本文主要是介绍【点云处理之论文狂读经典版14】—— Dynamic Graph CNN for Learning on Point Clouds,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DGCNN:Dynamic Graph CNN for Learning on Point Clouds
- 摘要
- 方法
- Edge Convolution
- Dynamic Graph Update
- Properties
- 实验
- Classification
- Part Segmentation
- Indoor Scene Segmentation
- 展望
- 生词
摘要
- 背景: 对于计算机图形学中的许多应用而言,point clouds是一种灵活的几何表示,通常是大多数3D采集设备的原始输出
- 问题: 尽管point clouds的hand-designed特征在很久以前就被提出来了,但是最近在image上很火的convolutional neural networks(CNNs)表明了将CNN应用到point clouds上的价值。Point clouds自身缺乏拓扑信息,所以需要设计一个可以恢复拓扑信息的模型,从而达到丰富point clouds表示能力的目的
- 方法: 在CNN中嵌入了一个叫EdgeConv的模块
- EdgeConv模块作用在graphs上,动态地对网络中每一层的graphs进行计算
- EdgeConv模块可导,并且可以被嵌入任意现有的网络中
- EdgeConv模块考虑了局部邻域信息和全局形状信息
- EdgeConv 具有排序不变性
- 特征空间中的multi-layer systems affinity采集了原始嵌入中潜在的长距离语义特征。
- 代码:
- TensorFlow版本
- PyTorch版本
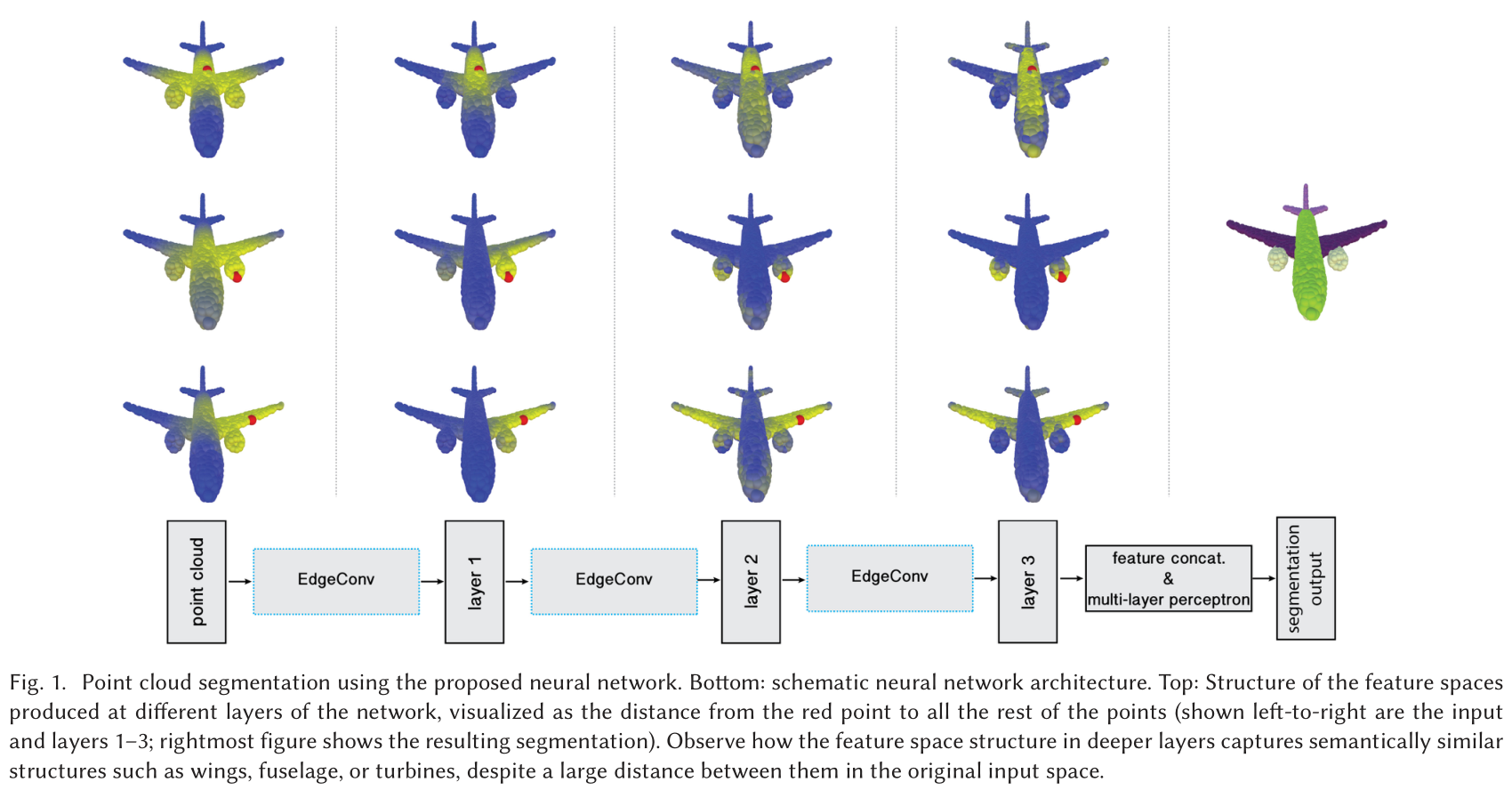
方法
- 为了挖掘局部几何结构,构造了一个局部邻域graph,并且在边上应用卷积操作,边连接着相邻的点对。
- 本文中的graph不固定,在网络的每一层都动态更新,也就是说,一个点的 k N N kNN kNN集合中的元素在网络的层与层之间是变化的,是通过embeddings序列计算得到的。
- 特征空间中的邻近性和输入不同,这样会导致信息在整个点云中的非局部扩散。
Edge Convolution
记 X = { x 1 , … , x n } ⊆ R F \mathbf{X}=\left\{\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right\} \subseteq \mathbb{R}^{F} X={x1,…,xn}⊆RF为输入点云,其中 n n n是点的数量, F F F是点的维度,在最简单的情况下, F = 3 F=3 F=3,每个点都包括了3D坐标 x i = ( x i , y i , z i ) \mathbf{x}_{i}=\left(x_{i}, y_{i}, z_{i}\right) xi=(xi,yi,zi),在其他情况下,还会包括颜色、法向量等,在网络的其他层, F F F表示点的特征维度。
我们计算一个有向图 G = ( V , E ) \mathcal{G}=(\mathcal{V}, \mathcal{E}) G=(V,E) ,表示局部点云结构,其中 V = { 1 , … , n } \mathcal{V}=\{1, \ldots, n\} V={1,…,n}, E ⊆ V × V \mathcal{E} \subseteq \mathcal{V} \times \mathcal{V} E⊆V×V分别是顶点和边。在最简单的情况下,构造一个 X \mathrm{X} X的KNN graph G \mathcal{G} G。该graph包括self-loop,每个节点都会指向自己。定义边特征为 e i j = h Θ ( x i , x j ) \boldsymbol{e}_{i j}=h_{\Theta}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) eij=hΘ(xi,xj),其中 h Θ : R F × h_{\Theta}: \mathbb{R}^{F} \times hΘ:RF× R F → R F ′ \mathbb{R}^{F} \rightarrow \mathbb{R}^{F^{\prime}} RF→RF′是非线性函数,可学习参数为 Θ \boldsymbol{\Theta} Θ。
最后,通过使用以channel为单位的对称聚合操作 □ \square □ (e.g., ∑ \sum ∑ or max) 定义EdgeConv操作,在与从每个顶点发出的所有边缘相关联的边缘特征上进行聚合操作。在第 i i i个顶点的EdgeConv输出表示为:
x i ′ = □ j : ( i , j ) ∈ E h Θ ( x i , x j ) \mathbf{x}_{i}^{\prime}=\mathop {\square}\limits_{{j:(i, j) \in \mathcal{E}}} h_{\Theta}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) xi′=j:(i,j)∈E□hΘ(xi,xj)
其中 x i \mathbf{x}_{i} xi是central point, { x j : ( i , j ) ∈ E } \left\{\mathbf{x}_{j}:(i, j) \in \mathcal{E}\right\} {xj:(i,j)∈E}是 x i \mathbf{x}_{i} xi的neigboured points。总而言之,给定带有 n n n个点的 F F F维点云,EdgeConv会产生一个相同数量点的 F ′ F^{\prime} F′维点云。
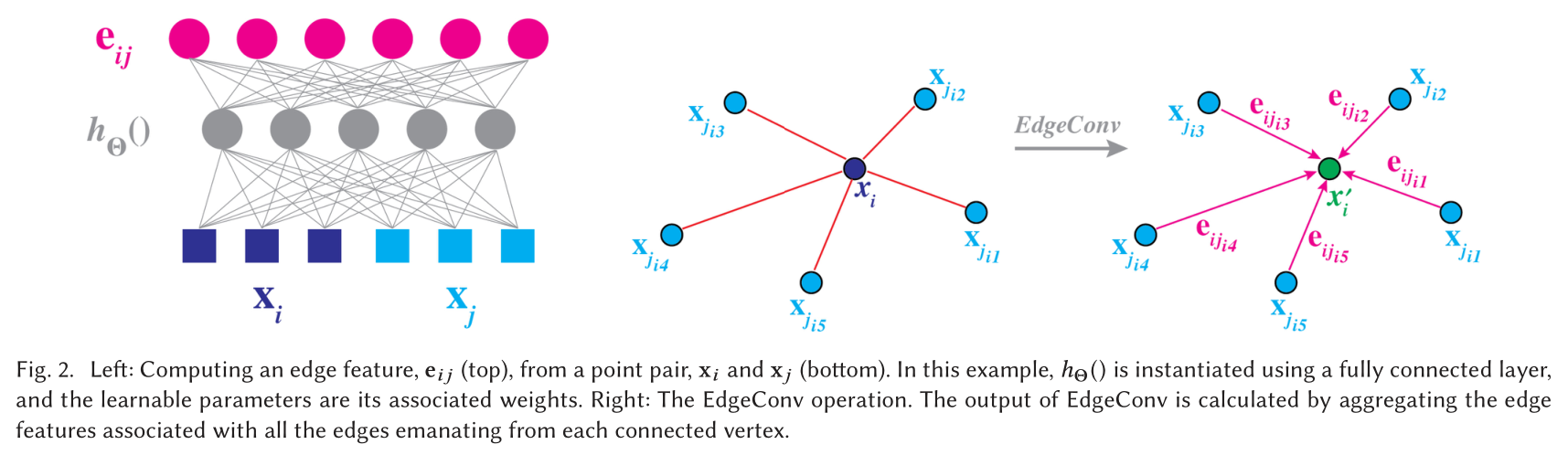
Choice of h h h and □ \square □
h h h的选择:
- 卷积式:
x i m ′ = ∑ j : ( i , j ) ∈ E θ m ⋅ x j . x_{i m}^{\prime}=\sum_{j:(i, j) \in \mathcal{E}} \boldsymbol{\theta}_{m} \cdot \mathbf{x}_{j} . xim′=j:(i,j)∈E∑θm⋅xj.
其中 Θ = ( θ 1 , … , θ M ) \Theta=\left(\theta_{1}, \ldots, \theta_{M}\right) Θ=(θ1,…,θM)对 M M M个不同的filters权值进行编码。每个 θ m \theta_{m} θm都有着与 x \mathbf{x} x相同的维度, ⋅ \cdot ⋅表示内积。 - PointNet式:
h Θ ( x i , x j ) = h Θ ( x i ) , h_{\Theta}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=h_{\Theta}\left(\mathbf{x}_{i}\right), hΘ(xi,xj)=hΘ(xi),
只对全局形状信息编码,而不考虑局部邻域结构,算是EdgeConv的一种特殊情况。 - Atzmon提出的PCNN式:
x i m ′ = ∑ j ∈ V ( h θ ( x j ) ) g ( u ( x i , x j ) ) , x_{i m}^{\prime}=\sum_{j \in \mathcal{V}}\left(h_{\boldsymbol{\theta}\left(\mathbf{x}_{j}\right)}\right) g\left(u\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)\right), xim′=j∈V∑(hθ(xj))g(u(xi,xj)),
其中 g g g是高斯kernel, u u u被用于计算欧式空间中的距离。 - PointNet++式:
h Θ ( x i , x j ) = h Θ ( x j − x i ) . h_{\boldsymbol{\Theta}}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=h_{\boldsymbol{\Theta}}\left(\mathbf{x}_{j}-\mathbf{x}_{i}\right) . hΘ(xi,xj)=hΘ(xj−xi).
仅对局部信息进行编码,将整个形状划分为很多块,丢失了全局结构信息。 - 本文使用的对称边函数:
h Θ ( x i , x j ) = h ˉ Θ ( x i , x j − x i ) . h_{\boldsymbol{\Theta}}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\bar{h}_{\boldsymbol{\Theta}}\left(\mathbf{x}_{i}, \mathbf{x}_{j}-\mathbf{x}_{i}\right) . hΘ(xi,xj)=hˉΘ(xi,xj−xi).
既结合了全局型状结构(通过以 x i \mathbf{x}_{i} xi为中心的坐标决定),又考虑到了局部邻域信息(通过 x j − x i \mathbf{x}_{j}-\mathbf{x}_{i} xj−xi获取)。
特别地,还可以通过下式表示EdgeConv的操作:
e i j m ′ = ReLU ( θ m ⋅ ( x j − x i ) + ϕ m ⋅ x i ) , e_{i j m}^{\prime}=\operatorname{ReLU}\left(\boldsymbol{\theta}_{m} \cdot\left(\mathbf{x}_{j}-\mathbf{x}_{i}\right)+\boldsymbol{\phi}_{m} \cdot \mathbf{x}_{i}\right), eijm′=ReLU(θm⋅(xj−xi)+ϕm⋅xi),
然后再执行:
x i m ′ = max j : ( i , j ) ∈ E e i j m ′ , x_{i m}^{\prime}=\max _{j:(i, j) \in \mathcal{E}} e_{i j m}^{\prime}, xim′=j:(i,j)∈Emaxeijm′,
其中 Θ = ( θ 1 , … , θ M , ϕ 1 , … , ϕ M ) \Theta=\left(\theta_{1}, \ldots, \theta_{M}, \phi_{1}, \ldots, \phi_{M}\right) Θ=(θ1,…,θM,ϕ1,…,ϕM)。
□ \square □选择为max
Dynamic Graph Update
我们的实验表明,利用每一层所产生的特征空间中的最近邻来重新计算graph是有用的。这是我们的方法与在固定输入graph上工作的graph CNN一个关键区别。这样的动态graph更新是我们的架构的名称DGCNN的原因。
在每一层,都有不同的graph G ( l ) = ( V ( l ) , E ( l ) ) \mathcal{G}^{(l)}=\left(\mathcal{V}^{(l)}, \mathcal{E}^{(l)}\right) G(l)=(V(l),E(l)),其中第 l l l 层的边的形式为 ( i , j i 1 ) , … , ( i , j i k l ) \left(i, j_{i 1}\right), \ldots,\left(i, j_{i k_{l}}\right) (i,ji1),…,(i,jikl),也就是 x j i 1 ( l ) , … , x j i k l ( l ) \mathbf{x}_{j_{i 1}}^{(l)}, \ldots, x_{j_{i k_{l}}}^{(l)} xji1(l),…,xjikl(l)是距离 x i ( l ) \mathbf{x}_{i}^{(l)} xi(l)最近的 k l k_{l} kl个点。我们的网络学习如何构造每层中的graph G \mathcal{G} G,而不是在网络开始预测前就已经固定好了。在实现时,在距离空间中计算距离矩阵,然后对每个单点取最近的 k k k个点。
Properties
Permutation Invariance
考虑到每一层的输出为:
x i ′ = max j : ( i , j ) ∈ E h Θ ( x i , x j ) , \mathbf{x}_{i}^{\prime}=\max _{j:(i, j) \in \mathcal{E}} h_{\boldsymbol{\Theta}}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right), xi′=j:(i,j)∈EmaxhΘ(xi,xj),
由于max是一个对称函数,所以输出层 x i ′ \mathrm{x}_{i}^{\prime} xi′相对于输入 x j \mathbf{x}_{j} xj是排序不变的。全局最大池化操作对于聚合点特征也是排序不变的。
Translation Invariance
我们的操作有着一部分的translation invariance性质,因为边函数公式不受平移的影响,也可以选择性的受translation影响。考虑在点 x j \mathbf{x}_{j} xj和点 x i \mathbf{x}_{i} xi上进行平移,当平移 T T T时,有:
e i j m ′ = θ m ⋅ ( x j + T − ( x i + T ) ) + ϕ m ⋅ ( x i + T ) = θ m ⋅ ( x j − x i ) + ϕ m ⋅ ( x i + T ) \begin{aligned} e_{i j m}^{\prime} &=\boldsymbol{\theta}_{m} \cdot\left(\mathbf{x}_{j}+T-\left(\mathbf{x}_{i}+T\right)\right)+\boldsymbol{\phi}_{m} \cdot\left(\mathbf{x}_{i}+T\right) \\ &=\boldsymbol{\theta}_{m} \cdot\left(\mathbf{x}_{j}-\mathbf{x}_{i}\right)+\boldsymbol{\phi}_{m} \cdot\left(\mathbf{x}_{i}+T\right) \end{aligned} eijm′=θm⋅(xj+T−(xi+T))+ϕm⋅(xi+T)=θm⋅(xj−xi)+ϕm⋅(xi+T)
如果令 ϕ m = 0 \boldsymbol{\phi}_{m}=\mathbf{0} ϕm=0时,只考虑 x j − x i \mathbf{x}_{j}-\mathbf{x}_{i} xj−xi,那么该操作是完全平移不变的。但是模型会损失局部信息的获取,所以说还是部分translation invariance。

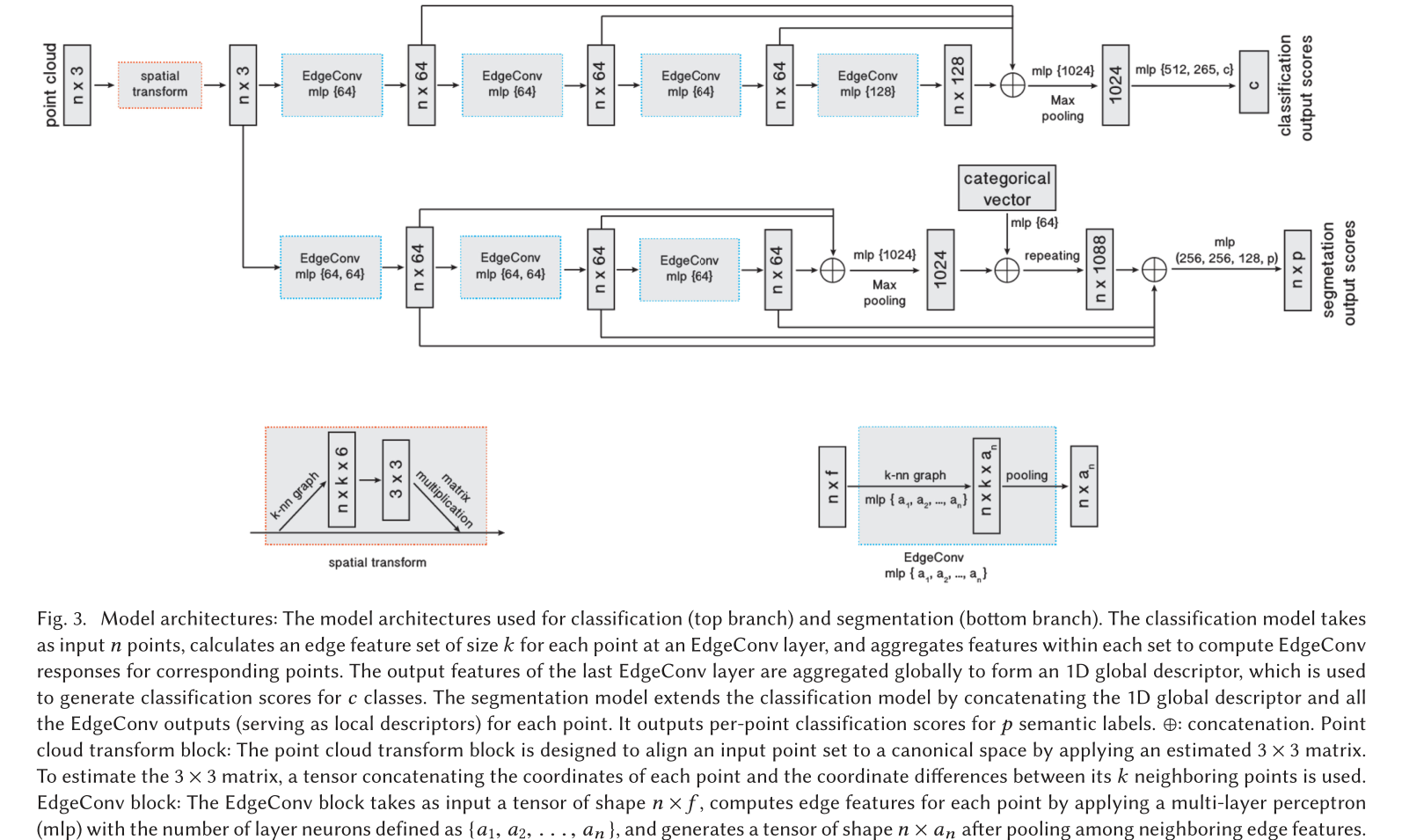
实验
Classification
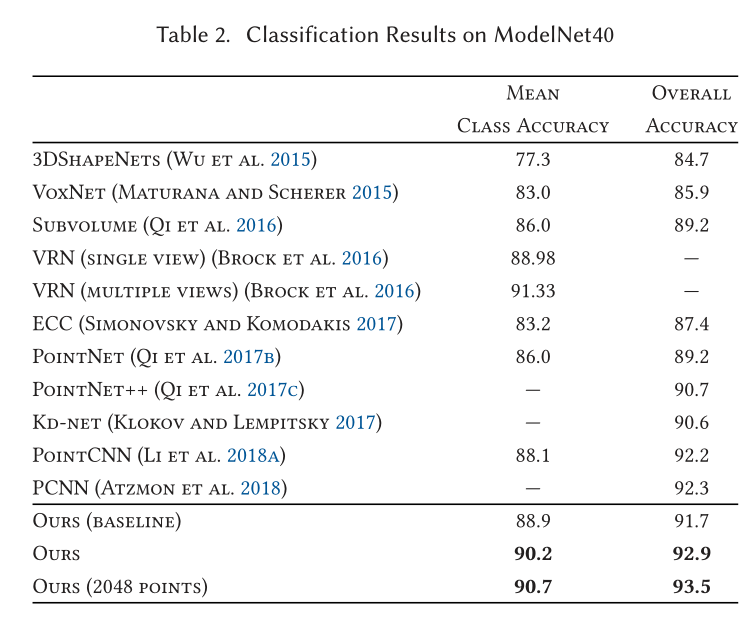
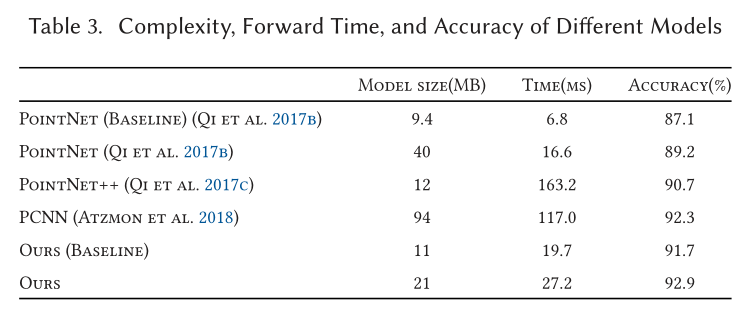
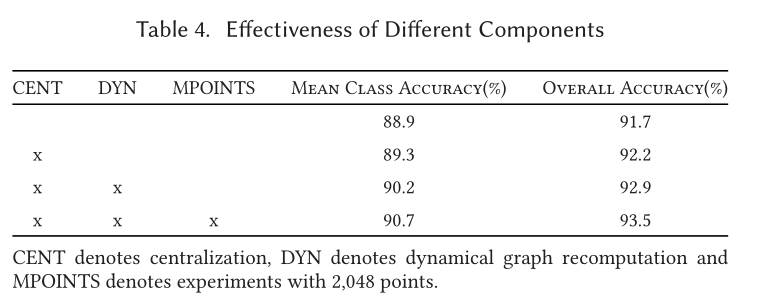
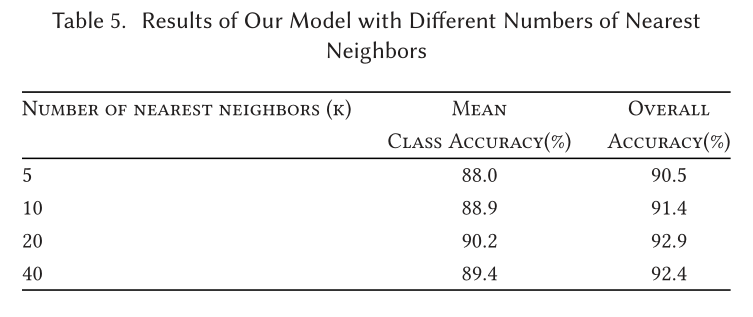
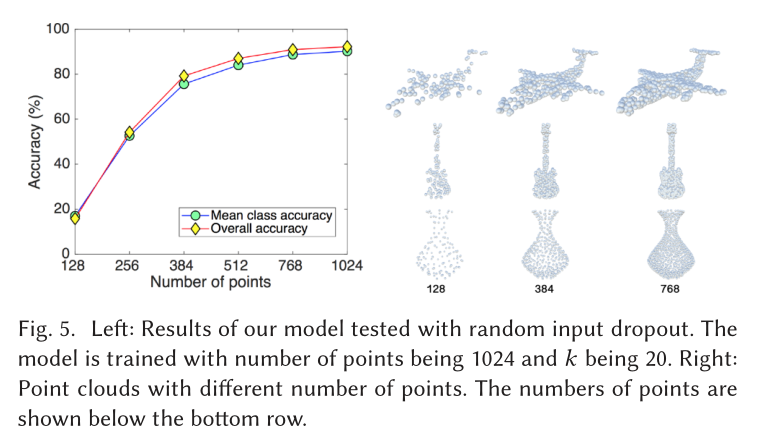
Part Segmentation

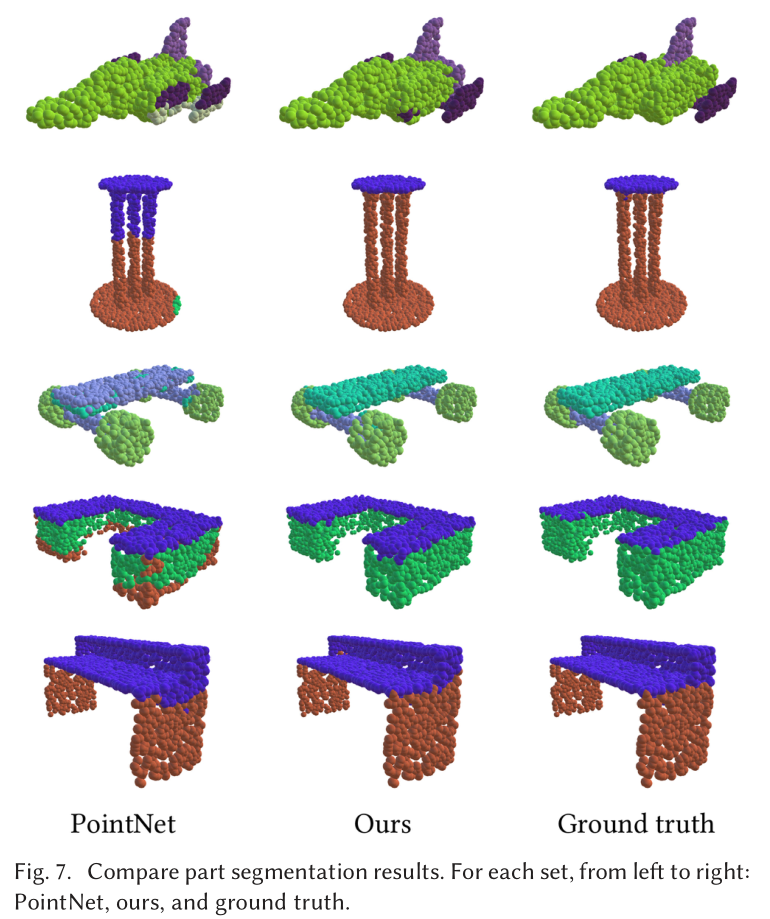
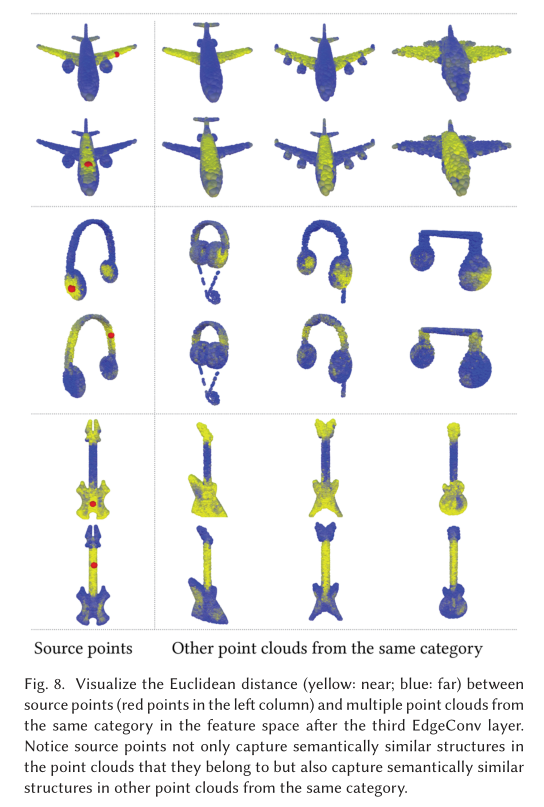

Indoor Scene Segmentation
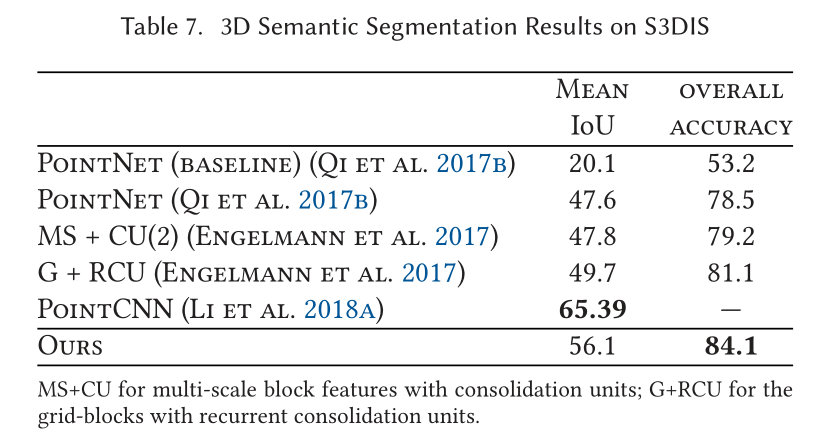
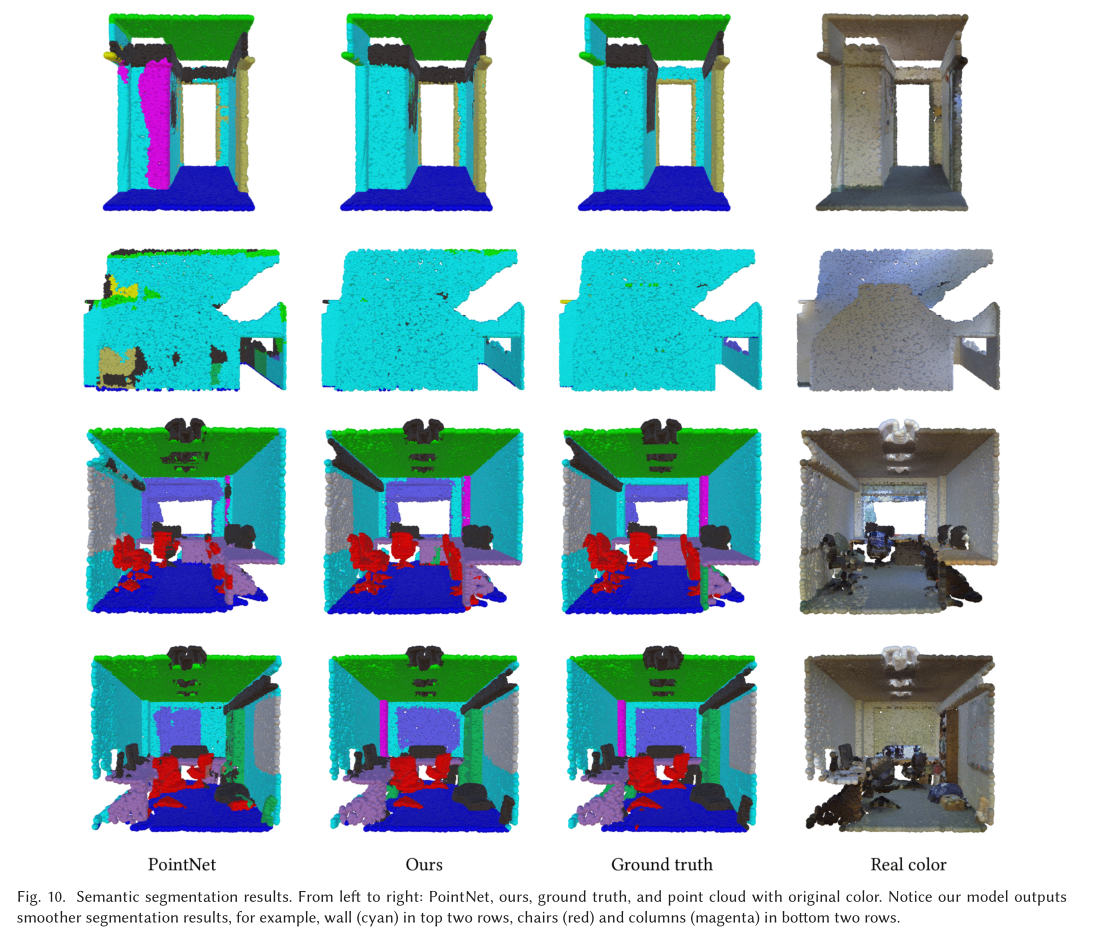
展望
- 通过结合更快的数据格式提高模型的速度,改用多元组,不去寻找点对之间的关系
- 设计一个非共享的transformer网络,在每个local patch上都不同,更具灵活性
生词
- dub v 被称为…
- arguably adv 可以说是
- emanate v 发出
这篇关于【点云处理之论文狂读经典版14】—— Dynamic Graph CNN for Learning on Point Clouds的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





