本文主要是介绍Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 虎嗅网文章数据----写在前面
今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流使用,切勿用作其他用途。
常规操作,分析待爬取的页面
拖拽页面到最底部,会发现一个加载更多按钮,点击之后,抓取一下请求,得到如下地址
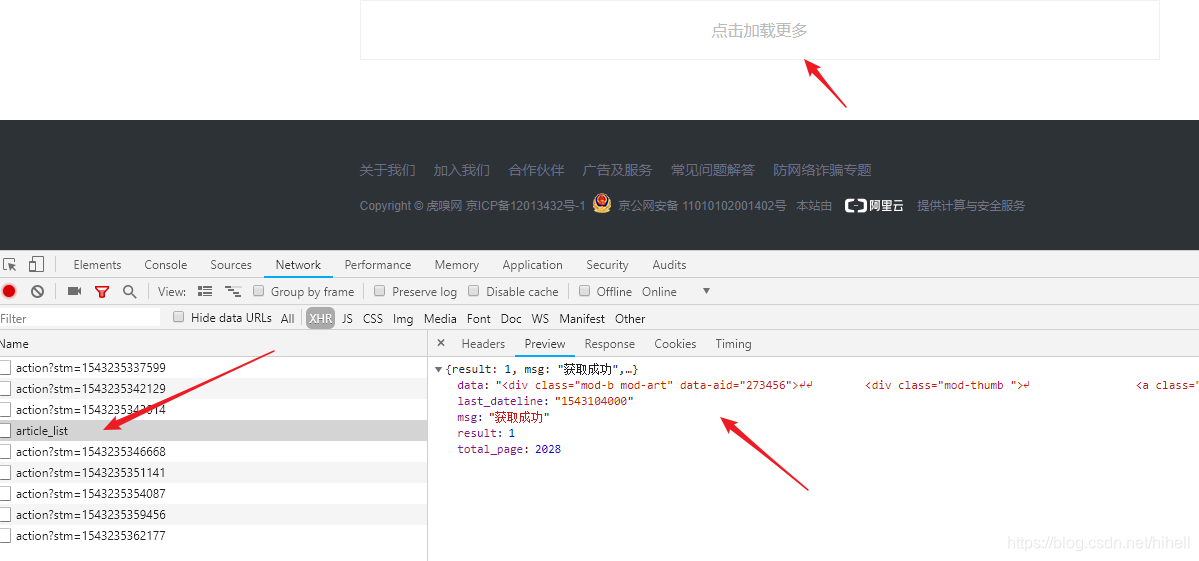
2. 虎嗅网文章数据----分析请求
查阅该请求的方式和地址,包括参数,如下图所示
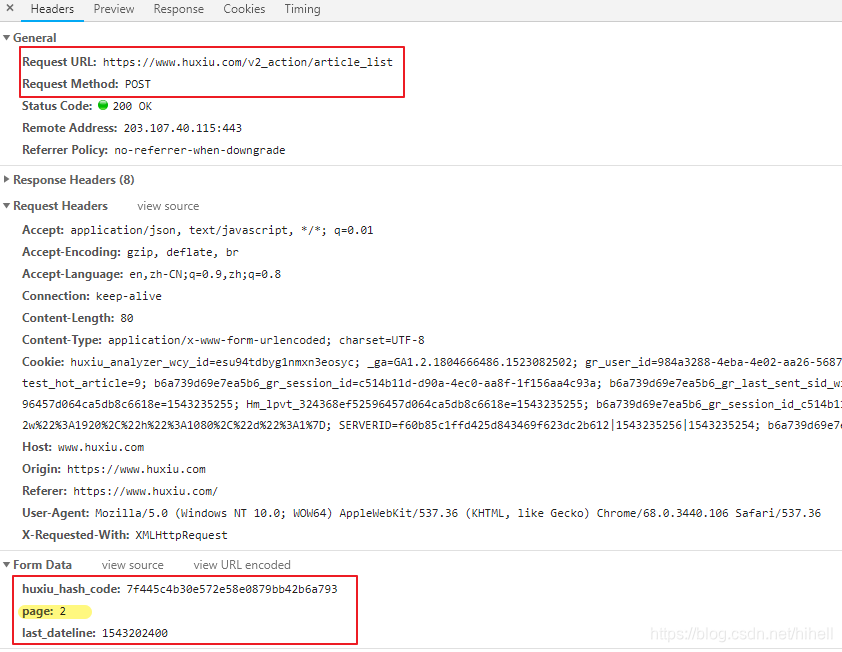
得到以下信息
- 页面请求地址为:
这篇关于Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




