handle media resolution,也就是 R4 这种的图片。所以这篇文章的主要目的就是来告诉你 Transformer 在 vision 这边儿能够扩展的有多好。
这是在超级大数据集和超级大模型的两方加持下, Transformer 到底能不能取代卷积神经网络的地位?
那我们回到引言,一般引言的最后就是把你最想说的结论或者最想表示的结果放出来,这样大家不用看完整篇论文就能知道你这篇论文的贡献到底有多大。他说当在中型大小的数据集上,比如说 image net 去训练的时候,如果不加比较强的约束,vit其实跟同等大小的残差网络相比,其实是要弱的,这是要弱几个点,那作者就得解释那它为什么弱?所以论文紧接着说这个看起来不太好的结果其实是可以预期的,为什么呢?因为 Transformer 跟卷积神经网络相比,它缺少一些卷积神经网络有的归纳偏置,
那这个归纳偏置这个概念很有意思,他其实说的就是指一种先验知识,或者一种我们提前做好的假设。比如说对于碱基神经网络来说,我们常说的就有两个 inducte bison,两个归纳变质,一个叫做locality。因为卷积神经网络是以滑动窗口,这种形式是一点儿在图片上进行卷积的,所以它假设图片上相邻的区域会有相邻的特征,那这个假设当然是非常合理的,比如说桌子和椅子,那就大概率它经常就会在一起,靠的越近的东西,它的相关性就会越强。
另外一个归纳偏置叫做平移等边性,也就是我们常说的 translation equivariance,它的意思就是如果你把它写成公式的话,其实是这样的, f g x 等于 g f x 就是不论你先做 g 这个函数,还是先做 f 这个函数,最后的结果是不变的。这里你可以把 f 理解成是卷积,然后 g 可以理解成是平移这个操作。那意思就是说无论你先做平移还是先做卷积,最后的结果是一样的,因为卷积神经网络里这个卷积核就相当于是一个模板一样,像一个 template 一样,那不论你这个图片同样的物体移到哪里,那只要是同样的输入进来,然后遇到了同样的卷积核,那它的输出永远是一样的。
一旦卷积神经网络有了这两个归纳偏执以后,它其实就有了很多先验信息,所以它就需要相对少的数据去学一个比较好的模型。但是对于 Transformer 来说,它没有这些先验信息,所以说它所有的这些能力,对视觉世界的感知全都需要从这些数据里自己学。
为了验证这个假设,作者就在更大的数据集上去做了预训练。这里的这个 14 million 1400 万的图片就是 image net twenty two k 数据集,这里的 300 million 数据集就是 Google 他们自己的 GFT 300 million 数据。上了大数据以后,果然这效果拔群,他们立马就发现,那这个大规模的预训练就比这个归纳偏执要好。 vision Transformer 只要在有这个足够的数据去预训练的情况下,就能在下游任务上获得很好的迁移学习效果。具体来说就是当在 imission net 21K 上去训练,或者说在这个 GFT 300 命令上去训练的时候, VIT 就能获得跟现在最好的残差网络相近或者说更好的结果。最后他还罗列了一些结果,比如说 image net 88. 5,那确实相当高。还有 image net real Safari 100 还有 v Tab 这些数据集。
v Tab 是其实也是这个作者团队他们提出来的一个数据集,是融合了 19 个数据集,主要是用来检测一个模型这个稳健性好不好的,所以从侧面也可以反映出 vision Transformer 的稳健性也是相当不错。所以读到这儿,引言算是读完了。那引言还是写得非常简洁明了的。
第一段先上来说,因为 Transformer 在 NRP 那边扩展得很好,越大的数据或者越大的模型,最后的 performance 就会一直上升,没有饱和的现象,那自然而然就会有一个问题,那如果把 transformer 用到视觉里来,那是不是视觉的问题也能获得大幅度的提升?
第二段就开始讲前人的工作,因为这么好的方向不可能没人做过,所以一定要讲清楚自己的工作和前人的工作的区别在哪里。他说之前的工作要么就是把卷积神经网络和自注意力合起来,要么就是用自助力去取代卷积神经网络,但是从来都没有工作直接把 Transformer 用到视觉领域里来,而且也都没有获得很好的扩展效果。
所以第三卷它就讲 vision Transformer,就是用了一个标准的 Transformer 模型,只需要对图片做一下预处理,就是把图片打成块,然后送到 transform 里就可以了,别的什么改动都不需要。这样彻底可以把一个视觉问题理解成是一个 NLP 问题,这样就 CV 和 NLP 这两个领域就大一统了。
最后两段当然是卖一下结果了,其实只要在有足够多数据去预训练的情况下, vision Transformer 能在很多数据集上取得很好的效果。
2结论
那接下来我们按照木神读论文的方式,先来看一下结论,结论里它上来没有任何花里胡哨,直接一句话就点明了这篇 paper 它到底在干什么:直接拿 NLP 领域里标准的 Transformer 来做计算机视觉问题。然后他说跟之前的那些工作就是用自注意力的那些工作不一样的,除了在刚开始的抽图像块儿的时候,还有这个位置编码用了一些图像特有的这个归纳偏置,除此之外就再也没有引入任何图像特有的归纳偏置了。
这样的好处就是我们不需要对 vision 领域有什么了解,或者有什么 domain knowledge,我们可以直接把这个图片理解成为是一个序列的图像块儿,就跟一个句子里有很多单词一样,然后就可以直接拿 NLP 里面一个标准的 Transformer 来做图像分类了。这个简单,然后扩展性很好的这个策略,当你跟大规模预训练结合起来的时候,工作的出奇的好。
怎么个好法?就是说 vision Transformer 在很多这个图像分类的这个 Benchmark 上,超过了之前最好的方法,而且还相对便宜,就训练起来还相对便宜。
然后接下来第二段,他又写了一些目前还没有解决的问题,或者是对未来的一个展望。为什么要写这一段?其实是因为 vision consumer 这篇论文属于是一个挖坑的论文,挖坑你可以是挖一个新问题的坑,或者是挖一个新数据集的坑,那这篇论文其实是挖了一个新模型的坑,比如说如何能用 Transformer 来做CV,那所以很自然的第一个问题就是说那 vision consumer 不能只做分类,那这个 vision consumer 肯定还得去做这个分割和检测,对吧?另外两个最主流的视觉任务,还有就是之前另外一篇很 popular 的工作,就这个detr。 DETR 是去年目标检测了一个力作,它相当于是改变了整个目标检测之前的框架,就是出框的这种方式。鉴于 VIT 和 DATR 良好的表现,所以说他是拿 vision Transformer 做视觉的,其他问题应该是没有问题的。
而事实上也正是如此,就在 VIT 出来短短的一个半月之后,就在 2020 年 12 月,检测这块就出来了一个工作,叫做VITFRCNN,就已经把 VIT 用到 detection 上了, segmentation 也一样。同年 12 月啊,这有一篇 SETR 啊塞出的论文把 Transformer 卫生 Transformer 用到分割里了。那这里我想说的是,大家的手速真的是太快了。因为虽然表面看起来 Satura 这篇论文是 12 月份才传到 r cap 上的,但是它是 CVPR 2020 的重稿论文,也就意味着他在 11 月 15 号的时候就已经完成了论文的写作并且投稿了。所以说 CV 圈这个卷的程度已经不能用月来计算了,已经要用天来计算了。而且紧接着三个月之后, swin Transformer 横空出世,他把多尺度的这个设计融合到了 Transformer 里面,所以说更加适合做视觉的问题了。
真正证明了 Transformer 是能够当成一个视觉领域,一个通用的骨干网络的另外一个未来工作方向,它就是说要去探索一下这个自监督的预训练方式。那是因为在 n l p 领域,所有的这些大的 transformer 全都是用自监督的方式训练。一会我们在看实验的时候也可以一起讨论一下之前 NLP 包括 vision 这边是怎么做自监督预训练的。所以说 vision translora 这篇论文它也做了一些初始实验,他们证明了就是说用这种自监督的训练方式也是 OK 的,但是跟这个有监督的训练比起来还是有不小的差距的。
最后作者还说就是说继续把这个 vision Transformer 变得更大,有可能会带来更好的结果。那这个坑作者团队没有等别人去填,他想着反正别人可能也没有这种计算资源,那我就来把这个坑填一填。所以说过了半年,同样的,作者团队又出了一篇论文,叫 scaling vision Transformer,就是把 Transformer 变得很大,提出了一个VIP,然后就把 image net 分类的准确率刷到 90 以上了。
所以说这篇论文真的是一个很好的挖坑之作,它不光是给视觉挖了一个坑,就是从此以后你可以用 Transformer 来做所有视觉的任务。他同时还挖了一个更大的坑,就是在 CV 和 RP 能够大一统之后,那是不是多模态的任务就可以用一个 transformer 去解决了?而事实上,多模态那边的工作最近一年也是井喷式的增长。由此可以看来 vision Transformer 这篇论文的影响力还是非常巨大的。
3相关工作
那我们现在回到相关工作,他先说了一下 Transformer 在 NLP 领域里的应用。他说自从 2017 年这个Transformer 提出来去做这个机器翻译以后,基本上 Transformer 就是很多 NLP 任务里表现最好的方法。现在大规模的这个 Transformer 模型一般都是先在一个大规模语料库上去做预训练,然后再在这个目标任务上去做一些细小的微调。这里面有两系列比较出名的工作,一个就是Bert,一个就是GPT。 a Bert 是用了一个 denoising 的自监督的方式,其实就是完形填空了,就是你有一个句子,你把其中某些词划掉,你先要把这些词再 predict 出来,这个 GPT 用的是 language modeling 去做词监督, language modeling 是你已经有一个句子,然后我要去预测下一个词是什么,也就是 next word prediction 预测下一个词。因为这两个任务其实都是我们人为定的,就是说语料都在哪,句子就在哪,是完整的。我们只是人为的去化掉其中某些部分,或者把最后的词拿掉,然后去做这种完形填空或者预测下一个词,所以这叫自监督的训练方式。
接下来就开始讲自注意力在视觉里的应用,视觉里就是说如果你想简单的使用一个自注意力,还用到这个图片上,最简单的方式就是说你把每一个像素点当成是一个元素,你就去让他们两两去自注意力就好了,但是我们在引言里也说过这个是平方复杂度,所以说是很难应用到真实的这个图片输入尺寸上的。那像现在分类任务的 224 * 224 Transformer 都很难处理。那更别提就是我们人眼看得比较清晰的图,一般都是 1K 或者 4K 这种画质了,那序列长度都是上百万,直接在像素层面使用 Transformer 肯定是不现实的。所以说如果你想用Transformer,那就一定得做一些这个近似,那这里他就罗列一些例子,比如说这些工作,
- 他们是说你的复杂度高是因为你用了整张图,所以你的序列长度长。那我现在不用整张图,我就用这个 local neighborhood,我就用一个小窗口去做这个自助移力,那序列长度不就大大降低了吗?那最后的这个计算复杂度不也就降低了吗?
- 那另外一条路就是用 SPASS Transformer,这个顾名思义就是我就只对一些稀疏的点去做自注意力,所以只是全局注意力的一个近似。
- 还有一系列方法,就是说把这个自注意力用到不同大小的这种 block 上,
- 或者说在极端的情况下就是直接走轴了,也就是我们刚才讲的轴注意力,就是先在横轴上去做自主语力,然后再在纵轴上做出自主意力,那这个序列长度也是大大减小的。
然后他说这些特制的自主意力结构其实在计算机视觉上的结果都不错,就是表现是没问题,但是它需要很复杂的工程去加速这个算子,从而能在 CPU 或者 GPU 上跑得很快,或者说让训练一个大模型成为可能?
- 接下来这段我们其实已经在引言里读过了,就是说跟他们工作最相似的是一篇ICLR2020 的论文,vision Transformer就是在用了更大的 patch 和更多的数据集,去训练一个更好的Transformer。然后他说在计算机视觉领域肯定还有很多工作是把这个卷积神经网络和这个自注意力结合起来的,这类工作是相当多的,而且基本涵盖了视觉里的很多任务,比如说这个检测分类,然后这个视频还有多模态。
- 然后作者又说还有一个工作跟他们的工作很相近,就叫 image GPT。我们都知道 GPT 是用在 NLP 里,是一个生成式的模型,那 image GPT 同样也是一个生成型模型,也是用无监督的方式去训练的,它跟 vision Transformer 有什么相近的地方?是因为它也用了Transformer,最后这个 i GPT 能达到一个什么效果?如果我们拿训练讨论模型去做一个微调,或者说就把它当成一个特征提取器,我们会发现它在 Imagenet 上最高这个分类准确率也只能到72,那像这篇 vision Transformer 最后的结果已经有 88. 5 了,所以说是远高于这个 72 的结果。但这个结果也是最近一篇论文 Mae 爆火的原因,因为在 BEIT 或者 MAE 这类工作之前,生成式网络在视觉领域很多任务上,这没法跟判别式网络比的,判别式网络往往要比生成式网络的结果要高很多,但是 MAE 就做到了,就在 Imagenet EK 这个数据集上去做训练,就用一个生成式的模型,比之前判别式模型的效果要好。而且不光是在分类任务上,最近他们还研究了一下迁移学习的效果,就是在目标检测上效果也非常好。
最后作者又说 vision Transformer 其实还跟另外一系列工作是有关系的,就是用比 image net 还大的数据集去做这个预训练,这种使用额外数据的方式一般能够帮助你达到特别好的效果。比如说之前 2017 的这篇论文,其实也就是介绍 JFT 300 million 的这个数据集的论文,他研究了就是卷积神经网络的效果是怎么随着数据集的增大而提高的。还有一些论文是研究了当你在更大的数据集上,比如说 Imagenet 21K 和 GFT 300 million 去做预训练的时候,这个迁移学习的效果会怎么样?就是当你迁移到 Imagenet 或者 Safari 100 上的效果会如何。在这篇论文里, vision consumer 说我们也是聚焦于最后两个数据集,就是这个 Imagenine 21K 和 GFT 300 million。但是我们并不是训一个残差网络,我们是去训transformer。
那其实这个相关工作写得非常彻底的,而且他列举了很多跟他们工作最相近的,比如说这篇 ICLR 2020 的论文,还有这个 i GPT,还有之前研究大数据集的,比如说BIT。其实写相关工作这个章节,就是要让读者知道在你的工作之前,别人做了哪些工作,你跟他们的区别在哪里?这个只要写清楚了,其实是对你非常有利的,并不会因此降低论文的这个创新性,反而会让整个文章变得更加简单易懂。
4方法
那接下来我们就一起来读一下这个文章的第三节这个主体部分。那么说在模型的设计上是尽可能的按照这个最原始的这个 Transformer 里来做的。这样一个好处就是说我们可以直接把NLP 那边已经成功的 Transformer 架构直接拿过来用,我们就不用自己再去魔改模型了。而且因为 Transformer 已经在 LP 领域火了这么多年了,它有一些写得非常高效的一些实现,同样vision Transformer 可以直接把它拿过来用。
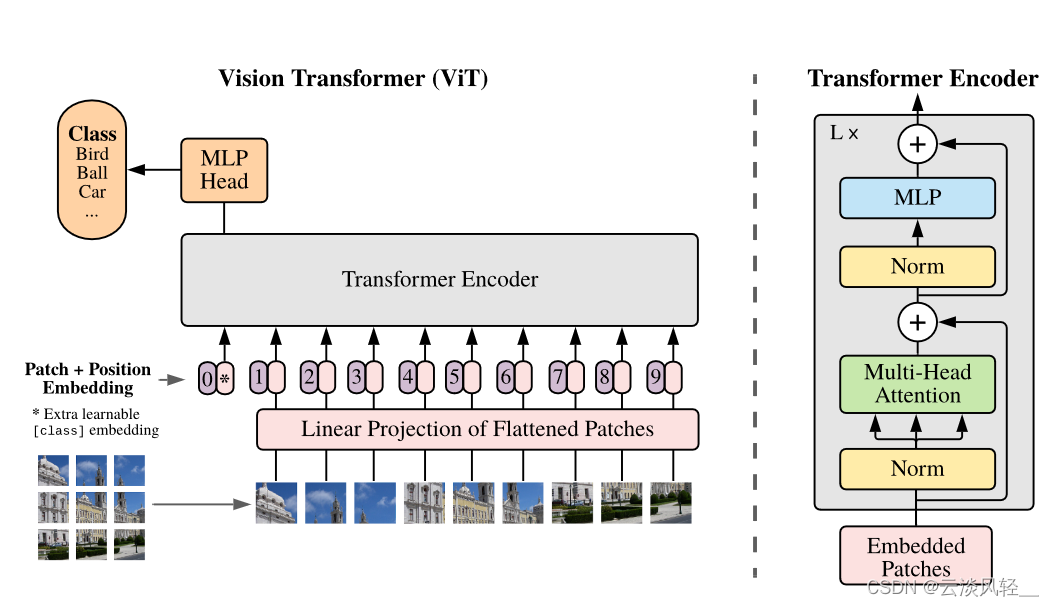
那接下来看 3. 1 说模型的一个总览图画在图一里了,模型的总览图其实对很多论文来说是非常重要的,画得好的模型总览图能够让读者在不读论文的情况下,光看这张图就能大概知道你整篇论文在讲什么内容。vit这张图其实画的就很好,因为我们也可以看到,当别人在讲解vit这篇论文或者跟他对比的时候,都是直接把这个图一直接就复制粘贴过去了,而不是说自己为了讲解的需要,还要再费尽心思再从头再画一个图。接下来我们先大概过一下这个整体的流程,然后我们再具体的过一遍整个网络的这个前向操作,这样对vit的理解就更深刻了。
首先给定一张图,他是先把这张图打成了这种patch,比如说这里是把这个图打成了九宫格,然后他把这些 patch 变成了一个序列,每个 patch 会通过一个叫线性投射层的操作得到一个特征,也就是这篇论文里说的 patch embedding。
但我们大家都知道,这个自注意力是所有的元素之间两两去做这个交互,所以说它本身并不存在一个顺序问题。但是对于图片来说,它是一个整体,这个九宫格是有自己的顺序的,比如说这图片就是123,一直到第九张图片,它是有顺序的,如果这个顺序颠倒了,其实就不是原来这张图片了。同样类似 LP 那边,我们给这个 patch embedding 加上了一个 positioning embedding,就加上一个位置编码,一旦加上这个位置编码信息以后,这个整体的 token 就既包含了这个图片块原本有的图像信息,又包含了这个图像块儿的所在位置信息。
那一旦我们得到这些一个一个的token,那其实接下来就跟 LP 那边是完全一样,我们直接把它给这么一个 transformer encoder,而 transformer encoder 就会同样的反馈给我们很多输出。那这里问题又来了,那这么多输出,我们该拿哪个输出去做最后的分类?所以说再次借鉴 Bert 那边有这个叫 extra learnable embedding,也就是一个特殊字符,叫CLS,哈,叫分类字符。同样的我们在这里也加了这么一个特殊的字符,这里用星号代替,而且它也是有 position embedding,它有位置信息的,它永远是0。因为所有的 token 都在跟所有的 token 做交互信息,所以他们相信这个 class embedding 能够从别的这些 embedding 里头去学到有用的信息,从而我们只需要根据它的输出做一个最后的判断就可以。那最后这个 MLB head 其实就是一个通用的分类头了,最后用交叉熵函数去进行模型的训练。
至于这个 transformer encoder 也是一个标准的transformer。这篇论文也把具体的结构列在右边了,就是说当你有这些 patch 的时候,你先进来做一次 layer norm,然后再做 multihead self attention,然后再 layer norm,然后再做一个MLP,这就是一个 transformer block,你可以把它叠加 l 次就得到了你的 Transformer encode。
所以说整体上来看, vision Transformer 的架构还是相当简洁,它的特殊之处就在于如何把一个图片变成这里的一系列的token。
我们接下来可以具体按照论文中的文字,再把整个模型的前向过程走一遍。
4.1整个对图片的这个预处理:包括加上特殊的字符 CLS 和加上这个位置编码信息,也就是 Transformer 的输入
假如说我们有个图片x,然后它的 dimension 是 224 乘 224 * 3,如果我们这里使用 16 * 16 的这个 patch size 大小,那我们就会得到多少token? n 等于 224 平方,除以 16 的平方,也就是196,就 14 的平方,就我们一共会得到 196 个图像块,那每一个图像块的维度如何?其实就是 16 乘以3,也就是768,这三就是 RGB channel。所以我们就把原来的这个图片 24 * 24 * 3 变成了一个有 196 个patch,每个 patch 的维度是768。
那接下来这个线性投射层是什么呢?其实这个线性投射层就是一个全连接层,文章后面是用大 e 这个符号,就代表这个全连接层的维度是多少。其实这个全连接层的维度是 768 乘以768,这个7768,也就是文章中一直说的那个d。当然这个 d 是可以变的,就如果你的 transfer 变得更大了,那这个 d 也可以变得相应的更大。但是前面这个 768 是从图像 patch 算来的,是 16 乘以 16 * 3 算来的,所以这个是不变。那经过了这个线性投射,我们就得到我们的这个 patch embedding。那具体来说就是如果 x 乘以e,那在维度上其实就可以理解成是 196 乘以768,然后又乘了个 768 乘 768 的矩阵,然后这两个维度抵消掉,所以最后你得到的还是 196 乘768。意思就是我现在有 196 个token,每个 token 向量的维度是768
那到现在就其实已经成功的把一个 vision 的问题变成了一个 NLP 的问题。我的输入就是一系列 1D 的token,而不再是一张 2D 的图了。除了图像本身带来的这些 token 以外,我们之前也说过这里面要加一个额外的 CLS token,就是一个特殊的字符,那这个特殊字符它只有一个token,它的维度也是768,这样方便你可以和后面图像的信息直接拼接起来。所以最后序列的长度就是整体进入Transformer,这个序列长度其实是 196 + 1,就是 197 乘以 768 了,这 197 就是有 196 个图片对应的 token 和一个那个特殊字符 CRS token。
最后我们还要加上这些位置编码信息,那位置编码刚才我们说 123 一直到9,其实这只是一个序号,而并不是我们真正使用的位置编码,因为我们不可能把这个 1234 56这些数字然后传给一个 Transformer 去学。具体的做法是我们有一个表,这个表的每一行其实就代表了这里面的 1234 这个序号,然后每一行就是一个向量,这个向量的维度是多少跟这边是一样的,跟这边的 d 是一样的,是768,这个向量也是可以学的。
然后我们把这个位置信息加到这所有的这些 token 里面,注意这里面是加而不是拼接,就不是concatination,是直接sum。所以加完位置编码信息以后,这个序列还是 197 乘以768。
那到此我们就做完了整个对图片的这个预处理,包括加上特殊的字符 CLS 和加上这个位置编码信息。也就是说我们对于 Transformer 的输入,这块儿的 embedded patches 就是 197 * 768 的一个Tensor,而这个 Tensor 先过一个 layer known 出来,还是 197 乘768。
4.2多头自注意力
然后那我们就要做这个多头自注意力了,那多投资注意力这里就变成了三份KQV,每一个都是 197 * 768, 197 乘 768 这样的。那这里因为我们做的是多头自助力,所以其实最后的这个维度并不是768。假设说我们现在用的是 vision Transformer 的 base 版本,也就是说它用多头是用了 12 个头,那这个维度就变成了768,除以 12 也就等于 64 的维度,也就是说这里的 KQV 变成了 197 * 64, 197 * 64 这样,但是有 12 个头, 12 个对应的 KQV 去做这个自助力操作,然后最后再把这些 12 个头的输出直接拼接起来,这样 64 拼接出来以后又变成了768。
所以多头自注意力 出来的结果,经过拼接到这块还是 197 * 768,然后再过一层 layer norm 还是 197 乘798,然后再过一层MLP,这里会把维度先对应的放大,一般是放大 4 倍,所以说就是 197 乘以3072,然后再把它缩小投射回去,然后再变成 197 乘 768 就输出了。
这个就是一个 transfer block 的前向传播的过程,所以说进去是 197 乘 768 出来还是 197 乘768,这个序列的长度和每个 token 对应的维度大小都是一样的,所以说你就可以在一个 translora block 上不停地往上叠 transfer block,想加多少?那最后有 l 层这个 translora block 的模型,就是这个 transformer encoder,也就是这里面这个 Transformer encoder。
其实到这里就已经把 vision Transformer 这整个的模型讲完了,我们再回到正文,再快速的把三点儿一过一遍,看有没有什么遗漏的。他说标准的 Transformer 是需要一序列这个 1D 的 token 当做输入,那但是对于 2D 的图片怎么办?那我们就把这个图片打成这么多的小patch,具体有多少个patch,就是 n 等于这个 h w 除以 p 方,那其实也就是我们之前算过的 224 的平方除以 16 的平方,也就是196。当然这个是对于 patch size 16 而言了,如果你 patch size 变了,就变成 8 或者变成14,那对应的这里的这个序列长度也会相应改变。
说这个 transmer 从头到尾都是用了这个 d 当作向量的长度的,也就是我们刚才说的那个768,所以就是从头到尾它的向量长度都是768,这个维度是不变的。那为了和 Transformer 这个维度匹配上,所以说我们的这个图像的 patch 的维度也得是这个 d dimension,也就是 7 68。那具体怎么做?就是用一个可以训练的 Linear projection,也就是一个全连阶层,从全连接层出来的这个东西叫做 patch embedding,然后接着说为了最后的分类,我们借鉴了 Bert 里的这个 class token,一个特殊的 cl s token。这个 token 是什么呢?是一个可以学习的特征,它跟图像的特征有同样的维度,就都是768,但它只有一个token,就是经过很多层的这个 Transformer block 以后,我们把它这个输出当成是整个 Transformer 的模型的输出,也就是当做整个图片的这个特征。
那一旦有了这个图像特征了,后面就好做了,因为你卷积神经网络到这块也是有一个图像的整体的特征,那我们就在后面加一个这个 m l p 的这个分类头就可以了。然后对于位置编码信息这篇文章就用的是标准的,这个可以学习的 1 d positioning embedding,也就是 bert 里用的位置编码。那当然作者也尝试了别的编码形式了,就比如说因为你是做图片,所以你对空间上的位置可能更敏感,你可能需要一个 2D aware,就是能处理 2D 信息的一个这个位置编码,那最后发现了这个结果其实都差不多,没什么区别。
其实针对这个特殊的 class token 还有这个位置编码,作者们还做了详细的消融实验,因为对于 vision Transformer 来说,怎么对图片进行预处理,还有怎么对图片最后的输出进行后处理是很关键的,因为毕竟中间的这个模型就是一个标准的Transformer,没什么好讲的。所以我们现在就来看一下这些消融实验。
4.3消融实验:clstoken
首先我们说一下这个 class token,他说因为在这篇论文中,我们想跟原始的这个 Transformer 保持尽可能的一致,所以说我们也用了这个 class token。因为这个 class token 在 NLP 那边的分类任务里也是用的,在那边也是当作一个全局的对句子理解的一个特征,那在这里我们就是把它当做一个图像的整体特征。那拿到这个 token 的输出以后,我们就在后面接一个这个MLP,里面是用 ten h 当作一个非线性的激活函数去做这个分类的预测。
但是这个 class token 的设计是完全从 NRP 那边借鉴过来的,之前在视觉领域我们其实不是这么做的,比如说我们现在有一个残差网络,一个 rise 50,我们现在有这个前面的几个block, rise 2, rise 3、 rise 4、 rise 5,对吧?假如说是234,那在最后这个 stage 出来的是一个 feature map,这个 feature map 是 14 * 14,怎么的?然后在这个 feature map 之上,我们其实是做了一部这个 g a p 的操作,也就是他这里说的 global average pooling,就是一个全局的平均尺,化石化以后的特征其实就已经拉直了,就是一个向量了,这个时候我们就可以把这个向量理解成是一个全局的对于这个图片的一个特征,然后我们就拿这个特征去做分类。
那现在对于 Transformer 来说,如果你有一个 consumer 的model,而你进去有这么多 n 个元素,而你出来也是有这么多 n 个元素,我们为什么不能直接在这 n 个输出上去做一个这个 global average pulling,然后得到一个最后的特征?我们为什么非得在这个前面加一个 class token,然后最后用 class 的 token 去做输出,然后去做分类?那其实通过实验作者最后的结论是说,其实这两种方式都可以,就你也可以去做这个 global average pooling,得到一个全局的特征,然后去做分类,或者你用什么一个 class token 去做那 vision Transformer 这篇论文所有的实验都是用 class token 去做的,它主要的目的就是跟原始的这个 Transformer 保持尽可能的一致,就像他这里说的一样, say as close as possible。我不想让你觉得它这个效果好,有可能是因为某些 trick 带来的,或者是某些针对 CV 的改动而带来的。它就是想告诉你一个标准的 transformer 照样能做视觉。

那我们往下拉看,这张图里,其实这个绿线就代表这个全局平均池化,就是原来 vision 领域里怎么做的,然后这个 class token 就代表是 NLP 那边怎么做,就这条蓝线,那我们可以看到其实最后这个绿线和蓝线的效果是一样的,但是作者指出这个绿线和蓝线用的这个学习率是不一样的,就是你得好好调参。
如果你不好好调参,比如说直接把这个 class token 用的这个 learning rate 直接拿过来去做这个全局平均池化,那它效果是非常差的,只有这么多,可能大概低了五六个点,所以说有的时候也不是你的 idea 不work,可能主要还是参美调好,炼丹技术还是要过硬。
4.5消融实验:位置编码
我们再来看一下位置编码,它这里也做了很多这个消重实验,主要的其实就是这三种, 1D 的 2D 的,或者是这个 relative positioning bedding
1D 的,其实也就是 NRP 那边常用的一个位置编码,也就是这篇文章从头到尾都在使用的位置编码。
2D 的这个位置编码,它是这个意思,就是原来你 1D 那边,比如说你把一个图片打成九宫格,我们之前有的是123,你知道9,那我们现在与其用这种方式去表示那些图像块儿,我们用这种方式就是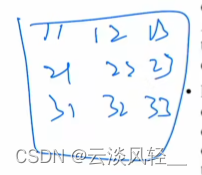 ,他去表示这么一个九宫格的图片,那这样是不是跟视觉问题就更贴近呢?因为它有了这个整体的这个 structure 信息,那具体是怎么做?就是说假如说原来的这种 ED 的这种位置编码,它的这个维度是d,那现在因为横坐标、纵坐标你都得需要去表示。 那对于横坐标来说,你有一个二分之 d 的维度,那对于纵坐标来说,一样你也有一个二分之 d 的维度,就是你分别有这么一个二分之 d 的这个向量去表述这个横坐标,然后还有一个二分之 d 的向量去描述这个纵坐标,最后你把这两个二分之 d 的向量拼接在一起, Concat 在一起就又得到了一个长度为 d 的这个向量。我们把这个向量叫做 2D 的位置编码。
,他去表示这么一个九宫格的图片,那这样是不是跟视觉问题就更贴近呢?因为它有了这个整体的这个 structure 信息,那具体是怎么做?就是说假如说原来的这种 ED 的这种位置编码,它的这个维度是d,那现在因为横坐标、纵坐标你都得需要去表示。 那对于横坐标来说,你有一个二分之 d 的维度,那对于纵坐标来说,一样你也有一个二分之 d 的维度,就是你分别有这么一个二分之 d 的这个向量去表述这个横坐标,然后还有一个二分之 d 的向量去描述这个纵坐标,最后你把这两个二分之 d 的向量拼接在一起, Concat 在一起就又得到了一个长度为 d 的这个向量。我们把这个向量叫做 2D 的位置编码。
那第三种这个相对位置编码是什么意思?就是说假如我们想还是 1D 的情况,那这个 patch 和这个 patch 的距离既可以用绝对距离来表示,又可以用它俩之间的这个相对距离来表示。就比如说它们现在之间差了 7 个单位距离,也就是它这里说的这个offset,这样也可以认为是一种方式去表示各个这个图像块之间的这个位置信息。
但是这个消融实验最后的结果也是无所谓,那我们现在来看它这个表 8 里说如果你不加任何的这个位置编码,那效果肯定是很差的,只有61,其实也不算很差, customer 根本没有感知这个图片位置的能力,那在没有位置编码的情况下,它还能达到这个 61 的效果,其实已经相当不错了。然后如果你来对比这个ED、 2D 和这个 relative 三种位置编码的形式,你会发现所有的这个 performance 都是64,就是没有任何区别。
这个现象其实还比较奇怪,作者在后面也给出了一个他们认为比较合理的解释,就是说他们这个 vision Transformer 是直接在这个图像块儿上去做的,而不是在原来的这个像素块儿上去做。因为这个图像块儿很小,比如说 14 * 14,而不是全局的那种 24 * 24,所以你去排列组合这种小块,或者你想知道这些小块之间相对的位置信息还是比较容易的,所以你用什么位置编码都无所谓。
那么现在从附录回到正文,刚才看了那些消融实验以后,我们也可以看出来,其实这个 class token 也可以用这个 global average pulling 去替换,包括最后的这个 1 d 的 positioning embedding,也可以用2 d 的或者相对的这种位置编码去替换。但是为了尽可能的对这个标准的 consumer 不做太多改动,所以说本文中 vision consumer 还是用了这个 class token,而且还是用了这个1D 的位置编码。
然后接下来就开始说这个 consumer encoder,那其实 Transformer 在现在来看已经是一个非常标准的操作了,那他这里对 consumer 或者说这个多投资质力的解释都没有放在正文里,直接就放在这个附录里了。就跟你看现在卷积神经网络的论文,也不会有人把卷积写在正文里。
4.6公式把整体的这个过程总结了一下
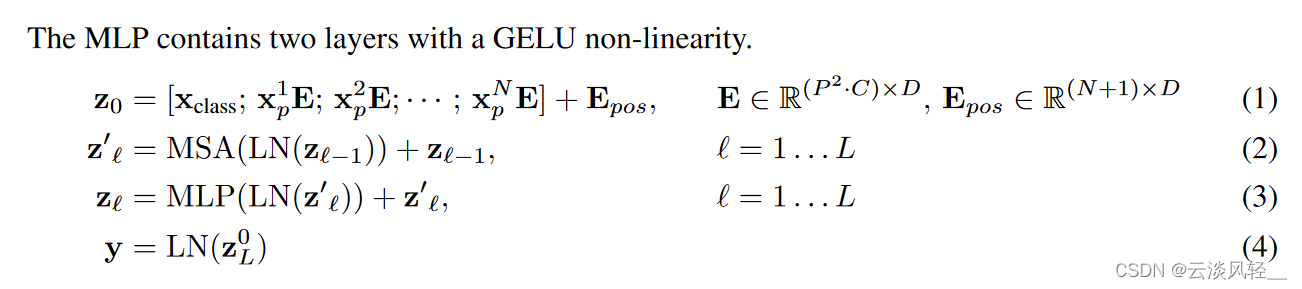
然后作者用公式把整体的这个过程总结了一下,就是说刚开始你这个X1P、X2P、XNP,其实就是这些图像块儿叫patch,然然后一共有 n 个patch,所以说 123 一直到n,那每个 patch 先去跟这个 Linear projection,也就是那个全连接层去做转换,从而得到这个 patch embedding。得到这些 patch embedding 之后,我们在它前面拼接一个这个 class embedding,因为我们需要用它去做最后的输出,而一旦得到所有的这个tokens,我们需要对这些 token 进行位置编码,所以说我们把这个位置编码信息加进去,这个就是对于整个 transform 的输入了, Z0 就是这个输入。
好,接下来这块就是一个循环,对于每一个 transfer block 来说,里面都有两个操作,一个是多头自助力,一个是MLP。然后在做这两个操作之前,我们都要先过layernor,然后每一层出来的结果都要再去有一个残差连接,所以说这个 ZL 一撇儿就是每一个多头自制力出来的结果,而这个 ZL 就是每一个 Transformer block 整体做完以后出来的结果。
然后我们这个 l 层循环完了之后,我们把 ZL 就是最后一层的那个输出的第一个位置上的 ZL 0,也就是这个 class token 所对应的输出,当做整体图像的一个特征,从而去做最后的这个分类人物。
4.7模型变体:混合模型
那所以到这儿对 vision Transformer 的文字描述也结束了,所以他就补了一些分析,比如说这个归纳偏置,然后又提出了一个模型的变体,叫做这个混合模型。最后在 3. 2 里又讲了讲当你遇到更大尺寸的图片的时候,你该怎么去做微调。那么先来看归纳偏置,他说 vision Transformer 比 CNN 而言要少很多这种图像特有的归纳偏置,那比如说在 CNN 里这个locality,还有这个 translation equivalents,这是这个局部性,还有这个平移等是在模型的每一层都有所体现的,这个先验知识相当于贯穿整个模型始终,但是对于 VIT 来说具有 MLP 这个 layer 是局部而且平移等边性的,但是自助于力层绝对是全局的。
这种图片 2D 的信息基本 VIT 没怎么用,其实也就是刚开始把图片切成 patch 的时候,还有就是加这个位置编码的时候用了,而除此之外就再也没有用任何针对视觉问题就针对图像的这个归纳片制了。而且这个位置编码说白了其实也是刚开始随机初始化的,并没有携带任何 2D 的信息,所有的关于这个图像块之间的这个距离信息,这个场景信息都得从头学,所以它这里也就是先给后面的结果做了个铺垫,就是说我 vision Transformer 没有用太多的这个归纳编制,所以说在中小数据集上进行预训练的时候,效果不如卷积神经网络是可以理解。
那讲完这个,那很自然的大家就会想,既然 transformer 这个全局建模的能力比较强,然后卷积神经网络又比较 data efficient,就不用那么多的训练数据,那我们是不是可以搞一个这个混合的网络?比如说前面是卷积神经网络,后面是Transformer,在它这里也做了对应的实验。具体来说就是原来你有一个图片,你把它打成patch,比如说打成 16 * 16 的patch,然后你得到了 196 个元素,然后这 196 个元素去和这个全连阶层去做一次操作,最后得到这个 patch embedding。 那现在我们不把图片打成块了,我们就按照卷积神经网络那样去处理图片,就是一整张图进来,然后我们把它给一个CNN,比如说一个残差网络 rise 50,那它最后的那个特征图出来是一个 14 * 14 的特征图,这个特征图刚好你把它拉直了以后,它也是 196 个元素,然后你用这新得到的这 196 个元素去跟这个全连接层去做操作,得到新的这种 patch embedding。那其实这里就是两种不同的对图片进行预处理的方式,一种就是直接把它打成patch,很简单,直接过全连接层。那另外一种就是还要再过一个CNN,然后得到这么 196 个序列长度,但是这得到的这个序列长度都是196,所以说后续的操作全都是一样的了,都是直接扔给一个transformer,然后最后做分类。
4.8微调
然后我们再来看 3. 2 为什么要把这个微调放在这个 section 3?是因为之前有工作说,如果你在微调的时候能用比较大的这个图像尺寸,就说不是用 224 * 224 了,而是用 256 * 256,甚至更大 320 * 320,那你就会得到更好的结果。那 vision consumer 肯定也不会放弃这个刷点的机会,他也想在更大的这个尺寸上去做微调,但是用一个预训练好的 vision consumer 其实是不太好去调整这个输入尺寸的。它这里说当你用更大尺寸的图片的时候,如果我们把 patch size 保持一样,就还用 16 * 16,但是你图片扩大了,那很显然你这个序列长度就增长了,对吧?你原来的这个序列长度是 N 1224 的平方,除以 16 的平方,那假如说你现在换成了 320 的图片,那就是 320 的平方除以 16 的平方,那对吧?序列长度肯定是增加了。
所以说 Transformer 从理论上来说,它是可以处理任意程度的,就只要硬件允许,任意程度都可以。但是你提前预训练好的这些位置编码有可能就没用了。因为你原来的位置编码,比如说 9 宫格的话,你是 1 到9,它是有明确的这个位置信息的意义在里面的。但是你现在图片变大了,如果保持 patch size 不变的话,你有可能得到 16 宫格 25 宫格,你的 patch 增多了,那你现在的位置信息就从 1 到25,而不是从 1 到 9 了。
那这个时候位置编码该如何使用?那他这里发现其实简单的做一个 2D 的插值就可以了,那在这里他们这个操作其实就是用 porch 官方自带的这个 interplay 的函数就能够完成。但是这里的差值也不是说可以想差多长就差多长,当你从一个很短的序列想要变到一个很长的序列的时候,比如说你从 256 到 562 甚至变到 768 更长的时候,直接这样一个简单的插值操作是会让最后的效果掉点的。所以说这里的差值其实只能说是一种临时的解决方案,它算是 vision Transformer 在微调的时候的一个局限性。
最后他说因为你用了这个图片的位置信息去做这个插值,所以尺寸改变,还有这个抽图像块儿,是 vision translora 里唯一的地方用了 2D 信息的这个归纳片制
5实验
接下来我们一起来读实验部分。他说在这个章节主要是对比了残差网络VIT,还有他们这个混合模型的这个表征学习能力。为了了解到底训练好每个模型需要多少数据,他们在不同大小的数据集上去做预训练,然后在很多的数据集上去做测试。当考虑到预训练的这个计算代价的时候,就是预训练的时间长短的时候, v 针传送表现得非常好,那在大多数据集上取得最好的结果,同时需要更少的时间去训练。最后作者还做了一个小小的实验,就做了一个自监督的实验,他说自监督涉实验的结果还可以,虽然没有最好。他说这个还是比较有潜力的,而事实上确实如此,时隔一年之后,最近大火的 MAE 就证明了自监督的方式去训练 VIT 确实效果很好。
数据集的使用方面,主要就是说用了这个 image net 数据集,它把这个有 1000 个类,就是大家最普遍使用的这个 1000 类的 Imagenet 数据集,叫做Imagenet,或者在很多别的论文里叫做 Imagenet one k,然后更大的那个集合 Imagenet 21K,有 21000 个类别,而且有 1400 万图片的那个数据集叫做 image net 21K, GFT 数据集就是 Google 自己的数据集,就是有那个 3 个亿的图片的数据集。它的下游任务全都做的是分类,也用的都是比较 popular 的数据集,比如说Safara, Oxford pet 和 Oxford flower 这些数据集,那接下来我们看一下模型的变体,它一共是三种模型,其实就是跟 Transformer 那边对应的,就是有base、 large 和huge,就是说对应的这些参数全都逐渐的变大。比如说用了更多的 transfer block,或者用了更长的这个向量维度,或者 MLP 的 size 变大,或者说多投资注意力的时候用了更多的投。
然后他接着正文里又补充了一些内容,因为它的模型不光跟这个 transfer 本身有关系,它还跟你这个输入有关系。当然这个 patch size 大小变化的时候,比如说从 16 * 16 变大变成 32 * 32,或者变小变成 8 * 8 的时候,这个模型的位置编码就不一样,所以 patch size 也要考虑到这个模型命名里面,于是他们模型命名的方式就是,比如 V i T L 16,意思就是说它用的是一个 VIT large 的模型,然后它的输入 patch size 是 16 * 16。
接着他又说这个 Transformer 的这个序列长度其实是跟你这个 patch size 成反比的,因为你 patch size 越小,那你切成的块儿就越多,你 patch size 越大,切成的块儿就越小。所以当模型用了更小的拍摄赛的时候,计算起来就会更贵。也就意味着,比如说你这个 V I T L 16,你要换成 V I T L 8 的话,那个 V I T L 8 的模型就要比这个 16 要贵很多,因为它的序列程度增加了。
5.1当它已经在大规模的数据集上进行预训练了,然后在这么多数据集上去做 fine tuning 时候得到的表现
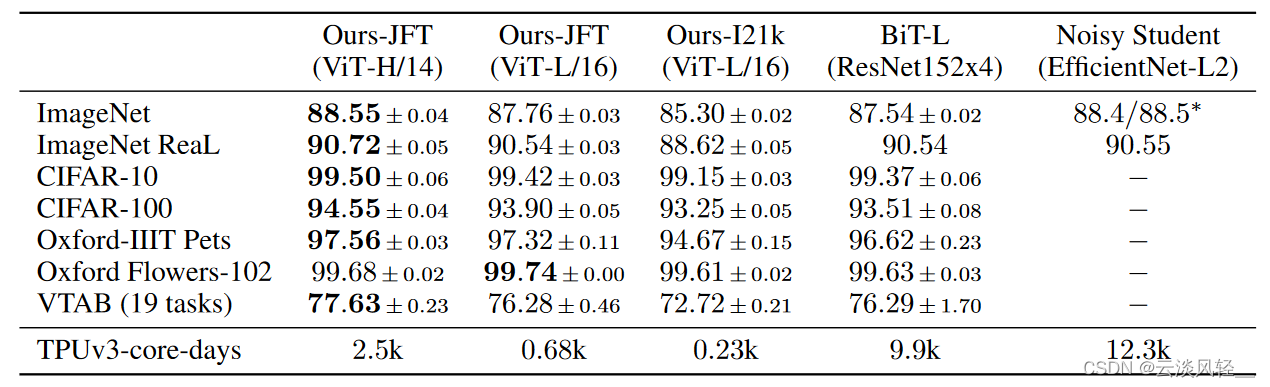
好,讲了这么多终于到可以看结果的时候了,这个表 2 是说当它已经在大规模的数据集上进行预训练了,然后在这么多数据集上去做 fine tuning 时候得到的表现。它这里相对比了几个 VIt 的变体,比如说 VIP 的 huge model 就是它最大的那个模型,放在这里是用来秀肌肉的,因为全都去取得了最好的结果。然后跟卷积神经网络那边,它就跟这个 BIT 和这个 noted student 做对比了。跟 BIT 做对比的原因是因为 BIT 确实是之前卷积神经网络里做的比较大的,而且也是因为是这个作者团队自己本身的工作,所以正好拿来可以比。所有之前做过的这些数据集 BIT 也都做过,那至于这个 noise student,是因为它是 image net 之前表现最好的方法,它用的方式是用 suitable label 去进行 self training,也就是我们常说的用这个尾标签也取得了很好的效果。
首先我们可以从这个表里看出来, VIT huge 这个模型,而且用比较小的拍摄在 14 就是相对更贵一点的模型,它能取得所有数据集上最好的结果。虽然说这里这个 99. 74 被黑体了,但跟 99. 68 也没差多少,但是因为这些数值,比如说这里这些数值都太接近了,都是差零点几个点或者一点几个点,没有特别大的差距,作者就觉得没有展示出 vision transform 的威力,所以作者就得从另外一个角度来凸显 VIT 的优点。
那他找了一个什么角度,他说因为我们训练起来更便宜,所以我们先来看他说的训练更便宜,是说他们最大的这个 VIT huge 的模型也只需要训练 2500 天, TPUV 三天数。正好这个 BIT 和 no ID student 也都是 Google 的工作,也都是用 TPUV 三训练的,所以刚好可以拿来比。那 BIT 是用了 9900 天, LID student 就更不得了,那用了 1 万多天。所以他说从这个角度上来说, VIT 不仅比你之前的这个 BIT 和 no ID student 要训练的快,而且效果还比你好。
5.2vit到底需要多少数据才能训练的比较好、分析训练成本
那这一下双重卖点,大家就会觉得 vision consumer 真的是比卷积神经网络要好。那在众多数据集上修完肌肉之后,接下来就该做一些分析了。那首先第一个分析,也就是最重要的 vision consumer 到底需要多少数据才能训练的比较好?那我们来看图3,这个图 3 应该是整个 vision consumer 论文最重要的, take home message 就是他最想让你知道的。其实这一张图基本就把所有的实验都概括了。
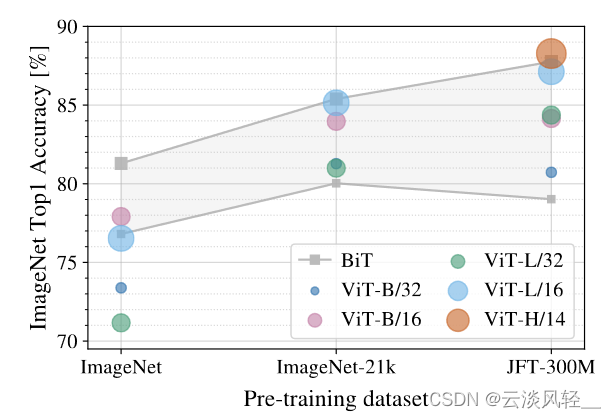
这张图的意思就是说当你使用不同大小的数据集的时候,比如说 Imagenet 是 1. 2 million,而这个的 21K 是 14 million,然后一直到最后 GFT 是 300 million。就是当你的数据集不断增大的时候,那 Resnet 和 VIT 到底在 Imagenet fine tuning 的时候效果如何?它这个图上点有点多,所以不太好看,但它的主要意思是说这个灰色代表BIT,也就是各种大小的这个Resnet,比如说这个下面应该就是个 Resso 50,而上面应该就是 152 啊,就是从最小的然后到最大的是有这么一个范围,那同样中间这样应该也是这是个50,这是个152。它这里想展示就是说在中间的这个灰色的区域,就是 Resnet 能达到的这个效果范围。那剩下的这些圆圈点了就是各种大小不一的 vision Transformer 了。
我们首先来看在最小的 Imagenet 上做预训练, Resnet 和 vision Transformer 的比较如何? vision Transformer 是全面不如 Resnet 的,因为 Resnet 这个效果范围在这儿,可是 vision 传送的基本所有的点都在这个范围之下,就是 vision Transformer 在中小型数据集上去做预训练的时候,它的效果是远不如残差网络的,原因就是因为 vision Transformer 没有用那些先验知识,没有用那些归纳偏执,最它需要更多的数据去让网络学的更好。
那接下来我们换到这个 image net 21K,用中间这一档的数据集去预训练,效果如何?我们会发现 Resnet 和 vision Transformer 就差不多了,它们的效果都是在这个范围里面。
只有当用特别大的数据集,用 3 个亿的图片数据集去做预训练的时候,我们可以发现 vision consumer 基本是全面超过 Resnet 了,因为你看 vision consumer 的范围在这儿,但是 Resnet 的范围在这儿。首先就是即使是最小的这个 VITB 32,就是这个蓝点也比这个 rise 50 高。其次就是当你用最大的模型就是 VITH 14 的时候,它是比 BIT 对应的 rise 152 还要高的。
那总之这个图其实只有两个信息,一个信息就是说如果你想用 vision Transformer,那你至少得准备差不多imagenet21k大小,如果你只有很小的数据集,那还是用卷积神经网络比较好。第二个点就是当你有规模比这个数据集更大的时候,用 vision consumer 应该能给你更好的结果,它的扩展性更好一些。
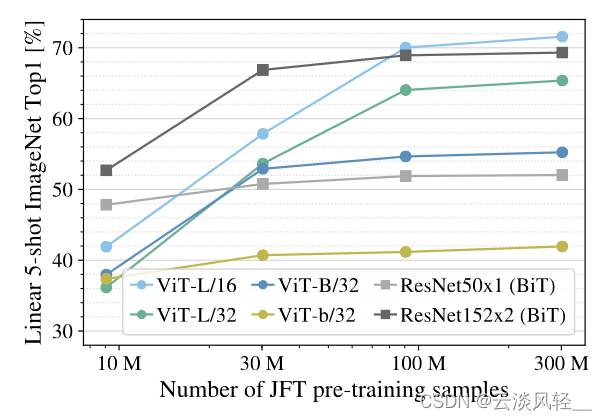
其实整篇论文讲的就是这个scaling。接下来作者又做了图4,原因是因为在图 3 的时候,他要用 vision consumer 去跟这个 Resnet 比,所以他还在训练的时候用了一些强约束,比如说用了 drop out,用了 wait a decay,用了 label smoothing,所以就不太好分析 vision Transformer 这个模型本身的一些特性。说在图 4 里,他做的是这个 Linear feel shot evaluation。这个 Linear evaluation 就是说我一旦拿到这个预训练的模型,我是直接把它当一个特征提取器,我不去 fine tuning,而是拿这些特征直接来做一个 logistic regression 就行了。同时他选了 few shot。然后在图里我们也看到了是 five shot,就是在 Imagenet 上,你去做这个 linear evaluation 的时候,每一类就随机选了 5 个sample,所以这个 evaluation 做起来是很快的,作者也就是用这种方式去做大量的消融实验。
那在图 4 里,这个横轴还是表示的这个预训练数据集的大小,这里它没有用别的数据集,它就用的是GFT,但是它取了一些 GFT 的子集,比如说这个 10 million, 30 million, 100 million 300 million 这样。因为所有的数据都是从一个数据集里来的,它就没有那么大的 distribution gap,那这样比较起来,模型的效果就更加能体现出模型本身的特质。
至于结果其实跟图 3 也是差不多的,就是说这条浅灰色的线是 rise 50,然后这条深灰色的线是 rise 152。用很小的预训练数据集的时候, vision Transformer 是完全比不过 Resnet 的文章里给出的解释,因为缺少归纳偏置那些约束的方法,比如说之前说的weight,decay,Labelle, smoothing 这些,所以就导致这里的 vision Transformer 容易过拟合,导致最后学到的特征不适合做其他任务。但是随着预训练数据集的增大, vision Transformer 的稳健性就上来了。但是因为这里的提升也不是很明显,所以说作者其实在这一段的最后也写了如何用 vision translora 去做这种小样本的学习,是一个非常有前途的方向。
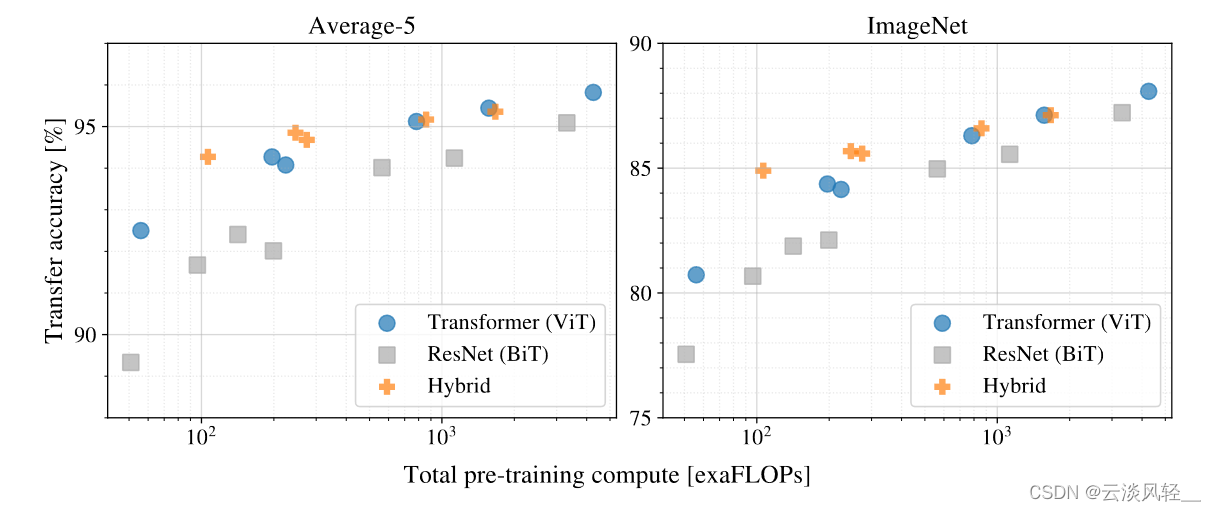
那么接下来看图5。由于 vision consumer 这篇论文之前说了它的预训练比用卷积神经网络要便宜,那它这里就得做更多的实验去支持它的这个论断,因为毕竟大家对 Translora 的印象都是说又大又贵,很难训练,那在图 5 里画了两个表,一个表,这个 average five 意思就是它是在五个数据集上去做了evaluation,然后把这个数字平均了,那这五个数据集分别是 image net real pets flowers、三份 20 和 seven 100。然后因为 image net 太重要了,所以说他把 image net 单独摘出来,然后又画了一张表,但其实这两张表的结果都差不多。
首先我们看图例说这样,这蓝色的这些圈都是VIt,然后这个灰色就是Resnet,然后这个橙色的加号就指的是混合模型,就是前面是卷积神经网络,后面是Transformer。但是图里各种大大小小的点,其实就是各种配置下大小不一样的这种卫生 translora 的变体,或者说是 Resnet 的变体。
这两张图里所有的模型都是在 GFT 300 million 这个数据集上去训练的,它的意思就是说它不想让模型的能力受限于数据集的大小,所以说所有的这些模型都在最大的数据集上去做预训练。好了,我们可以看到有几个比较有意思的现象。首先第一个现象就是说如果你拿蓝色这些圈儿,就是 VIT 去跟灰色这些 Resnet 比,你会发现在同等的计算复杂度的情况下,一般 Transformer 都是比 Resnet 要好的,这个就证明了他们所说的就是训练一个 vision Transformer 是要比训练一个卷积神经网络要便宜的。
第二个比较有意思的点,我们可以发现在比较小的模型上,这个混合模型的精度是非常高的,它比 vision Transformer 和对应的 Resnet 都要高,这个倒也没什么惊讶了,按道理来说这个混合模型就应该吸收了双方的优点,就是说既不需要很多的数据去预训练,同时又能达到跟 vision Transformer 一样的效果。但是比较好玩儿的就是说当随着这个模型越来越大的时候,这个混合模型慢慢的就跟 vision Transformer 差不多了,而且甚至还不如在同等计算条件下的一个 vision Transformer。这个还是比较有意思的,就为什么卷积神经网络抽出来的特征没有帮助 vision Transformer 去更好的学习,当然这里作者也没有做过多的解释,其实怎么预处理一个图像,怎么做这个 tokenization 是个非常重要的点,之后有很多论文都去研究了这个问题。
最后如果我们看这个整体趋势的话,就是随着这个模型不断的增加这个 vision translora 效果也在不停增加,并没有一个饱和的现象,那饱和的话就是说一般就增加到一个平台就不增加了,但是现在这个趋势还是在不停的往上走的。当然如果只从这个图里来看,其实除除了这个混合模型有点饱和之外,其实卷积神经网络的这个效果好像也没有饱和。
5.3可视化分析vit内部的表征
那分析完这个训练成本以后,作者就继续做了一些可视化,他希望通过这个可视化能够分析一下 VIT 内部的表征。
patch embedding
那如果要类似卷积神经网络那边,那第一个要看的那就是第一层到底学到了什么样的特征,那 vision consumer 的第一层就是那个 linear projection layer,也就是那个我们说的大一,那我们现在来看图7,就是展示了一下那个大 e 是如何 embed RGB valued,它这里只是展示了头 28 个主成分。

其实这个 vision Transformer 学到的跟卷积神经网络也很像,都是这种看起来像 GABOR filter 的这种就是有一些颜色,然后还有一些纹理。所以说作者说这些成分是可以当做这个基函数的,也就是说可以去描述每一个图像块的这种底层的结构。
positional embedding
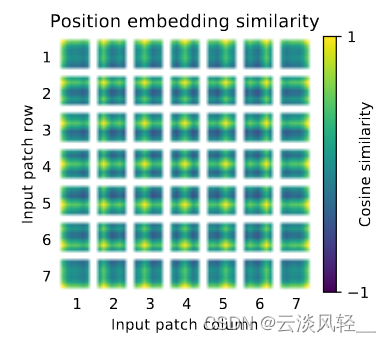
看完了 patch embedding,那接下来就要看一下这个 positional embedding 这个位置编码是怎样工作的。那我们再回来看图 7 中间的这个图,这个图就画的是这个位置编码的这个相似性,相似性越高就是一,相似性越低就是 -1,因为它做的是个 cosine 的similarity,它的横纵坐标就分别是对应的patch。那首先我们来看,如果是同一个patch,自己跟自己比,那这个相似性肯定是最高的。所以说对于 EE 这个 position 来说,那这个肯定黄色的点是在这儿的。
那接下来我们能观察到这个学到的位置编码真的是可以表示一些这个距离的信息的。比如说假如说我们看这个,那就说离中心点越近的地方它就会越黄,然后离中心点越远的地方它就会越蓝,也就意味着它的相似度越低,所以他已经学到了这个距离的概念了。同时我们还可以看到他还学到一些行和列之间的这个规则,比如说你看这个每一个都是同行同列的,这个相似度更高,同行同列对吧?同行同列也就意味着虽然它是一个 1D 的位置编码,但它已经学到了 2D 图像的这种距离的概念,所以作者在文中也说了,就这也可以解释为什么他们换成 2D 的配置编码以后并没有得到效果上的提升,是因为 1D 已经够用。
自注意力有没有起作用
最后作者就想看一下这个自助力到底有没有起作用,因为之所以大家想用consumer,就是因为自助力这个操作能够模拟长距离的关系。那在 NLP 那边就是说一个很长的句子里,开头的一个词和结尾的一个词也能互相有关联,那在图像里就是很远的两个像素点之间也能做自助于力。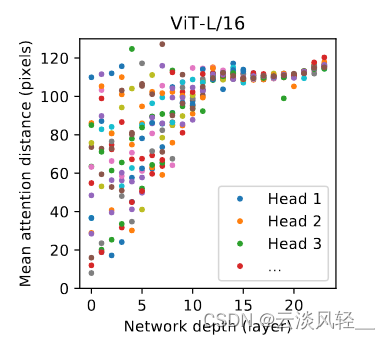
所以作者在这里只想看一下自助力到底是不是像期待的一样去工作的?那我们回到图7,看最右边的这张图,这张图画的是这个 VIP large 16 的这个模型,那 VIP large 有 24 层,所以说这个横坐标,这个网络深度这样就是从 0 到24,那这些五颜六色的点就是每一层的 Transformer block 里面的那个多头自助力的头。
那对于 VIT large 来说,我们一共有 16 个头,所以其实就是说每一列我们其实是有 16 个点的,它这里纵轴画的是一个叫 mean attention distance 的东西,就是平均注意力的距离,这个它是怎么定义的?假如说你图上有两个点a b,那这个 mean attention distance,假如说我们用 d 来表示,Dab =LAB*注意力权重:LAB就是这两个点之间真正的 Pixel 之间差的距离乘以它们之间的 attention weights。因为自注意力是全局在做,所以说每一个像素点跟每一个像素点都会有一个这个自助力权重,那这个平均注意力的距离的大小就能反映这个模型到底能不能注意到很远的两个Pixel。那这个图里的规律还是比较明显的。就假如说我们先看头几层,那头几层就是说有的自助力头注意的距离还是挺近的,就有可能 20 个Pixel,但是有的头能到 120 个Pixel。
所以这也就证明了自注意力真的能在网络最底层,就最刚开始的时候就已经能注意到全局上的信息了,而不是像卷积神经网络一样,刚开始第一层的 receptive field 非常小,就只能看到附近的这些Pixel,那随着网络越来越深,网络学到的这个特征也会变得越来越high, level 就是越来越具有语义信息。
所以说我们也看到了,大概就是网络的后半部分,它的这个自助力距离都非常远了,也就意味着他已经学到这个带有语义性的概念,而不是靠邻近的这个像素点去进行判断。

那为了验证这一点,作者优化另外一个图,就是图6,它这里面是用网络最后一层那个 output token 去做的这些图,发现如果用输出的 token 这个自制为例,折射回原来的这个输入图片,我们其实可以看到他真的学到了这些概念。比如说第一个里面这个狗,他其实就已经注意到这个狗了,这个飞机。
那作者最后一句话写,对于对于全局来说,因为你这个输出 token 是融合了所有的信息,是一个全局的特征。他们就发现模型已经可以关注到那些图像区域,哪些区域就是跟最后分类有关的区域。
5.4如何用自监督的方式去训练一个 vision Transformer
在文章的最后,作者还做了一个尝试,就是如何用自监督的方式去训练一个 vision Transformer。这篇论文其实如果算上附录的话,一共有 22 页,那在这么多结果中,作者把别的结果都放到了附录里,而把这个自监督放到了正文里,可见它的重要性。它之所以重要,是因为在 NLP 领域, Translora 这个模型确实起到了很大的推动作用,但另外一个真正让 Translora 能火起来,另外一个成功的因素其实是大规模的自监督训练,这两个是缺一不可的。
那之前我们说过 NRP 那边的这个自监督,无非就是完形填空或者预测下一个词。那因为这篇论文整体都仿照的是Bert,所以他就想说,我能不能也借鉴 Bert 的这个目标函数,去创建一个专属于 vision 的目标函数。那 Bert 呢?用的其实就是完形填空了,也就叫 mask 的 language modeling,就是一个句子给你,然后你把一些词 mask 掉,然后你通过一个模型,最后再去把它预测出来。那同样的道理,这篇论文就搞了一个 mask 的 patch prediction,意思就是说我有一张图片,然后已经画成 patch 了,这时候我把某些 patch 随机抹掉,通过这个模型以后,你再把这个 patch 给我重建出来。
这其实真的是很激动人心的,因为它不论是从模型上还是从目标函数上, CV 和 NLP 真的就做到大一统。但是他们这个模型他说最后,比如说 vit base 一个patch, SARS 16 的模型在 image net 上只能达到大概 80 的准确率。虽然相对于从头来训练这个微针transformer,它已经提高了两个点了,但是跟最好的这种就是监有监督的训练方式比是差了 4 个点。
然后作者说他把跟对比学习的结合当做是 mutual work 了,因为对比学习其实去年 CV 圈最火的一个 topic 是所有自监督学习方法里表现最好,所以紧接着 VIT MOCO V3 就出来了,还有 d no 也出来。这两篇论文都是用 contrast 的方式去训练了一个 vision Transformer。
总结
最后我们来回顾总结一下这篇 vision Transformer 的论文。这篇论文写的还是相当简洁明了的,它在有这么多内容和结果的情况下,做到了有轻有重,把最重要的结果都放在了正文里,图和表做的也都一目了然。
那从内容上来说, vision consumer 真的是挖了一个很大的坑,你可以从各个角度去分析它,或者提高它,或者推广它。比如说,如果从任务角度来说, vision Transformer 只做了分类,那接下来很自然的你就可以拿它去做检测、分割和甚至别的领域的任务。
那如果从改变结构的角度来说,你可以去改刚开始的tokenization,你也可以改中间的这个 transfer block,因为后来就已经有人把这个 self attention 换成MLP,且还是可以工作的很好。然后就在几天前,甚至有一篇论文叫 Meta former,他觉得 Transformer 真正 work 的原因是因为 Transformer 这个架构,而不是某些特殊的算子,所以他就把这个 self attention 直接换成了一个迟化操作,然后他发现用一个甚至不能学习的池化操作,也就是他提出这个 pull former 的这个模型也能在视觉领域取得很好的效果,所以说在模型的改进上也大有可为。
而如果从目标函数来讲,那就更是了,你可以继续走,有监督,然后也可以尝试很多不同的这个自监督训练的方式。
最后更重要的是,它打通了 CV 和 LP 之间的鸿沟,挖了一个更大的多模态的坑。那接下来大家还可以用它去做视频,去做音频,甚至还可以去做一些基于 touch 的这种信号,就各种 modelity 的信号都可以拿来用。
在我看来,卷积自注意力或者 MLP 究竟鹿死谁手还有未可知。我是很期待下一个即将出现的一个改进版的 fashion Transformer,它有可能真的就是一个简洁、高效、通用的视觉骨干网络,而且可以完全不用任何标注信息。
这篇关于逐字稿 | 1 ViT论文逐段精读【论文精读】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


