本文主要是介绍机器学习之分类算法,mnist手写体识别的python实战(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们来学习机器学习之分类算法,MNIST手写体识别的python实战。
目录
- 一、MNIST数据集
- 二、python代码实战
- 1.查看MNIST数据
- 2.分类算法
- 2.1训练一个二分类器
- 2.2评估分类器
- 使用交叉验证测量精度
- 混淆矩阵
- 2.3精度和召回率
- 精度和召回率权衡
- 2.4ROC曲线
- 2.5随机森林分类器
- 2.6多元分类器
- 错误分析
一、MNIST数据集
首先来介绍一下什么是MNIST。
这是一组由美国高中生和人口调查局员工手写的70000个数字的图片。每张图像都用其代表的数字标记。这个数据集被广为使用,因此也被称作是机器学习领域的“Hello World”:但凡有人想到了一个新的分类算法,都会想看看在MNIST上的执行结果。因此只要是学习机器学习的人,早晚都要面对MNIST。
二、python代码实战
1.查看MNIST数据
首先导入库
# 使用sklearn的函数来获取MNIST数据集
from sklearn.datasets import fetch_openml
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 为了显示中文
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
通过sklearn函数获取MNIST数据
# 耗时巨大
def sort_by_target(mnist):reorder_train=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[:60000])]))[:,1]reorder_test=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[60000:])]))[:,1]mnist.data[:60000]=mnist.data[reorder_train]mnist.target[:60000]=mnist.target[reorder_train]mnist.data[60000:]=mnist.data[reorder_test+60000]mnist.target[60000:]=mnist.target[reorder_test+60000]
mnist=fetch_openml('mnist_784',version=1,cache=True)
mnist.target=mnist.target.astype(np.int8)
sort_by_target(mnist)
然后对数据进行排序
mnist["data"], mnist["target"]
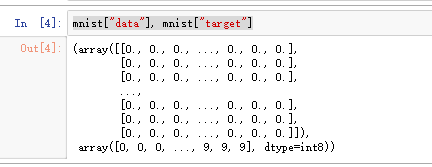
查看MNIST数据集的特征
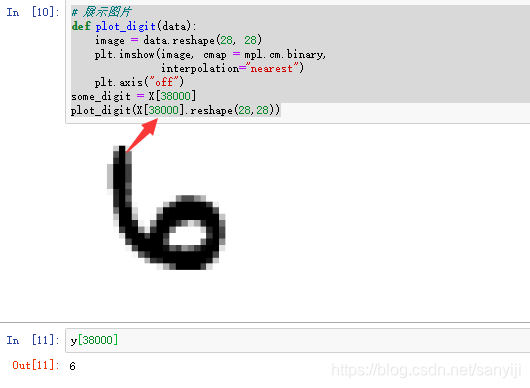
展示单张图片
# 展示图片
def plot_digit(data):image = data.reshape(28, 28)plt.imshow(image, cmap = mpl.cm.binary,interpolation="nearest")plt.axis("off")
some_digit = X[38000]
plot_digit(X[38000].reshape(28,28))
通过修改图片上所指的值修改想要展示的图片位置。
展示10x10的图片集合
代码如下:
# 更好看的图片展示
def plot_digits(instances,images_per_row=10,**options):size=28# 每一行有一个image_pre_row=min(len(instances),images_per_row)images=[instances.reshape(size,size) for instances in instances]
# 有几行n_rows=(len(instances)-1) // image_pre_row+1row_images=[]n_empty=n_rows*image_pre_row-len(instances)images.append(np.zeros((size,size*n_empty)))for row in range(n_rows):# 每一次添加一行rimages=images[row*image_pre_row:(row+1)*image_pre_row]# 对添加的每一行的额图片左右连接row_images.append(np.concatenate(rimages,axis=1))# 对添加的每一列图片 上下连接image=np.concatenate(row_images,axis=0)plt.imshow(image,cmap=mpl.cm.binary,**options)plt.axis("off")
plt.figure(figsize=(9,9))
example_images=np.r_[X[:12000:600],X[13000:30600:600],X[30600:60000:590]]
plot_digits(example_images,images_per_row=10)
plt.show()
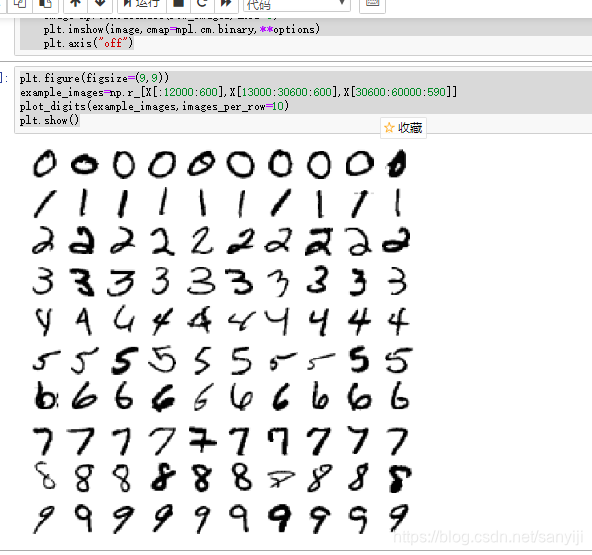
这些代码都不是很重要,能够理解其中的含义最好,不能理解也可以当做一个工具来使用。
前面的一些代码只是让我们进一步了解MNIST,接下来开始使用MNIST数据集进行分类实战。
2.分类算法
首先创建一个测试集,并把其放在一边。
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
同样,我们还需要对训练集进行洗牌,这样可以保证交叉验证的时候,所有的折叠都差不多。此外,有些机器学习算法对训练示例的循序敏感,如果连续输入许多相似的实例,可能导致执行的性能不佳。给数据洗牌,正是为了确保这种情况不会发生。
import numpy as npshuffer_index=np.random.permutation(60000)
X_train,y_train=X_train[shuffer_index],y_train[shuffer_index]
2.1训练一个二分类器
现在,我们先简化问题,只尝试识别一个数字,比如数字5,那么这个"数字5检测器",就是一个二分类器的例子,它只能区分两个类别:5和非5。先为此分类任务创建目录标量。
y_train_5=(y_train==5)
y_test_5=(y_test==5)
这篇关于机器学习之分类算法,mnist手写体识别的python实战(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





