本文主要是介绍星环科技分布式向量数据库Transwarp Hippo正式发布,拓展大语言模型时间和空间维度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

随着企业、机构中非结构化数据应用的日益增多以及AI的爆发式增长所带来的大量生成式数据,所涉及的数据呈现了体量大、格式和存储方式多样、处理速度要求高、潜在价值大等特点。但传统数据平台对这些数据的处理能力较为有限,如使用文件系统、多类不同数据库存储上述数据,在数据存储管理、查询分析效率、数据价值挖掘等方面都存在一定的瓶颈,例如传统数据库查询是点查和范围查的一种精确查询,无法满足大模型下如智能问答、智能推荐等场景。
因此,企业急需一款或数款管理好非结构化数据的数据管理平台。业内常用的做法,是利用人工智能中的表示学习,将这些非结构化数据抽象、转换为高维度的多维向量,由此可以结构化地在向量数据库中进行管理,实现快速、高效的数据存储和检索过程,结合相似性检索特性,进而更高效地支撑更广泛的应用场景,比如智能推荐场景等。同时,随着大语言模型应用中对长文本处理和领域知识表示使用的深入,对向量数据库的需求也日益迫切。
近日,在向星力•未来数据技术峰会上,星环科技正式发布了分布式向量数据库Transwarp Hippo。作为一款企业级云原生分布式向量数据库,星环分布式向量数据库Hippo支持存储、索引以及管理海量的向量式数据集,提供向量相似度检索、高密度向量聚类等能力,有效地解决了大模型在知识时效性低、输入能力有限、准确度低等问题,让大模型更高效率地存储和读取知识库,降低训练和推理成本,激发更多的AI应用场景。在赋予大模型拥有“长期记忆”的同时,还可以协助企业解决目前最担忧的大模型数据隐私泄露问题。
大模型的快速应用,推动向量数据库向高扩展、高性能、实时性方向发展
![]()
大模型正在与企业应用迅速结合,重塑企业应用中人与数据的交互方式。然而,不管是通用模型,还是微调出来的行业模型,都存在着一定的局限性:
-
实时性难题:模型训练需要很长的时间,可能需要半年或一年,实时资讯、新闻、市场行情等快速变化的信息,无法及时地内置到模型当中。
-
长Token难题:大模型的输入Token(文本中的最小单位)能力受到算力和工程化程度的限制。在这种限制下,例如无法将一家上市公司的全部年报数据输入进大模型,导致不能进行全面的分析。
-
精度校正难题:大模型虽然经过大量数据的长期训练,但很多场景下精准度还是不够,需要补充知识库进行校正,让其能够给出更准确的结果和更实时的信息。
目前,大模型训练所使用的数据包含了如文档、图片、音视频等各种类型的非结构化数据。用户可以通过表示学习的预处理方式将这些数据转化为多维向量,并存储在向量数据库中,从而可以很好地解决上述三个问题。比如,在应用端与大模型进行交互时,将输入的文字、图片等问题信息进行向量化,先进行语义搜索,找到相关的信息,将其拼接成提示词传递给大模型,大模型通过计算分析后反馈结果。
星环科技创始人、CEO孙元浩表示,“向量数据库承担了中间存储的角色,我们认为向量数据库就是大语言模型的海马体,是一个记忆体。其基本功能是能够存储多维向量,并提供进一步的检索。”
向量数据库早先被用于文本搜索或者语义搜索,过去不少公司用来做个性化推荐、构建知识图谱等。随着大模型的兴起,向量数据库可以让大模型更高效率地存储和读取知识库,并以更低的成本进行模型微调,进一步地激发AI应用场景。此外,几千、上万种应用带来海量的数据,需要一个高扩展的向量数据库来存放更多的数据信息。而向量数据复杂度的提升,模型推理速度的加快等也要求能够提供高性能的检索能力。实时动态变化的数据,对向量数据库的实时写入、实时更新、实现召回能力的要求变高,通过将实时资讯、实时新闻、市场行情等快速变化的信息及时地内置到模型中,使其能够提供更实时、更精准的结果。
星环科技分布式向量数据库Transwarp Hippo
![]()
星环分布式向量数据库Hippo作为一款企业级云原生分布式向量数据库,基于分布式特性,可以对文档、图片、音视频等多源、海量数据转化后的多维向量进行统一存储和管理。通过多进程架构与GPU加速技术,充分发挥并行检索能力,实现毫秒级高性能数据检索,结合相似度检索等技术,帮助用户快速挖掘数据价值。
与开源的向量数据库不同,星环分布式向量数据库Hippo具备高可用、高性能、易拓展等特点,支持多种向量搜索索引,支持数据分区分片、数据持久化、增量数据摄取、向量标量字段过滤混合查询等功能,很好地满足了企业针对海量向量数据的高实时性检索等场景。
云原生技术,支持弹性扩缩容
星环分布式向量数据库Hippo采用全面容器化部署,支持服务的弹性扩缩容,同时具备多租户和强大的资源管控能力。
高扩展性,海量向量数据存储
与直接利用各类算法lib不同,星环Hippo存储和计算都可以充分利用分布式特性,按需灵活扩展,满足大规模集群部署需求;通过Raft算法确保数据的强一致性;并提供故障迁移,数据修复等数据保障能力。
深度优化,高性能数据检索
星环分布式向量数据库Hippo支持多进程架构与GPU加速,充分发挥并行检索能力;支持基于检索速度和内存使用的特定优化,以及寄存器级算法优化;同时提供多类索引支持,满足不同需求不同体量的业务场景。
动态更新,实时检索
星环分布式向量数据库Hippo提供数据动态更新的能力,对于实时插入/更新的数据,可以快速完成数据的加载和索引的构建,解决向量数据T+1的传统处理逻辑,满足实时动态变化数据的向量检索分析。
多样化接口,丰富场景支持
星环分布式向量数据库Hippo供标准的Python、Restful、CPP、Java API等接口,可轻松对接各类应用和模型,提高应用开发和调用的效率。同时,提供类SQL接口,满足入库等特定场景,大幅降低使用和操作的难度。
多模型联合
基于TDH多模型统一技术架构,向量数据与关系型数据、图数据、时序数据等多种模型数据可进行统一存储管理,并通过统一接口实现数据跨模型联合分析。
具备高可用、高性能、易拓展等特点的星环分布式向量数据库Hippo,可以很好地满足企业针对海量向量数据的高实时性等场景。
文本检索
传统搜索引擎更偏向于词/句的精确查询,星环分布式向量数据库Hippo通过向量引擎提供自然语言处理能力,可以更好地支持基于语义的查询分析,让查询更满足人性化的需求。
语音/视频/图像检索
星环分布式向量数据库Hippo将多维向量特征构建成高效的向量索引,实现数据的相似性检索,可覆盖人脸识别、语音识别、视频指纹等多类AI场景。
个性化推荐
星环分布式向量数据库Hippo可与各类深度学习平台搭建的模型进行耦合,通过向量相似度检索,可以对用户行为与喜好等多方面进行分析、挖掘,做到千人千面的推荐效果。
智能搜索,智能问答
知识图谱的目的在于将结构化数据、非结构化数据以及这些数据、实体之间的关联关系进行存储和表达。通过星环分布式向量数据库Hippo可以将这些信息更好地进行表达和处理,给出符合需求的一系列近似答案和推荐查询。
向量数据库与图数据库联合,低成本、高效构建特定领域大模型应用
![]()
基于星环分布式向量数据库Hippo,可以有效地解决大模型在知识时效性低、输入能力有限、准确度低等问题。通过将最新资料、专业知识、个人习惯等海量信息向量存储在星环分布式向量数据库Hippo中,可以极大地拓展大模型的应用边界,让大模型保持信息实时性,并能够动态调整,使大模型拥有“长期记忆”。
通过建立垂直领域的知识库,对大模型输出结果进行校正,可以提高结果的精准度,在一定程度上解决“AI幻觉”问题。
此外,通过星环分布式向量数据库Hippo对向量数据进行存储,有效解除大模型对输入的限制,并且大模型在安全机制下访问向量数据库中的隐私数据,可以充分保证数据安全,杜绝隐私泄露风险。

然而,大模型只有向量数据库还不够。在召回的基础上通过提示工程确保数据更精确,更贴近实际场景,同样也是重要的一环。星环科技将分布式向量数据库Hippo和分布式图数据库StellarDB结合,并以此作为微调的数据凭依,可以更低成本、更高效地构建特定领域的大模型应用。
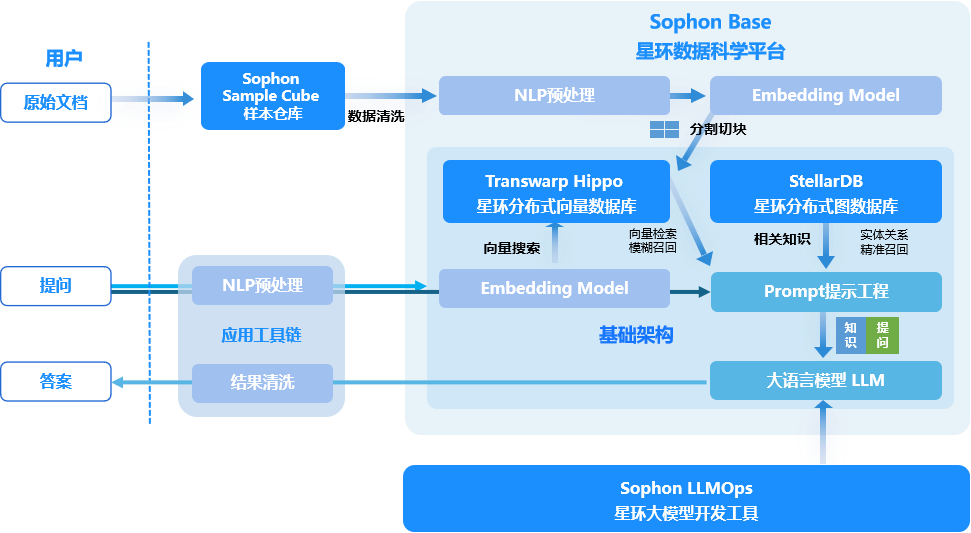
图数据库StellarDB和知识图谱联合,与大模型可视化端到端构建工具一起,提供了知识抽取融合、知识建模、知识图谱生成存储、基于大模型的知识问答等闭环功能。客户以知识图谱作为大语言模型提示即可发起模型微调,以较低代价就可获得行业的专属大语言模型问答应用。
将向量数据库、图数据库与大语言模型结合,可以构建业务域知识图谱和业务系统的应用服务,进一步提高人机交互的效率,提供更灵活的组合业务服务,激发出更多更深入的业务场景AI应用。
例如,在询问某开源通用大模型关于某集团玉米收储价格、某集团主要合作上下游企业等问题,通用大模型没有行业知识,无法给出准确答案。而把农业知识图谱和向量数据库结合后,可以从知识图谱中去获取或者补充大模型的答案,使其可以精确地回答新收猪价以及价格影响等。
通过这样的组合可以解决大模型目前存在的三大问题。一是能够把实时的知识、变化的信息放到大模型中,二是能够校正结果的准确性,极大地提升精准度,三是构建相应的知识图谱,增强大模型的能力。
在星环科技此次推出的金融领域大模型“无涯”中,基于星环科技自身在金融领域积累的上百万金融专业领域的语料,结合图数据库StellarDB、深度图推理算法技术,形成了大规模高质量的金融类事件训练指令集,共同铸就了星环开发金融领域大语言模型的坚实底座。星环“无涯”大模型能够理解金融行业的术语,也能够执行特定的任务,比如分析上市公司的年报、公告,生成新闻摘要,判断特定新闻事件产生的影响等,提升分析师、研究员、投资经理的效率。
这篇关于星环科技分布式向量数据库Transwarp Hippo正式发布,拓展大语言模型时间和空间维度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








