nearestneighbor专题

KNN(K-NearestNeighbor)算法
KNN是最简单的分类算法之一。通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。其算法的描述为: 1. 计算测试数据与各个训练

论文复现:Active Learning with the Furthest NearestNeighbor Criterion for Facial Age Estimation
Furthest Nearest Neighbor 方法就是其他文章中的Descripency方法,是一种diversity samplig方法。 由于特征空间是不断变化的,在特征空间上使用Descripency方法违背了该准则的初衷。 import osimport torchimport numpy as npfrom copy import deepcopyfro
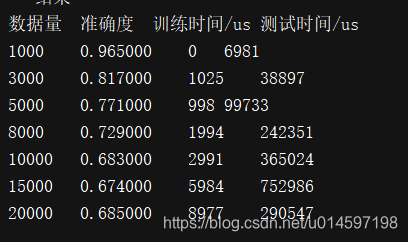
机器学习 之 K近邻(K-NearestNeighbor)文本算法的精确率
目录 0、推荐1、背景2、效果图3、本次实验整体流程4、这里不用词向量,而是用TF-IDF预处理后的向量5、源代码6、知识点普及6.1 K近邻优点6.2 K近邻缺点 0、推荐 无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。 1、背景 最近的项目中,用到了