本文主要是介绍Python数据挖掘项目实战——自动售货机销售数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

01 案例背景
近年来,随着我国经济技术的不断提升,自动化机械在人们日常生活中扮演着越来越重要的角色,更多的被应用在不同的领域。而作为新的一种自动化零售业态,自动售货机在日常生活中应用越来越广泛。自动售货机销售产业在走向信息化、合理化同时,也面临着高度同质化、成本上升、毛利下降等诸多困难与问题,这也是大多数企业所会面临到的问题。
为了提高市场占有率和企业的竞争力,某企业在广东省某8个市部署了376台自动售货机,但经过一段时间后,发现其经营状况并不理想。而如何了解销售额、订单数量与自动售货机数量之间的关系,畅销或滞销的商品又有哪些,自动售货机的销售情况等,已成为该企业亟待解决的问题。
02 分析目标
获取了该企业某6个月的自动售货机销售数据,结合销售背景进行分析,并可视化展现销售现状,同时预测未来一段时间内的销售额,从而为企业制定营销策略提供一定的参考依据。
03 分析过程
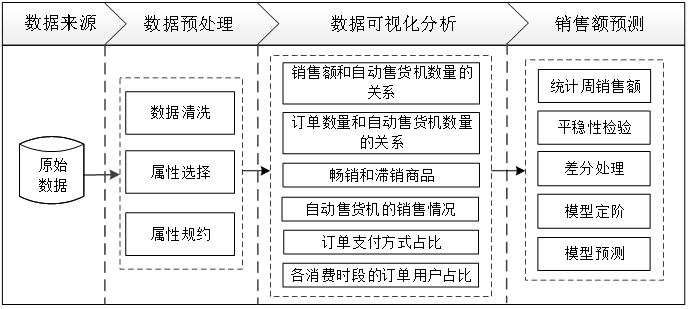
04 数据预处理
1. 清洗数据
1.1 合并订单表并处理缺失值
由于订单表的数据是按月份分开存放的,为了方便后续对数据进行处理和可视化,所以需要对订单数据进行合并处理。同时,在合并订单表的数据后,为了了解订单表的缺失数据的基本情况,需要进行缺失值检测。合并订单表并进行缺失值检测,操作结果如图1所示。
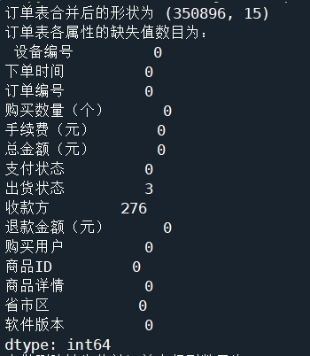
由操作结果可知,合并后的订单数据有350867条记录,且订单表中含有缺失值的记录总共有279条,其数量相对较少,可直接使用删除法对其中的缺失值进行处理。
合并订单表、查看缺失值并处理缺失值,如代码清单1所示。
代码清单1 合并订单表、查看缺失值并处理缺失值
import pandas as pd# 读取数据data4 = pd.read_csv('../data/订单表2018-4.csv', encoding='gbk')data5 = pd.read_csv('../data/订单表2018-5.csv', encoding='gbk')data6 = pd.read_csv('../data/订单表2018-6.csv', encoding='gbk')data7 = pd.read_csv('../data/订单表2018-7.csv', encoding='gbk')data8 = pd.read_csv('../data/订单表2018-8.csv', encoding='gbk')data9 = pd.read_csv('../data/订单表2018-9.csv', encoding='gbk')# 合并数据data = pd.concat([data4, data5, data6, data7, data8, data9], ignore_index=True)print('订单表合并后的形状为', data.shape)# 缺失值检测print('订单表各属性的缺失值数目为:\n', data.isnull().sum())data = data.dropna(how='any') # 删除缺失值
1.2 增加“市”属性
为了满足后续的数据可视化需求,需要在订单表中增加“市”属性
增加“市”属性如代码清单2所示。
代码清单2 增加“市”属性
# 从省市区属性中提取市的信息,并创建新属性data['市'] = data['省市区'].str[3: 6]print('经过处理后的数据前5行为:\n', data.head())
1.3 处理订单表中的“商品详情”属性
通过浏览订单表数据发现,在“商品详情”属性中存在有异名同义的情况,即两个名称不同的值所代表的实际意义是一致的,如“脉动青柠X1;”“脉动青柠x1;”等。因为此情况会对后面的分析结果造成一定的影响,所以需要对订单表中的“商品详情”属性进行处理,增加“商品名称”属性,如代码清单3所示。
代码清单3 处理订单表中的“商品详情”属性
# 定义一个需剔除字符的列表error_strerror_str = [' ', '(', ')', '(', ')', '0', '1', '2', '3', '4', '5', '6','7', '8', '9', 'g', 'l', 'm', 'M', 'L', '听', '特', '饮', '罐','瓶', '只', '装', '欧', '式', '&', '%', 'X', 'x', ';']# 使用循环剔除指定字符for i in error_str:data['商品详情'] = data['商品详情'].str.replace(i, '')# 新建“商品名称”属性,用于新数据的存放data['商品名称'] = data['商品详情']
1.4 处理“总金额(元)”属性
此外,当浏览订单表数据时,发现在“总金额(元)”属性中,存在极少订单的金额很小,如0、0.01等。在现实生活中,这种记录存在的情况极少,且这部分数据不具有分析意义。因此,在本案例中,对订单的金额小于0.5的记录进行删除处理
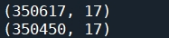
由操作结果可知,删除前的数据行列数目为(350617, 17),删除后的数据行列数目为(350450, 17)。
删除“总金额(元)”属性中订单的金额较少的记录如代码清单4所示。
代码清单4 删除“总金额(元)”属性中订单的金额较少的记录
# 删除金额较少的订单前的数据行列数目print(data.shape)# 删除金额较少的订单后的数据行列数目data = data[data['总金额(元)'] >= 0.5]print(data.shape)
属性选择
因为订单表中的“手续费(元)”“收款方”“软件版本”“省市区”“商品详情”“退款金额(元)”等属性对本案例的分析没有意义,所以需要对其进行删除处理,选择合适的属性,操作的结果如图4所示。

属性选择如代码清单5所示。
代码清单5 属性选择
# 对于订单表数据选择合适的属性data = data.drop(['手续费(元)', '收款方', '软件版本', '省市区', '商品详情', '退款金额(元)'], axis=1)print('选择后,数据属性为:\n', data.columns.values)
3.属性规约
在订单表“下单时间”属性中含有的信息量较多,并且存在概念分层的情况,需要对属性进行数据规约,提取需要的信息。提取相应的“小时”属性和“月份”属性,进一步泛化“小时”属性为“下单时间段”属性,规则如下:
Ø当小时≤5时,为“凌晨”;
Ø当5<小时≤8时,为“早晨”;
Ø当8<小时≤11时,为“上午”;
Ø当11<小时≤13时,为“中午”;
Ø当13<小时≤16时,为“下午”;
Ø当16<小时≤19时,为“傍晚”;
Ø当19<小时≤24,为“晚上”。
在Python中规约订单表的属性,如代码清单6所示。
代码清单6 规约订单表的属性
# 将时间格式的字符串转换为标准的时间格式data['下单时间'] = pd.to_datetime(data['下单时间'])data['小时'] = data['下单时间'].dt.hour # 提取时间中的小时data['月份'] = data['下单时间'].dt.month # 提取时间中的月份data['下单时间段'] = 'time' # 新增“下单时间段”属性,并将其初始化为timeexp1 = data['小时'] <= 5 # 判断小时是否小于等于5# 若条件为真,则时间段为凌晨data.loc[exp1, '下单时间段'] = '凌晨'# 判断小时是否大于5且小于等于8exp2 = (5 < data['小时']) & (data['小时'] <= 8)# 若条件为真,则时间段为早晨data.loc[exp2, '下单时间段'] = '早晨'# 判断小时是否大于8且小于等于11exp3 = (8 < data['小时']) & (data['小时'] <= 11)# 若条件为真,则时间段为上午data.loc[exp3, '下单时间段'] = '上午'# 判断小时是否小大于11且小于等于13exp4 = (11 < data['小时']) & (data['小时'] <= 13)# 若条件为真,则时间段为中午data.loc[exp4, '下单时间段'] = '中午'# 判断小时是否大于13且小于等于16exp5 = (13 < data['小时']) & (data['小时'] <= 16)# 若条件为真,则时间段为下午data.loc[exp5, '下单时间段'] = '下午'# 判断小时是否大于16且小于等于19exp6 = (16 < data['小时']) & (data['小时'] <= 19)# 若条件为真,则时间段为傍晚data.loc[exp6, '下单时间段'] = '傍晚'# 判断小时是否大于19且小于等于24exp7 = (19 < data['小时']) & (data['小时'] <= 24)# 若条件为真,则时间段为晚上data.loc[exp7, '下单时间段'] = '晚上'data.to_csv('../tmp/order.csv', index=False, encoding = 'gbk')
05 销售数据可视化分析
在销售数据中含有的数据量较多,作为企业管理人员以及决策制定者,无法直观了解目前自动售货机的销售状况。因此需要利用处理好的数据进行可视化分析,直观地展示销售走势以及各区销售情况等,为决策者提供参考。
1.销售额和自动售货机数量的关系
探索6个月销售额和自动售货机数量之间的关系,并按时间走势进行可视化分析,结果如图5所示。
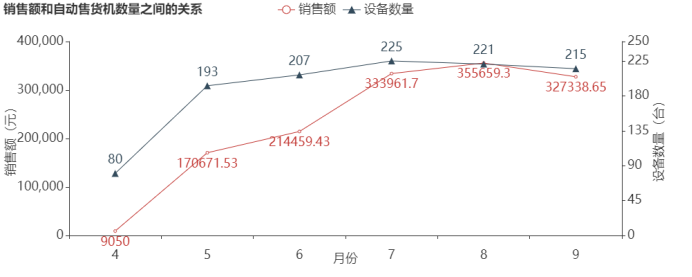
4月至7月,自动售货机的数量在增加,销售额也随着自动售货机的数量增加而增加;8月,虽然自动售货机数量减少了4台,但是销售额还在增加;9月相比8月的自动售货机数量减少了6台,销售额也随着减少。可以推断出销售额与自动售货机的数量存在一定的相关性,增加自动售货机的数量将会带来销售额的增长。出现该情况可能是因为广东处于亚热带,气候相对炎热,而7、8、9月的气温也相对较高,人们使用自动售货机的频率也相对较高。
探索销售额和自动售货机数量之间的关系如代码清单7所示。
代码清单7 销售额和自动售货机数量之间的关系
import pandas as pdimport numpy as npfrom pyecharts.charts import Linefrom pyecharts import options as optsimport matplotlib.pyplot as pltfrom pyecharts.charts import Barfrom pyecharts.charts import Piefrom pyecharts.charts import Griddata = pd.read_csv('../tmp/order.csv', encoding='gbk')def f(x):return len(list(set((x.values))))# 绘制销售额和自动售货机数量之间的关系图groupby1 = data.groupby(by='月份', as_index=False).agg({'设备编号': f, '总金额(元)': np.sum})groupby1.columns = ['月份', '设备数量', '销售额']line = (Line().add_xaxis([str(i) for i in groupby1['月份'].values.tolist()]).add_yaxis('销售额', np.round(groupby1['销售额'].values.tolist(), 2)).add_yaxis('设备数量', groupby1['设备数量'].values.tolist(), yaxis_index=1,symbol='triangle').set_series_opts(label_opts=opts.LabelOpts(is_show=True, position='top', font_size=10)).set_global_opts(xaxis_opts=opts.AxisOpts(name='月份', name_location='center', name_gap=25),title_opts=opts.TitleOpts(title='销售额和自动售货机数量之间的关系'),yaxis_opts=opts.AxisOpts( name='销售额(元)', name_location='center', name_gap=60,axislabel_opts=opts.LabelOpts(formatter='{value}'))).extend_axis(yaxis=opts.AxisOpts( name='设备数量(台)', name_location='center', name_gap=40,axislabel_opts=opts.LabelOpts(formatter='{value}'), interval=50)))line.render_notebook()
2.订单数量和自动售货机数量的关系
探索6个月订单数量和自动售货机数量之间的关系,并按时间走势进行可视化分析,结果如图6所示。
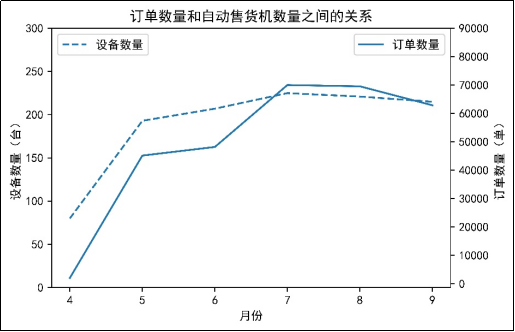
由图6可知,4月至7月,自动售货机数量呈上升趋势,订单数量也随着自动售货机数量增加而增加,而8月至9月,自动售货机数量在减少,订单数量也在减少。这说明了订单数量与自动售货机的数量是严格相关的,增加自动售货机会给用户带来便利,从而提高订单数量。同时,结合图5可知,订单数量和销售额的变化趋势基本保持一样的变化趋势,这也说明了订单数量和销售额存在一定的相关性。
由于各市的设备数量并不一致,所以探索各市自动售货机的平均销售总额,并进行对比分析,结果如图7所示。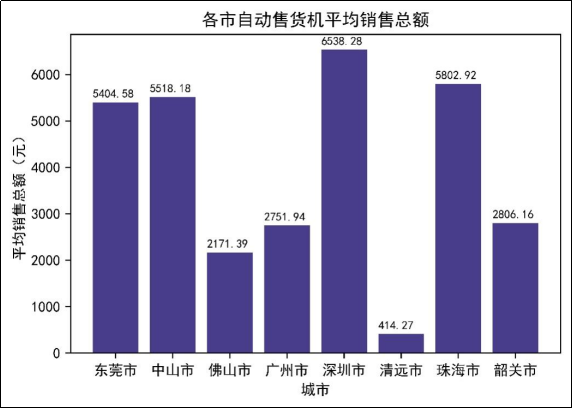
由图7可知,深圳市自动售货机平均销售总额最高,达到了6538.28元,排在其后的是珠海市和中山市。而最少的是清远市,其平均销售总额只有414.27元。出现此情况可能是因为不同区域的人流量不同,而深圳市相对于其他区域的人流量相对较大,清远市相对于其他区域的人流量相对较小。此外,广州市的人流量也相对较大,但其平均销售总额却相对较少,可能是因为自动售货机放置不合理导致的。
探索订单数量和自动售货机数量之间的关系,以及各市自动售货机的平均销售总额如代码清单8所示。
代码清单8 订单数量和自动售货机数量之间的关系
groupby2 = data.groupby(by='月份', as_index=False).agg({'设备编号': f, '订单编号': f})groupby2.columns = ['月份', '设备数量', '订单数量']# 绘制图形plt.figure(figsize=(10, 4))plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falsefig, ax1 = plt.subplots() # 使用subplots函数创建窗口ax1.plot(groupby2['月份'], groupby2['设备数量'], '--')ax1.set_yticks(range(0, 350, 50)) # 设置y1轴的刻度范围ax1.legend(('设备数量',), loc='upper left', fontsize=10)ax2 = ax1.twinx() # 创建第二个坐标轴ax2.plot(groupby2['月份'], groupby2['订单数量'])ax2.set_yticks(range(0, 100000, 10000)) # 设置y2轴的刻度范围ax2.legend(('订单数量',), loc='upper right', fontsize=10)ax1.set_xlabel('月份')ax1.set_ylabel('设备数量(台)')ax2.set_ylabel('订单数量(单)')plt.title('订单数量和自动售货机数量之间的关系')plt.show()gruop3 = data.groupby(by='市', as_index=False).agg({'总金额(元)':sum, '设备编号':f})gruop3['销售总额'] = np.round(gruop3['总金额(元)'], 2)gruop3['平均销售总额'] = np.round(gruop3['销售总额'] / gruop3['设备编号'], 2)plt.bar(gruop3['市'].values.tolist(), gruop3['平均销售总额'].values.tolist(), color='#483D8B')# 添加数据标注for x, y in enumerate(gruop3['平均销售总额'].values):plt.text(x - 0.4, y + 100, '%s' %y, fontsize=8)plt.xlabel('城市')plt.ylabel('平均销售总额(元)')plt.title('各市自动售货机平均销售总额')plt.show()
3.畅销和滞销商品
查找6个月销售额排名前10和后10的商品,从而找出畅销商品和滞销商品,并对其销售额进行可视化分析,结果如图8、图9所示。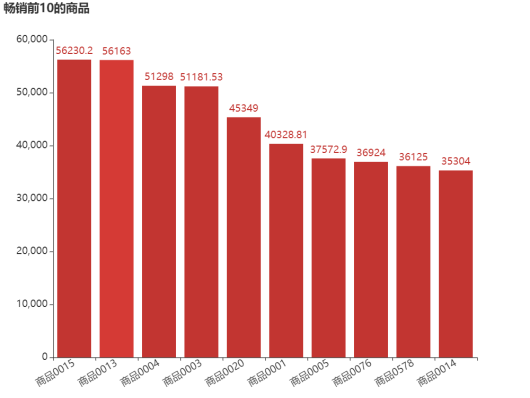
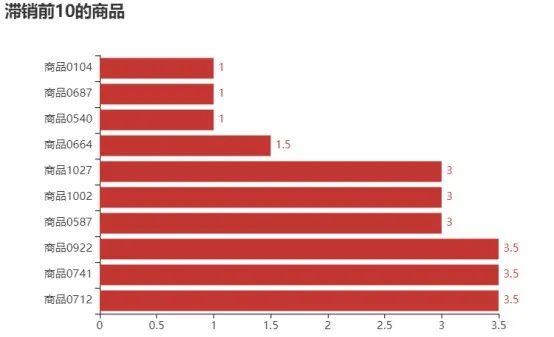
探索6个月销售额排名前10和后10的商品如代码清单9所示。
代码清单9 10种畅销商品、10种滞销商品
# 销售额前10的商品group4 = data.groupby(by='商品ID', as_index=False)['总金额(元)'].sum()group4.sort_values(by='总金额(元)', ascending=False, inplace=True)d = group4.iloc[: 10]x_data = d['商品ID'].values.tolist()y_data = np.round(d['总金额(元)'].values, 2).tolist()bar = (Bar(init_opts=opts.InitOpts(width='800px',height='600px')).add_xaxis(x_data).add_yaxis('', y_data, label_opts=opts.LabelOpts(font_size=15)).set_global_opts(title_opts=opts.TitleOpts(title='畅销前10的商品'),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}',font_size=15)),xaxis_opts=opts.AxisOpts(type_='category',axislabel_opts=opts.LabelOpts({'interval': '0'}, font_size=15, rotate=30))))bar.render_notebook()h = group4.iloc[-10: ]x_data = h['商品ID'].values.tolist()y_data = np.round(h['总金额(元)'].values, 2).tolist()bar = (Bar().add_xaxis(x_data).add_yaxis('', y_data, label_opts=opts.LabelOpts(position='right')).set_global_opts(title_opts=opts.TitleOpts(title='滞销前10的商品'),xaxis_opts=opts.AxisOpts(axislabel_opts={'interval': '0'})).reversal_axis())grid = Grid(init_opts=opts.InitOpts(width='600px', height='400px'))grid.add(bar, grid_opts=opts.GridOpts(pos_left='18%'))grid.render_notebook()
4.自动售货机的销售情况
探索6个月销售额前10以及销售额后10的设备及其所在的城市,并进行可视化分析
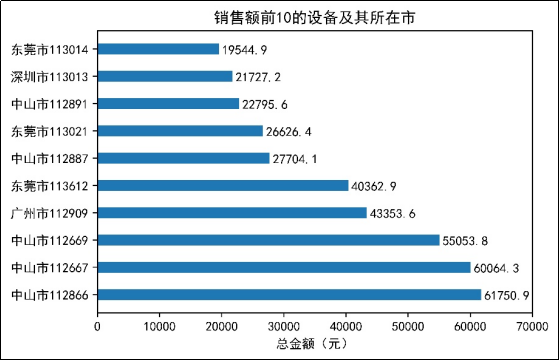
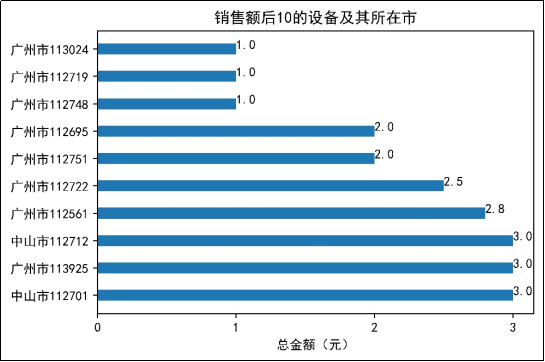
销售额靠前的设备所在城市主要集中在中山市、广州市、东莞市和深圳市,其中,销售额前3的设备都集中在中山市。由图11可知,广州市的设备113024、112719、112748的销售额只有1元,而销售额后10的设备全部在广州市和中山市。
探索6个月销售额前10以及销售额后10的设备及其所在的城市如代码清单10所示。
代码清单10 销售额前10、后10的设备及其所在市
group5 = data.groupby(by=['市', '设备编号'], as_index=False)['总金额(元)'].sum()group5.sort_values(by='总金额(元)', ascending=False, inplace=True)b = group5[: 10]label = []# 销售额前10的设备及其所在市for i in range(len(b)):a = b.iloc[i, 0] + str(b.iloc[i, 1])label.append(a)x = np.round(b['总金额(元)'], 2).values.tolist()y = range(10)plt.bar(x=0, bottom=y, height=0.4, width=x, orientation='horizontal')plt.xticks(range(0, 80000, 10000)) # 设置x轴的刻度范围plt.yticks(range(10), label)for y, x in enumerate(np.round(b['总金额(元)'], 2).values):plt.text(x + 500, y - 0.2, "%s" %x)plt.xlabel('总金额(元)')plt.title('销售额前10的设备及其所在市')plt.show()l = group5[-10: ]label1 = []for i in range(len(l)):a = l.iloc[i, 0] + str(l.iloc[i, 1])label1.append(a)x = np.round(l['总金额(元)'], 2).values.tolist()y = range(10)plt.bar(x=0, bottom=y, height=0.4, width=x, orientation='horizontal')plt.xticks(range(0, 4, 1)) # 设置x轴的刻度范围plt.yticks(range(10), label1)for y, x in enumerate(np.round(l['总金额(元)'], 2).values):plt.text(x, y, "%s" %x)plt.xlabel('总金额(元)')plt.title('销售额后10的设备及其所在市')plt.show()
统计各城市销售额小于100的设备数量,并进行可视化分析
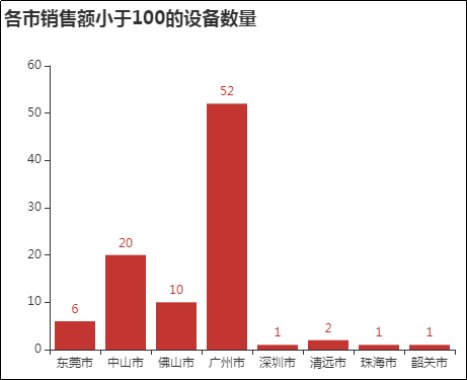
只展示部分内容后续更多精彩就在书中探索吧
推荐阅读

正版链接:https://item.jd.com/13814157.html

文末精彩福利
购买链接:https://item.jd.com/14141114.html
- 🎁本次送书1~3本【取决于阅读量,阅读量越多,送的越多】👈
- ⌛️活动时间:截止到2023-10月18号
- ✳️参与方式:关注博主+三连(点赞、收藏、评论)
私信我进送书互三群有更多福利哦可以在文章末尾或主页添加微信

这篇关于Python数据挖掘项目实战——自动售货机销售数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





