pyspider专题
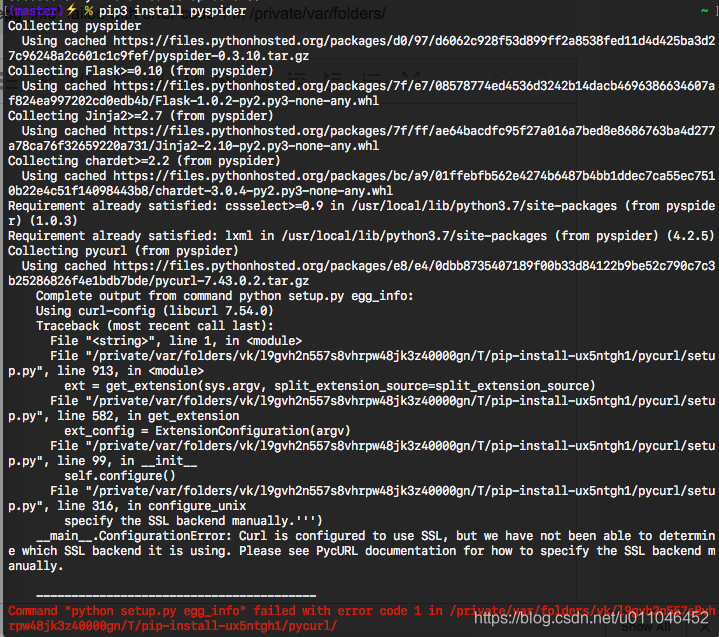
Mac下安装pyspider报了Command python setup.py egg_info failed with error code 1 in /private/var/folders/
复制以下代码到终端执行: pip3 uninstall pycurlexport PYCURL_SSL_LIBRARY=openssl export LDFLAGS=-L/usr/local/opt/openssl/lib export CPPFLAGS=-I/usr/local/opt/openssl/includepip3 install pycurl --compile --no-ca

kubernetes集群创建pyspider爬虫系统
kubernetes集群部署pyspider分布式爬虫系统 基础 1. 已安装、配置kubernetes 2. 集群中有pyspider与mysql容器镜像 3. 有docker基础 具体步骤 部署mysql 部署redis 部署pyspider相关部件 我们想要在kubernetes集群中配置mysql服务,首先要保证集群中的节点上有mysql镜像,镜像可以从docker Hub

docker分布式部署pyspider爬虫系统
阅读准备 docker基础命令,docker-compose基础pyspider基础 如果您不熟悉上面的内容,可以先网上查阅有关资料。 1. 创建网络接口 首先,创建一个Driver为bridge的网络接口,命名为pyspider:docker network create --driver bridge pyspider 说明1: 需要创建该网络接口的原因是:在下面创建Docker容器
2024Windows11最新安装pyspider
1、创建conda虚拟环境 conda create -n _pyspider python==3.6虚拟环境建好后会自动有 wheel库 2、配置phantom浏览器 参考phantom安装 3、conda安装pycurl conda install pycurl 4、一次性安装各种依赖 requirements.txt内容如下: Flask==0.10Jinja2==2.

使用PySpider进行IP代理爬虫的技巧与实践
目录 前言 一、安装与配置PySpider 二、使用IP代理 三、IP代理池的使用 四、处理代理IP的异常 五、总结 前言 IP代理爬虫是一种常见的网络爬虫技术,可以通过使用代理IP来隐藏自己的真实IP地址,防止被目标网站封禁或限制访问。PySpider是一个基于Python的强大的开源网络爬虫框架,它使用简单、灵活,并且具有良好的扩展性。本文将介绍如何使用PySpider

Centos 安装pyspider 必须成功
Centos安装pyspider踩过的坑!!!一个接着一个 写在前面的话: 一直在本地机器小玩玩pyspider,今天心血来潮linux安排上。。。网上教程一大堆,一个接着一个坑。特此记录错误过程与解决方案,注重解决问题,直接上命令。 pip3 install pyspider 错误 No.1 Command "python setup.py egg_info" faile

python 3.7下安装pyspider的错误
成功将pyspider安装完成后,运行发现出错 因为python3.7中async设成了关键字,原作者使用了这参数导致有语法错误 所以有两种方法解决这个问题: 第一种降低python版本(这种一般不考虑) 第二种修改pyspider中的async 修改的地方有3个 ...\Python\Python37\Lib\site-packages\pyspider这

Python pyspider 安装与开发
PySpider 简介 PySpider是一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器、任务监视器,项目管理器以及结果查看器。 PySpider 来源于以前做的一个垂直搜索引擎使用的爬虫后端。我们需要从200个站点(由于站点失效,不是都同时啦,同时有100+在跑吧)采集数据,并要求在5分钟内将对

对于Pyspider爬虫框架你知道多少?
Pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。 主要功能需求: 1、抓取,更新调度多站点的特定的页面 2、需要对页面进行结果化信息的提取 3、灵活可扩展,稳定可监控 Pyspider设计基础:
安装 pyspider 遇到的常见报错问题解决
场景:windows 下 安装pyspider 安装环境 win10 64位 python版本: 3.8.1 pyspider版本:0.3.10 问题1:提示async 关键字问题 这个是网上答案比较多的一个问题,主要是python版本在3.5以后,将async 和 await 作为了关键字导致 File “c:\users\one\appdata\local\programs\
个人知乎 ##基础九——爬虫入门PySpider
个人知乎 基础九——爬虫入门PySpider 爬虫基础框架 安装:pip install pyspiderscheduler:调度器,调度一个url处理fetcher:下载网页器processor:处理网页器,并解析出新的url class Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_sta

pyspider框架使用方法——以爬取樱花动漫网为例。
本篇文章内容: 1.pyspider框架使用方法 2.爬取樱花动漫网url,存到数据库。 3.源代码。 1.pyspider框架使用方法 安装和配置的过程,就不介绍了。参考官方文章。 如果你是在window下安装就直接下载源码就好。gthub源码。 安装好后运行,在linux下命令行执行 python3 run.py window下运行安装包的 run.py 如果在命令行下反馈没有报错,

pyspider 简单应用之快速问医生药品抓取(一)
网址:http://yp.120ask.com/search/-0-0--0-0-0-0.html from pyspider.libs.base_handler import *class Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_start(self):#进入主页self.crawl('http:

解决安装pyspider失败:Command python setup.py egg_infofailed with error code 10 in.....
最近在学习python3爬虫,今天学到pyspider了,然后就在win7的系统下安装pyspider,结果出现了一连串的错误 首先我用pip3 install pyspider命令进行安装,结果出现pip的版本太低 然后,我就用命令 python3 -m pip install -- upgrade pip 对pip管道升级,升级后的版本是pip -18.0 接着用pi

【pyspider】爬取ajax请求数据(post),如何处理python2字典的unicode编码字段?
情景:传统的爬虫只需要设置fetch_type=js即可,因为可以获取到整个页面。但是现在ajax应用越来越广泛,所以有的网页不能用此种爬虫类型来获取页面的数据,只能用slef.crawl()来发起http请求来抓取数据。 直接上例子: 可以看到,该网页的每一页的数据是通过ajax请求获取到的,方式为POST,所以不能用传统方法。 可以看到该请求的请求体,我们需要把请求体和请求方法写到cra
【pyspider】爬取ajax请求数据(post),如何处理python2字典的unicode编码字段?
情景:传统的爬虫只需要设置fetch_type=js即可,因为可以获取到整个页面。但是现在ajax应用越来越广泛,所以有的网页不能用此种爬虫类型来获取页面的数据,只能用slef.crawl()来发起http请求来抓取数据。 直接上例子: 可以看到,该网页的每一页的数据是通过ajax请求获取到的,方式为POST,所以不能用传统方法。 可以看到该请求的请求体,我们需要把请求体和请求方法写到cra
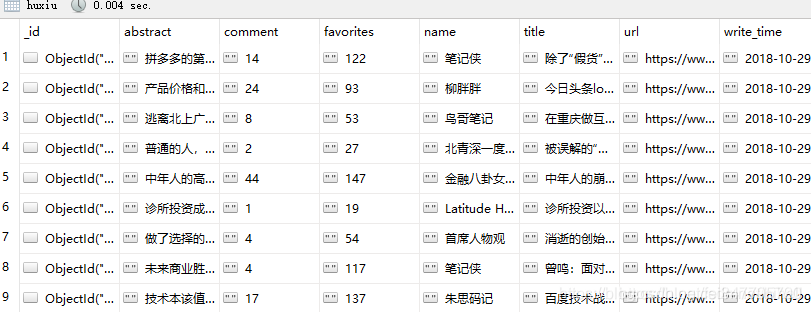
pyspider抓取虎嗅网文章数据
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流使用,切勿用作其他用途。 常规操作,分析待爬取的页面 拖拽页面到最底部,会发现一个加载更多按钮,点击之后,抓取一下请求,得到如下地址 2. 虎嗅网文章数据----分析请求 查阅该请求的方式
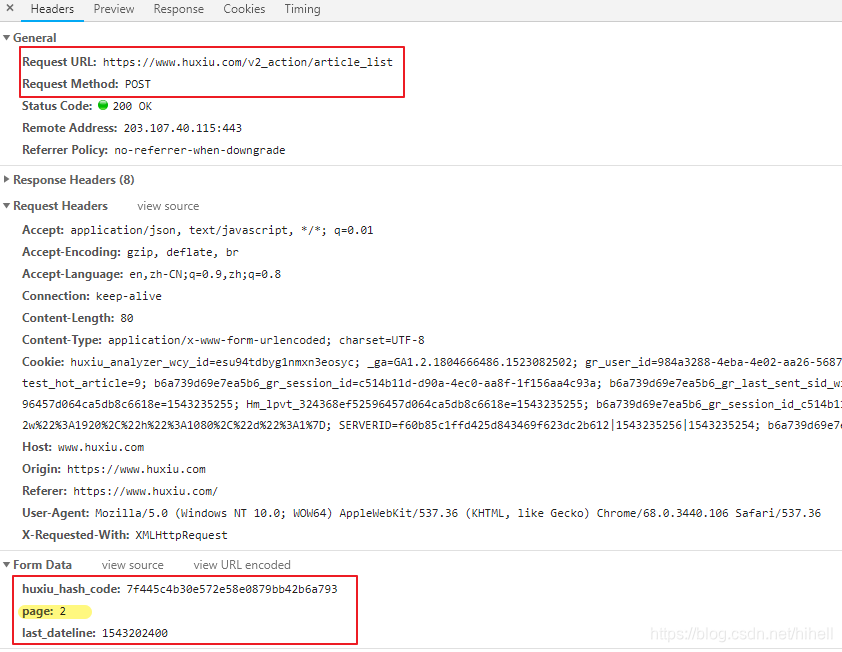
Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流使用,切勿用作其他用途。 常规操作,分析待爬取的页面 拖拽页面到最底部,会发现一个加载更多按钮,点击之后,抓取一下请求,得到如下地址 2. 虎嗅网文章数据----分析请求 查阅该请求的方

pyspider爬虫框架之宝宝树需求
1 需求和分析 最近在做爬取宝宝树网站上商品信息的需求,原本以为很简单,没想到反爬还挺严重,研究了两天,发现有几个参数是经过JS加密的。通过分析,获取网站上的数据,需要constId这个请求参数,然而这个constId是经过三次网络请求得到的一个参数,最后一个请求是得到这个参数的关键请求,但是它依赖前两个请求,这几个请求的关键在于请求头里的“Param”参数,如下图所示: 通过查看ne