本文主要是介绍撕开黑幕!AI担任拳击比赛裁判;思维导图工程图表工具大合辑;CVPR视觉-语言的预训练最新进展;游戏开发资源列表;前沿论文 | ShowMeAI资讯日报,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

👀日报合辑 | 📆电子月刊 | 🔔公众号下载资料 | 🍩@韩信子
📢 DeepStrike:人工智能担任拳击比赛裁判
https://superinnovators.com/2022/10/ai-boxing-judge/
拳击评分容易出现人为错判、腐败或法官带有偏见的故意操纵。2016 年里约奥运会拳击锦标赛就被调查发现了贿赂的证据。丹麦初创公司 Jabbr 的机器学习工程师开发了一个名为 DeepStrike 的 AI 模型,自动分析了使用摄像头分析拳击比赛的性能。
DeepStrike 使用深度学习来衡量 50 个指标,包括出拳类型、出拳落点、质量、步法、侵略性、压力等。这项创新可用于取代拳击裁判,确保结果公平,也可以为运动员提供训练数据统计与分析,帮助提升运动员成绩。

工具&框架
🚧 『WeTextProcessing』为中文设计的文本规则化和文本反规则化工具包
https://github.com/wenet-e2e/WeTextProcessing
WeTextProcessing 是一个为中文设计的,可以把文本规则化(比如一些阿拉伯数字的日期、时间和数量转化为中文)和反规则化的工具包。
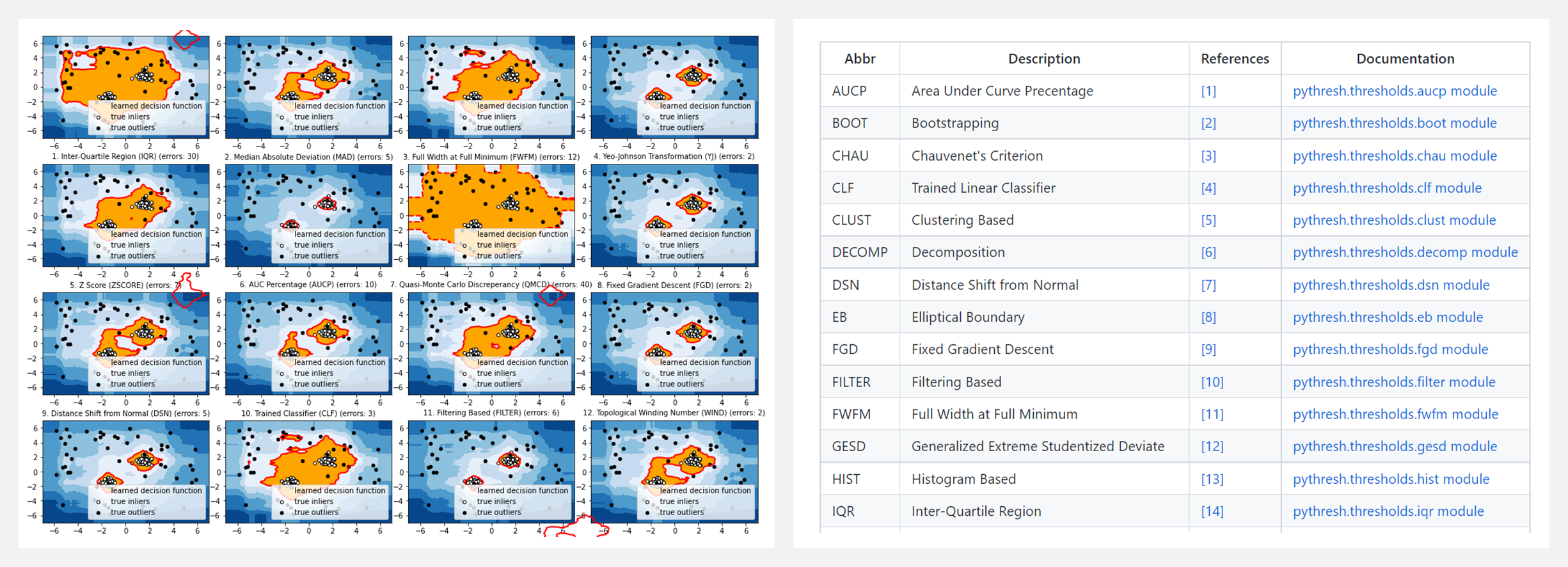
🚧 『Python Outlier Detection Thresholding (PyThresh)』 Python离群点检测阈值决策库
https://github.com/KulikDM/pythresh
PyThresh 是一个 Python 工具包,用于对单变量/多变量数据中的离群点检测分数进行阈值化。它可以与 PyOD 协同工作,具有类似的语法和数据结构,区别在于 PyThresh 是用来对离群点检测产生的分数进行阈值处理的,它不需要设置边界阈值,也无需定义异常值数量。
这个工具库下的离群点检测分数遵循这个规则:分数越高,它是数据集中的离群点的概率就越高。所有的阈值函数都返回一个二进制数组,其中 liers 和 outliers 分别用 0 和 1 表示。
PyThresh 包括 30 多种阈值处理算法。这些算法的范围从使用简单的统计分析(如Z-score)到涉及图论和拓扑学的更复杂的数学方法。
🚧 『Zshot』零样本和少样本命名实体识别与关系识别
https://github.com/IBM/zshot
https://ibm.github.io/zshot/
Zshot 是一个高度可定制的框架,用于零样本和少样本的命名实体识别。可以在指代抽取、将文本指代与维基百科中的实体联系起来等场景发挥作用。

🚧 『CORL (Clean Offline Reinforcement Learning)』最新强化学习算法的单文件高质量实现
https://github.com/tinkoff-ai/CORL
CORL 是一个离线强化学习库,为 SOTA ORL 算法提供了高质量和易于理解的单文件实现。每个实现都有一个便于研究的代码库支持,能运行或调整成千上万的实验。
博文&分享
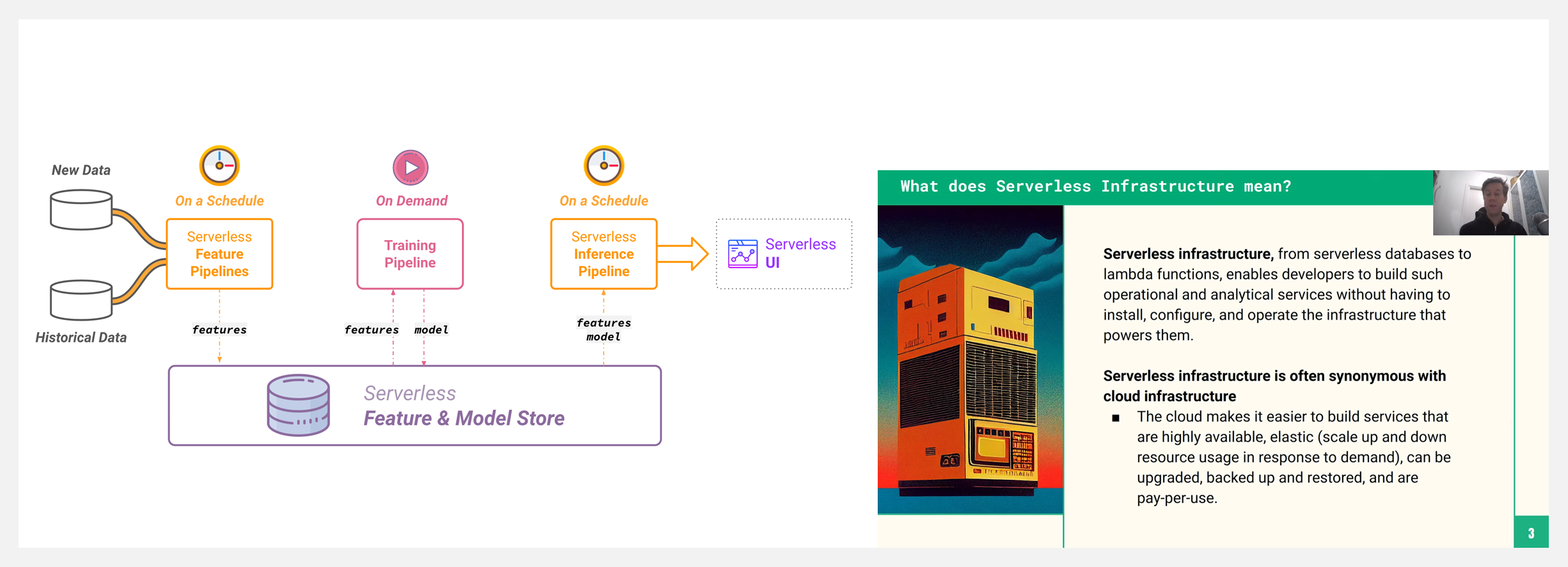
👍 『Serverless ML』从模型和特征开始,构建AI预测Serverless机器学习应用·课程
https://github.com/featurestoreorg/serverless-ml-course
无需成为 Kubernetes 或云计算方面的专家,即可构建端到端服务,并借助 ML 模型做出智能决策。无服务器 ML 可以轻松构建使用 ML 模型进行预测的系统。
只需要能够编写可以作为管道运行的 Python 程序,管道生成的功能和模型由无服务器功能存储/模型注册表管理。课程还将展示如何通过编写 Python 和一些 HTML 来构建 UI。课程包括以下模块:

- Pandas and ML Pipelines in Python, Write your first serverless App(Python 中的 Pandas 和 ML 管道,编写你的第一个无服务器应用程序)
- Data modeling and the Feature Store, The Credit-card fraud prediction service(数据建模和特征存储,信用卡欺诈预测服务)
- Training Pipelines, Inference Pipelines, and the Model Registry(训练管道、推理管道和模型注册表)
- Bring a Prediction Service to Life with a User Interface(通过用户界面实现预测服务)
- Automated Testing and Versioning of features and models(功能和模型的自动化测试和版本控制)
- Real-time serverless machine learning systems, Project presentation(实时无服务器机器学习系统,项目介绍)
👍 『Recent Advanced in Vision-and-Language Pre-training』CVPR2022 Tutorial | 视觉-语言的预训练 · 最新进展
https://vlp-tutorial.github.io/2022/
人类通过许多渠道感知世界,例如眼睛看到的图像或耳朵听到的声音。尽管任何单个通道都可能不完整或嘈杂,但人类可以自然地对齐和融合从多个通道收集的信息,以便掌握更好地理解世界所需的关键概念。
人工智能的核心愿望之一是开发算法,使计算机能够有效地从多模态(或多通道)数据中学习。这些数据类似于从视觉和语言中获得的视觉和声音,帮助人类理解我们周围的世界。视觉-语言 (Vision-and-Language,VL) 是一个受欢迎的研究领域,位于计算机视觉和自然语言处理 (NLP) 的结合处,旨在实现这一目标。

受 NLP 中语言模型预训练的巨大成功的启发,视觉和语言预训练(VLP)最近引起了关注。在本教程中,我们将介绍 VLP 前沿的最新方法和原则,包括:
- 基于区域特征和端到端图像文本预训练
- 统一的视觉语言建模
- 扩展到视频语言预训练
- 从语言监督中学习视觉模型
- 视觉合成

数据&资源
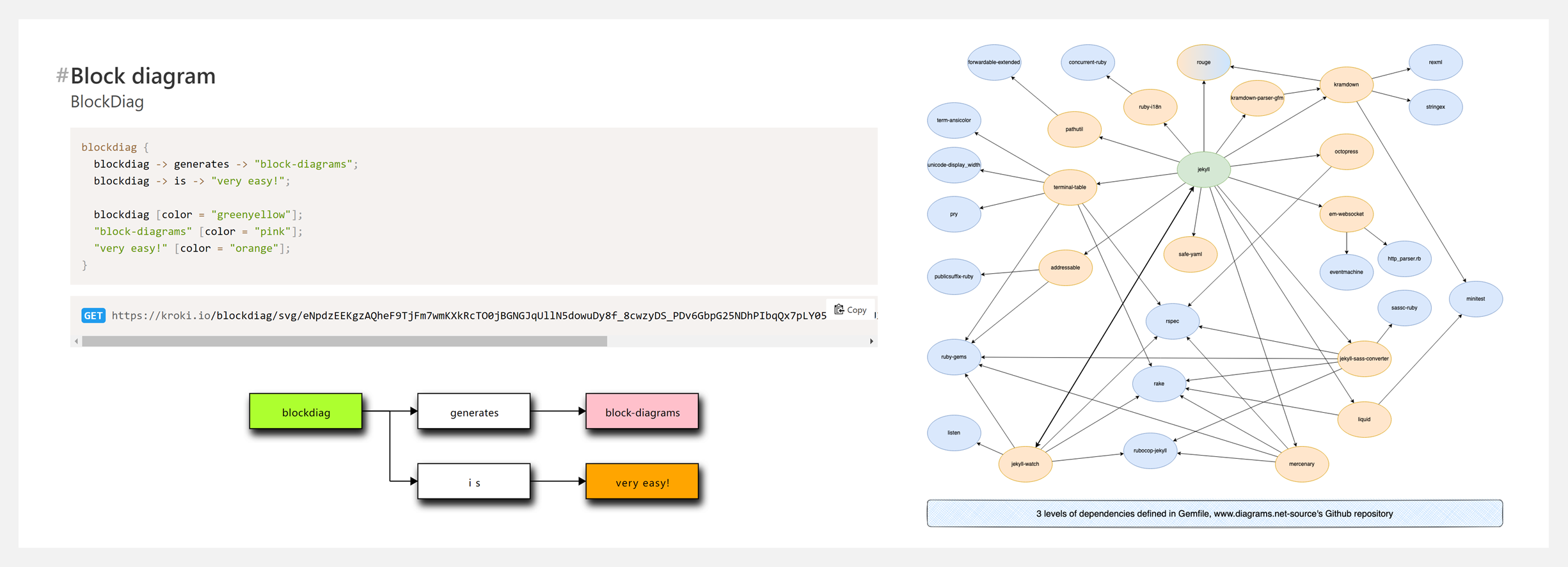
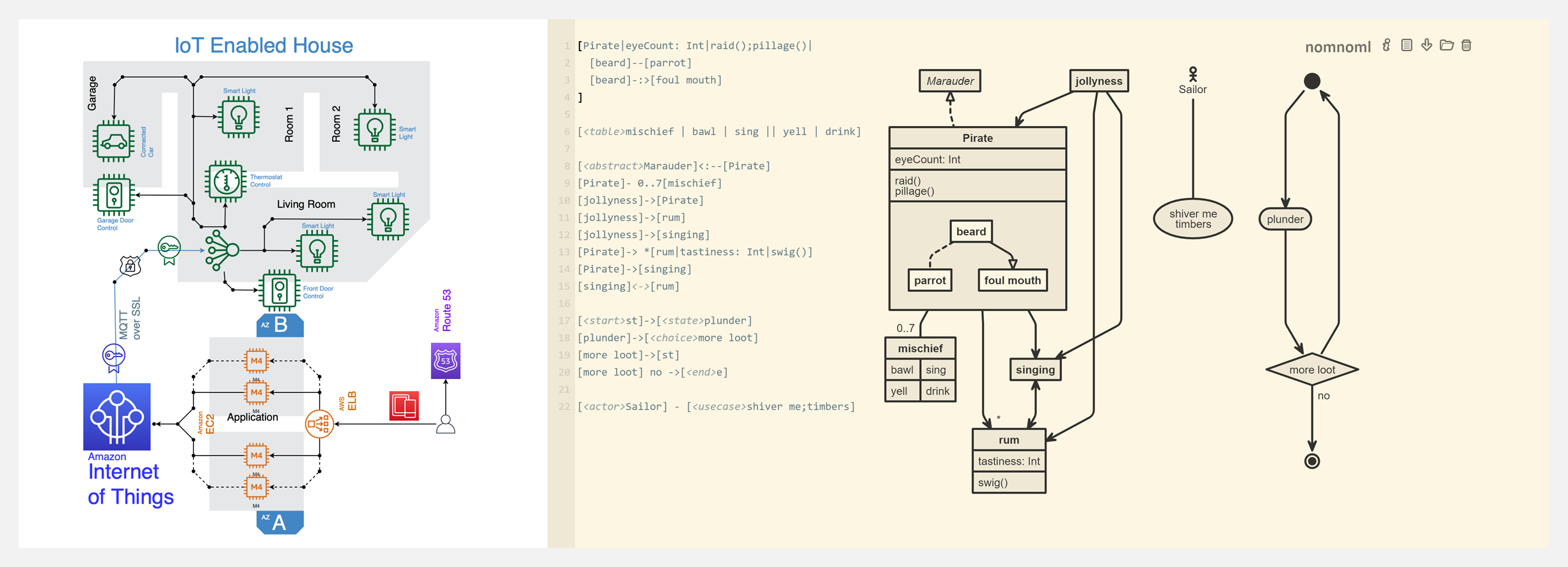
🔥 『Awesome Diagramming』软件工程团队图表工具大列表
https://github.com/shubhamgrg04/awesome-diagramming
图表可以提供软件设计高级概览,序列图、系统架构图、ER图、甘特图等是工程团队使用最广泛的图表。Repo 考虑了免费、开源、便捷、代码/手绘、视觉外观等要素,汇总了最常用的可视化图表软件。

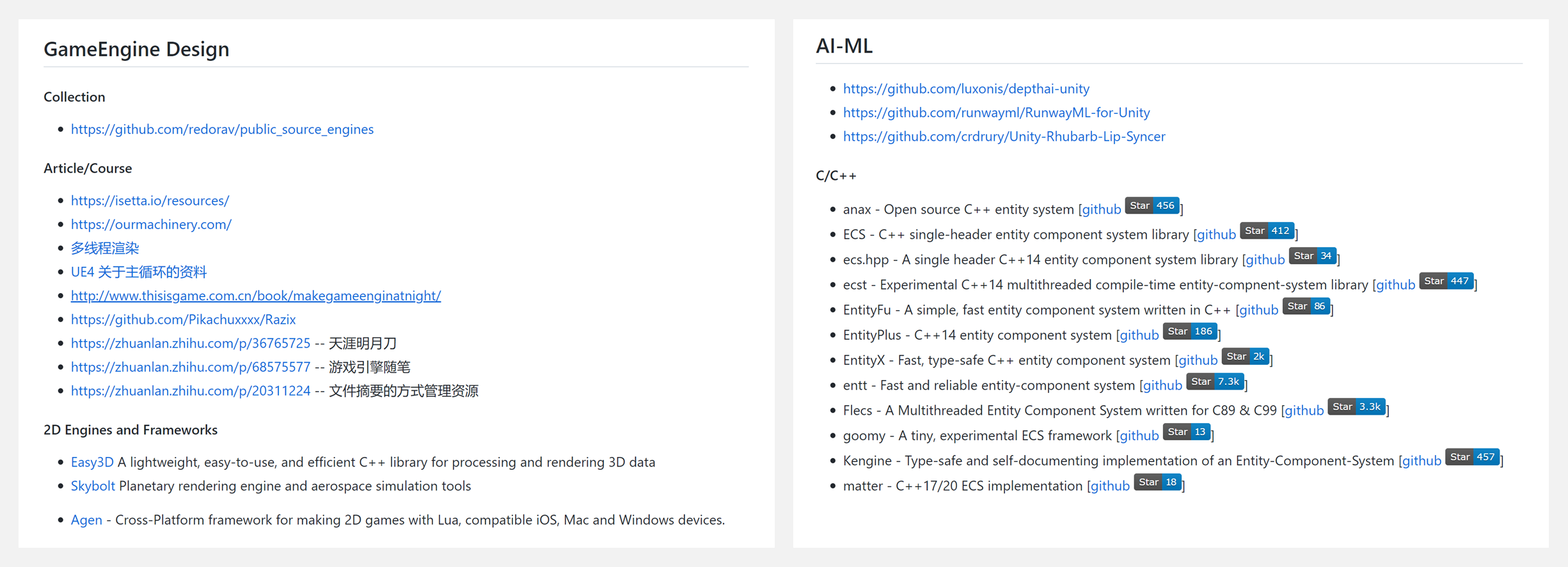
🔥 『Awesome-Game』游戏开发资源大列表
https://github.com/killop/anything_about_game
这是一份游戏开发资源的大列表,囊括了非常丰富的内容!以下选取部分主题,有需求的读者可以访问上方GitHub连接:
- News(新闻)
- Person/Social/Blogs(人物/社交/博客)
- Game-Company(游戏公司)
- Game-Asset(游戏资产)
- Game-Design-Tool(游戏设计工具)
- Animation(动画)
- 3D Rendering Software/Plugin(3D 渲染软件/插件)
- Game-Server-framework(游戏服务器框架)
- AI-ML(人工智能-机器学习)
- File Systems(文件系统)
- GameEngine Design(游戏引擎设计)
- GameAI(游戏人工智能)
- Game-Math(游戏数学)
- Game-BenchMark/Metric/Tool(游戏基准/公制/工具)
- ComputerGraphics && Shading(计算机图形 && 阴影)
- DataStruct-Algorithms(数据结构与算法)
- 文案排版
- 游戏策划
- ······
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.27 『文本生成』 EditEval: An Instruction-Based Benchmark for Text Improvements
- 2022.10.04 『音频分类』 Learning the Spectrogram Temporal Resolution for Audio Classification
- 2022.10.04 『表征学习』 One Transformer Can Understand Both 2D & 3D Molecular Data
⚡ 论文:EditEval: An Instruction-Based Benchmark for Text Improvements
论文时间:27 Sep 2022
领域任务:Text Generation,文本生成
论文地址:https://arxiv.org/abs/2209.13331
代码实现:https://github.com/facebookresearch/editeval
论文作者:Jane Dwivedi-Yu, Timo Schick, Zhengbao Jiang, Maria Lomeli, Patrick Lewis, Gautier Izacard, Edouard Grave, Sebastian Riedel, Fabio Petroni
论文简介:Evaluation of text generation to date has primarily focused on content created sequentially, rather than improvements on a piece of text./迄今为止,对文本生成的评价主要集中在按顺序创建的内容上,而不是对一段文本的改进。
论文摘要:迄今为止,对文本生成的评价主要集中在按顺序创建的内容上,而不是对一段文本的改进。然而,写作自然是一个迭代和增量的过程,需要不同模块技能的专业知识,如修复过时的信息或使风格更加一致。即便如此,对一个模型执行这些技能的能力和编辑能力的全面评价仍然是稀缺的。我们提出了EditEval:一个基于指令的基准和评估套件,利用高质量的现有和新的数据集来自动评估编辑能力,如使文本更有凝聚力和改写。我们评估了几个预训练的模型,这表明InstructGPT和PEER表现最好,但大多数基线都低于监督的SOTA,特别是在中和和更新信息时。我们的分析还表明,常用的编辑任务指标并不总是有很好的相关性,对具有最高性能的提示的优化并不一定意味着对不同模型有最强的鲁棒性。通过发布这个基准和一个公开的排行榜挑战,我们希望能开启未来的研究,开发出能够进行迭代和更可控的编辑的模型。

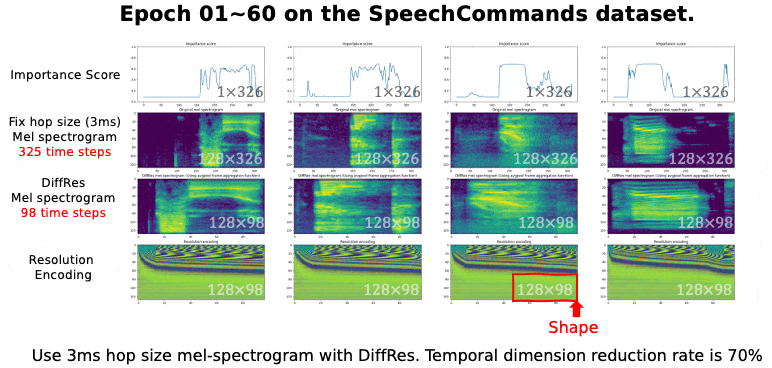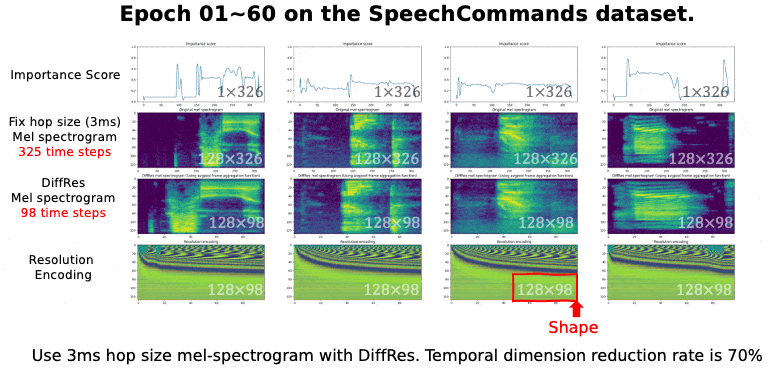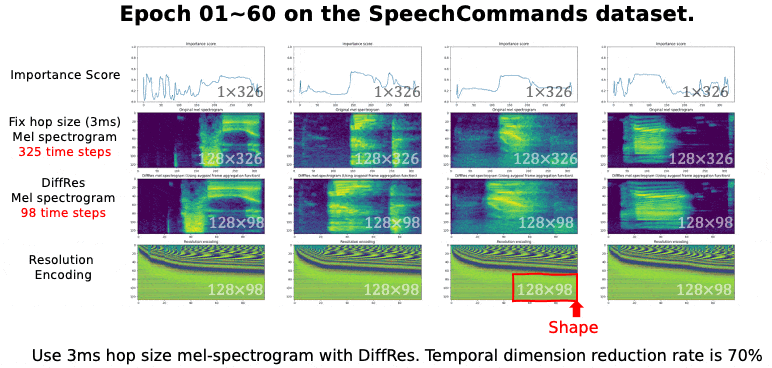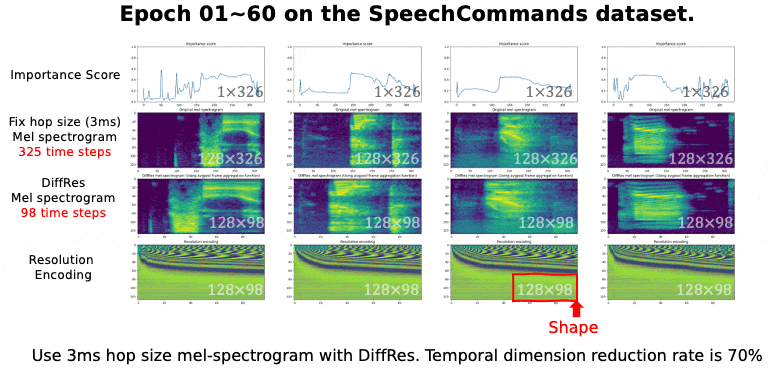
⚡ 论文:Learning the Spectrogram Temporal Resolution for Audio Classification
论文时间:4 Oct 2022
领域任务:Audio Classification, Classification,音频分类,分类
论文地址:https://arxiv.org/abs/2210.01719
代码实现:https://github.com/haoheliu/diffres-python
论文作者:Haohe Liu, Xubo Liu, Qiuqiang Kong, Wenwu Wang, Mark D. Plumbley
论文简介:Starting from a high-temporal-resolution spectrogram such as one-millisecond hop size, we show that DiffRes can improve classification accuracy with the same computational complexity./从高时间分辨率的频谱图开始,如一毫秒的跳动大小,我们表明DiffRes可以在相同的计算复杂度下提高分类精度。
论文摘要:音频频谱图是一种时间-频率表示,已被广泛用于音频分类。频谱图的时间分辨率取决于跳数大小。以前的工作一般认为跳数应该是一个恒定的值,如10毫秒。然而,对于不同类型的声音,固定的跳跃大小或分辨率并不总是最佳的。本文提出了一种新的方法,即DiffRes,它能使可区分的时间分辨率学习,以提高音频分类模型的性能。给定一个用固定跳数计算的频谱图,DiffRes合并非必要的时间帧,同时保留重要的帧。DiffRes作为音频谱图和分类器之间的一个 "插入 "模块,可以进行端到端的优化。我们在Mel-spectrogram上评估了DiffRes,然后是最先进的分类器骨架,并将其应用于五个不同的子任务。与使用固定分辨率的mel-spectrogram相比,基于DiffRes的方法可以在特征层面减少至少25%的时间维度的情况下达到相同或更好的分类精度,这同时也减轻了计算成本。从高时间分辨率的频谱图开始,如一毫秒的跳动大小,我们表明DiffRes可以在相同的计算复杂性下提高分类精度。

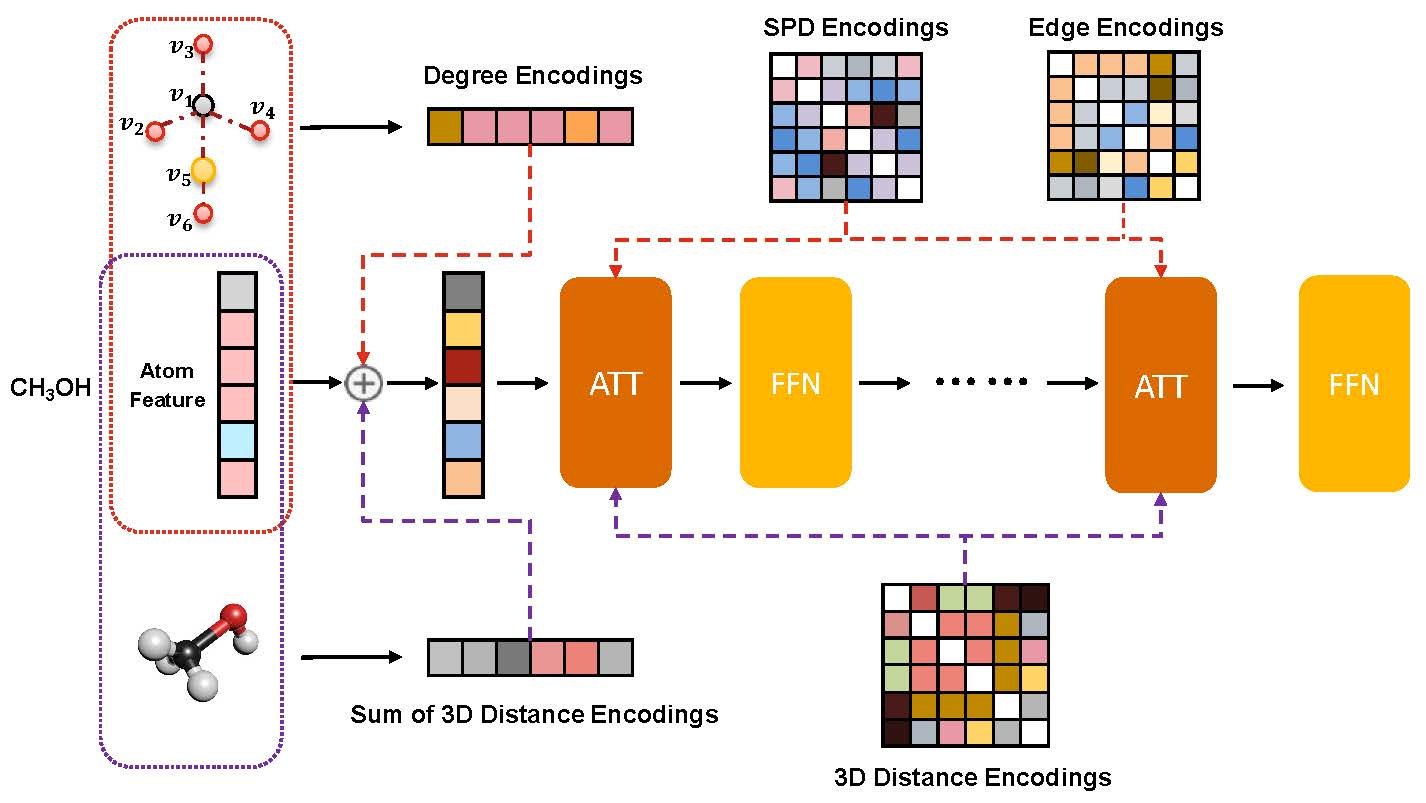
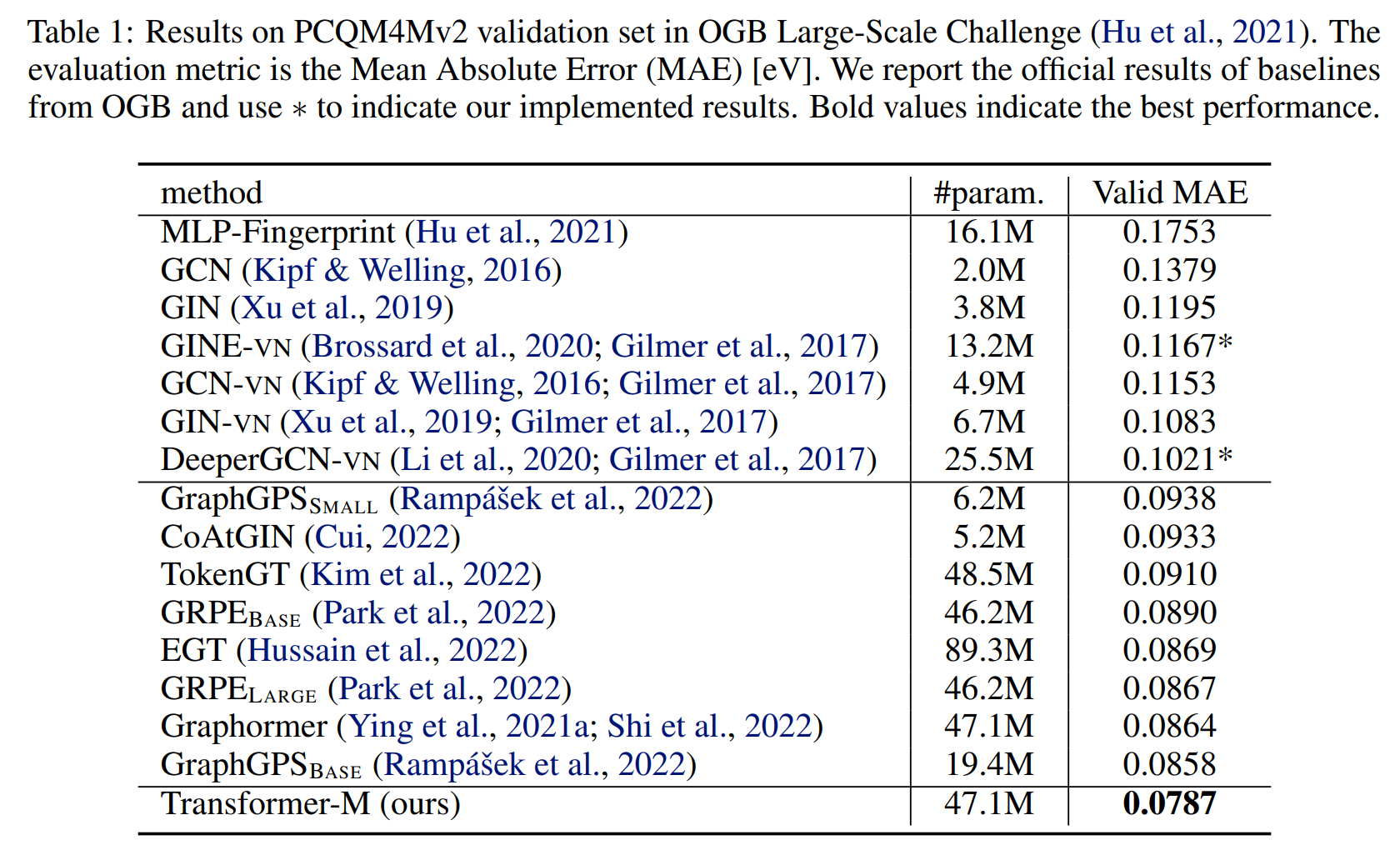
⚡ 论文:One Transformer Can Understand Both 2D & 3D Molecular Data
论文时间:4 Oct 2022
领域任务:Graph Regression, Representation Learning,图回归,表征学习
论文地址:https://arxiv.org/abs/2210.01765
代码实现:https://github.com/lsj2408/Transformer-M
论文作者:Shengjie Luo, Tianlang Chen, Yixian Xu, Shuxin Zheng, Tie-Yan Liu, LiWei Wang, Di He
论文简介:To achieve this goal, in this work, we develop a novel Transformer-based Molecular model called Transformer-M, which can take molecular data of 2D or 3D formats as input and generate meaningful semantic representations./为了实现这一目标,在这项工作中,我们开发了一种新型的基于Transformer的分子模型,称为Transformer-M,它可以将二维或三维格式的分子数据作为输入,并生成有意义的语义表示。
论文摘要:与通常具有独特格式的视觉和语言数据不同,分子可以自然地使用不同的化学配方来描述。人们可以把分子看作是一个二维图形,或者把它定义为位于三维空间中的原子集合。对于分子表征的学习,以前的大多数工作只为特定的数据格式设计了神经网络,使得学到的模型对其他数据格式可能会失败。我们认为一个通用的化学神经网络模型应该能够处理跨数据模式的分子任务。为了实现这一目标,在这项工作中,我们开发了一个新的基于Transformer的分子模型,称为Transformer-M,它可以将二维或三维格式的分子数据作为输入,并产生有意义的语义表示。使用标准的Transformer作为骨干架构,Transformer-M开发了两个分离的通道来编码二维和三维结构信息,并将它们与网络模块中的原子特征结合起来。当输入的数据为特定格式时,相应的通道将被激活,而另一个通道将被禁用。通过对具有适当设计的监督信号的二维和三维分子数据进行训练,Transformer-M自动学会利用来自不同数据模式的知识,并正确捕捉表征。我们对Transformer-M进行了广泛的实验。所有的经验结果表明,Transformer-M可以同时在二维和三维任务上取得强大的性能,这表明它具有广泛的适用性。代码和模型将在https://github.com/lsj2408/Transformer-M 上公开。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。

这篇关于撕开黑幕!AI担任拳击比赛裁判;思维导图工程图表工具大合辑;CVPR视觉-语言的预训练最新进展;游戏开发资源列表;前沿论文 | ShowMeAI资讯日报的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




