本文主要是介绍全球首款3nm芯片塞进电脑,苹果M3炸翻全场!128GB巨量内存,大模型单机可跑,性能最高飙升80%,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【导读】史上最短苹果发布会上,M3芯片家族震撼亮相了!在它们的加持下,MacBook Pro、iMac纷纷升级成性能猛兽。
史上最短苹果发布会「Scary Fast」,刚刚结束。30分钟的时长虽短,效果却依然炸裂。
在这个「暗黑万圣节」风格发布会上,三款突破性的芯片——M3、M3 Pro、M3 Max同时亮相!

3nm工艺的加持,让M家族系列芯片性能大增。回想21年M1芯片的横空出世,到M2的挤牙膏,今天的M3总算不负众望,让苹果打了个翻身仗。
MacBookAir和MacBook Pro,也随之变身性能猛兽。
库克也顺势安利——换Mac的好时机来了!

而在发布会最后,苹果还给了大家一点点震撼——整场活动都是用iPhone拍摄,并用Mac剪辑制作。

苹果发布会,已经登上微博热搜第一。

标配版价格总结如下:
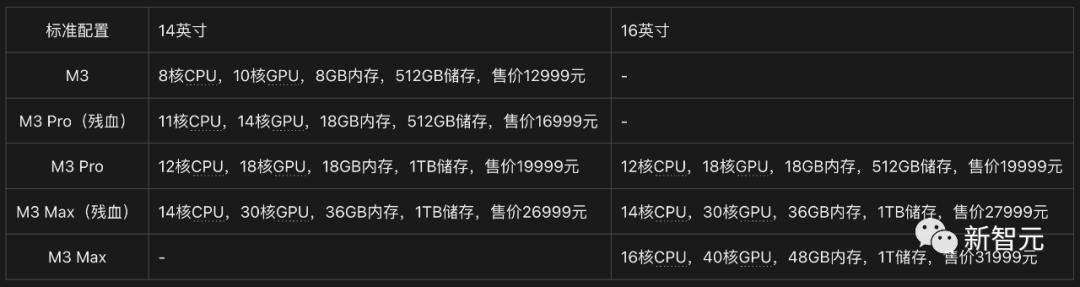
其中,16英寸满血版M3 Max机型,将配置拉满后价格直接打上了55999元。

全新升级后的24英寸iMac诚意满满,不仅配备了M3,价格维持原价,售价10999元。
所以,新产品啥时候能买?
11月1日上午9点开启预售,11月7日正式发售。
M3来了!
一开场,M3、M3 Pro、M3 Max三款芯片重磅亮相!
得益于3nm技术和新一代GPU架构,性能更强的CPU,更快的神经网络引擎,更大的统一内存,M3家族的实力可谓是一骑绝尘。
短短两年,性能就有如此惊人的飞跃,苹果着实让我们惊艳了一把。

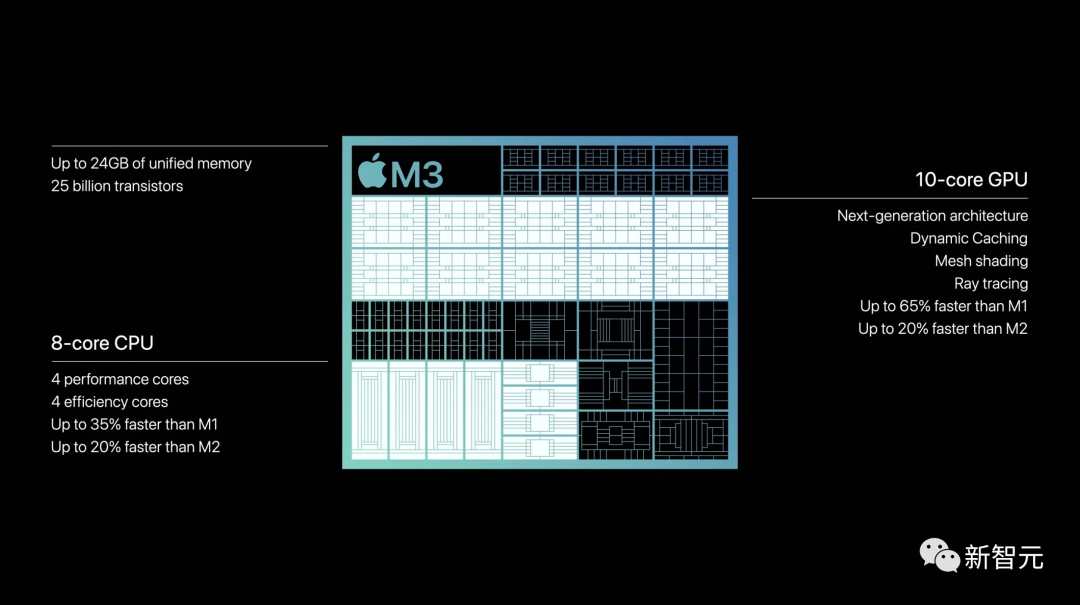
入门级的M3芯片拥有250亿个晶体管,8个CPU核心,10个GPU核心,以及最高支持24GB的统一内存。
CPU方面,4能效+4性能的搭配,让M3实现了比M1快35%,以及比M2快20%的性能释放。
得益于新一代的架构,M3的GPU也实现了相较于M1最高65%的提升,以及相较于M2最高20%的提升。
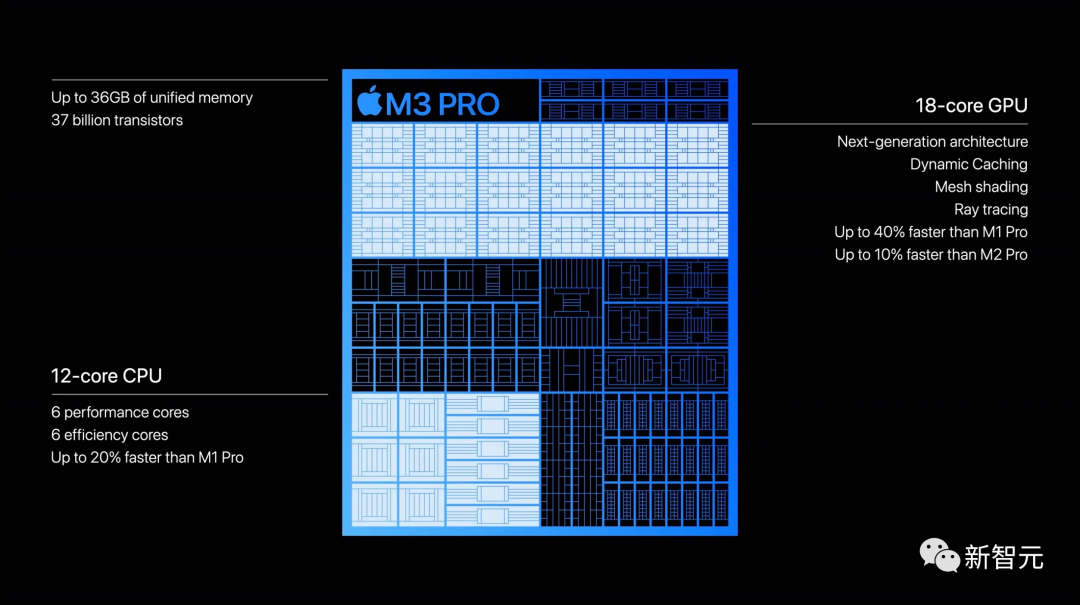
M3 Pro则将晶体管数量扩展到了370亿个,实力更胜一筹,适合对性能要求更高的用户。
它拥有12核CPU、18核GPU,最高支持36GB的统一内存。
和M1 Pro相比,M3 Pro分别在CPU和GPU上,实现了20%和40%的性能提升。
但对比M2 Pro来说,GPU只提升了10%。
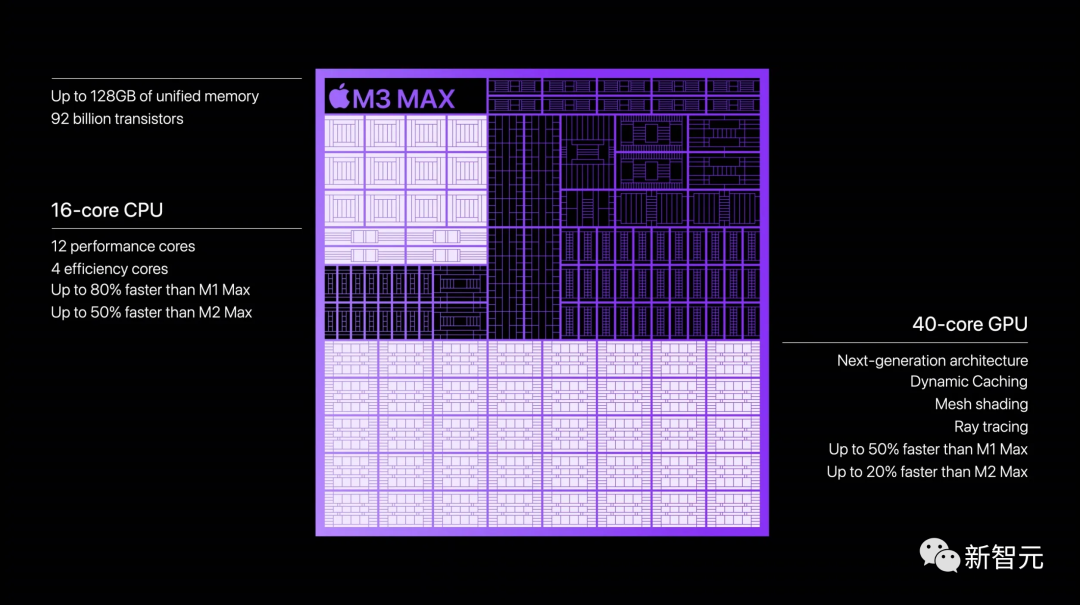
M3 Max拥有16核CPU、40核GPU,支持最高达128GB的海量统一内存,让AI开发者可以处理更庞大的Transformer模型,甚至包含数十亿参数。
全新的架构和高达920亿的晶体管数量,让M3 Max的性能得到了突飞猛进的提升——
在CPU方面,相比于M1 Max实现了高达80%的飞跃,甚至比M2 Max也强了50%!
GPU方面,则比M1 Max提升了50%,比M2 Max提升了20%。
可以说,最新升级的M3 Max足以胜任各种要求严苛的专业任务。
可以说,苹果芯片架构的每一处设计,都是为了提升性能和能效。即使不插电,性能也不受影响。
全球首款3nm电脑芯片
这款全新芯片,首次采用业界领先的3nm工艺。
利用先进的极紫外光刻,3nm工艺可以制造极小的晶体管。
一根头发的横截面,就可以容纳200万个晶体管。

使用这些尖端晶体管,苹果优化了新款芯片的每个组件,GPU的提升尤为显著。
M3系列芯片配备的新一代GPU,实现了GPU架构的空前飞跃。
首创动态缓存
它的新型微架构具备一个突破性的功能:苹果首创的动态缓存。
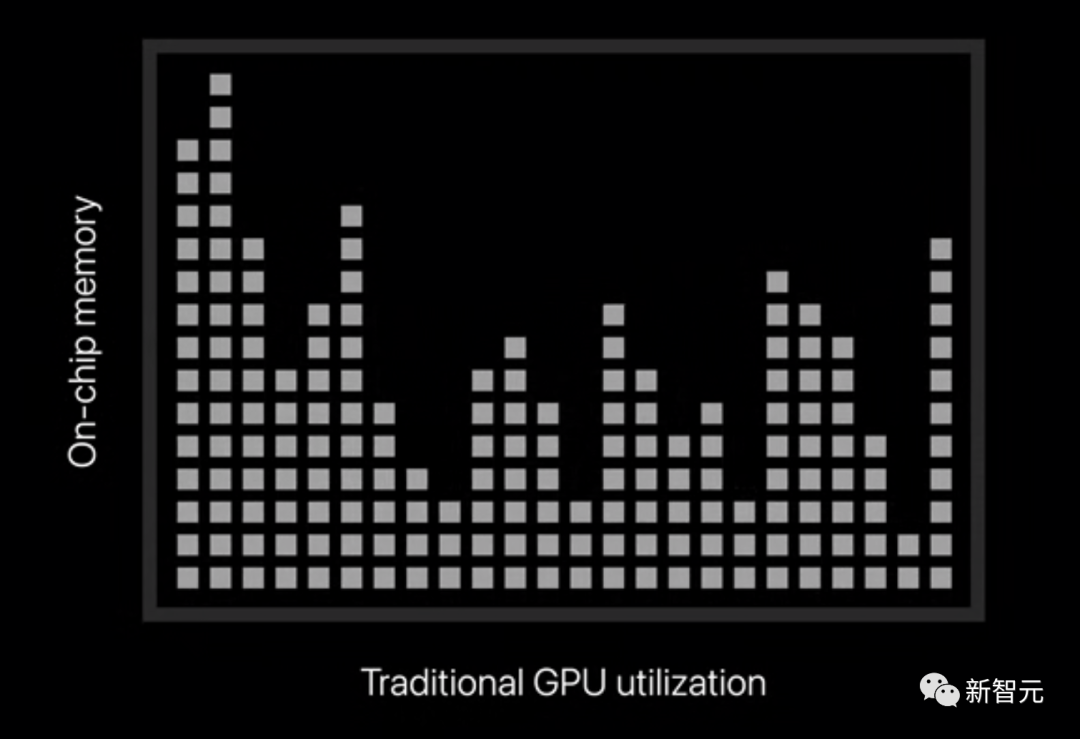
在传统的GPU架构中,是由软件在编译时根据接下来的任务,决定预留多少局部GPU内存。
这样做的结果就是,根据需求最高的单个任务,为所有任务预留相同的内存量。
这就会造成GPU的利用率不足,特别是在运行复杂的程序时。
而在新一代GPU中,局部内存可实时在硬件中动态分配。
因此,每项任务仅会占用它实际所需的内存量,这就大幅提高了GPU的平均利用率,显著提升了专业APP和游戏的性能表现。
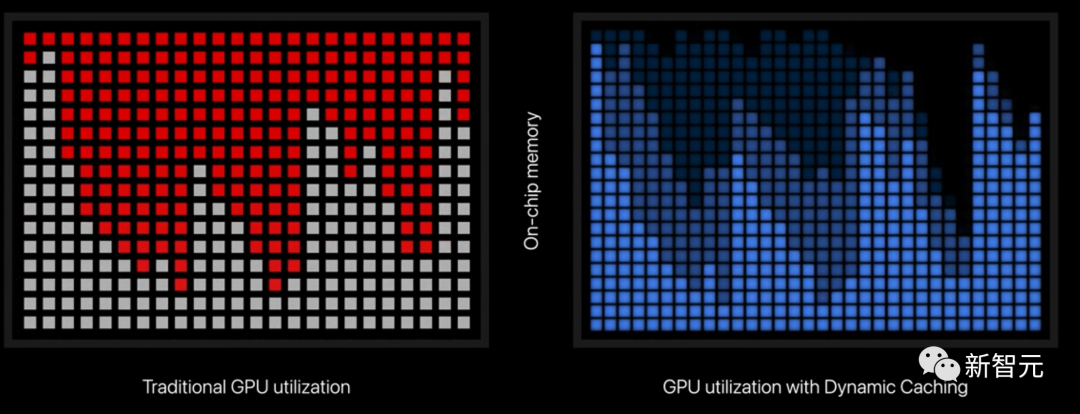
这属于开创先河的技术,对开发者透明,是新一代GPU架构的基础。
全新渲染功能
其次,新一代GPU还为苹果芯片带来了新的渲染功能,比如硬件加速网格着色。
网格着色提升了几何模型处理的功能和效率,能打造视觉效果更复杂的场景。

支持光追,比M1渲染提升2.5倍
最后,新的GPU架构把支持硬件加速的光线追踪,首度带到了Mac上。
光线追踪可在光与场景交互时,对光的物理属性进行建模,为游戏渲染出更精准的阴影和反光,打造更真实的环境。
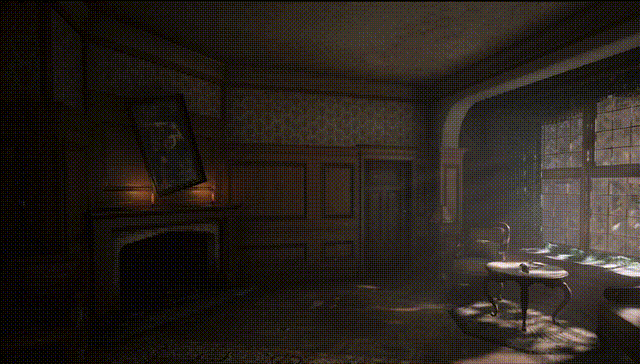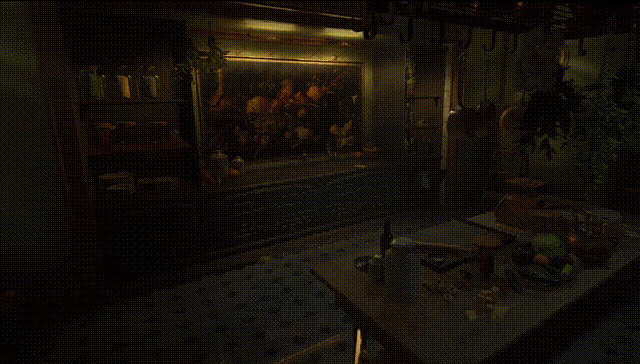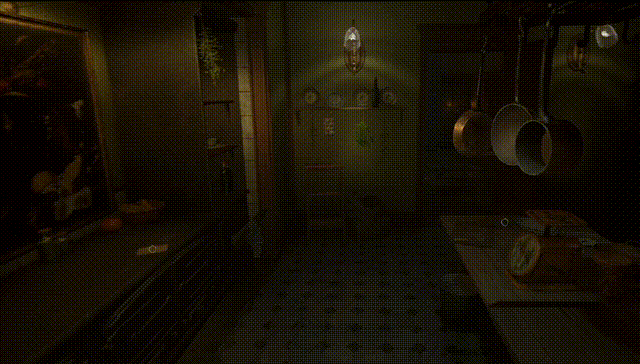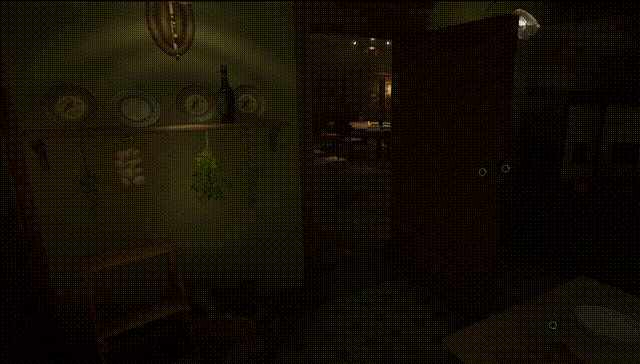
专业的3D渲染软件,能生成惊艳的光追效果,速度也更快了。

硬件加速光线追踪,联手新的GPU架构,让专业app的渲染速度最高提升至M1系列芯片的2.5倍。
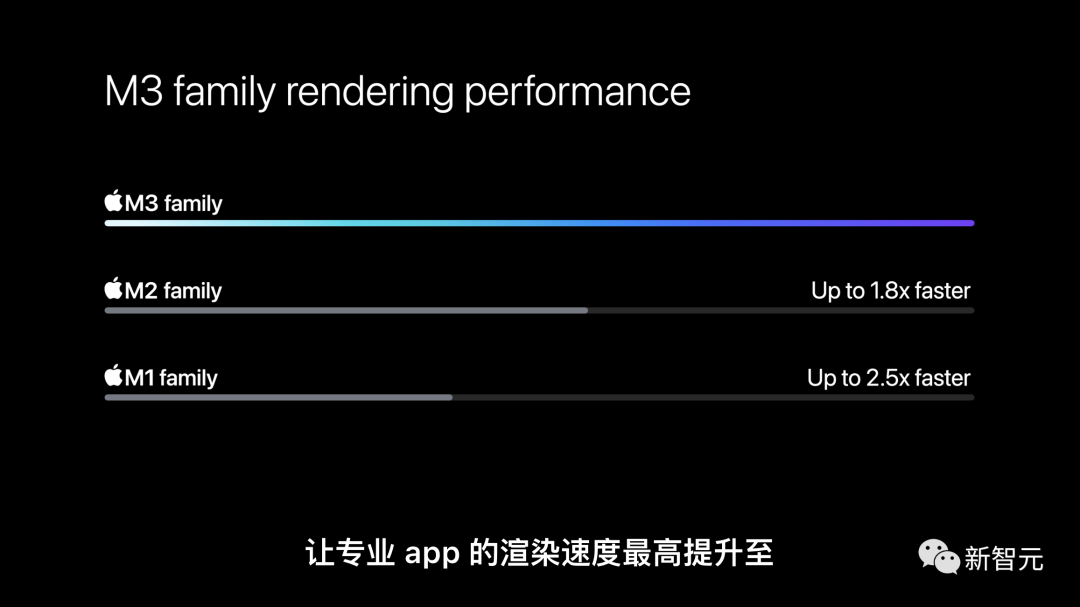
对于繁重的图形任务,这是非常惊人的提升。
突破性的新一代GPU架构,将让Mac的图形性能再上新境界。

性能功耗比惊人
M3系列的新一代CPU核心,性能核心速度最高比M1系列提升了30%,但能效依然出众。
能效核心的提升更是惊人,处理许多常见任务时,最高快50%。
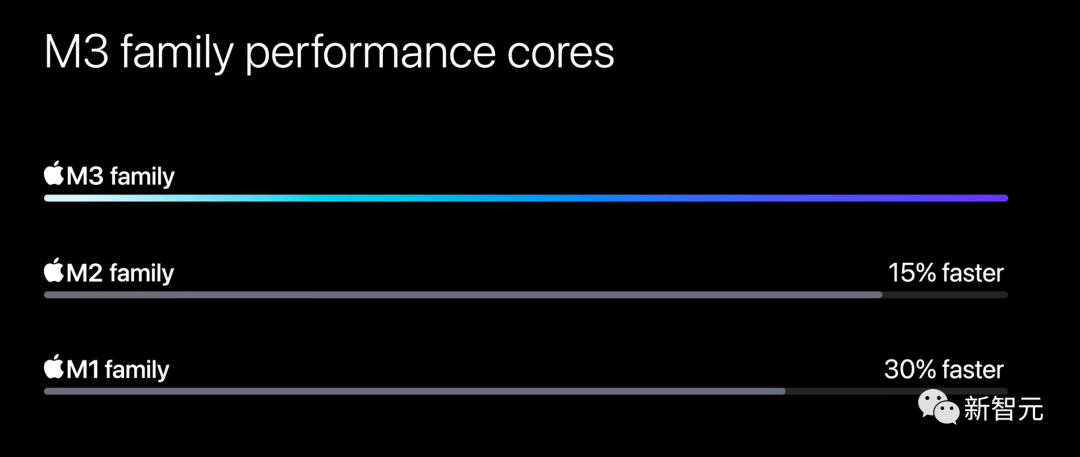
在提升架构和性能的同时,苹果还保持着傲人的性能功耗比。
这个架构在达到与M1相同的多线程CPU性能时,功耗仅为一半。
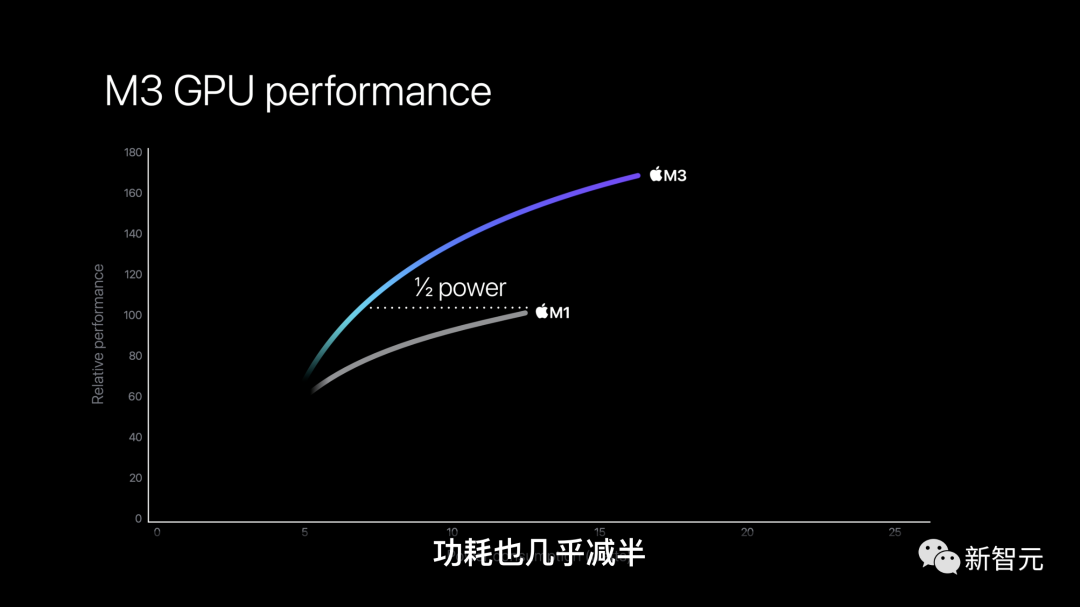
而GPU在提供与M1相同的性能时,功耗也几乎减半。
在性能功耗比上,这是巨大的提升!
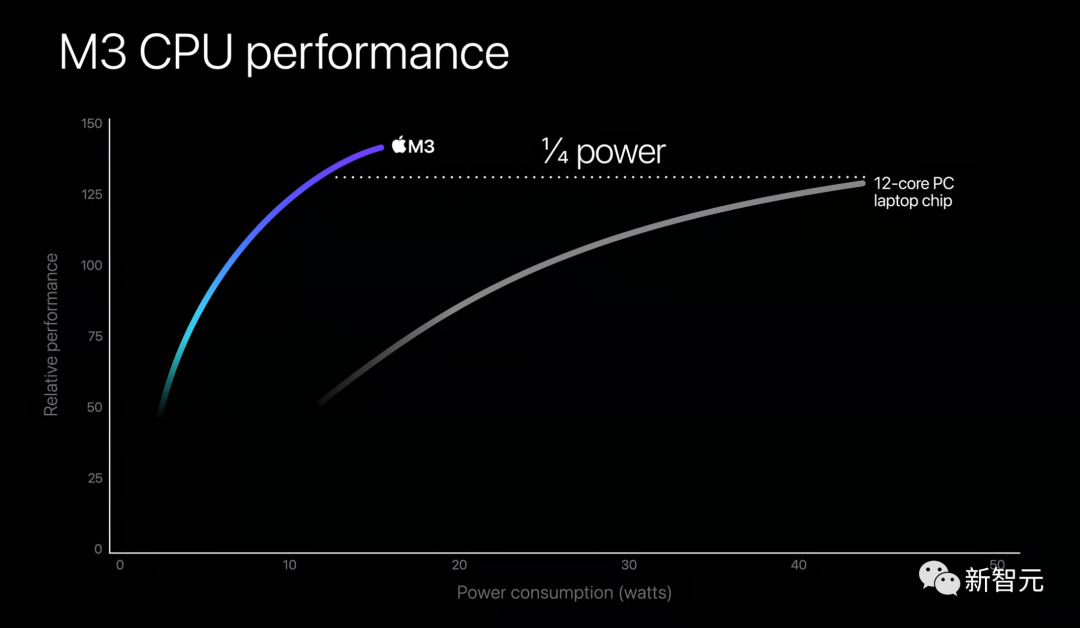
与最新的12核PC笔记本电脑芯片相比,当它提供相同的CPU性能时,只需要区区1/4的功耗。
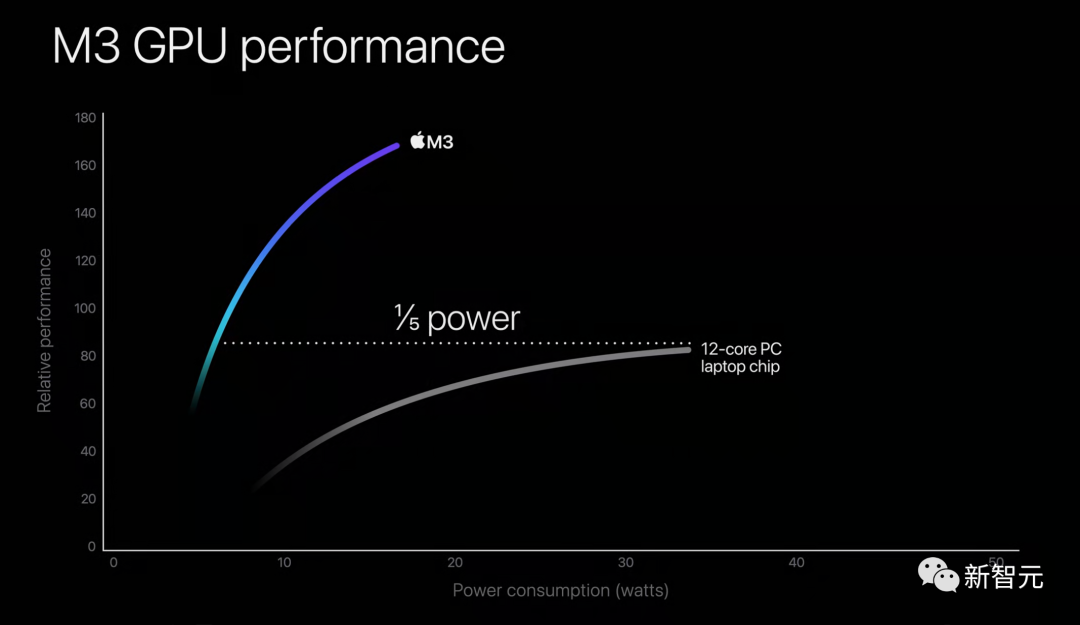
而对比GPU时,它达到相同性能的功耗仅为五分之一。
神经网络+媒体处理引擎
三款芯片的神经网络引擎也更快、更高效。
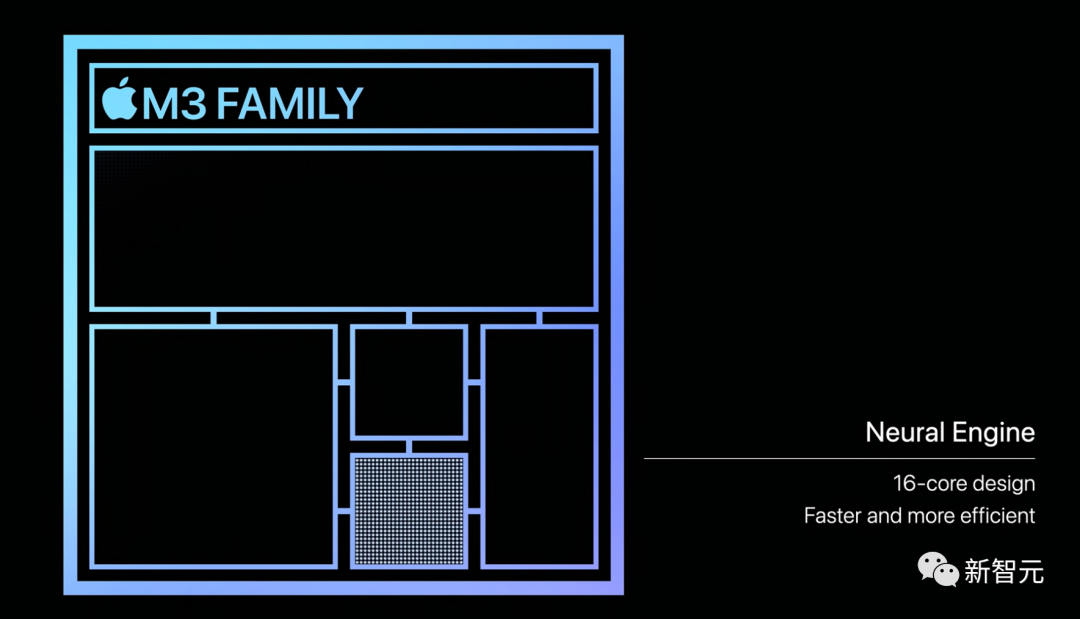
比起M1系列,提速达惊人的60%。

这不仅让AI运算更快,还能将数据保留在设备端,以保护隐私。
M3系列还拥有先进的媒体处理引擎,可以对常用的视频编解码器进行硬件加速。
现在更支持AV1,播放流媒体视频时能效更高,比如YouTube、Netflix等。
总之,M3系列芯片的这一系列先进技术,让Mac的Apple芯片大步飞跃。
MacBook Pro猛兽:高级深空黑,128GB巨量内存
这次,史诗级最强的M3系列芯片,也塞进了全新的MacBook Pro,简直是逆天升级。
配备M3芯片MacBook Pro,只有14英寸。

最高配比比M1的13英寸MacBook Pro快60%,比M2快40%。
这对于处理一些繁琐重度的工作任务来说,简直就是加速神器。硬件加速光线追踪,能够带来极致的光影效果。

接下来,出场的便是配备最强的M3 Pro和M3 Max芯片的MacBook Pro,分别有2种不同的尺寸:14英寸、16英寸。
这次,最惊艳的是,这两款笔记本新增一款惊艳配色「深空黑」,简直Pro范儿十足!
当然了,MacBook Pro也是经久耐用的,机身外观采用的定制合金,由100%的铝金属打造,用许多年都是没问题的。
同时,MacBook Pro还采用了突破性的化学工艺,在表层形成了有效减少指纹的阳极氧化层。

16英寸最新MacBook Pro,其性能比M1 Pro要提升40%,比M2 Pro提升20%。

比如,在用PS拼接和编辑巨幅全景图片时,更加丝滑。在MATLAB中处理大型数据模型时,也能加速流程。

你可以一边在MacBook Pro做任务的同时,还能外接2台分辨率的显示器。
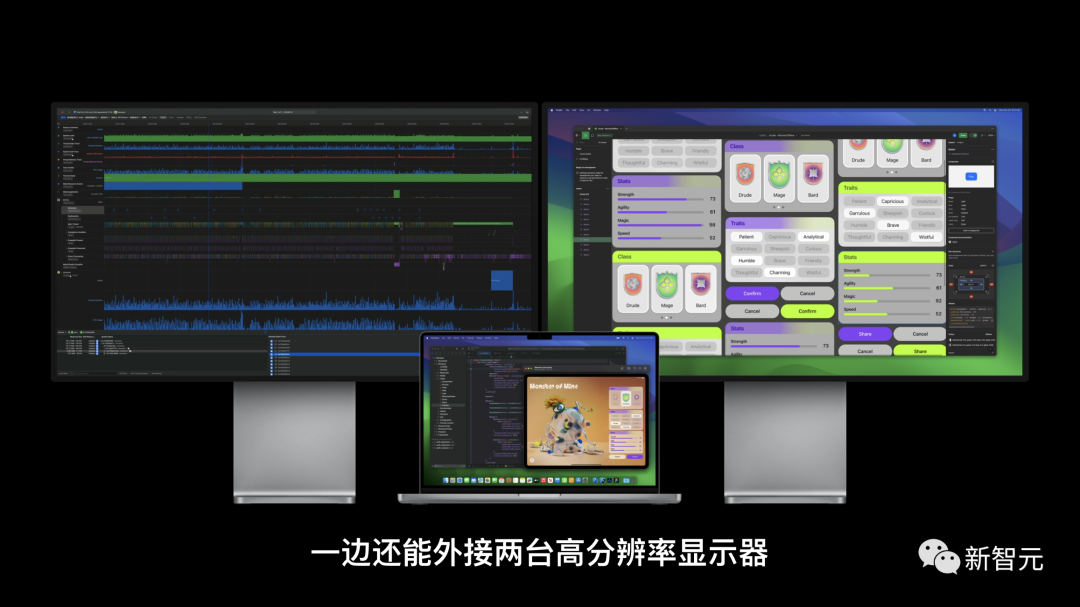
M3 Max的MacBook Pro,对于AI开发者、3D艺术家,视频工作者来说,这简直就是台猛兽。
它的性能突破了以往的极限,其速度最高达16英寸的M1 Max的2.5倍,M2 Max的2倍。

M3 Max的MacBook Pro是第一个拥有巨量内存的笔记本——128GB,可以外接4台高分辨率的显示器。
值得一提的是,MacBook Pro最高续航长达22小时,工作从早挺到晚,也是没问题了。
对于那些还在用Intel处理器的Mac用户来说,M3系列的MacBook Pro更是能够带来巅峰体验。
比最快的Intel芯片的MacBook Pro来说,速度最高可达11倍。

另外,在超强芯片的加持下,即便是工作,你也听不到风扇运行的声音。而且电池续航比Intel芯片电脑来说,延长了足足有11个小时。
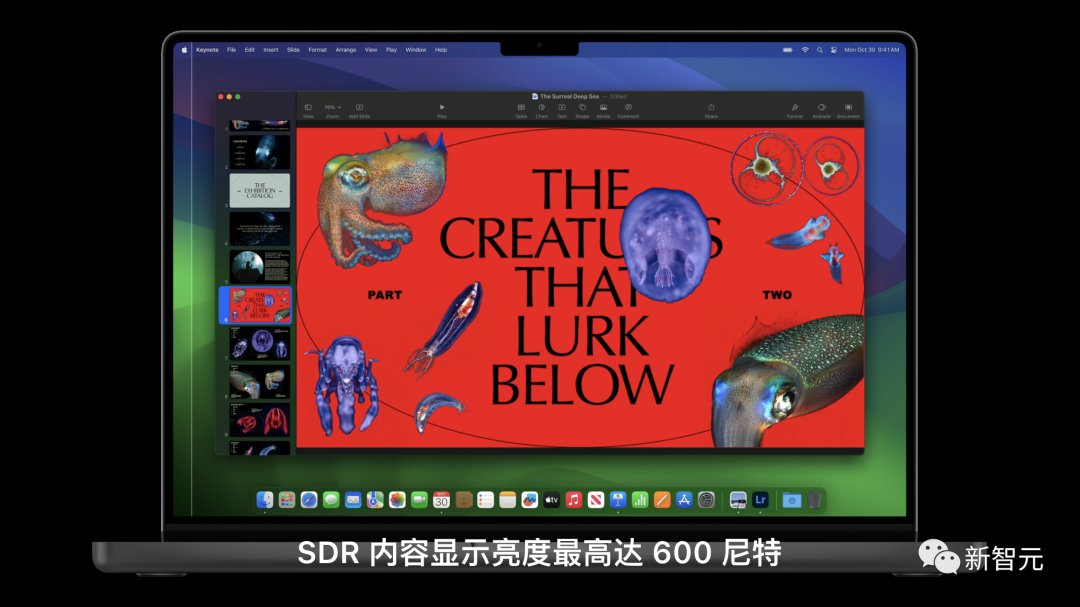
在出色的性能和续航之外,还有Liquid视网膜XDR显示屏,持续亮度为1000尼特。在显示HDR内容时,峰值亮度为1600尼特。
在新款MacBook Pro上,SDR内容显示亮度最高可达600尼特,比以往提高了20%。即便是连接外部显示屏,其亮度也能同样达到600尼特。
各种鲜艳的色彩,宽广的浏览视角,对比度足够惊人。
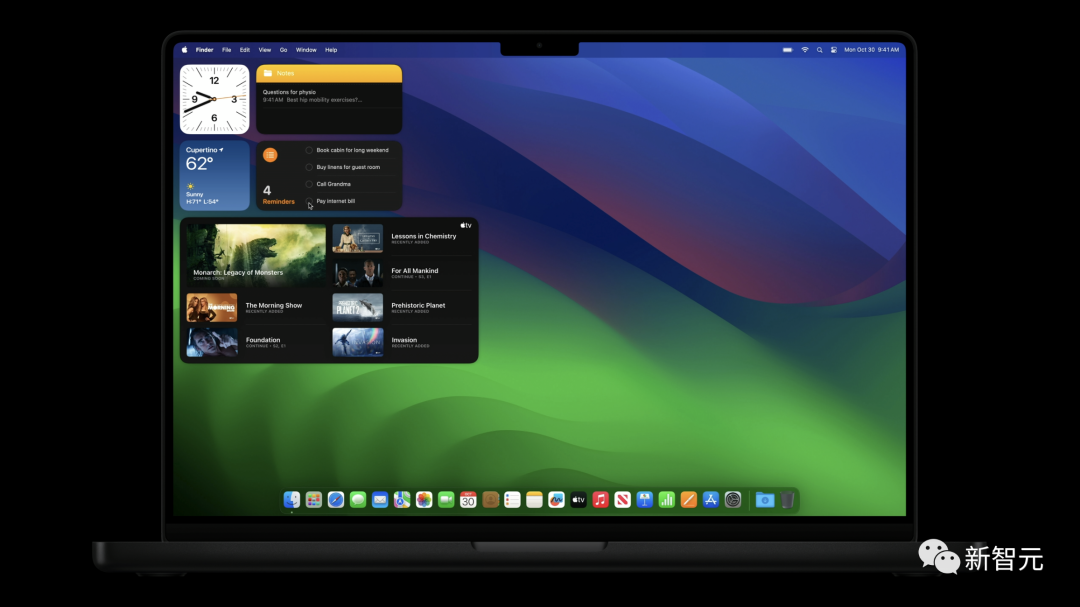
另外,为新款MacBook Pro画龙点睛的便是全新的macOS Sonoma系统。
各种桌面小组件随意组合,看天气、便签、代办事项,一目了然。
如上便是目前性能超强、实力超群的MacBook Pro,整体要点下图全览。

接下来,重点是多少钱?
售价
这次,库克特地在发布会上强调,14寸MacBook Pro的起售价比之前更低!
而担此重任的最新入门级产品就是——「丐中丐版」14寸MacBook Pro,搭载满血的M3处理器,以及不知道为何还会出现的8GB统一内存,配色是旧款的深空灰和银色,售价12999元。
除此之外,在14寸机型中,还有一款搭载了「阉割版」M3 Pro(11核CPU,14核GPU)的产品,售价16999。
相比起来,16寸MacBook Pro搭载的都是满血版M3 Pro和M3 Max处理器。
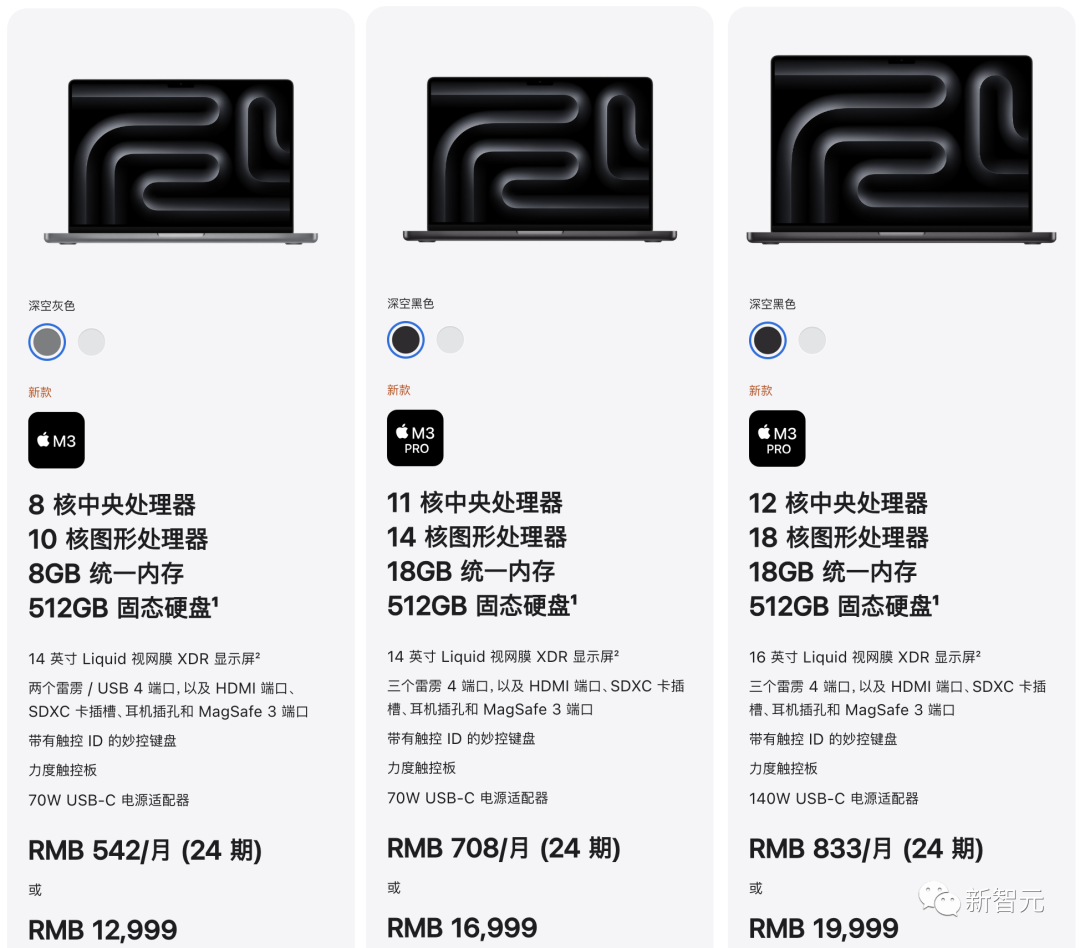
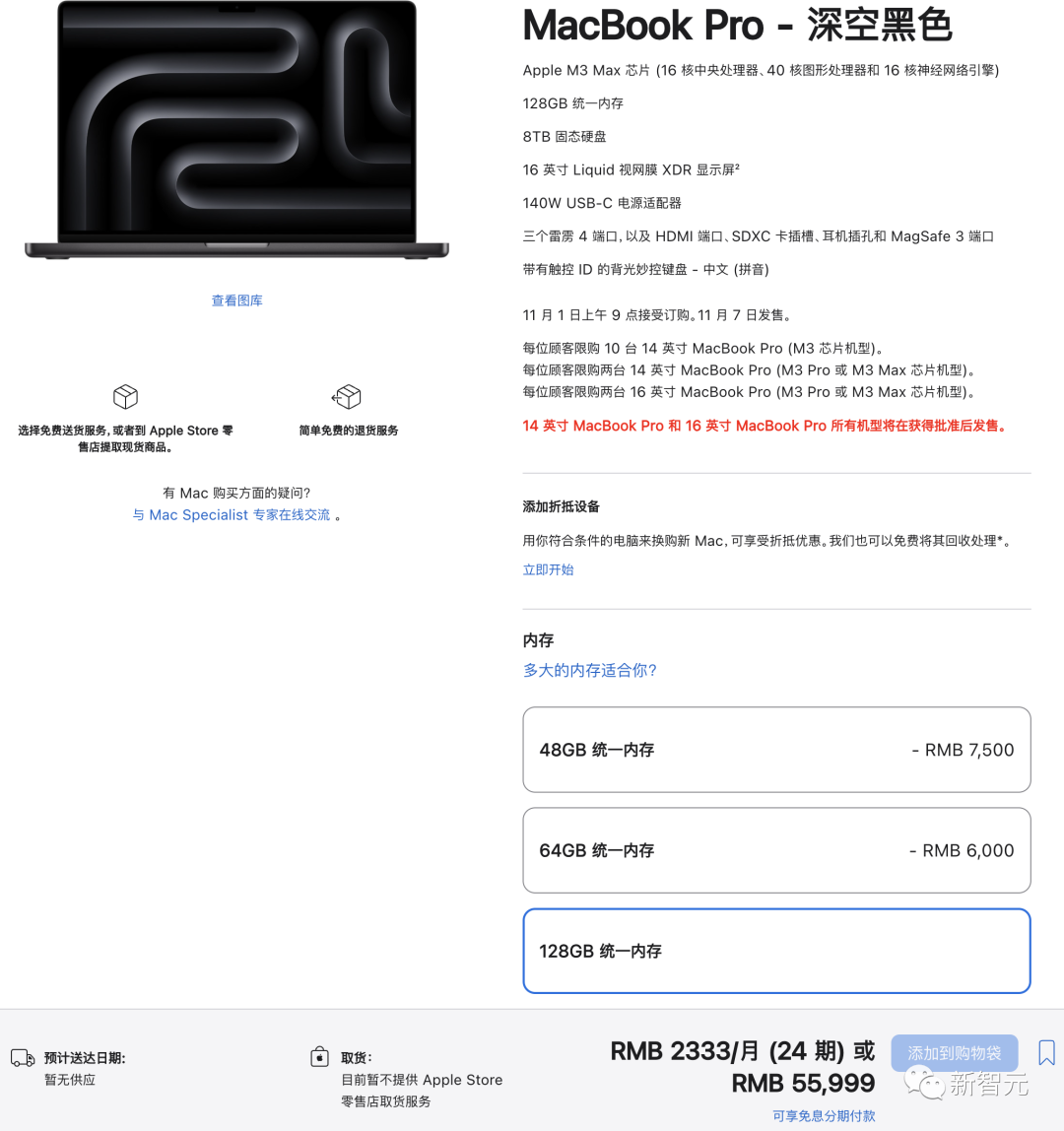
其中,搭载满血版M3 Max(16核CPU,40核GPU),128GB统一内存,8TB固态硬盘的顶配16寸MacBook Pro,售价高达55999。
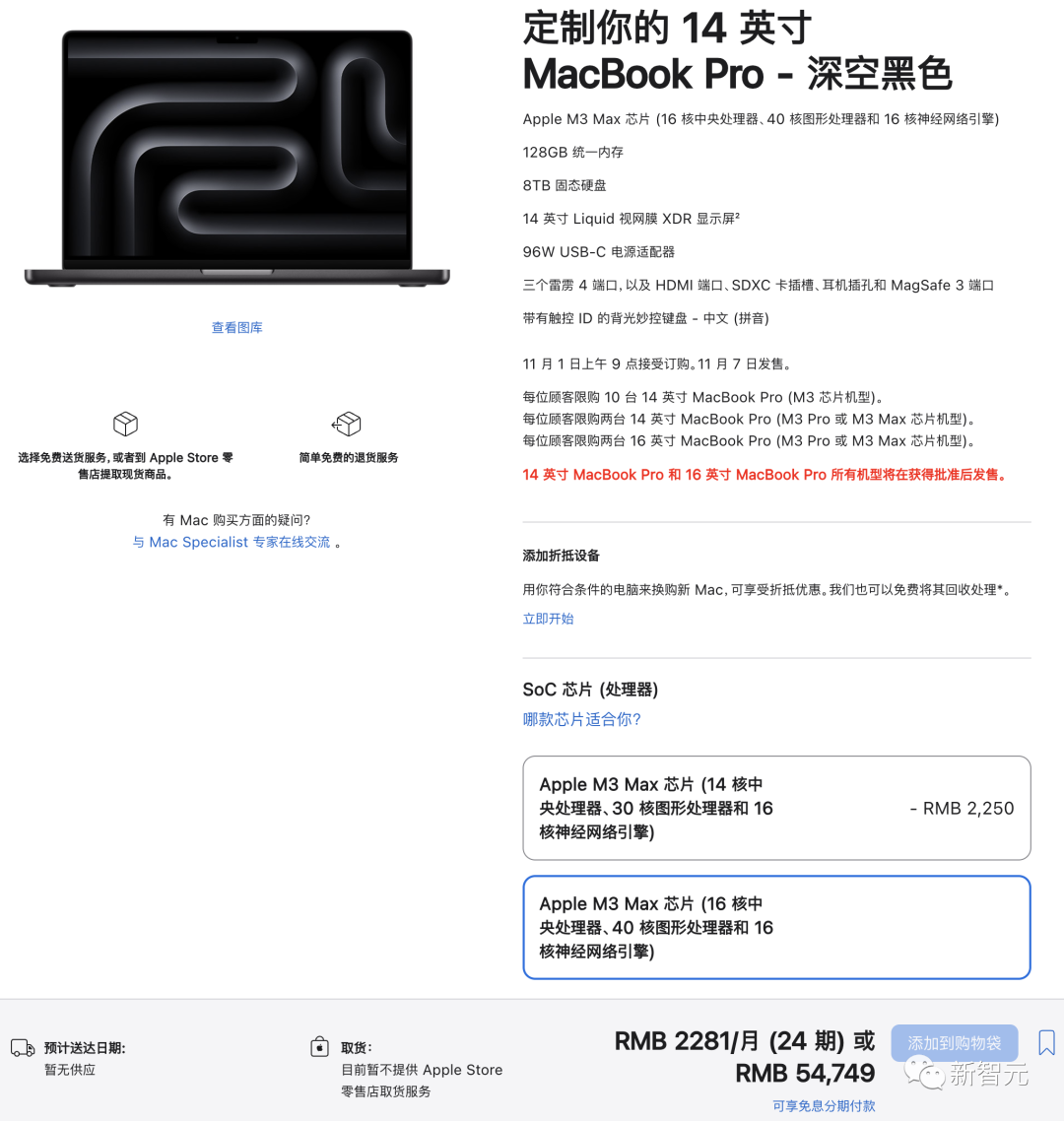
而高配版14寸机型,默认搭载的是残血版M3 Max(14核CPU,30核GPU)。想要升级成满血版,则需再加2250元。
值得注意的是,残血版M3 Max只支持36GB和96GB两种规格的内存,而满血版为48GB、64GB和128GB。
选择相同的配置之后,顶配的14寸MacBook Pro售价为54749元,比16寸便宜了1250元。
24英寸iMac首升级,速度飙升2倍
当然了,除了MacBook Pro,也少不了iMac的更新。
还记得苹果上一次更新iMac,是在2021年4月,当时推出了配备M1芯片的标志性一体机。
时隔2年,苹果终于推陈出新,而且还是把最强的M3芯片,装在iMac上。
这次不变的是,iMac还是7种配色,显示屏尺寸依旧是24英寸。
在性能方面,速度是M1芯片iMac的2倍。

比起27英寸的ntel芯片的iMac来说,新款速度最高提升2.5倍。而与顶配的21.5英寸iMac相比,速度最高提升4倍。

显示屏有1100万颗像素,500尼特亮度,就像一块可扩展的画布,可呈现超过十亿的色彩。
最重要的是,你能够在4.5K视网膜显示屏上,体验沉浸感十足的画面。
再加上1080p FaceTime摄像头,空间音频的六扬声器系统,录音棚级的麦克风,简直强的一批。
如上便是全新配备M3芯片的超凡一体机iMac,所有功能如下图所示。

售价
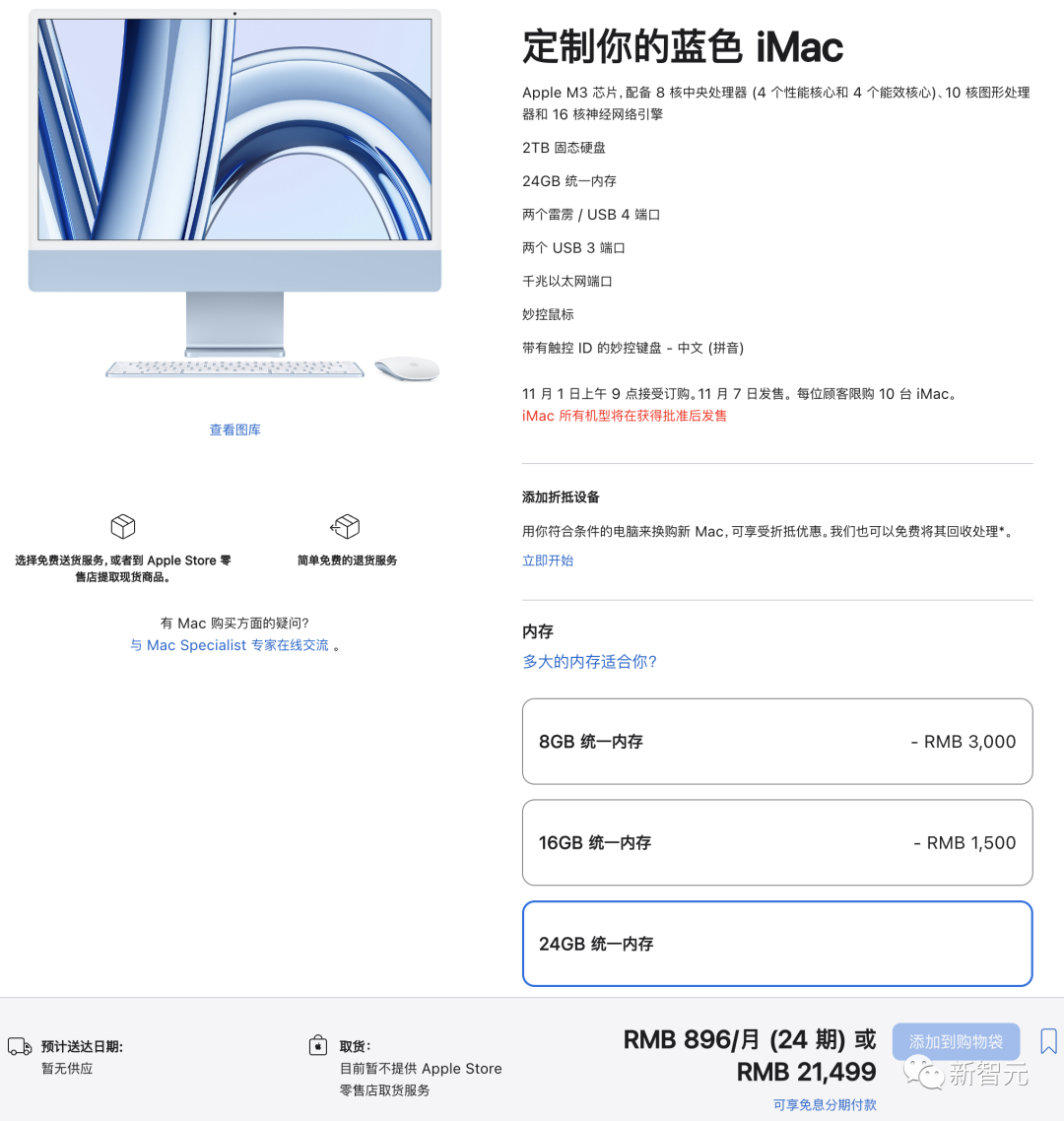
M3版iMac的规格较之前变化不大,售价10999元起步。
具体来说,有「阉割版」M3处(8核CPU/8核GPU)和满血版M3(8核CPU/10核GPU)可选,8GB内存、256GB储存起步。

在选配最高24GB统一内存和2TB固态硬盘之后,售价来到了21499元。
参考资料:
https://www.apple.com/apple-events/event-stream/?_=1698712195390
这篇关于全球首款3nm芯片塞进电脑,苹果M3炸翻全场!128GB巨量内存,大模型单机可跑,性能最高飙升80%的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








