本文主要是介绍【论文笔记】Reality Transform Adversarial Generators for Image Splicing Forgery Detection and Localization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用于图像拼接伪造检测和定位的真实变换对抗生成器
发布于ICCV2021
摘要
伪造图像的生成和检测过程与生成对抗网络的原理相同。本文针对伪造图像的修图过程需要抑制篡改伪影并保持结构信息的问题,将此修图过程看作是一种图像风格变换,提出了一种假到真转换生成器GT。 为了检测篡改区域,提出了一种基于多解码器单任务策略的定位生成器GM。 在GT中提出的α-learnable whitening and coloring transform (α-learnable WCT)块,通过对抗性训练两个生成器,自动抑制伪造图像中的篡改伪影。 同时,通过对GT修复后的伪造图像进行学习,提高GM的检测和定位能力。 实验结果表明,所提出的两个GAN生成器能够很好地模拟伪造者与认证者之间的对抗; 在四个公共数据集上,定位生成器GM在拼接伪造检测和定位方面优于现有的方法。
引言
图1(a)展示了拼接伪造图像的两个例子。

基于CNN的方法可以进一步分为基于patch的方法和端到端方法。
- 基于patch的方法:由于最终的检测结果是由图像patch的决定而来的,所以检测结果一般是由方形的白色块组成,或者只检测被篡改区域边界上的patch。
- 端到端方法:如果伪造者抑制和减少篡改伪影,端到端方法很难检测到篡改区域。
图1-(d)为基于CNN的方法的实验结果。
MAG需要类分割来修饰拼接伪造图像,这消耗了大量的计算资源。此外,由于篡改区域和类分割的预测都是在单个解码器网络中产生的,一些与ground truth中篡改区域相似的未被篡改的语义区域很容易被检测为篡改区域,如图1-(e)所示的实验结果。
在这项工作中,我们重新思考产生和检测伪造图像的原理。当图像伪造者对伪造图像进行更逼真的修饰时,需要隐藏篡改后的图像,同时保持伪造图像的结构信息不变。伪造图像的修图过程与图像风格变换的任务是相同的。因此,我们将伪造图像的修图过程视为图像风格变换,将拼接的伪造图像从“假风格”转换为“真风格”。基于这一观点,我们提出了假到真转换生成器GT来模拟伪造者。与此相反,身份验证者需要从这些更“真实风格”的拼接伪造图像中检测出篡改区域,因此提出了一种基于多译码器-单任务(MDST)策略的定位生成器GM。在GT和GM的对抗训练中,为了逐步抑制拼接伪造图像的篡改伪影,我们提出了α-learnable whitening and coloring transform (α-learnable WCT)块。而通过多译码-单任务策略(MDST), GM将从修改后的图像中学习更少的篡改伪像,从而提高其检测和定位能力。此外,鉴别器DT和DM将对GT和GM的输出进行限制。用于对抗训练GM和GT的GAN框架被命名为现实变换对抗生成器(RTAG),这两个检测结果的示例如图1-(f)所示。
主要贡献
- 本文将伪图像的修图过程视为图像的风格变换。在此基础上,提出了一种拟真变换生成算法GT,该算法利用α-可学习WCT块对拼接后的伪图像进行自动渐进润色;
- 为了利用更少的篡改工件检测篡改区域,提出了一种基于多译码器-单任务策略的定位生成器GM;
- 通过在GAN框架中对抗式训练GT和GM,定位生成器GM将检测并定位篡改区域,即使拼接伪造图像篡改较少。
方法
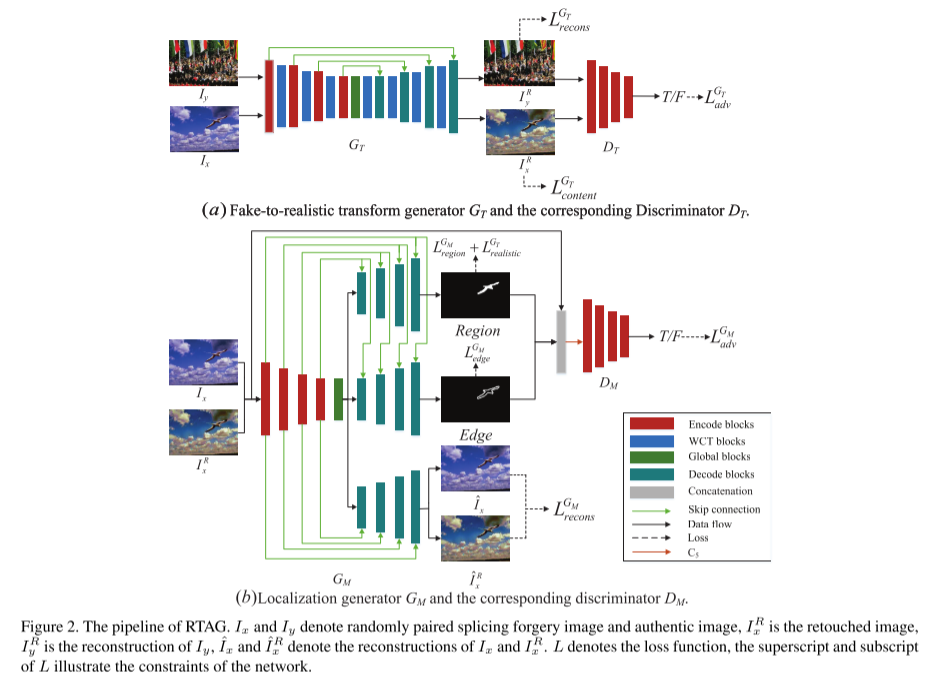
在本文提出的RTAG框架中,拼接伪造图像的生成和检测被认为是一场GT和GM之间的对抗游戏。GT逐步地将拼接伪造图像从一种“假风格”处理为一种“真风格”,然后GM需要通过学习被GT修饰过的图像来检测篡改区域,这些修饰过的图像有较少的篡改伪影。通过对抗性的GT和GM训练,增强GM的检测和定位能力。该RTAG框架如图2所示。
这里,GT和GM遵循目标函数V(GM)和V(GT):
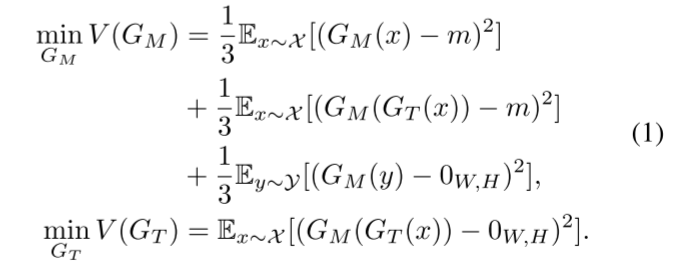
式中,x为拼接伪造图像Ix中的值;y为真实图像Iy中的值;X、Y分别表示伪造域和真实域;m表示拼接伪造图像Ix的ground truth;0W,H为黑色图像,表示真实图像Iy没有任何篡改区域。
假到真转换生成器GT
在MAG中,注释器生成器通过生成篡改区域和类分割的预测来确保修饰后的图像可识别。类分割的生成不仅需要额外的计算源,而且可能会干扰定位任务。因此,在本文中,我们将修饰过程视为一种图像风格变换。GT在保持Ix的结构信息不变的情况下,将拼接的伪造图像Ix转换为真实感图像。如下图所示,GT在U-Net的某些层之间应用WCT块,在编码器和解码器之间插入一个全局块。相应的鉴别器DT的结构与PatchGAN体系结构相同,是一个条件鉴别器。
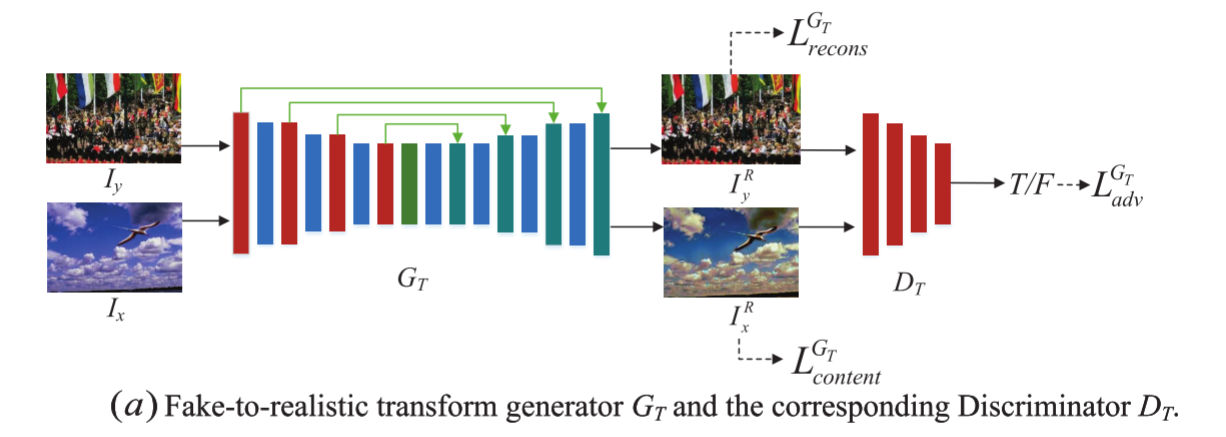
在生成器GT中,将拼接的伪造图像Ix和真实图像Iy随机配对,输入第一个编码块生成特征图fx和fy。WCT块直接将feature map fx与feature map fy的协方差矩阵进行匹配。WCT首先剥离了fx中的风格特征,如颜色、对比度等。然后用fy中的样式特征填充去皮的特征图fx,得到变换特征图fxy。最后通过式(2)将变换后的feature map fxy与feature map fx进行混合。
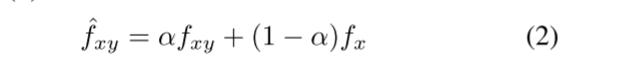
其中fˆxy表示第一个WCT块的输出特征。α∈[0,1]表示控制修饰程度的权重。然后,fˆxy将是下一个块的输入特征fx。
之前只是手工设定α的值。但是,如果α值过高,修饰图像中的结构信息可能会丢失,修饰后的图像总是带有黑斑,修饰后的图像边缘会出现颜色晕。另外,当α值接近1时,拼接的伪造图像Ix的特征几乎被真实图像所替代,GM将不会学到任何东西来区分被篡改的区域。另一方面,如果α太低,WCT将失去其功能。因此,手工计算α值比较困难。为了解决这个问题,我们提出了α-可学习WCT块,该块的结构如图3所示。
注:GAP是全局平均池化层
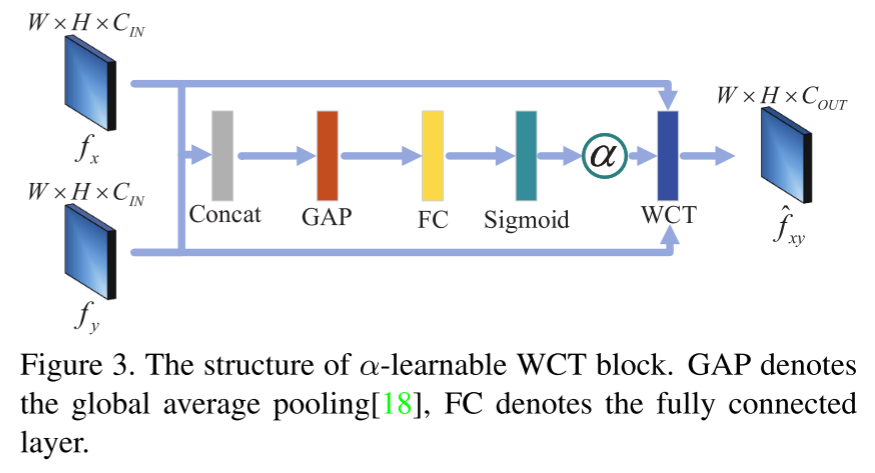
α-可学习WCT块可以通过学习特征映射fx和fy来确定α的最佳值。α-可学习WCT块的定性结果如图4-(f)所示。基于评价α-可学习WCT块的实验结果,我们认为它可以进一步应用于其他端到端变换网络。

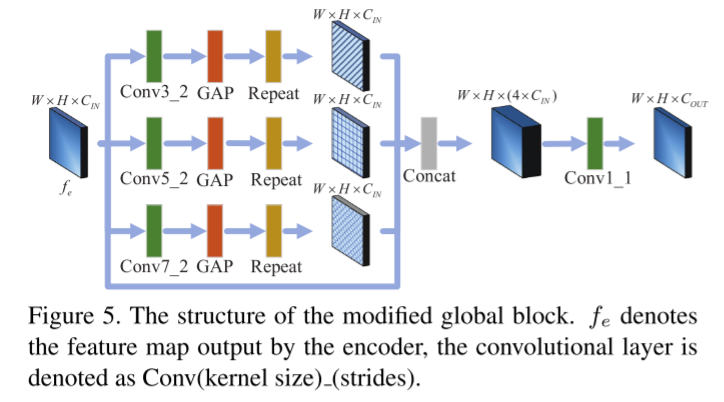
因为从全局的角度来看,伪造图像Ix的特征应该被真实图像Iy的特征所取代。在[3]中提出的全局块的基础上,我们对该全局块进行了修改,通过应用不同接受域的卷积来提取多级特征,修改后的全局块可以得到更全面的全局特征。在编码器和解码器之间插入全局特征提取,提高了变换的真实感。改进的全局块结构如图5所示。
为了在GT中实现多任务,GT使用混合损失函数,其由四个部分组成:LGT content、LGT recons、LGT realistic和LGT adv。GT在修饰伪造图像时不应改变伪造图像的结构信息,因此内容损失函数LGT content被定义为等式(3):
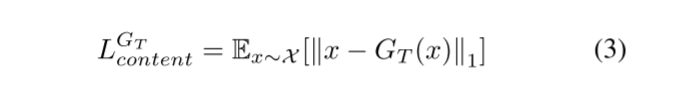
在公式(3)中,x表示拼接伪造图像Ix的值,·1表示1范数。由于GT需要重建真实图像Iy,并且保持重建图像IR y与真实图像Iy相同。因此,利用重构LGTrecons的损失函数来增强GT的重构能力,公式(4)中定义了LGTrecons:
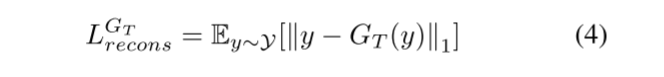
其中,y为真实图像Iy的值。由于GT是对GM进行对抗训练的,当输出的修饰图像IR x较真实时,GM的预测就比较困难。因此,我们使用公式(5)进行的现实损失函数LGTrealistic:
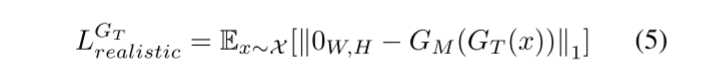
最后,我们使用公式(6)中定义的最小二乘方程作为相应鉴别器的对抗性损失函数DT。对抗损失函数LGT adv将使输出的修饰图像IR x更加真实。
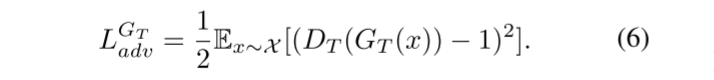
最终的损失函数可以总结为:
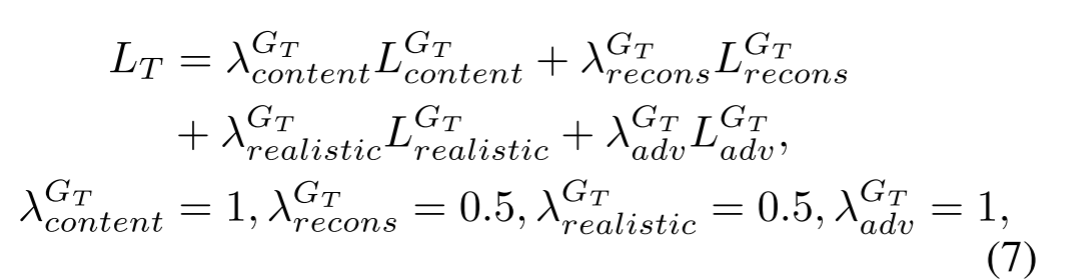
其中λ表示每个损失函数的权值,每个权值由实验的经验确定。
定位生成器GM
MAG使用U-Net生成被检测区域、被检测边缘和类分割,如图1-(e)所示,单编码器工作于多任务(SDMT)会导致检测结果的精度较低。因为未被篡改的语义区域与被篡改区域的语义类相似,将被检测为被篡改的区域。因此,我们用多译码器-单任务策略来代替SDMT。MDST可以使网络的每个解码器集中在单个任务上,避免任务之间的干扰。
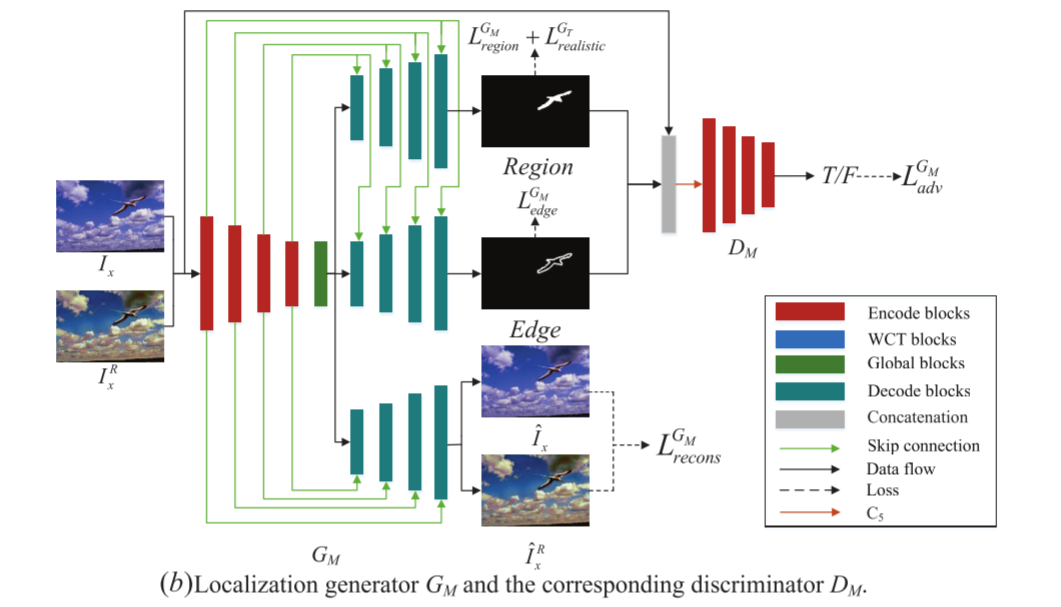
如上图所示,GM的结构是一个改进的UNet,它有三个编码器。DM和DT的结构是一样的。在GT对伪造图像Ix进行润色处理时,通过图像的颜色、对比度等特性来区分篡改区域比较困难。因此,需要一个边缘解码器,使GM更多地关注被篡改区域和未被篡改区域之间的边缘。为了保证编码器输出的隐藏代码是全面的和有意义的,使用重构解码器来正则化共享编码器。由于定位任务是一个全局分类问题,需要对不同区域的特征进行全局比较,因此在编码器和解码器之间也使用了GT中使用的改进全局块。
该算法采用混合损失函数进行训练,混合损失函数由四部分组成:区域损失LGMregion、边缘损失LGMedge、重构损失LGMrecons和对抗损失LGMadv。区域损失LGMregion是解码器预测gt中被篡改区域的损失函数。LGMregion通过二元交叉熵函数计算被检测区域与被实际篡改区域之间的距离,由公式(8)进行。
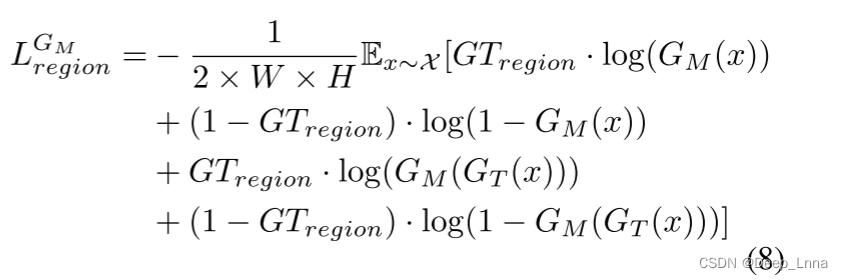
在公式(8)中,W和H表示gt的宽度和高度,GTregion是伪造图像Ix的gt中被篡改的区域。GT (x)为修饰后的图像IR x。GM (x)为伪造图像Ix的检测区域。GM(GT(x))是修饰后图像IR x的检测区域。边缘损失函数LGMedge可以用公式LGMregion来计算。由于被篡改区域的边缘含有较少的像素,这会导致丢失结果不稳定,反馈不足。为了解决这一问题,LGMdege被特别定义为公式(9)。我们在二元交叉熵函数中加入外部权重来调节边缘损失。
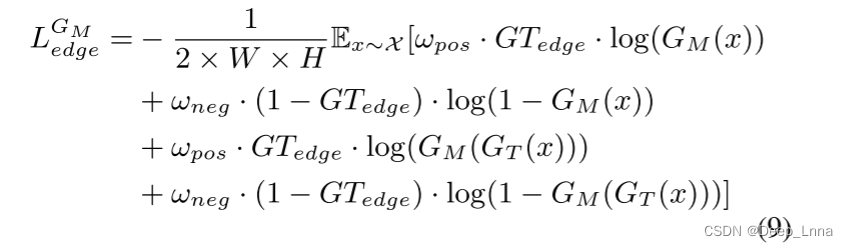
式中,GM(x)为伪造图像Ix中被篡改区域的检测边缘,GM(GT(x))为修饰图像IR x中被篡改区域的检测边缘。GTedge表示ground truth中被篡改区域的边缘。ωpos和ωneg是使GM更关注被篡改区域边缘的权值。在下面的实验中,我们设ωpos = 1.5, ωneg = 0.5。对于GM中的重构解码器,通过公式(10)计算损耗函数LGMrecons。
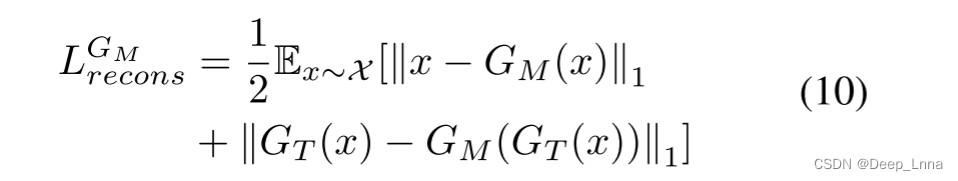
在公式(10)中,GM(x)为重构图像Ix, GM(GT(x))为重构图像I R x。最后,为避免输出模糊,提出了一种对抗性损失LGM adv,定义为公式(11)。
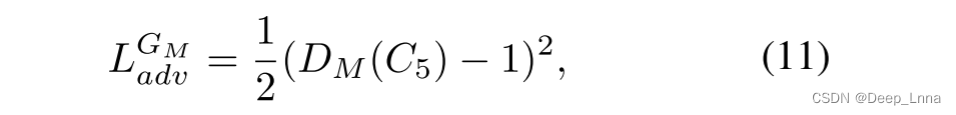
式中,C5是三个部分的拼接输入:伪造图像Ix的检测区域、伪造图像Ix中被篡改区域的检测边缘、拼接的伪造图像Ix或修饰后的图像IR x。C5的下标是连接的通道号。最后,计算GM的最终损失函数如下:
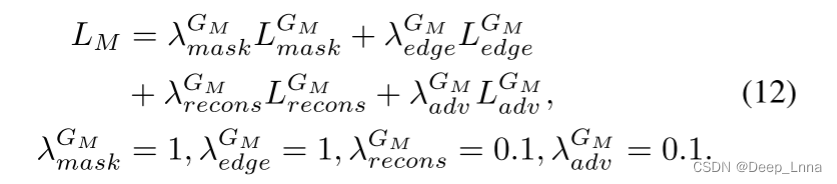
LM中的每个权值λ是根据实验经验确定的。
实验
数据集
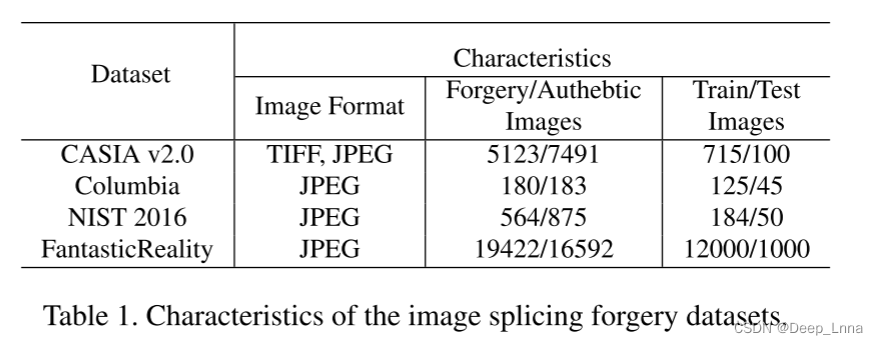
CASIA v2.0、Columbia、NIST 2016、FantasticReality。在每个数据集中只选择拼接伪造图像,数据集的特点如下表1所示。
评价标准
平均精度(mAP)、曲线下面积(AUC)和F率(F rate)。
比较
- 四种最先进的深度学习剪接伪造检测方法(ManTra、MAG、LSTM、C2RNet)。
- 两种传统的方法(ADQ、ELA)。
- 仅在FantasticReality数据集上的MAG进行了比较,因为MAG需要类分割,而类分割只在FantasticReality数据集上提供。
我们在像素级评估了RTAG和比较方法的性能。评价结果见表2。
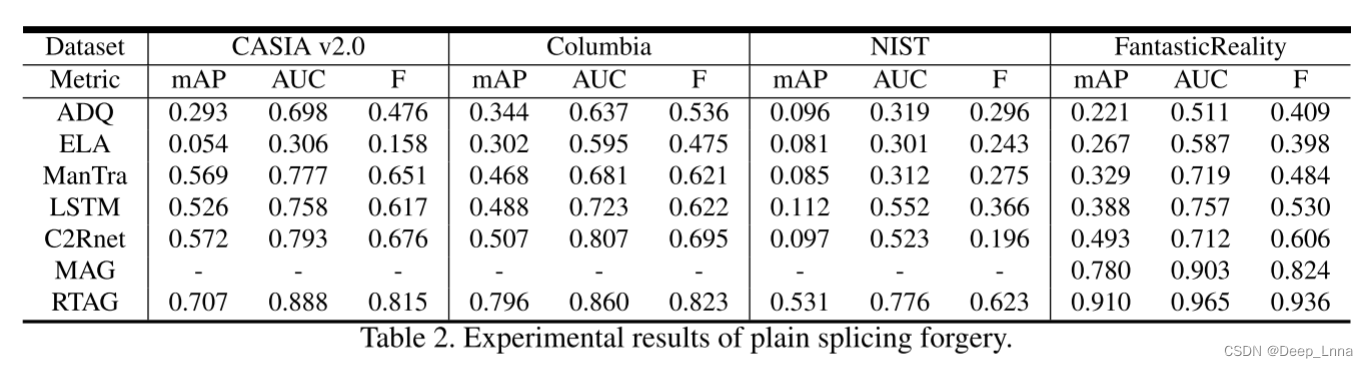
传统方法总是将整个图像作为篡改区域进行检测,因此这些方法的查全率很高,但查准率很低。NIST 2016的训练集非常小,被篡改的图像经过适当的后处理来隐藏篡改的工件,所以很多方法在这个数据集上都失败了。但我们的模型学会了通过更少的篡改工件来检测篡改区域,并优于NIST 2016上的其他方法。如图6和图7所示的结果表明,我们的方法的性能优于目前最先进的方法。



消融研究
在CASIA v2.0上进行研究。
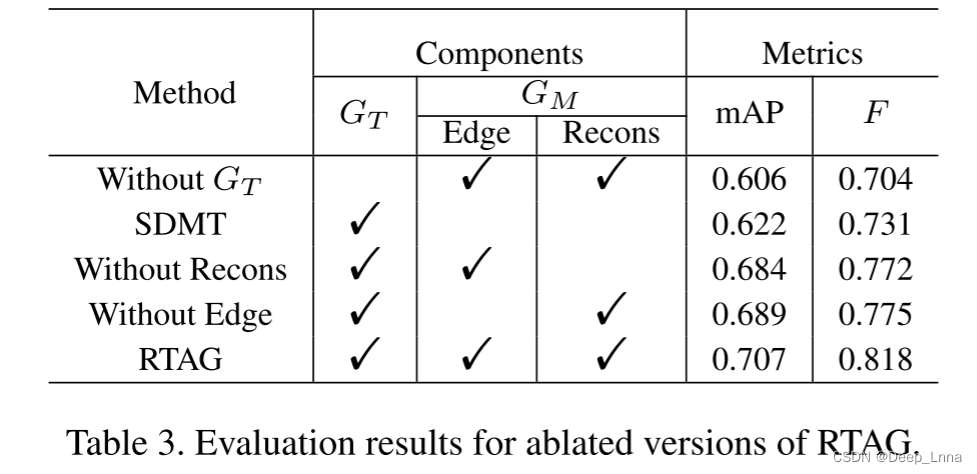


总结
本文提出了一种用于剪接检测和定位的生成对抗网络框架(RTAG)。RTAG对抗性地训练一个伪到真转换生成器GT和一个定位生成器GM来模拟图像伪造者和图像验证者。提出了一种新的α-可学习的WCT块来自动渐进地抑制伪造图像的篡改伪影。同时,GM的多解码器单任务策略将通过学习篡改较少的篡改图像来提高GM的检测和定位能力。通过对GT进行对抗训练,GM可以从较少的篡改工件中学习检测篡改区域。实验结果表明,该方法在图像拼接伪造检测和定位方面优于目前最先进的方法。
这篇关于【论文笔记】Reality Transform Adversarial Generators for Image Splicing Forgery Detection and Localization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








