本文主要是介绍机器学习 之 K近邻(K-NearestNeighbor)文本算法的精确率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 0、推荐
- 1、背景
- 2、效果图
- 3、本次实验整体流程
- 4、这里不用词向量,而是用TF-IDF预处理后的向量
- 5、源代码
- 6、知识点普及
- 6.1 K近邻优点
- 6.2 K近邻缺点
0、推荐
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。
1、背景
最近的项目中,用到了很多机器学习的算法,每个机器学习的算法在不同的样本下的精准率是不同的。为了验证每个算法在每种不同样本数量的能力,就做了一下实验,本文讲的是“K近邻”在文本算法中的精准率。
相关其它机器学习算法的精准率:
决策树:机器学习 之 决策树(Decision Tree)文本算法的精确率
逻辑回归:机器学习 之 逻辑回归(LogisticRegression)文本算法的精确率
支持向量机:机器学习 之 支持向量机(SupportVectorMachine)文本算法的精确率
朴素贝叶斯:机器学习 之 朴素贝叶斯(Naive Bayesian Model)文本算法的精确率
随机森林:机器学习 之 随机森林(Random Forest)文本算法的精确率
机器学习各个算法对比:人工智能 之 机器学习常用算法总结 及 各个常用分类算法精确率对比
2、效果图
先看一下没有任何调参的情况下的效果吧!
K近邻:
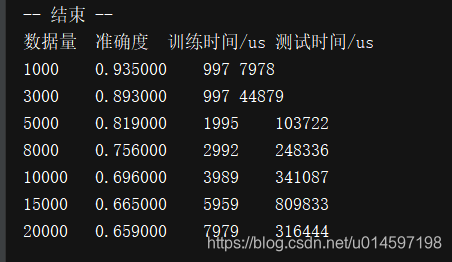
通过以上数据可以看出在样本数量较低的情况下还不错,在样本数量在5000的时候效果还可以,但是到达20000的时候,准确率已经在65%左右了。
3、本次实验整体流程
1、先把整体样本读到内存中
2、把整体样本按照8:2的比例,分为80%的训练集,20%的测试集
3、然后“训练集”的样本 先分词,再转换为词向量
4、接着把训练集的样本和标签统一的传入算法中,得到拟合后的模型
5、把“测试集”的样本 先分词,再得到词向量
6、把测试集得出的词向量丢到拟合后的模型中,看得出的结果
7、把结果转换为准确率的形式,最后做成表格形式以便观看
这里应该多跑几遍不同样本,然后把结果取平均值,每次的结果还是稍有不同的。
4、这里不用词向量,而是用TF-IDF预处理后的向量
这里我们直接取得词向量,而不是经过TF-IDF处理过的词向量。如果处理过,效果会不如现在的好。
TF-IDF(词频-逆文本频率),前面的TF也就是常说到的词频,我们之前做的向量化也就是做了文本中各个词的出现频率统计,并作为文本特征,这个很好理解。关键是后面的这个IDF,即“逆文本频率”如何理解。有些句子中的词,比如说“的”,几乎所有句子都会出现,词频虽然高,但是重要性却应该比 主语、宾语等低。IDF就是来帮助我们来反应这个词的重要性的,进而修正仅仅用词频表示的词特征值。
概括来讲, IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低
加了TF-IDF处理后的效果:
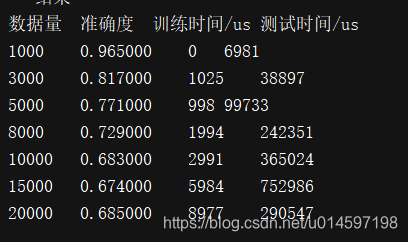
经过TF-IDF处理后的效果比不处理效果好。所以,这里就要经过TF-IDF处理了哈。
以下源码中,如果加TF-IDF处理,只需要在jiabaToVector()函数中增加True这个参数就OK了
vector_train = jiabaToVector(m_text_train, False, True)......vector_test = jiabaToVector(m_text_test, True, True)
5、源代码
import jieba
import datetime
# 向量\测试集\训练集\得分比对
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction这篇关于机器学习 之 K近邻(K-NearestNeighbor)文本算法的精确率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




