本文主要是介绍meta分析的异质性检验指标如何计算?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是异质性?
广义:描述参与者、干预措施和一系列研究间测量结果的差异和多样性,或那些研究中内在真实性的变异。
狭义:统计学异质性,用来描述一系列研究中效应量的变异程度,也用于表明除仅可预见的偶然机会外研究间存在的超逸。
二、异质性分析怎么做?
(1)异质性检验
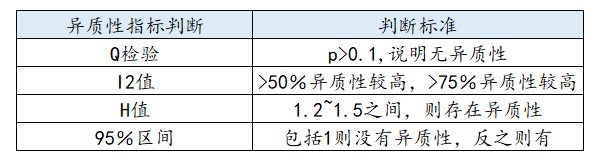
可以使用异质性检验进行异质性分析,结论更加客观,其中包括:Q检验,I2值判断,H值判断等。通常情况下Q检验时p 值>0.1,即说明无异质性(即同质性);I2指标衡量组间异质性的占比情况,通常I2大于50%时认为异质性较高,I2大于75%时认为异质性过高;通常H值大于1.5则说明存在异质性,H值小于1.2说明不存在异质性问题,如果H介于1.2 ~ 1.5之间时,如果95%区间包括1说明没有异质性,反之说明具有异质性。
(2)可视化图形
也可以用图形进行分析,比如森林图、Galbraith 图法、L’Abbe 图等。比如森林图举例如下:

森林图左侧为研究Study名称及异质性检验和合并效应统计检验等信息;森林图中间部分展示效应量及置信区间,方块矩形为权重大小其表示该Study的贡献情况,中间虚线为参照对比线其对应着合并效应值,菱形表示合并效应量结果;森林图右侧展示效应及其置信区间具体数据,并且展示各Study权重信息等;如果有亚组Subgroup,则会展示各亚组效应量及检验信息等。
三、异质性分析指标如何计算?
异质性分析中Q值、I2等如何计算呢?异质性分析在很多方法中都有体现。比如在meta分析中,SPSSAU结果如下(以固定效应为例):

上传的数据如下:
效应量结果如下:


以此类推。
也可以使用excel进行计算,结果如下:
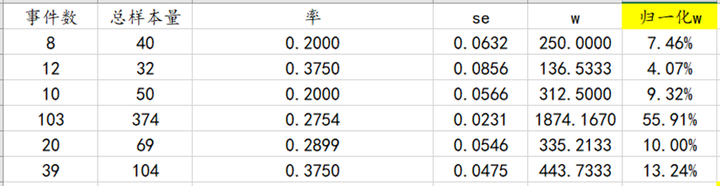
异质性检验的结果如下:



所以Q值计算如下:
250×(0.2-0.2814)^2+136.5333×(0.375-0.2814)^2+……+443.7333×(0.375-0.2814)^2=8.9022;
(2) I2
I2=100%×(Q-df)/Q,其中Q为Q值,df为文献个数-1,计算如下:
100%×(8.9022-5)/8.9022=43.83%
 异质性检验的分析如下:
异质性检验的分析如下:
本次分析进行异质性Q检验时p值=0.113>=0.1,意味着并不存在异质性问题,可考虑使用固定效应模型。
I2表示异质性的比例情况,从上表格可知: I2值为0.438<=50%,意味着研究无异质性问题,可考虑使用固定效应模型。
H2表示总变异与组内变异之比,H2越大即意味着组间变异即异质性情况越大,实质研究中一般使用H值(H2开根号)进行分析。本研究时:H值为1.334,其介于1.2~1.5之间,并且其95%置信区间不包括1,意味着本研究有一定异质性,可考虑使用随机效应模型。
[PS:异质性分析时通常结合多个指标综合决择,如果出现指标间结果矛盾,建议以Q检验或者I2值为准即可。另随机效应时tau2值表示效应量离散程度,其为随机效应时估计值,该值越大表示异质性越强]
四、异质性如何处理?
(1)改变结果变量的指标
Fleiss 指出仅仅改变结果变量的指标,对去除异质性也可能充分。对于一个二分类变量,结果变量的指标由绝对测量标度(如危险差 RD)变为相对测量标度(如比数比 OR),可以降低异质性的程度。对于连续型变量,转化其为对数形式也是其常用的方法,尽管这种方法可能导致在统计学同质性和临床可解释性中做取舍。
(2)选用随机效应合并效应量
在meta分析中统计学方法一般包括固定效应和随机效应,固定效应是所有观察的变异都是由偶然机会引起的一种合并效应量的计算模型,随机效应还考虑吧了研究内抽样误差和研究间变异以估计结果的不确定性模型,当包括的研究有除偶然机会外的异质性时,随机效应模型将给出固定效应模型更宽的可信区间。(PS:如果异质性较小可以选择固定效应模型,如果异质性较大可以选择随机效应模型,但是还需要通过其它的分析)
(3)解释异质性
出现异质性是需要探讨异质性来源,可以通过亚组分析、meta回归、敏感性分析进行查看。
(4)忽略异质性
[1]王丹,翟俊霞,牟振云等.Meta分析中的异质性及其处理方法[J].中国循证医学杂志,2009,9(10):1115-1118.
这篇关于meta分析的异质性检验指标如何计算?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





