本文主要是介绍卷积神经网络CNN预测苹果公司股价AAPL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、CNN可以做预测吗?
- 二、实现步骤
- 1.准备工作(下载数据集)
- 2.实战开始
- (1)导入所需包
- (2)读取数据集并处理
- (3)重头戏,模型搭建!
- (4)模型编译与训练
- (5)模型预测
- (6)效果图展示
- 总结
前言
在大多数同学的眼中,CNN可能只是用来做图像识别的,没办法将他和预测放在一起,我也是,至少我几个小时之前才突然发现原来CNN也是可以做预测的,其实CNN做预测的原理就是利用卷积核的能力,可以感受数据一段时间的情况,根据这数据之前一段时间的情况来做出预测,原理存在,实践开始:
提示:以下是本篇文章正文内容,下面案例可供参考
一、CNN可以做预测吗?
可以。
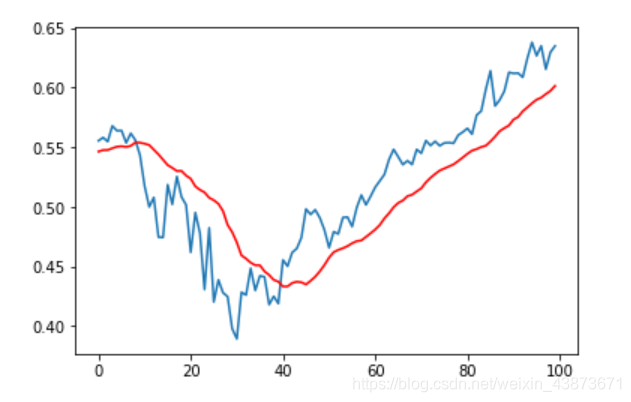
准确的说,是所有的神经网络都可以,简单来说y=ax+b都可以预测,cnn为什么不能?[公式] ,函数 [公式] 可以有很多形式,CNN就是其中一种,当然可以给定输入,输出预测值。区别可能在于他们的功能、准确度和损失率可能有些差距,CNN大放光彩的是它在图像领域的成绩,但这并不影响他也可以出色的完成预测的任务,下面是根据前20天的苹果公司股价,来预测下一天的成交价格的实例,注释我写的简介明白。效果图如下:(红色为预测值,蓝色为实际值),虽然有点差距,但是走势一样,哈哈哈哈。
二、实现步骤
1.准备工作(下载数据集)
数据集可以在雅虎.财经网站上搜索苹果公司最新的股价数据,当然了也可以下载你喜欢的公司的股票数据,这是网站链接:
https://finance.yahoo.com/?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuc28uY29tL2xpbms_bT1ieExod1pPMHd1WXRiY0liZXVCOCUyQmVDZkJad2toekNmMDREZHFvUiUyRlNiUWs1SDA0eXM2SDd0OVlVU3BtOVJxdkkwaEtmdk90JTJGQkhLMzZNWHpVY0xkQWlJZ1FHZnBuVXdYU3FKYzNJT3dRUnY5ejJDek9PcVF6MGR6V0NzJTNE&guce_referrer_sig=AQAAAKEY_jOyLj9ebmmTrbI7ATJS54FU9ibrssNItDvfFchNj5bGDS7LykxqUGMGnaY1eqylsuJK45YXLk3I8LOPfhSkHYD6h1lPEkVh99bFjejA4auVtngjhvpj-R_jcG8lMVyeMp2-0hAe15Q6-jlTnJEpwM8f0rS1UnpP8NxQ7KAn
2.实战开始
(1)导入所需包
来回来去就这几个,全导入没坏处。
import tensorflow as tf
import numpy as np
import matplotlib. pyplot as plt
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Reshape,Dropout,Activation
from tensorflow.keras.layers import Conv2D,MaxPooling2D
from tensorflow.keras.layers import Conv1D,MaxPooling1D
from tensorflow.keras.optimizers import SGD
from sklearn.model_selection import train_test_split(2)读取数据集并处理
这块看着有点多,但是其实并不复杂,我把每行都写上了注释,读取CSV文件,取出要预测的列,在将这行数据都转化为0-1的数字,最后在定义所需要的变量,比如列数x0、频率p、输入输出量X,y。最后再把数据集分成训练集和测试集,准备工作完毕!
df = pd.read_csv('AAPL.csv') #读取APPLE 公司股票文件#df.head() #显示前五行的股票数据
x0 =df['Adj Close'].values #取出所需的Adj Close列,此时已经转化为了arrdy数组
#len(x0)#查看x0的行数#数据预处理,将所有的x0数据都转化为0-1之间的数字,并查看前十个数字
m=max(x0)
x0=x0/m
x0[:10]n=len(x0)#此时的n是x0的个数,p是每20天即预测一次开盘的频率
p=20x=np.array([x0[k:k+p]for k in range(n-p+1)])#将每个K以后20天的值都对应好
x.shapey=np.array(x0[p:])#y是20天预测的数据
y.shapeX=x[:-1]#X是实际可以预测到的数量,比给的数量应当少一笔
X=X[:,:,np.newaxis]#给X赋值,np.newaxis的功能:插入新维度
X.shapex_train, x_test, y_train, y_test=train_test_split(X,y,test_size=0.2,shuffle=False) #拆分数据集,将test集为0.2,参数不同
x_train.shape(3)重头戏,模型搭建!
一如既往选择贯序模型,这是序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”。我觉得贯序模型就比较友好,简单粗暴。
接下来就是添加一维的卷积层和池化层,还有Flatten层和全连接层,其中的参数都在注释里标的很清楚。CNN结构如下图所示。
另外,回答一个疑问:“为什莫最后的激活函数选择了relu,而不是之前一直在用的softmax”,因为这个预测,我理解的它算是一个回归问题,而sofftmax激活函数在分类问题中是最好用的,因此使用了relu。
model=Sequential()#选择贯序模型#添加一维卷积层,卷积核数量为50个4维的,补0策略为same,保留卷积后的边界,激活函数为relu,输入的尺寸形状为(20,1)
model.add(Conv1D(50,4,padding='same',activation='relu',input_shape=(p,1)))model.add(MaxPooling1D(2))#添加一维池化层,选择最大池化,(池化层大小是2,每两个数字留一个)model.add(Flatten()) #添加Flatten层,Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。model.add(Dense(20))#20个神经元的全连接层
model.add(Dropout(0.2))#dropout是CNN中防止过拟合提高效果的一个大杀器,隐含节点dropout率设置为0.2
model.add(Activation('relu'))model.add(Dense(1))#输出层
model.add(Activation('relu'))
(4)模型编译与训练
编译(损失函数、优化器、评价函数)
训练(回合数为50、每次取样本为32)
因为都是数字,没有图片,CPU计算也极快,一秒就完成了,为了降低损失率,大家可以多设置回合数。当然,也可以自己修改优化器,换成Adam应该不错,而且他还有默认的学习率。
model.compile(loss='mse',optimizer=SGD(lr=0.2),metrics=['accuracy'])#编译模型,损失函数、优化器、学习率、评价函数
model.summary()#查看神经网络模型结构#训练模型+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
model.fit(x_train,y_train,epochs=50,batch_size=32)#训练50回合,每次30个样本
(5)模型预测
把测试集数据加入到模型中,就可以预测到 结果了,进行可视化处理后就能以图表形式展示啦!
#模型预测=======================================================================================================
y_predict=model.pridict(x_test)#输入测试集进行预测plt.plot(y_test[:100])
plt.plot(y_predict[:100],'r')(6)效果图展示
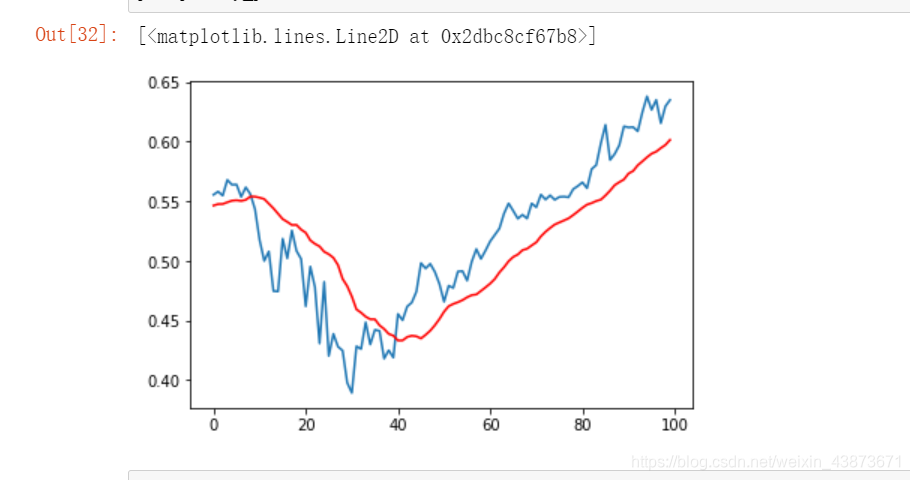
总结
股票预测这个数据集相对好获取,数据全面且准确是个不错的练习项目。
之所以选择苹果公司这种大型公司的股票进行预测,是因为在某种意义上,大盘股被单股力量操纵的可能性比较低,通俗来说,大型公司的股票不会大起大跌,而且数据充足。
不尽人意的是:在训练过程中,也出现了categorical_accuracy: 0.0000e+00的问题,原因还在寻找,期望早点解决!
这篇关于卷积神经网络CNN预测苹果公司股价AAPL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









