本文主要是介绍MetaAI提出全新验证链框架CoVE,大模型也可以通过“三省吾身”来缓解幻觉现象,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文名称: Chain-of-Verification Reduces Hallucination in Large Language Models
论文链接: https://arxiv.org/abs/2309.11495
曾子曰:“吾日三省吾身”
--出自《论语·学而》
时至今日,生成幻觉(hallucination)仍然是大模型研究界中一个令人非常头疼的问题。生成幻觉是指大语言模型在针对一些问题给出看似合理但不符合真实事实的虚假回答,这对于大模型在一些风险场景中的落地应用提出了更高的要求。本文介绍一篇来自MetaAI的最新研究工作,本文参考大模型核心技术思维链(CoT)的设计模式,提出了一种大模型自身纠正错误(自省)的方法框架,称为验证链(Chain-of-Verification,CoVE)。CoVE首先会让模型根据用户输入的问题草拟一个初始回答,然后规划出一个对该初始回答进行事实核查的验证计划,随后使模型独立回答这些验证问题,保证问题之间不会产生影响,最后模型会综合以上所有信息产生一个验证结果。作者在MultiSpanQA和长格式文本生成等任务上进行了大量的实验,实验表明,CoVE方法可以有效缓解LLMs在各种任务中的生成幻觉现象。
01. 引言
LLMs的训练语料库规模非常庞大,通常包含数十亿的文本标记数据,目前有很多研究表明,随着模型参数数量的增加,LLMs可以生成更多正确的事实陈述。但是对于一些位于数据集尾部分布的问题,即使是规模最大的模型仍然会出现幻觉现象,尤其是在一些长文本生成或长篇文本理解任务中。此外,目前LLMs的研究重心已经逐渐转向研究其在复杂问题上的推理能力。因此基于这一研究方向,本文作者开始考虑如何在模型生成的内部思维推理链上实现一些操作来缓解模型的幻觉现象,并提出了一种称为验证链的CoVE方法,CoVE方法使大模型先生成一个初始回答草稿,并根据草稿生成自我检查的验证计划,然后根据计划系统的回答这些子问题,最终根据子问题的结果来生成最终的响应,这一过程非常像大模型在自己进行“三省吾身”。作者发现,CoVE通过独立验证问题的方式会相比原始长回答带来更加准确的事实信息。
02. 本文方法
2.1 整体框架流程
本文提出的CoVE框架主要分为以下四个核心步骤:
(1)生成基线响应:给定一个用户查询文本,使用LLM生成第一个草稿响应。
(2)验证计划的制定:根据输入查询和基线响应文本,LLM需要生成一个可以验证问题回答正确性的列表,这有助于LLM开启自我分析进程。
(3)执行验证计划:LLM需要依次回答每个验证问题,然后将答案与原始响应进行检查,以检查是否存在不一致的情况或错误。
(4)生成最终验证响应:LLM需要根据执行验证计划得到的不一致情况(如果有),综合生成包含验证结果的修正后响应。
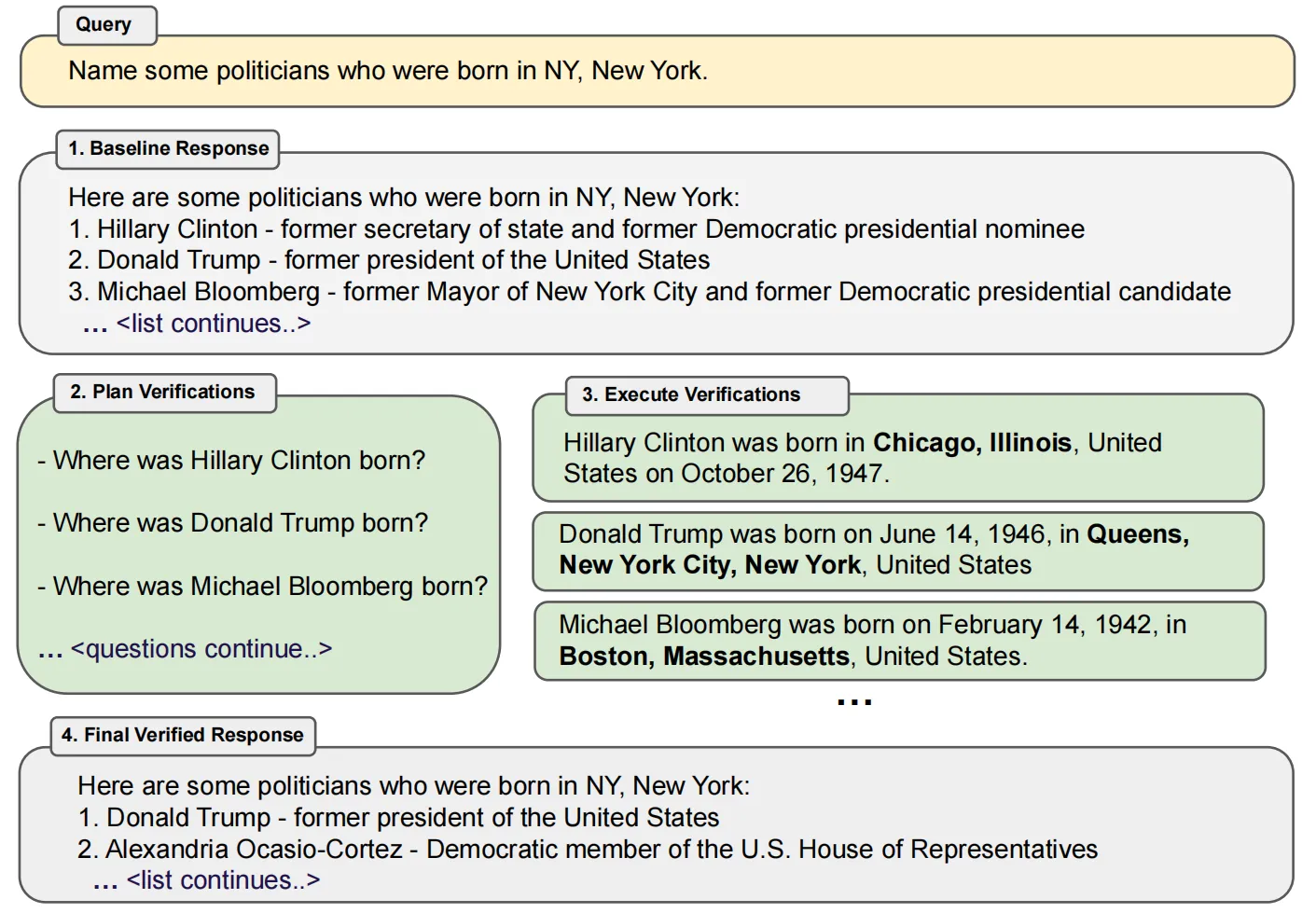
上述四个步骤的执行情况如上图所示,这里给出了一个ChatGPT生成幻觉的示例,可以看到,CoVE对验证计划列表中的每个问题进行单独处理后,可以产生出与初始基线响应事实性完全相反的结果(希拉里·克林顿事实出生在芝加哥),通过回答这些问题并检查生成答案与基线响应是否一致,CoVE就可以将幻觉现象检测出来并进行更正。
2.2 执行验证计划的不同方式
上一小节中列出的四个步骤均需要提示同一个LLM来获得响应,其中步骤(1)(2)和(4)都可以通过单个文本提示来进行调用,但是对于幻觉检查质量的关键其实是在步骤(3)中的验证计划执行,因此作者对步骤(3)设计了多个不同版本,包括联合方法、2-step方法和分解方法。这些不同的版本涉及到单个提示、两个提示或每个问题独立的提示,其中分解方法的执行较为复杂,但是可以直接改进生成的结果。
2.2.1 联合方法
对于最简单的联合方法,计划和执行都是通过使用单个LLM提示来完成的,但是这种方法存在一个明显的缺陷,由于验证问题必须以初始基线响应为条件,因此这样联合产生的验证答案极有可能与初始响应中的内容有关,这有可能会在验证过程中产生二次幻觉。
2.2.2 2-step方法
为了解决联合方法中存在的问题,作者将计划和执行分成单独的步骤,两个步骤都设置了专用的LLM提示,称为2-step方法。这时,规划提示会以第一步中的基线响应为条件,而由规划产生的验证问题则会在第二步中得到回答,其中至关重要的是,LLM提示的上下文仅包含问题,而不包含原始基线响应的内容,因而可以避免产生二次幻觉。
2.2.3 分解方法
除了上述两种方法,作者还提供了一种更加复杂的方法,即分解方法。分解方法将完全不以原始基线响应为条件,其可以消除来自基线响应中的任何潜在干扰。其要求在生成规划和执行规划时全都使用单独的提示并使LLM独立回答所有问题,这样可以消除答案上下文之间的任何潜在干扰。虽然这可能会增加计算成本,需要执行更多的LLM推理,因此必须从计划验证制定步骤中获取生成的问题集,并将它们解析为单独的问题列表,这样就可以对其进行批处理操作,实现并行推理来提高效率。在对每个验证问题回答完成之后,CoVE需要对这些答案与原始响应的一致性进行检查,这时,作者引入了一个额外的LLM提示来执行这一操作,这一操作需要同时以基线响应、验证问题和验证答案为条件,因而可以得到更加完善,消除幻觉后的回答。
03. 实验效果
本文的实验在多种文本生成和回答基准上进行,例如Wikidata、Wiki-Category lists、MultiSpanQA和长篇传记生成任务等。其中Wikidata基准需要模型根据列表形式的问题生成实体类的回答。Wiki-Category lists是一种相比Wikidata更加困难的集合生成任务,MultiSpanQA是一项标准的大模型阅读理解基准,其由包含多个独立答案的问题组成,本文的实验使用了闭卷设置。此外,为了评估CoVE在长文本生成方面的效果,作者使用了传记生成基线Factscore[1],LLM需要根据输入一个实体提示来直接生成其对应的传记。
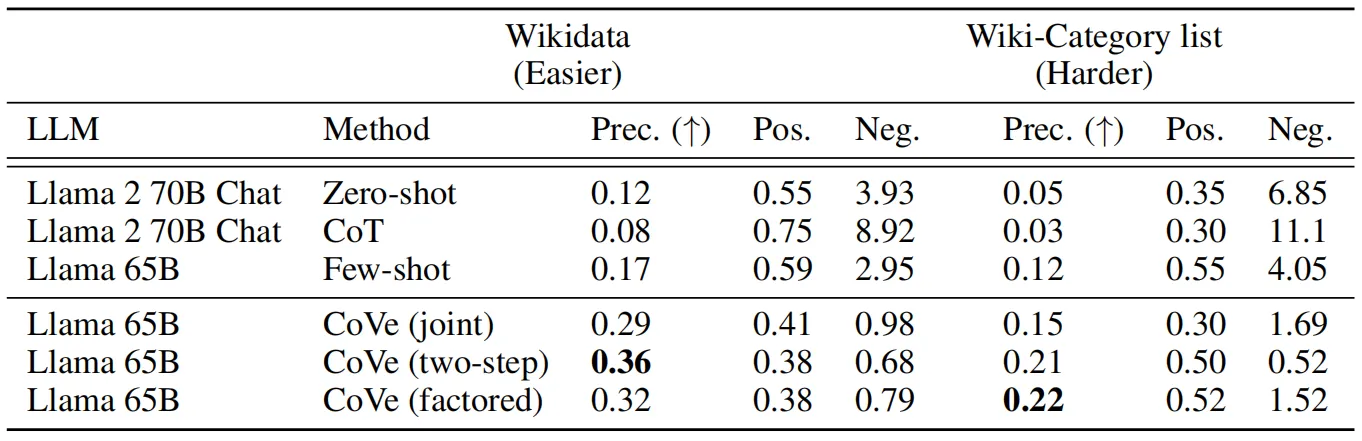
对于基线LLM,作者选用了开源的Llama 65B[2],上表展示了CoVE在列表回答任务上的实验效果,可以看到,CoVe相比Llama 65B的few-shot基线的精度提高了一倍多(从0.17到0.36)。此外,从正负分类的结果可以看出,在使用CoVE方法之后,模型生成的幻觉答案数量大幅减少(Neg:2.95到0.68),而非幻觉答案数量受到的影响很小(Pos:0.59到0.38)。
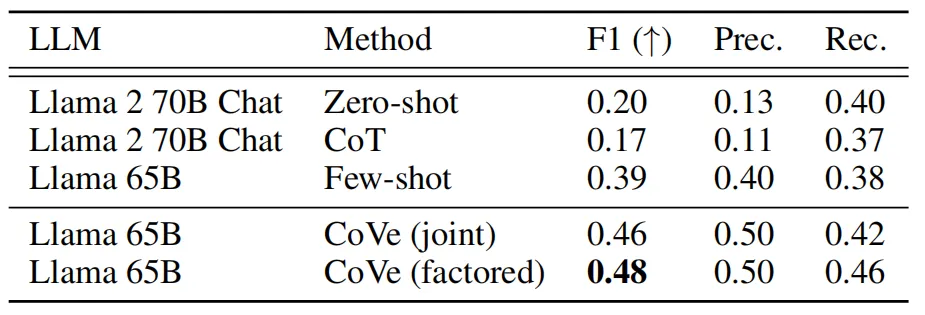
上表展示了CoVE在MultiSpanQA基线上的实验效果,可以看到,CoVe改善了Llama在普通QA问题上的回答正确率,尤其是其F1比Llama few-shot基线提高了 23%。
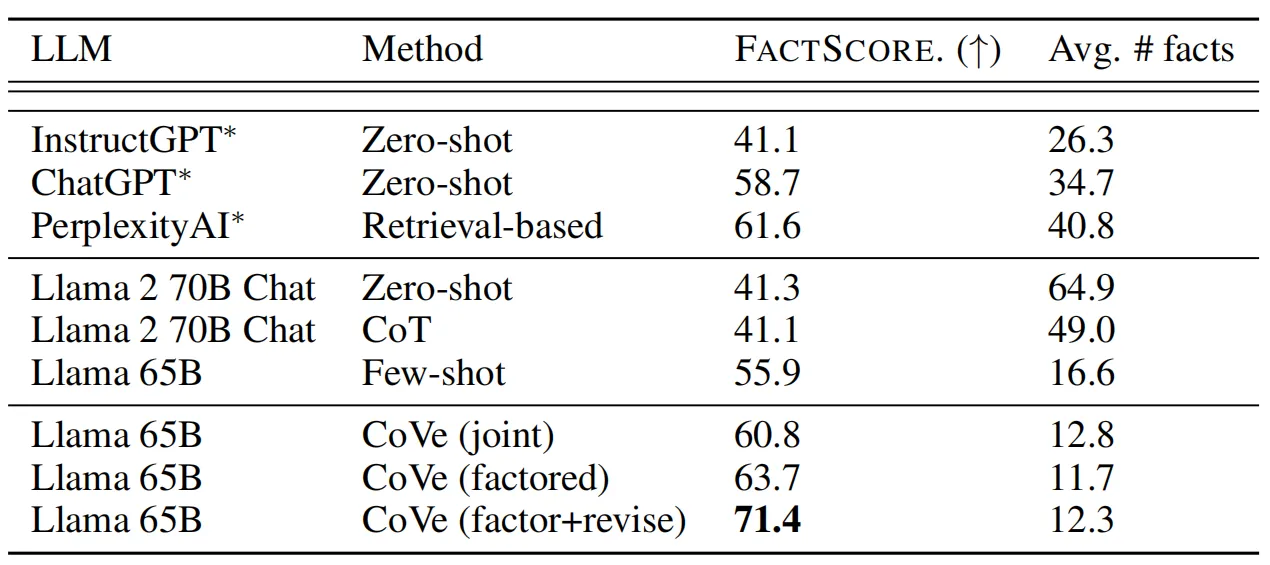
此外,在长格式文本生成方面,CoVE实现了相比列表回答和QA任务更加明显的性能增益,具体实验结果如上表所示,其在Factscore基线上得到的分数相比Llama few-shot基线增加了28% (55.9到71.4)。
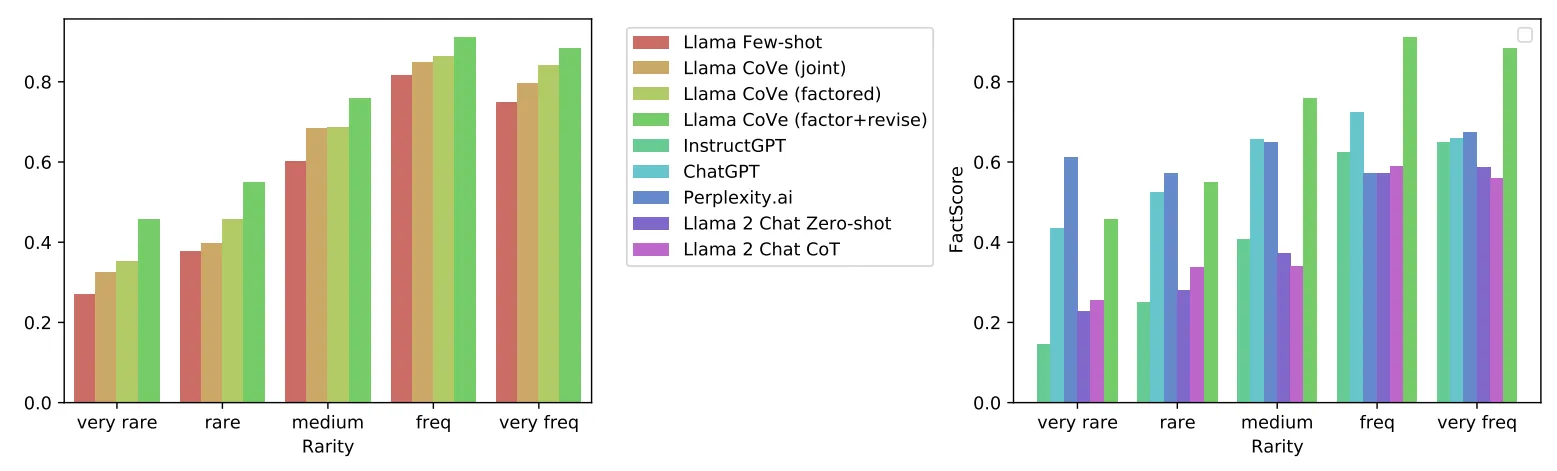
此外,作者还在上图中展示了CoVE在事实改进细分方面的改进对比效果,其中黄色、浅绿色和绿色条柱为本文方法的效果,可以看到,CoVe主要在罕见事实和更常见事实方面提供了更明显的改正。
04. 总结
本文引入了一种称为验证链(CoVE)的大模型幻觉消除方法,这是一种通过仔细考虑自身的反应并进行自我纠正的方法。CoVE通过将初始问题的回答进行合理的拆分,并对拆分的问题进行单独的验证,模型就可以相比回答原始查询时更加准确地回答问题。其次,在回答一组验证问题时,CoVE可以控制模型不受先前答案和上下文的影响,从而有效的减轻幻觉的生成。总体来说,CoVE是一项简单而有效的方法,本文作者还提到,后续可以为CoVE配备一些工具来使用。例如,在验证执行步骤中使用可以使用在线检索增强技术,这可能会带来进一步的性能提升。
参考
[1] Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. arXiv preprint arXiv:2305.14251, 2023
[2] Hugo Touvron et al. Llama 2: Open foundation and fine-tuned chat models, 2023b.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
这篇关于MetaAI提出全新验证链框架CoVE,大模型也可以通过“三省吾身”来缓解幻觉现象的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









