本文主要是介绍CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是一篇针对图像拼接检测黑盒定位的压缩伪影研究的论文
定位拼接区域的一个主要挑战就是区分具有固定属性的真实区域和篡改区域,
本文提出了一种端到端的全卷积神经网络——压缩伪迹跟踪网络(CAT-Net),用于检测和定位拼接区域。该网络包括RGB流、DCT流和最终融合阶段。RGB流学习视觉伪影并且DCT流学习压缩伪影(即DCT系数分布)。我们对双JPEG检测的DCT流进行预处理,并将其用作拼接定位的初始化。融合阶段融合来自两个流的多个分辨率特征以生成最终掩模。
考虑多分辨率特征的分割网络目的是为了快速推断和获得逐像素预测
使用量化DCT系数的二进制体积表示在DCT域中提取JPEG伪影,目的是为了使网络对JPEG压缩具有鲁棒性。
主要贡献:
- CAT-Net首次结合RGB和DCT域对拼接对象进行定位,使用不同基准数据进行的大量实验表明,CAT-Net与基线相比取得了最先进的性能,并且在JPEG和非JPEG图像方面表现稳定。
- 本文设计DCT流来学习基于DCT系数的二进制体积表示跟踪双重压缩线索的压缩伪影,在检测双JPEG压缩方面,该方法优于使用直方图的现有技术网络。
方法:
网络结构:
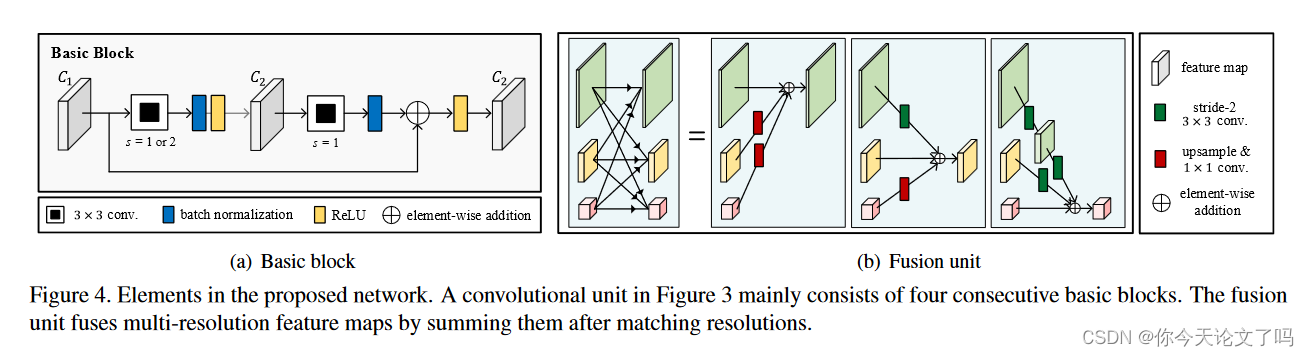
使用HRNet作为CAT网络主干,因为它在整个过程中保持高分辨率表示,并采用一种新的融合方法来组个多个分辨率特征并捕获整体图像,这有助于捕获整体结构,而不会丢失精细证据,HRNet使用stride-2卷积对特征图进行下采样,而不使用池化层(池化层对需要细微信号的任务是不可取的,因为池化增强了内容并抑制了类噪声信号。)
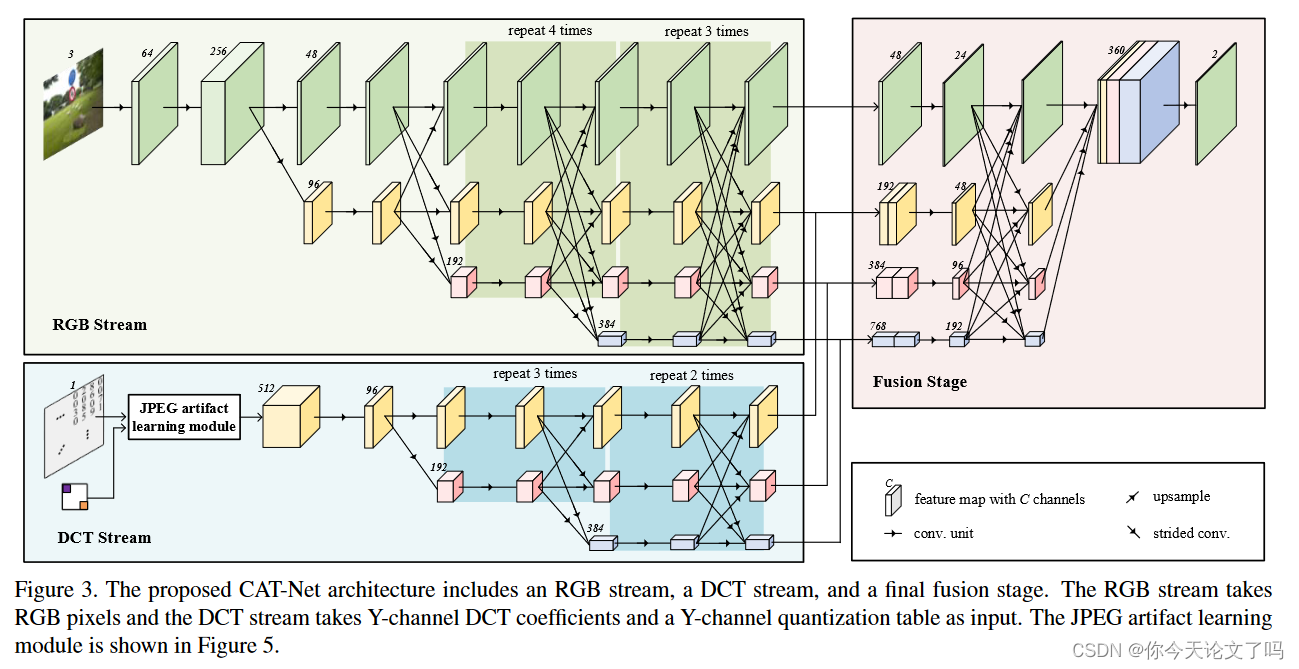
整个网络包括两个单元:卷积单元和融合单元,图3中的每个卷积单元由图4(a)中所示的四个连续基本块组成,只有少数例外,如第一部分和最后一部分。图4(b)显示了融合单元,该融合单元在通过双线性插值(上采样)或跨卷积(下采样)匹配分辨率后,通过对多分辨率特征求和来融合多分辨率特征图。
RGB流结构与HRNet相同,只是去掉了最后一部分。RGB流将RGB像素值作为输入,第一个卷积单元将分辨率降低4倍。从高分辨率路径开始,它逐渐通过网络,逐个添加高分辨率到低分辨率路径,并并行连接多分辨率路径。每一个决议都会持续到最后,产生1/4、1/8、1/6和1/32个决议。
DCT流捕获压缩伪影,即y通道DCT系数的分布,该结构是HENet的三分辨率变体,其中第一个卷积单元被JPEG工件学习模块取代,该流中所有的卷积单元都包含四个基本快,无一例外。
JPEG伪影学习模块最初用f将DCT系数的输入数组转换为二进制体积:
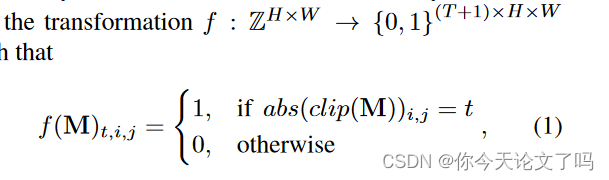
本文采用扩展卷积,所提出的网络使用8扩展卷积,以便提取从同一频率基导出的DCT系数中特征。使用1x1卷积将通道的数量减少到4,并且特征图被分叉。对于分叉路经,将从JPEG报头获得的8x8量化表乘以相应的频率分量,这与JPEG反编码中对DCT系数进行反量化的过程相似。对于另一条路径,该表不会相乘。对于两条路径,每个64个频率分量都是分开的。由于前面的操作都是按照频率进行的,因此8x8块中的每个值都代表一个频率分量,分离组件将形状从4xHxW变成256xH/8xW/8,这有助于显著降低分辨率。最后,本模块中,两条路径的特征图在通道维度上进行拼接,输出通过DCT流的剩余路径。
在训练过程中,将输入图像裁剪为固定大小,以构建具有批次维度的张量,值得注意的是,矩形裁剪区域必须以8x8网络对齐,因为JPEG将图像编码为8x8块,这使得信道分离张量的每个信道表示为一个频率分量,这还允许RGB流学习JPEG伪影以及视觉伪影,
输出特征图分别具有RGB和DCT流的分辨率(1/ 4、1 /8、1 /16、1 /32)和(1/ 8、2/ 16、1 /32)。两个流特征图在通道维度上按分辨率连接,并传递到最终融合阶段(图3),该融合阶段与最终HRNet阶段结构相同,但通道数量不同。所有四个分辨率的特征图最终被双线性上采样,以匹配最高分辨率、级联并通过最终卷积层。最终输出是每个类(真实和篡改)的2xH/4xW/4逻辑数组。
处理非JPEG图像
网络也可以处理非JPEG图像,由于非JPEG图像不包含量化DCT系数,因此在处理非JPEG图像时,根据RGB像素进行计算,这类似于JPEG编码器,我们认为这些图像的量化表是1 ,对应JPEG质量为100.为了实现,在网络前端放置了一个JPEG编码器,并使用质量因子将非JPEG压缩为JPEG,无需色度二次采样,这将自动创建量化DCT系数和包含所有1的量化表。
这是基于压缩假设:虽然拼接图像以未压缩图像格式保存,但在采集过程中,用于拼接伪造的两个源(真实)图像最初在相机中被压缩。操纵图像的文件扩展名并不重要,也就是说,我们不认为伪造者以特定格式保存了伪造图像。
双JPEG检测预训练
通过对双JPEG检测进行预训练还初始化DCT流权重,任务是给定的JPEG图像是否已经被压缩一一次或者两次,
实验
数据集
除了一些基本数据集外,本文创建了另一个数据集(拼接COCO),以避免过度拟合特定的压缩参数,使用COCO 2017数据集和各种量化表。拼接图像是通过在一幅图像中选择一个或多个任意对象,并在随机位置将其粘贴到另一幅图像上,随机旋转和调整大小来自动创建的。然后,这些图像以随机JPEG质量因子50–99进行压缩。我们没有应用其他后处理,例如模糊拼接的边界,因为这可能会误导网络,使其像模糊检测器一样工作。
细节:
通过对RGB流的ImageNet分类和通过对DCT流的多JPEG分类进行预训练来初始化网络权重;
在每个数据集中对均衡数量的图像进行采样,以构建一个新的epoch,从而更好的处理数据集大小的多样性;
训练图像被裁剪成512个与8x8网络对齐的补丁。
评价:
用联合平均交集mIoU来评估网络性能,对于两分类

用Permulted-mIoU来评估;

对于伪造定任务,有时哪个是被拼接的是模棱两可的,p-mIoU评价的是区分真实区域和篡改区域的能力,而非判断哪个是哪个,mIoU不适合评估真实图像,采用像素精度来评估真实图像
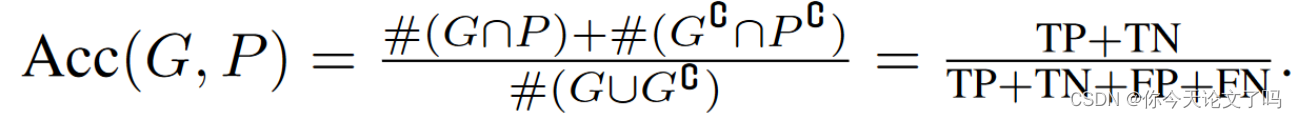
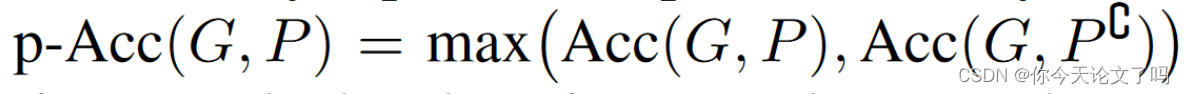
结论:
我们提出了一种CAT-Net,它可以定位给定图像上的拼接区域。CAT-Net是第一次尝试同时考虑RGB和DCT域,以有效地学习通过RGB流和DCT流保留在每个域中的视觉和压缩伪影的法医特征。特别是,包含JPEG伪影学习模块的DCT流在检测双JPEG压缩时实现了出色的性能。我们首次将双JPEG检测任务的转移学习应用于图像伪造定位任务。这有助于网络区分拼接区域和真实区域之间的统计指纹。与当前网络相比,CAT Net在不同数据集上定位JPEG或非JPEG图像拼接区域方面达到了最先进的性能
这篇关于CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






