本文主要是介绍【论文解读】单目3D目标检测 LPCG(ECCV 2022),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文分享单目3D目标检测,LPCG模型的论文解读,了解它的设计思路,论文核心观点,模型结构,以及效果和性能。

目录
一、LPCG 简介
二、论文核心观点
三、思路框架
四、核心观点——单目3D目标检测的标签中,3D位置是极其关键的
五、核心内容——低成本模式,点云数据生成粗略的3D标签
六、核心内容——高精度模式,小量标注数据生成精准标签
七、在自动驾驶中应用LPCG
八、实验分析
一、LPCG 简介
LPCG是一种用激光点云指导-单目3D目标检测的方法,通过点云数据生成海量粗略的3D标签,生成过程中不用对点云进行标注;降低3D标签的成本。
同时这些海量“粗略的3D标签”位置是准确的,只是尺寸和朝向有些偏差;
所以如何通过点云数据,直接生成粗略的3D标签是LPCG论文亮点。
用这些海量“粗略的3D标签”,作为伪标签,指导单目3D目标检测训练。这种方法可以应用到各种单目3D目标检测模型中,模型精度提升大,太强了~
论文地址:Lidar Point Cloud Guided Monocular 3D Object Detection
开源地址:https://github.com/SPengLiang/LPCG
二、论文核心观点
论文核心观点,主要有4点组成:
- 1、在单目3D目标检测的标签中,中心点位置准确性,是非常重要的;与标签的尺寸和朝向相比,3D位置是极其关键的。
- 2、激光雷达的点云数据,具有准确的3D测量;获取点云数据,不用对点云数据进行标注,经过算法直接生成粗略的3D标签。
- 3、标注一小部分数据,监督训练点云3D目标检测模型,得到高精度的模型;模型预测的结果,作为较精准的3D标签。
- 4、用海量的粗略3D标签,和小量的较精准3D标签,一起形成伪标签,指导单目3D目标检测训练。
三、思路框架
LPCG是一种用激光点云指导-单目3D目标检测的方法,可以应用到各种单目3D目标检测模型中,比如:MonoFlex、M3D-RPN等等。
思路框架如下图所示:
第一步:生成伪标签
- 低成本模式,获取点云数据,不用对点云数据进行标注,经过算法直接生成粗略的3D标签。
- 高精度模式,标注一小部分数据,监督训练点云3D目标检测模型,得到高精度的模型;模型预测的结果,作为较精准的3D标签。
- 整合低成本模型输出的海量的粗略3D标签,高精度模型输出的较精准的3D标签,一起作为单目3D目标检测模型的标签。
第二步:训练单目3D模型
- 得到伪标签,进行有监督训练,得到单目3D目标检测模型。

四、核心观点——单目3D目标检测的标签中,3D位置是极其关键的
作者对标签中的中心位置、尺寸、朝向,进行干扰实验。通过在百分比范围内,随机移动相应的值来扰乱完美的手动注释标签。
受5%干扰的标签准确率,与完美标签的准确度相当。
当实施大干扰(10%和20%)时,可以看到位置(Location)主导性能(AP仅在干扰位置时显著降低)。
这表明,具有精确位置的粗略伪3D box标签,可以替代完美的带注释的3D box标签。即:发现手动标注的完美标签,对于单目3D检测是非必要的。

作者注意到激光点云可以提供有价值的3D Location信息,点云可以提供精确的深度测量,而周围精确的深度信息可以提供更加精确的物体位置,这对于3D物体检测至关重要。
点云可以由激光雷达设备轻松获取,允许离线收集大量点云,无需人工成本。
于是,使用点云生成3D伪标签,新生成的标签可用于训练单目3D检测器。
五、核心内容——低成本模式,点云数据生成粗略的3D标签
低成本模式,获取点云数据,不用对点云数据进行标注,经过算法直接生成粗略的3D标签。思路流程:
1、2D实例分割:采用2D实例分割模型,对图像进行分割,获得2D框和掩模mask。默认使用mask-rcnn模型。
2、提取ROI点云:结合实例分割结果mask,和相机平截头体camera frustums,提取每个对象选择相关的ROI点云。其中忽略了内部没有任何点云点的框。
3、点云聚类:位于同一平截头体中的激光雷达点由对象点和混合背景或遮挡点组成。为了消除不相关的点,作者用DBSCAN根据密度将RoI点云划分为不同的组。在3D空间中接近的点将聚集到一个簇中。
4、形成各个物体点云:将包含大多数点的簇视为与对象相对应的目标。
5、在BEV中形成2D框:为了简化解决3D边界框的问题,作者将点投影到BEV鸟瞰图上,减少了参数。得到BEV的中心点信息、长宽、朝向。
6、生成3D框信息:结合点云的高度,和BEV的中心点信息、长宽、朝向,得到完整的3D框信息(中心位置、长宽高、朝向)

这里再讲一下在BEV中形成2D框,使用物体点的凸包( the convex hull),然后使用旋转卡壳(rotating calipers)。

看一下2D实例分割的代码,默认使用mask-rcnn模型,进行实例分割。包含的类别的:
COCO_INSTANCE_CATEGORY_NAMES = ['__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus','train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign','parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A','handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball','kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket','bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl','banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza','donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table','N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book','clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]核心代码:
if __name__ == '__main__':# pre_trained_mask_rcnn_path = '/private/pengliang/maskrcnn_resnet50_fpn.pth'# model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False, pretrained_backbone=False)# model.load_state_dict(torch.load(pre_trained_mask_rcnn_path))model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)model.cuda()model.eval()with torch.no_grad():for _, v in enumerate(tqdm(train_id)):img_file_path = os.path.join(img_dir, v+'.png')seg_mask_path = img_file_path.replace('image_2', 'seg_mask').replace('png', 'npz')seg_bbox_path = img_file_path.replace('image_2', 'seg_bbox').replace('png', 'txt')seg_mask_dir = os.path.dirname(seg_mask_path)seg_bbox_dir = os.path.dirname(seg_bbox_path)if not os.path.exists(seg_mask_dir):os.makedirs(seg_mask_dir)if not os.path.exists(seg_bbox_dir):os.makedirs(seg_bbox_dir)image = cv.imread(img_file_path)image_tensor = torchvision.transforms.functional.to_tensor(image)output = model([image_tensor.cuda()])[0]labels = output['labels'].cpu().numpy()'''for car'''ind = (labels == 3)scores = (output['scores'].cpu().numpy())score_ind = scores > 0.5ind = ind & score_indbbox = (output['boxes'].cpu().numpy())[ind]masks = (output['masks'].cpu().numpy())[ind]scores = scores[ind]if bbox.shape[0] > 0:bbox2d = np.hstack([bbox.reshape(-1, 4), scores.reshape(-1, 1)])np.savetxt(seg_bbox_path, bbox2d, fmt='%f')np.savez(seg_mask_path, masks=masks[:, 0, ...])看一下点云聚类的代码,默认使用DBSCAN算法:
import os
from tqdm import tqdm
import numpy as np
import cv2 as cv
from sklearn.cluster import DBSCAN
import yamlimport utilskitti_cfg = yaml.load(open('./config/kitti.yaml', 'r'), Loader=yaml.Loader)
kitti_merge_data_dir = kitti_cfg['KITTI_merge_data_dir']
dst_low_cost_label_dir = os.path.join(kitti_cfg['root_dir'], 'low_cost/label_2')def obtain_cluster_box(l_3d, l_2d, seg_bbox_path, seg_mask_path, P2, wh_range, mask_conf):bbox2d = np.loadtxt(seg_bbox_path).reshape(-1, 5)bbox_mask = (np.load(seg_mask_path))['masks']_, h, w = bbox_mask.shapefov_ind = (l_3d[:, 2] > 0) & (l_2d[:, 0] > 0) & (l_2d[:, 1] > 0) & (l_2d[:, 0] < w-1) & (l_2d[:, 1] < h-1)l_3d, l_2d = l_3d[fov_ind], l_2d[fov_ind]label = []for index, b in enumerate(bbox2d):if b[-1] < mask_conf:continuebbox2d_2 = bbox_mask[index]bbox2d_2[bbox2d_2 < 0.7] = 0bbox2d_2[bbox2d_2 >= 0.7] = 1ind = bbox2d_2[l_2d[:, 1], l_2d[:, 0]].astype(np.bool)cam_points = l_3d[ind]if len(cam_points) < 10:continuecluster_index = DBSCAN(eps=0.8, min_samples=10, n_jobs=-1).fit_predict(cam_points)cam_points = cam_points[cluster_index > -1]cluster_index = cluster_index[cluster_index > -1]if len(cam_points) < 10:continuecluster_set = set(cluster_index[cluster_index > -1])cluster_sum = np.array([len(cam_points[cluster_index == i]) for i in cluster_set])cam_points = cam_points[cluster_index == np.argmax(cluster_sum)]rect = cv.minAreaRect(np.array([(cam_points[:, [0, 2]]).astype(np.float32)]))(l_t_x, l_t_z), (w, l), rot = rectif w > l:w, l = l, wrot = 90 + rotif w > wh_range[0] and w < wh_range[1] and l > wh_range[2] and l < wh_range[3]:rect = ((l_t_x, l_t_z), (w, l), rot)box = cv.boxPoints(rect)h = np.max(cam_points[:, 1]) - np.min(cam_points[:, 1])y_center = np.mean(cam_points[:, 1])y = y_center + h / 2x, z = np.mean(box[:, 0]), np.mean(box[:, 1])Ry = (-(np.pi / 2 - (-rot) / 180 * np.pi)) % (np.pi*2)if Ry > np.pi:Ry -= np.pi*2if Ry < -np.pi:Ry += np.pi*2c_3d = utils.corner_3d([h, w, l, x, y, z, Ry])c_2d = utils.convert_to_2d(c_3d, P2)bbox = [np.min(c_2d[:, 0]), np.min(c_2d[:, 1]),np.max(c_2d[:, 0]), np.max(c_2d[:, 1])]res = np.array([bbox[0], bbox[1], bbox[2], bbox[3],h, w, l, np.mean(box[:, 0]), y, np.mean(box[:, 1]), Ry])res = np.round(res, 2)label.append(['Car', '0', '0', '0'] + list(res))return np.array(label)if __name__ == '__main__':wh_range = [1.2, 1.8, 3.2, 4.2]mask_conf = 0.9root_dir = kitti_merge_data_dirif not os.path.exists(dst_low_cost_label_dir):os.makedirs(dst_low_cost_label_dir)calib_dir = os.path.join(root_dir, 'calib')lidar_dir = os.path.join(root_dir, 'velodyne')seg_box_dir = os.path.join(root_dir, 'seg_bbox')seg_mask_dir = os.path.join(root_dir, 'seg_mask')train_id_path = os.path.join(root_dir, 'split/train.txt')train_id = np.loadtxt(train_id_path, dtype=str)for i, v in enumerate(tqdm(train_id)):lidar_path = os.path.join(lidar_dir, v+'.bin')calib_path = os.path.join(calib_dir, v+'.txt')seg_bbox_path = os.path.join(seg_box_dir, v+'.txt')seg_mask_path = os.path.join(seg_mask_dir, v+'.npz')dst_low_cost_label_path = os.path.join(dst_low_cost_label_dir, v+'.txt')# obtain and transform lidar pointsl_3d = np.fromfile(lidar_path, dtype=np.float32, count=-1).reshape([-1, 4])[:, :3]calibs = utils.parse_calib('3d', calib_path)l_3d = (calibs['l2i'] @ (np.concatenate([l_3d, np.ones_like(l_3d[:, :1])], axis=1)).T).Tl_2d = (utils.convert_to_2d(l_3d, calibs['P2'])).astype(np.int32)if not os.path.exists(seg_bbox_path):np.savetxt(dst_low_cost_label_path, np.array([]), fmt='%s')continuelow_cost_label = obtain_cluster_box(l_3d, l_2d, seg_bbox_path, seg_mask_path, calibs['P2'], wh_range, mask_conf)np.savetxt(dst_low_cost_label_path, low_cost_label, fmt='%s')六、核心内容——高精度模式,小量标注数据生成精准标签
标注一小部分数据,监督训练点云3D目标检测模型,得到高精度的模型;模型预测的结果,作为较精准的3D标签。
- 首先使用LiDAR点云和相关的3D box注释,从头开始训练基于LiDAR的3D检测器。
- 然后利用预训练的基于激光雷达的3D检测器,来推断其他未标记激光雷达点云上的3D box。
- 这样的3D box结果被当作伪标签来训练单目3D检测器。
作者将伪标签与手动注释的完美标签进行了比较。由于精确的3D位置测量,基于LiDAR的3D探测器预测的伪标签相当准确,可以直接用于单目3D检测器的训练。
由生成的伪标签训练的单目3D检测器显示出接近的性能,只需要少量的3D注释框就足以推动单目方法实现高性能。
看一下高精度模式和低成本模式的效果对比:



在LiDAR的3D检测器中,默认使用的是OpenPCDet开源库中 PV-RCNN模型。还有许多其他点云3D目标检测模型可以换的。

OpenPCDet库具有统一点云坐标的数据模型分离,可轻松扩展到自定义数据集。
统一3D框定义:(x、y、z、dx、dy、dz、航向)。

OpenPCDet开源库:GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
在KITTI数据集的val集上,3D检测性能为中等难度:
| training time | Car@R11 | Pedestrian@R11 | Cyclist@R11 | download | |
|---|---|---|---|---|---|
| PointPillar | ~1.2 hours | 77.28 | 52.29 | 62.68 | model-18M |
| SECOND | ~1.7 hours | 78.62 | 52.98 | 67.15 | model-20M |
| SECOND-IoU | - | 79.09 | 55.74 | 71.31 | model-46M |
| PointRCNN | ~3 hours | 78.70 | 54.41 | 72.11 | model-16M |
| PointRCNN-IoU | ~3 hours | 78.75 | 58.32 | 71.34 | model-16M |
| Part-A2-Free | ~3.8 hours | 78.72 | 65.99 | 74.29 | model-226M |
| Part-A2-Anchor | ~4.3 hours | 79.40 | 60.05 | 69.90 | model-244M |
| PV-RCNN | ~5 hours | 83.61 | 57.90 | 70.47 | model-50M |
| Voxel R-CNN (Car) | ~2.2 hours | 84.54 | - | - | model-28M |
| Focals Conv - F | ~4 hours | 85.66 | - | - | model-30M |
七、在自动驾驶中应用LPCG
在自动驾驶中,下图说明了数据收集策略。
- 大多数自动驾驶系统可以轻松地同步收集大量未标记的LiDAR点云数据和RGB图像。
- 该数据由多个序列构成,其中每个序列通常指向特定场景并包含多个连续帧。
- 由于现实世界中时间和资源有限,仅选择一些序列进行注释,以训练网络,如Waymo。
- 此外,为了降低高注释成本,仅对所选序列中的一些关键帧进行注释,例如KITTI。因此,在实际应用程序中仍然存在大量未标记的数据。

考虑到LPCG可以充分利用未标记的数据,在现实世界的自动驾驶系统中使用是很自然的。
- 高精度模式,只需要少量标记数据。
- 在低成本模式,从单目3D检测器的剩余未标记数据中,生成高质量的训练数据,以提高准确性。
低成本模式不需要任何3D注释框,仍然可以提供准确的3D框伪标签;生成的3D box伪标签对于单目3D检测器来说是很不错的。
八、实验分析
KITTI 测试集上实现分析的。 使用红色表示最高结果,蓝色表示第二高结果,青色表示第三高结果。
‡ 表示我们使用的基线检测器,改进是相对于基线检测器而言的。相对于MonoFlex模型,在简单场景的AP3D提升了5.62,达到25.56。

DD3D 采用大型私有 DDAD15M 数据集(包含大约 15M 帧)和KITTI 深度数据集(包含大约 26K 帧)。
KITTI 深度数据集提供大约 26K 样本来训练深度估计器(对于大多数基于深度图的方法),或为单目 3D 检测器 (LPCG) 生成额外的训练样本。
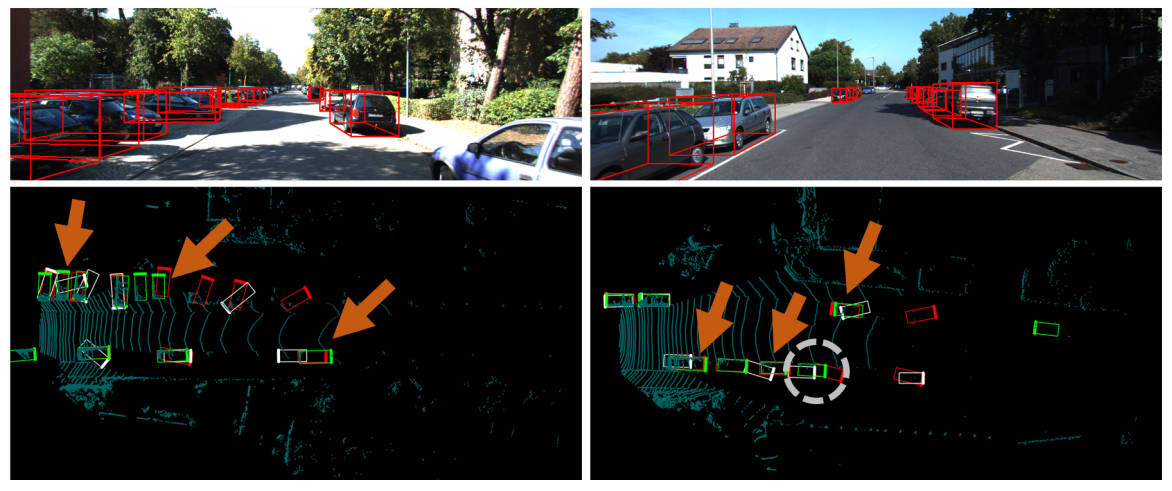
LPCG训练的 M3D-RPN的结果。 绿色:真实框。 红色:预测框。 白色:来自 M3D-RPN 的原始预测。
鸟瞰图中方框的粗体一侧指的是方向,可以看到LPCG的预测更加准确,一些预测框与真实框重叠。还展示了失败案例,这些案例包含在灰色虚线圆圈中。


分享完成~
单目3D目标检测专栏,大家可以参考一下
【综述篇】
单目3D目标检测 方法综述——直接回归方法、基于深度信息方法、基于点云信息方法-CSDN博客
【数据集】单目3D目标检测:
3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图)_kitti标签_一颗小树x的博客-CSDN博客
3D目标检测数据集 DAIR-V2X-V_一颗小树x的博客-CSDN博客
【论文解读】单目3D目标检测:
【论文解读】SMOKE 单目相机 3D目标检测(CVPR2020)_相机smoke-CSDN博客
【论文解读】单目3D目标检测 CUPNet(ICCV 2021)-CSDN博客
【论文解读】单目3D目标检测 DD3D(ICCV 2021)-CSDN博客
【论文解读】单目3D目标检测 MonoDLE(CVPR2021)_一颗小树x的博客-CSDN博客
【论文解读】单目3D目标检测 MonoFlex(CVPR 2021)-CSDN博客
【论文解读】单目3D目标检测 MonoCon(AAAI2022)_一颗小树x的博客-CSDN博客
【实践应用】
单目3D目标检测——SMOKE 环境搭建|模型训练_一颗小树x的博客-CSDN博客
单目3D目标检测——SMOKE 模型推理 | 可视化结果-CSDN博客
单目3D目标检测——MonoDLE 模型训练 | 模型推理_一颗小树x的博客-CSDN博客
单目3D目标检测——MonoCon 模型训练 | 模型推理-CSDN博客
这篇关于【论文解读】单目3D目标检测 LPCG(ECCV 2022)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




