本文主要是介绍【论文阅读】DETR 论文逐段精读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文阅读】DETR 论文逐段精读
文章目录
- 【论文阅读】DETR 论文逐段精读
- 📖DETR 论文精读【论文精读】
- 🌐前言
- 📋摘要
- 📚引言
- 🧬相关工作
- 🔍方法
- 💡目标函数
- 📜模型结构
- ⚙️代码
- 📌实验
参考跟李沐学AI: 精读DETR
📖DETR 论文精读【论文精读】
🌐前言
目标检测领域:从目标检测开始火到 detr 都很少有端到端的方法,大部分方法最后至少需要后处理操作(NMS, non-maximum suppression 非极大值抑制)。有了 NMS,模型调参就会很复杂,而且即使训练好了一个模型,部署起来也非常困难(NMS 不是所有硬件都支持)。
📋摘要
贡献:把目标检测做成一个端到端的框架,把之前特别依赖人的先验知识的部分删掉了(NMS 部分、anchor)。
DETR提出:
- 新的目标函数,通过二分图匹配的方式,强制模型输出一组独一无二的预测(没有那么多冗余框,每个物体理想状态下就会生成一个框)
- 使用 encoder-decoder 的架构
两个小贡献:
- decoder 还有另外一个输入
learned object query,类似 anchor 的意思
(给定这些object query之后,detr就可以把learned object query和全局图像信息结合一起,通过不同的做注意力操作,从而让模型直接输出最后的一组预测框) - 想法&&实效性:并行比串行更合适
DETR 的好处:
- 简单性:想法上简单,不需要一个特殊的 library,只要硬件支持 transformer 或 CNN,就一定支持 detr
- 性能:在 coco 数据集上,detr 和一个训练非常好的 faster RCNN 基线网络取得了差不多的效果,模型内存和速度也和 faster RCNN 差不多
- 想法好,解决了目标检测领域很多痛点,写作好
- 别的任务:全景分割任务上 detr 效果很好,detr 能够非常简单拓展到其他任务上
📚引言
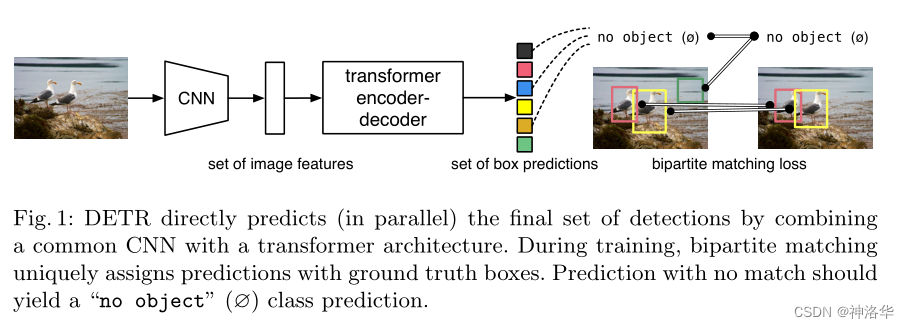
DETR 流程(训练):
- CNN 提特征
- 特征拉直,送到 encoder-decoder 中,encoder 作用:进一步学习全局信息,为近下来的 decoder,也就是最后出预测框做铺垫。
- decoder 生成框的输出,当你有了图像特征之后,还会有一个 object query(限定了你要出多少框),通过 query 和特征在 decoder 里进行自注意力操作,得到输出的框(文中是100,无论是什么图片都会预测100个框)
- loss :二分图匹配,计算100个预测框和2个 GT 框的 matching loss,决定100个预测框哪两个是独一无二对应到红黄色的 GT 框,匹配的框去算目标检测的 loss
推理:
1、2、3一致,第四步 loss 不需要,直接在最后的输出上用一个阈值卡一个输出的置信度,置信度比较大(>0.7的)保留,置信度小于0.7的当做背景物体。
🧬相关工作
让 DETR 成功主要原因:transformer
🔍方法
分两块:1、基于集合的目标函数怎么做,作者如何通过二分图匹配把预测的框和 GT 框连接在一起,算得目标函数 2、detr 具体模型架构
💡目标函数
DETR模型最后输出是一个固定集合,无论图片是什么,最后都会输出 n 个(本文 n=100)
问题:detr 每次都会出 100 个输出,但是实际上一个图片的 GT 的 bounding box 可能只有几个,如何匹配?如何计算 loss?怎么知道哪个预测框对应 GT 框?
匈牙利算法是解决该问题的一个知名且高效的算法,能够以较低的复杂度得到唯一的最优解。
在 scipy 库中,已经封装好了匈牙利算法,只需要将成本矩阵(cost matrix)输入进去就能够得到最优的排列。在 DETR 的官方代码中,也是调用的这个函数进行匹配(from scipy.optimize import linear_sum_assignment)。
从N个预测框中,选出与M个GT Box最匹配的预测框,也可以转化为二分图匹配问题,这里需要填入矩阵的“成本”,就是每个预测框和GT Box的损失。对于目标检测问题,损失就是分类损失和边框损失组成。
所以整个步骤就是:
- 遍历所有的预测框和 GT Box,计算其 loss。
- 将 loss 构建为 cost matrix,然后用 scipy 的
linear_sum_assignment(匈牙利算法)求出最优解,即找到每个 GT Box 最匹配的那个预测框。 - 计算最优的预测框和 GT Box 的损失。(分类+回归)
但是在 DETR 中,损失函数有两点小改动:
- 去掉分类损失中的 log
- 回归损失为 L1 loss+GIOU
📜模型结构

下面参考官网的一个 demo,以输入尺寸3×800×1066为例进行前向过程:
- CNN 提取特征(
[800,1066,3]→[25,34,256])
backbone 为 ResNet-50,最后一个 stage 输出特征图为 25×34×2048(32 倍下采样),然后用 1×1 的卷积将通道数降为 256; - Transformer encoder 计算自注意力(
[25,34,256]→[850,256])
将上一步的特征拉直为 850×256,并加上同样维度的位置编码(Transformer 本身没有位置信息),然后输入的 Transformer encoder 进行自注意力计算,最终输出维度还是 850×256; - Transformer decoder 解码,生成预测框
decoder 输入除了 encoder 部分最终输出的图像特征,还有前面提到的 learned object query,其维度为100×256。在解码时,learned object query 和全局图像特征不停地做 across attention,最终输出100×256的自注意力结果。
这里的 object query 即相当于之前的 anchor/proposal,是一个硬性条件,告诉模型最后只得到 100 个输出。然后用这 100 个输出接 FFN 得到分类损失和回归损失。 - 使用检测头输出预测框
检测头就是目标检测中常用的全连接层(FFN),输出 100 个预测框( h x c e n t e r , y c e n t e r , w , h h x_{center}, y_{center}, w, h hxcenter,ycenter,w,h )和对应的类别。 - 使用二分图匹配方式输出最终的预测框,然后计算预测框和真实框的损失,梯度回传,更新网络。
除此之外还有部分细节:
- Transformer-encode/decoder 都有 6层
- 除第一层外,每层 Transformer encoder 里都会先计算 object query 的 self-attention,主要是为了移除冗余框。这些 query 交互之后,大概就知道每个 query 会出哪种框,互相之间不会再重复(见实验)。
- decoder 加了 auxiliary loss,即每层 decoder 输出的 100×256 维的结果,都加了 FFN 得到输出,然后去计算 loss,这样模型收敛更快。(每层 FFN 共享参数)
⚙️代码
import torch
from torch import nn
from torchvision.models import resnet50class DETR(nn.Module):def __init__(self, num_classes, hidden_dim, nheads,num_encoder_layers, num_decoder_layers):super().__init__()# We take only convolutional layers from ResNet-50 modelself.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])self.conv = nn.Conv2d(2048, hidden_dim, 1) # 1×1卷积层将2048维特征降到256维self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)self.linear_class = nn.Linear(hidden_dim, num_classes + 1) # 类别FFNself.linear_bbox = nn.Linear(hidden_dim, 4) # 回归FFNself.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # object query# 下面两个是位置编码self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))def forward(self, inputs):x = self.backbone(inputs)h = self.conv(x)H, W = h.shape[-2:]pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),], dim=-1).flatten(0, 1).unsqueeze(1) # 位置编码h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),self.query_pos.unsqueeze(1))return self.linear_class(h), self.linear_bbox(h).sigmoid()detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
📌实验
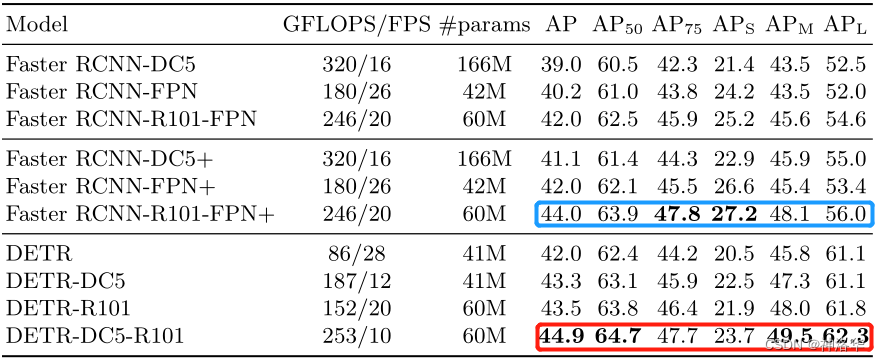
- 最上面一部分是 Detectron 2 实现的 Faster RCNN ,但是本文中作者使用了很多 trick
- 中间部分是作者使用了 GIoU loss、更强的数据增强策略、更长的训练时间来把上面三个模型重新训练了一次,这样更显公平。重新训练的模型以+表示,参数量等这些是一样的,但是普偏提了两个点
- 下面部分是 DETR 模型,可以看到参数量、GFLOPS 更小,但是推理更慢。模型比 Faster RCNN 精度高一点,主要是大物体检测提升 6 个点 AP,小物体相比降低了 4个点左右。
这篇关于【论文阅读】DETR 论文逐段精读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
