本文主要是介绍pyspider抓取虎嗅网文章数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 虎嗅网文章数据----写在前面
今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流使用,切勿用作其他用途。
常规操作,分析待爬取的页面
拖拽页面到最底部,会发现一个加载更多按钮,点击之后,抓取一下请求,得到如下地址

2. 虎嗅网文章数据----分析请求
查阅该请求的方式和地址,包括参数,如下图所示

得到以下信息
- 页面请求地址为:https://www.huxiu.com/v2_action/article_list
- 请求方式:POST
- 请求参数比较重要的是一个叫做page的参数
我们只需要按照上面的内容,把pyspider代码部分编写完毕即可。
on_start 函数内部编写循环事件,注意到有个数字2025这个数字,是我从刚才那个请求中看到的总页数。你看到这篇文章的时候,这个数字应该变的更大了。
@every(minutes=24 * 60)def on_start(self):for page in range(1,2025):print("正在爬取第 {} 页".format(page))self.crawl('https://www.huxiu.com/v2_action/article_list', method="POST",data={"page":page},callback=self.parse_page,validate_cert=False)
页面生成完毕之后,开始调用parse_page 函数,用来解析 crawl() 方法爬取 URL 成功后返回的 Response 响应。
@config(age=10 * 24 * 60 * 60)def parse_page(self, response):content = response.json["data"]doc = pq(content)lis = doc('.mod-art').items()data = [{'title': item('.msubstr-row2').text(),'url':'https://www.huxiu.com'+ str(item('.msubstr-row2').attr('href')),'name': item('.author-name').text(),'write_time':item('.time').text(),'comment':item('.icon-cmt+ em').text(),'favorites':item('.icon-fvr+ em').text(),'abstract':item('.mob-sub').text()} for item in lis ] return data
最后,定义一个 on_result() 方法,该方法专门用来获取 return 的结果数据。这里用来接收上面 parse_page() 返回的 data 数据,在该方法可以将数据保存到 MongoDB 中。
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''# 页面每次返回的数据 def on_result(self,result):if result:self.save_to_mongo(result) # 存储到mongo数据库def save_to_mongo(self,result):df = pd.DataFrame(result) content = json.loads(df.T.to_json()).values()if collection.insert_many(content):print('存储数据成功')# 暂停1stime.sleep(1)
好的,保存代码,修改每秒运行次数和并发数

点击run将代码跑起来,不过当跑起来之后,就会发现抓取一个页面之后程序就停止了, pyspider 以 URL的 MD5 值作为 唯一 ID 编号,ID 编号相同,就视为同一个任务, 不会再重复爬取。
GET 请求的分页URL 一般不同,所以 ID 编号会不同,能够爬取多页。
POST 请求的URL是相同的,爬取第一页之后,后面的页数便不会再爬取。
解决办法,需要重新写下 ID 编号的生成方式,在 on_start() 方法前面添加下面代码即可:
def get_taskid(self,task):return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
基本操作之后,文章入库
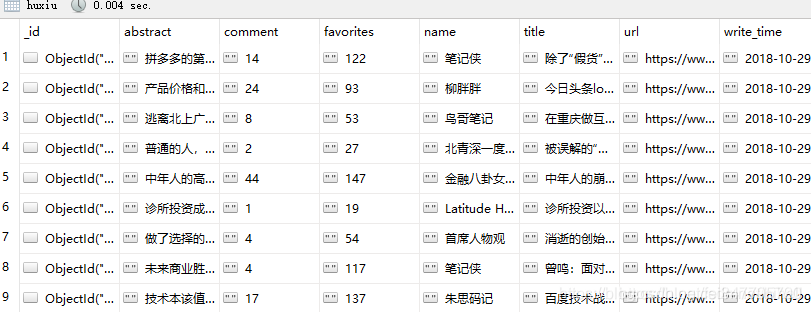
这篇关于pyspider抓取虎嗅网文章数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






