本文主要是介绍mysql 每天6000w数据_震惊,小白看了都知道的!!Mysql6000w数据表的查询优化到0.023S...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
很抱歉现在才把这篇文章发出来,这几天事情比较多,周四把任务完成才得空写一写,闲话不多说请看下↓↓↓
详细需求
需求:
系统中有一个专门存车流量的库(没有主键),其中一个历史表数据量太大,表空间占据太大,每天有500w的数据写入,然后老大给我安排了个任务,让我写个按天分表的定时任务,每次把一天的数据转移到按天生成的表中,并删除原表中的数据,主要目的是不想再增长表空间了,保持一个平衡,因为每天删500w也会加500w
表空间和数据量:
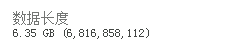

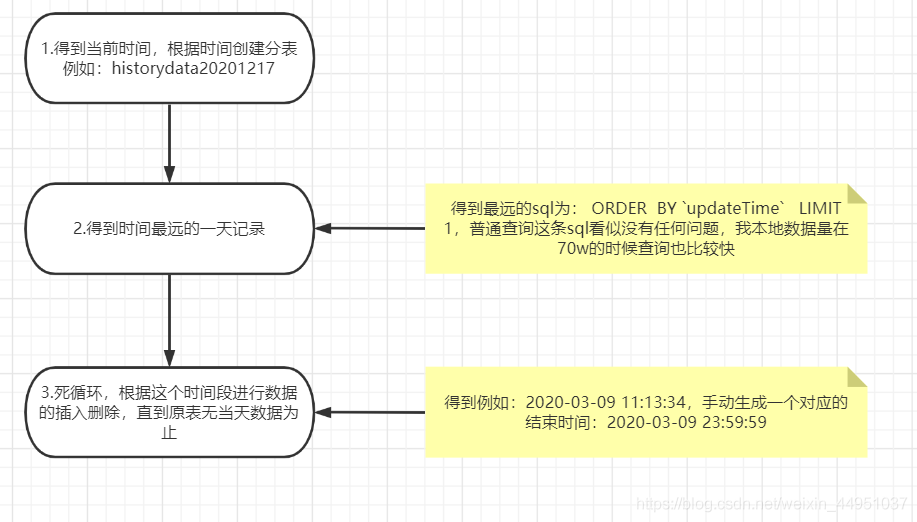
实现思路
我本人实现的做法流程,如图
实现伪代码(删减了部分代码):
/**
* 转移数据 每天凌晨3点 每次只能转移一天的数据
*/
@Scheduled(cron = "0 0 3 * * ?")
public void dataTransfer()throws Exception{
System.out.println("定时器开始运行------------------------------------------");
String tabaleName = "XXX";
String isTable = getTableName(tabaleName);
// 当返回为空时,代表该表不存在,则创建
if(ObjectUtils.isNull(isTable)){
createHistoryDate(names);
}
// 得到最远的时间段
Map orderTime = orderByTime();
// 得到开始和结束时间
if(SysFun.isNotEmpty(orderTime) && orderTime.size() > 0){
orderTime.put("startTime",startTime);
orderTime.put("endTime",endTime);
orderTime.put("tableName",tabaleName);
int i=0;
for (;;) {
System.out.println("进入循环");
// 转移数据
int rst = dataTransfer(orderTime);
// 删除重复数据
int delt = deleteDataTransfer(orderTime);
// 当今天数据转移完成时,退出本次循环
if(rst<=0 && delt <=0){
break;
}
i++;
System.out.println("转移数据表为:"+tabaleName+" 转移数据次数: "+i);
}
}
System.out.println("定时器结束运行------------------------------------------");
}
心路历程
方法完成之后,上周五去服务器正式实测,实测时方法用 @PostConstruct 修饰,会在服务器加载Servlet的时候运行,并且只会被服务器执行一次。
当时控制台打印:
(“定时器开始运行”)卡住,去库中看到表已成功创建
开始以为是某个地方异常了,后面逐一打印步骤发现是得到最远时间段是卡住了,也就是被一条sql查询卡住了(直接用这条sql去库里查询300s+也没查询出来),然后维护这个库的小伙跟我说:要不直接limit 1 吧,它的插入是根据时间顺序插入的,当时也想到了会出问题,时间顺序肯定不可能完全按照顺序写入,周末程序走了2天果然有问题,如图:
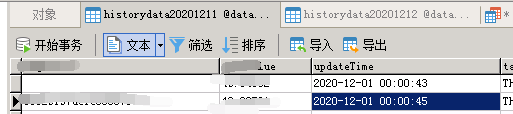
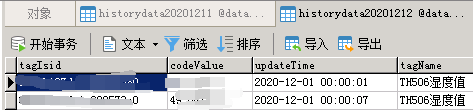
limit 1是行不通了,那就只能来查询优化了,讲查询优化之前,先说说为什么我们使用order by为什么会这么慢?
深入分析
MySql有两种方式可以实现 ORDER BY 这里只做简单介绍:
通过索引扫描生成有序的结果
举个例子,假设history表有id字段上有主键索引,且id目前的范围在1001-1006之间,则id的索引B+Tree如下:
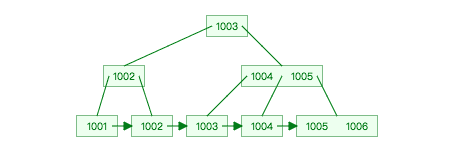
现在当我们想按照id从小到大的顺序中取出数据时,执行以下sql
select * from history order by id
Mysql会直接遍历上图id索引的叶子节点链表,不需要进行额外的排序操作。这就是用索引扫描来排序。
2. 使用文件排序(filesort)
但如果id字段没有任何索引,上图的B+Tree结构不存在,Mysql就只能先扫表筛选出符合条件的数据,再将筛选结果根据id排序。这个排序过程就是filesort。
我们要让ORDER BY字句使用索引来避免filesort(用“避免”可能有些欠妥,某些场景下全表扫描、filesort未必比走索引慢),以提高查询效率。
————————————————————————————-
进行优化之前我们还需要学会看sql的执行计划(EXPLAIN)分别为(这里着重讲解type、rows、Extra,其它的这里不做讲解,可自己私下进行了解):
id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
type:对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
Mysql找到数据行的方式,效率排名 NULL > system > const > eq_ref > ref > range > index > All
1.range 只检索给定范围的行,使用一个索引来选择行,一般是在where中出现between、、in等查询,范围扫描好于全表扫描
2.index Full Index Scan,Index与All区别为index类型只遍历索引树。通常比All快,因为索引文件通常比数据文件小。也就是说,虽然all和index都是读全表,但是index是从索引中读取的,而all是从硬盘读取的
3.ALL Full Table Scan,将遍历全表以找到匹配的行
rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,也就是说,用的越少越好
extra :包含不适合在其他列中显式但十分重要的额外信息
1.Using Index:表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错。如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。
2.Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
下面我们通过一张真实数据图来分析
由于正式库的未优化之前的执行计划图片忘记保存,这里用本地环境代替一下,内容相同
执行SQL:
EXPLAIN SELECT updateTime FROM historydata ORDER BY updateTime LIMIT 1

可以看到type:ALL,则代表为全表扫描,rows为扫描行数,Extra的描述信息为 using filesort,所以造成了查询的缓慢,既然知道问题的源头,下面我们就来解决问题!!
解决
我们线上的历史表是没有主键的,设计初有一个唯一索引,如图:

通过我们那种查询是没有办法命中索引的,遵循最左原则,为updateTime新建一个普通索引(index)NORMAL

添加索引的过程中再提一嘴,因为这个历史库时时刻刻都有数据写入,所以我当时建索引时担心锁表,后面查询相关资料就知道了,Mysql5.6之后的版本不影响读写,不会锁表,前提存储引擎为InnoDB,MyISAM加索引锁表,读写会全部堵塞。
如果表数据量过多,可能建立索引的时间会过长,以我举例6000w差不多建了4h,下面为索引效果图:


结合执行计划分析该数据,优化就到这了,优化过后这几天定时程序异常的稳,每天定时500w数据的转移和删除,也算是解决了。
结尾
其实本文就是一些很基础得东西,欢迎指出问题,可能大家都知道,但是没有机会去实际接触这么多数据,实际去优化这样的东西,我也是第一次接触这些东西,写本文单纯就是想分享下,顺便加深下自己的印象,写的不好,请见谅!!
sql索引详解(mysql)
Mysql – ORDER BY详解
这篇关于mysql 每天6000w数据_震惊,小白看了都知道的!!Mysql6000w数据表的查询优化到0.023S...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







