本文主要是介绍图像分类任务ViT与CNN谁更胜一筹?DeepMind用实验证明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
今天跟大家分享DeepMind发表的一篇技术报告,通过实验得出,CNN与ViT的架构之间虽然存在差异,但同等计算资源的预训练下两者性能非常相似。

-
论文标题:ConvNets Match Vision Transformers at Scale
-
机构:Google DeepMind
-
论文地址:https://arxiv.org/pdf/2310.16764.pdf
-
关键词:CNN、Vision Transformer
1.动机
卷积神经网络(ConvNets)是深度学习早期成功的原因。20多年前ConvNets首次商业化部署,2012年AlexNet在ImageNet挑战赛的成功重新点燃了人们对该领域的兴趣。近十年来,ConvNets(通常是ResNets)主导着计算机视觉基准;然而,近年来它们逐渐被Vision Transformers(ViTs)所取代。
与此同时,计算机视觉行业已经从主要评估随机初始化的网络在ImageNet等特定数据集上的性能,转向评估从web收集的大型通用数据集上预训练网络的性能。这就提出了一个重要的问题:使用差不多的计算资源进行预训练,Vision Transformers是否优于ConvNet架构?
尽管大多数研究人员认为Vision Transformer比ConvNets具有更好的扩展性,但几乎没有证据支持这一说法。研究ViTs的论文常与较差的ConvNet baseline(通常是原始的ResNet架构)进行比较。此外,最强的ViT模型使用超过500k TPU-v3 core hours的计算资源进行预训练,极大地超过了预训练ConvNet时所需的计算资源。
2.实验
作者评估了NFNet模型的拓展性,NFNet是与第一篇ViT论文同时发表的纯卷积架构,也是最后一个在ImageNet上的SOTA ConvNet。作者没有对模型体系结构或训练过程进行更改(除了调整简单的超参数,如学习率或epoch)。预训练时使用了多达110k TPU-v4 core hours的计算资源,在JFT-4B数据集上预训练模型,该数据集包含约40亿张标记图像,共有30k个类。作者观察了验证集损失和模型预训练时使用的计算资源之间的log-log关系。在ImageNet上进行微调后,使用同等计算资源的NFNet与ViTs的性能差不多,如下图所示。
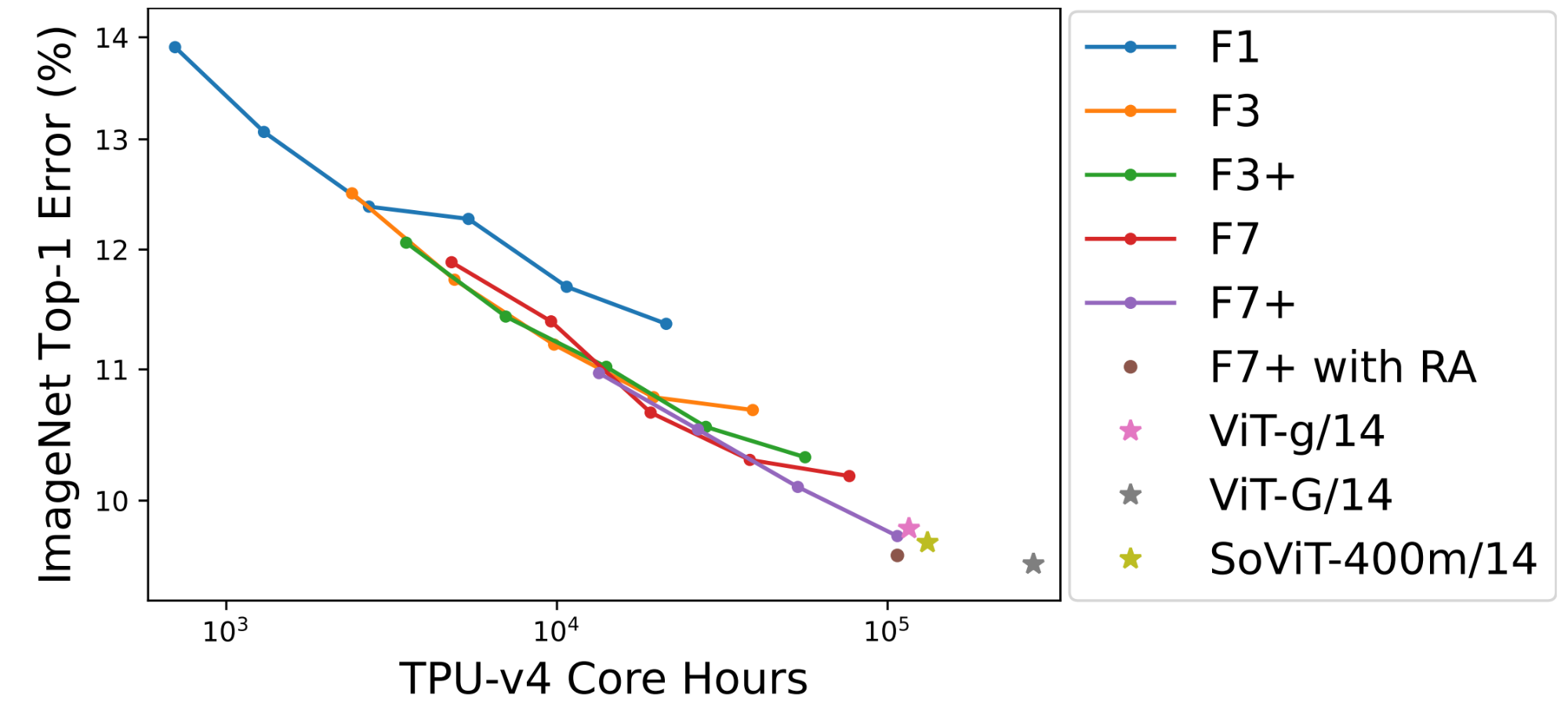
上图为ImageNet Top-1 error,使用50个epoch微调预训练NFNet模型,在微调时使用Sharpness Aware Minimization(简称SAM),使用了随机深度和dropout。微调时输入图片分辨率为384×384,评估时输入图片分辨率为480×480。图中2个轴都是对数缩放的。随着预训练时使用的计算资源的增加,性能持续提高。最大的模型(F7+)与使用相当计算资源预训练的vit有相当的性能。当使用Repeated Augmentation(RA)进行微调时,模型的性能进一步提高。
作者在JFT-4B数据集上训练了一系列不同深度和宽度的NFNet模型。每个模型都使用余弦衰减学习率,每个模型训练的epoch数量在0.25-8之间。为不同epoch数量的训练分别调整基础学习率。作者根据训练结束时使用130k张图片计算的验证损失和训练模型时所需的计算资源绘制了下图。F7和F3的宽度相同,但F7的深度是F3的2倍,类似地,F3的深度是F1的2倍,F1的深度是F0的两倍。F3+和F7+的深度与F3和F7相同,但宽度较大。使用带有动量和自适应梯度裁剪(Adaptive GradientClipping,简称AGC)的SGD进行训练,batch size为4096,在训练时使用的图片尺寸,在评估时使用的图片尺寸。NFNet网络结构和训练流程的细节,作者参考了NFNet原论文《High-performance large-scale image recognition without normalization》,原文中6.2节描述了在JFT数据集上的预训练细节。需要注意的是,在训练前,作者从JFT-4B数据集中删除了与ImageNet训练集和验证集相似的图像。
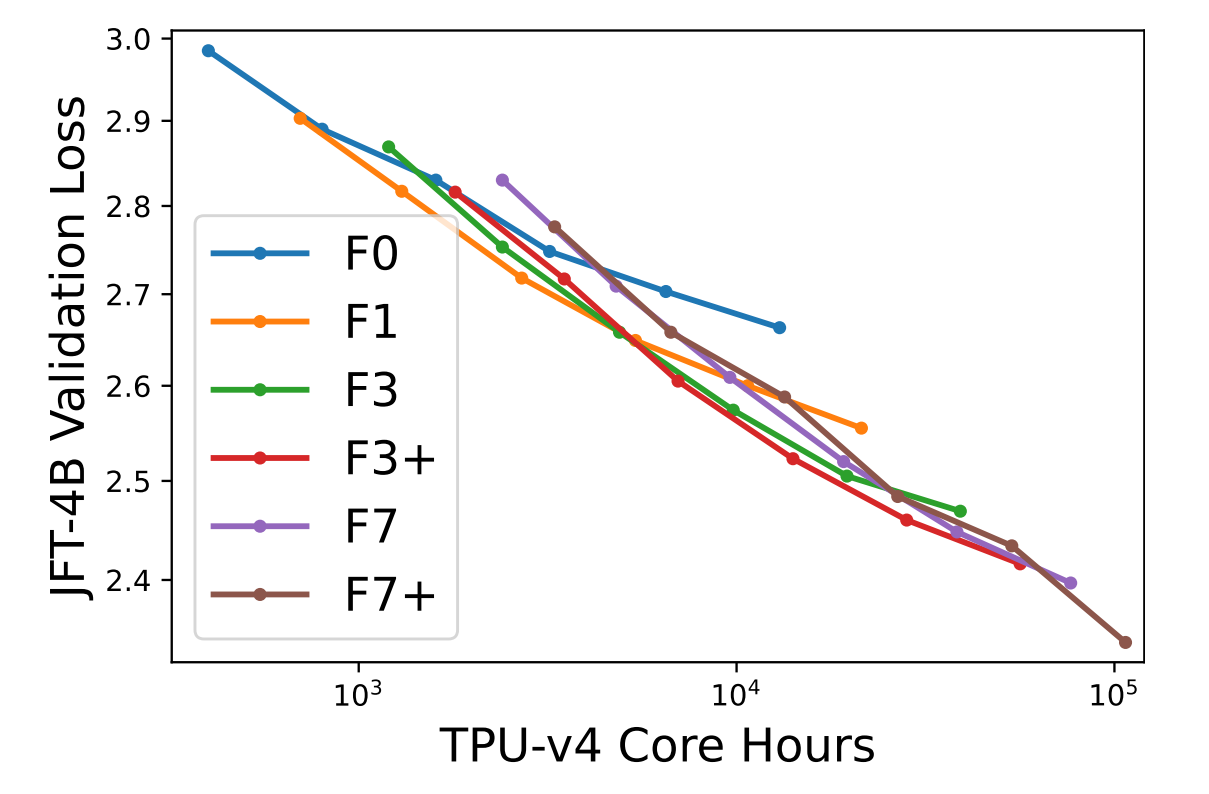
上图描述了NFNets在JFT-4B数据集上的损失与训练时使用的计算资源。2个轴都是对数缩放的,每条曲线中不同的点表示使用不同epoch数量的训练模型。上图表示了验证损失和预训练计算资源之间具有log-log线性趋势。
最优的模型规模和最优的epoch数量(达到最小验证损失)都随着投入的计算资源的增加而增加。
尽管两种模型架构之间存在显著差异,但同等规模的预训练NFNets性能与预训练Vision Transformers性能非常相似。
3.总结
决定结构合理的模型的性能的最重要因素是训练时使用的计算资源和数据。尽管ViTs在计算机视觉方面的成功令人印象深刻,但没有强有力的证据表明,预训练的ViTs优于预训练的ConvNets。然而,ViTs在特定的上下文中可能具有实际的优势,例如能够跨模态使用相似的模型组件。
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.10.27
CV计算机视觉每日开源代码Paper with code速览-2023.10.26
CV计算机视觉每日开源代码Paper with code速览-2023.10.25
CV计算机视觉每日开源代码Paper with code速览-2023.10.24
CV计算机视觉每日开源代码Paper with code速览-2023.10.23
使用目标之间的先验关系提升目标检测器性能
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
如何优雅地读取网络的中间特征?
港科大提出适用于夜间场景语义分割的无监督域自适应新方法
这篇关于图像分类任务ViT与CNN谁更胜一筹?DeepMind用实验证明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





