逐段专题

BERT 论文逐段精读【论文精读】
BERT: 近 3 年 NLP 最火 CV: 大数据集上的训练好的 NN 模型,提升 CV 任务的性能 —— ImageNet 的 CNN 模型 NLP: BERT 简化了 NLP 任务的训练,提升了 NLP 任务的性能 BERT 如何站在巨人的肩膀上的?使用了哪些 NLP 已有的技术和思想?哪些是 BERT 的创新? 1标题 + 作者 BERT: Pre-trainin
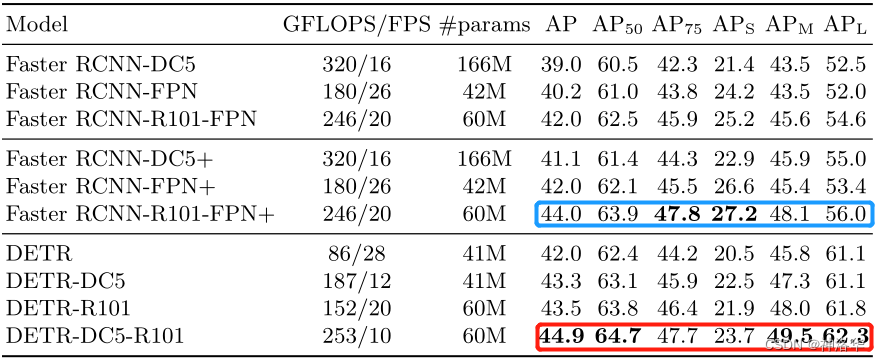
【论文阅读】DETR 论文逐段精读
【论文阅读】DETR 论文逐段精读 文章目录 【论文阅读】DETR 论文逐段精读📖DETR 论文精读【论文精读】🌐前言📋摘要📚引言🧬相关工作🔍方法💡目标函数📜模型结构⚙️代码 📌实验 参考跟李沐学AI: 精读DETR 📖DETR 论文精读【论文精读】 🌐前言 目标检测领域:从目标检测开始火到 detr 都很少有端到端的方法,大部分方法最后至少

中长期水文预报——逐段回归法
原始数据: 年份 x1 x2 x3 x4 预报对象y 1955 26.4 29.1 4.1 5.8 3467 1956 27.6 28.8 12.3 6 2622 1957 29.1 30 5.8 8 1880 1958 29 28.7 7.3 7.8 1997 1959 29.4 27.8 11.1 5.3 2615
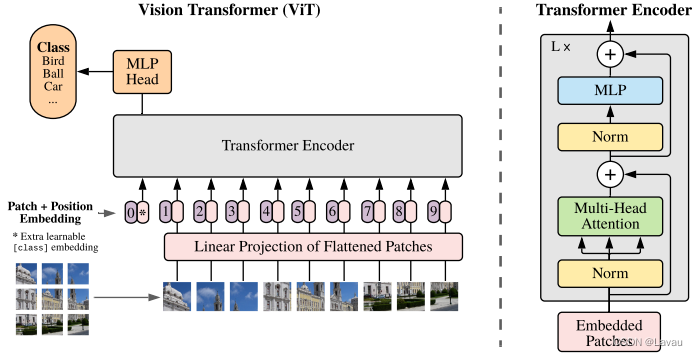
ViT 论文逐段精读——B站up:跟李沐学AI讲解笔记
https://www.bilibili.com/video/BV15P4y137jb Vision Transformer 挑战了 CNN 在 CV 中绝对的统治地位。Vision Transformer 得出的结论是如果在足够多的数据上做预训练,在不依赖 CNN 的基础上,直接用自然语言上的 Transformer 也能 CV 问题解决得很好。Transformer 打破了 CV、NLP 之

逐字稿 | 1 ViT论文逐段精读【论文精读】
目录 标题 摘要 1引言 1.1把 Transformer 用到视觉问题上的一些难处 1.2受到transformer可扩展性的启发,要用一个标准的transformer处理视觉问题,序列长度怎么办? 最相似的过往工作 2结论 3相关工作 4方法 4.1整个对图片的这个预处理:包括加上特殊的字符 CLS 和加上这个位置编码信息,也就是 Transformer 的输入 4.2多

逐字稿 | 5 CLIP 论文逐段精读【论文精读】
https://space.bilibili.com/511378644 目录 1评价 2 CLIP的模型 总览图 2.1clip是如何进行预训练的呢? 2.2CLIP如何做zero-shot推理? 其他基于clip的有趣的应用。 3标题:利用来自nlp的监督信号去学习一个迁移效果很好的视觉模型 4摘要 5引言 NLP效果非常好的框架:文本进文本出+利用自监督信号训练整个

【论文视频】MoCo 论文逐段精读. CVPR 2020 zui佳论文提名【论文精读】
文章目录 1. 四个问题2. 视频正文什么是对比学习?论文内容1. 题目和作者2. 摘要3. 引言4. 结论5. 相关工作6. MoCo方法7. 实验8. 总结 3. 参考资料 1. 四个问题 解决什么问题 做无监督的表征学习 用什么方法解决 本文提出了MoCo去做无监督的表征学习,虽然是基于对比学习的,但是本文是从另外一个角度来看对比学习,也就是说把对比学习看作是一个
ViT论文逐段精读【论文精读】
如果说过去一年中在计算机视觉领域哪个工作的影响力最大,那应该非 vision consumer 莫属了,因为它挑战了自从 2012 年 Alexnet 提出以来卷积神经网络在计算机视觉领域里绝对统治的地位。它的结论就是说,如果在足够多的数据上去做预训练,那我们也可以不需要卷积神经网络,直接用一个从自然预言处理那边搬过来的标准的 transmer 也能把视觉问题解决得很好。

CLIP 论文逐段精读【论文精读】
00:06评价 评价:工作clip呢自从去年2月底提出就立马火爆全场,他的方法出奇的简单,但是效果呢又出奇的好,很多结果和结论呢都让人瞠目结舌。比如呢作者说clip的这个迁移学习能力是非常强的,它预训好的这个模型能够在任意一个视觉分类的这个数据集上,取得不错的效果,而且最重要的是它是zero shot的,意思就是说他完全没有在这些数据集上去做训练,就能得到这么高的效果,作者这里