本文主要是介绍搜索推荐算法挑战赛OGeek-完整方案及代码(亚军),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先很幸运拿到TIANCHI天池-OGeek算法挑战赛大赛的亚军,同时非常感谢大佬队友的带飞,同时希望我的分享与总结能给大家带来些许帮助,并且一起交流学习。(作者:王贺,知乎:鱼遇雨欲语与余)
赛题链接:
https://tianchi.aliyun.com/competition/entrance/231688/introduction
Github链接:
https://github.com/fanfanda/OGeek-Competition

本文目录
赛题分析
数据分析
赛题难点
特征工程
算法模型
思考总结
1. 赛题分析
此次赛题来自OPPO手机搜索排序优化的一个子场景,并做了相应的简化,意在解决query-title语义匹配的问题。简化后,本次题目内容主要为一个实时搜索场景下query-title的ctr预估问题。
赛题特征:prefix(用户输入,query前缀),query_prediction(根据当前前缀,预测的用户完整需求查询词,最多10条;预测的查询词可能是前缀本身,数字为统计概率),title(文章标题),tag(文章内容标签)
提供数据:初赛复赛一致, 训练数据:200万 验证数据:5万 测试数据1:5万 测试数据2:25万
评估指标:本次竞赛的评价标准采用F1 score 指标,正样本为1,公式如下:
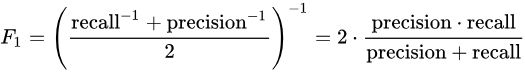
2. 数据分析
这一部分将会对部分数据进行分析,另外获取部分特征的点击率分布情况判断特征效果,看分布可以有一个很好的初步验证作用。
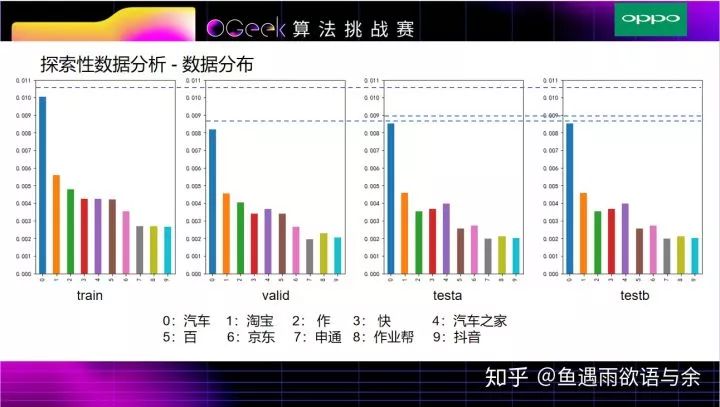
这四个图是prefix在各自数据集的百分比统计,并以训练集中出现频次top10的prefix画出了每个数据集的占比情况,可以发现valid与testa和testb的分布相似,说明valid与testa和testb的查询时间比较接近,作为验证集线下比较可信。
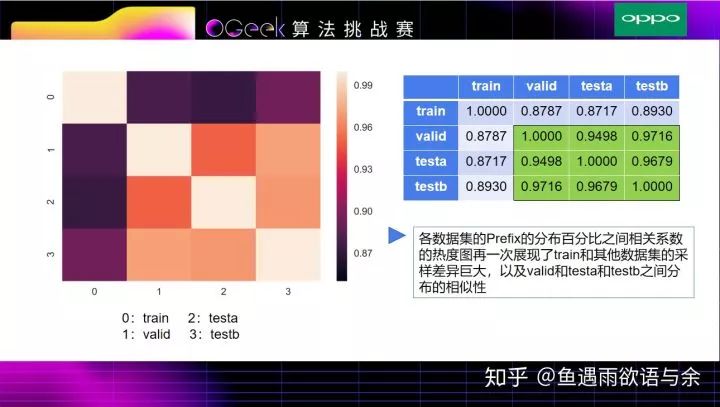
此处更近一步分析了train和testa、testb有较大的差异性。

我们对数据特点进行了分析。发现,
1.用户有可能会拼错prefix,如‘抖音’拼写成‘枓音’,分析发现,使用prefix的pinying会比中文大幅度减少不同值的出现次数,当然也有一部分不是拼写错误的,如痘印,所以最后我们中文和拼音的两部分特征都使用了。
2.由于这是实时性比较强的搜索场景,分析发现,测试集中会有很大一部分prefix和title未在训练集中出现过。
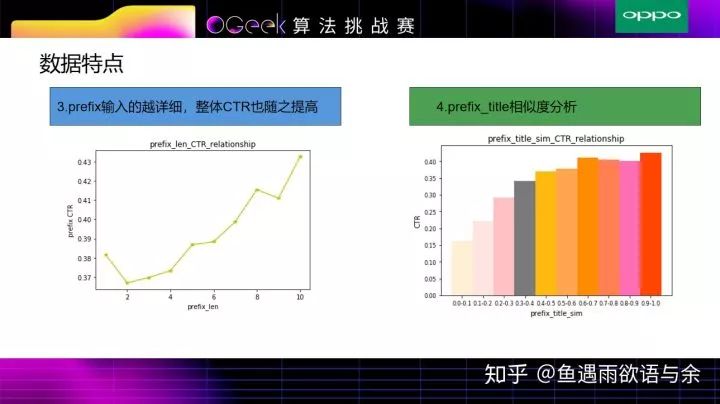
除基础数据分析外,我们还分析了部分特征,比如prefix的长度特征,其用户输入prefix越详细,整体CTR也随之提高,其他特征的长度也有类似的趋势。
另外,相似度特征是非常重要的特征,prefix和title越相似度,点击的可能就越高。
3. 赛题难点
经过上面的分析以及对业务的理解,本赛题有什么难点呢?对此我们总结了五点:
没有用户/没有时间的信息,因此无法对用户建模,对于同一个query,不同人不同时间段都会有不同的反应。
实事热点转移快,训练集中点击率高的,测试集中不一定高。
训练集和测试集的分布不是单纯的按照时间,因为一些明显的热搜词训练集中没有,但是验证集和测试集里面大量存在。这显然不合理的,所以我们认为,主办方数据抽样的时候,过滤了该词语。
因为是实时性比较强的搜索场景,因此面对新出现的title如何处理?由于同样的query-title,最终都会被模型预测成相同的标签,模型对于高频新词的点击率均值的把握,成为了关键点。
用户的明显拼写错误query,例如刘览器这种如何处理?
4. 特征工程


这里对CountVector的特征构造进行展示,CountVector特征在复赛提升也是非常大的。
# CountVectorizer
data = data_df[['prefix', 'query_prediction', 'title', 'label']]
data.replace('nan',np.nan,inplace=True)
data['query_prediction'].fillna('{}',inplace=True)
data['title'].fillna('-1',inplace=True)
# prefix,title,query_prediction jieba分词
def get_cv_feature(dt):
df = pd.DataFrame()
for item in ['prefix', 'title']:
print(item)
stat = pd.DataFrame()
stat[item] = dt[item].drop_duplicates().values
stat[item+'_jieba'] = stat[item].apply(lambda x:' '.join(jieba.cut(str(x), cut_all=False)))
df[item+'_jieba'] = pd.merge(dt,stat,how='left',on=item)[item+'_jieba']
stat = pd.DataFrame()
item = 'query_prediction'
print(item)
stat[item] = dt[item].drop_duplicates().values
def getFeature(x):
dct = json.loads(x)
lst = []
for k in dct.keys():
lst.extend(jieba.cut(k,cut_all=False))
return ' '.join(lst)
stat['query_prediction_jieba'] = stat['query_prediction'].apply(getFeature)
df[item+'_jieba'] = pd.merge(dt,stat,how='left',on=item)[item+'_jieba']
return df
df = get_cv_feature(data)
from sklearn.feature_extraction.text import CountVectorizer
from scipy import sparse
cntv=CountVectorizer()
data['label'] = data['label'].astype(int)
vector_feature = ['prefix_jieba','query_prediction_jieba','title_jieba']
train_index = data[data['label']>=0].index.tolist()
test_index = data[data['label']==-1].index.tolist()
train_sp = pd.DataFrame()
test_sp = pd.DataFrame()
for feature in vector_feature:
print(feature)
cntv.fit(df[feature])
train_sp = sparse.hstack((train_sp,cntv.transform(df.loc[train_index][feature]))).tocsr()
test_sp = sparse.hstack((test_sp,cntv.transform(df.loc[test_index][feature]))).tocsr()
print(train_sp.shape)
print(test_sp.shape)
相似度特征:prefix,title分别构造与query_prediction中每个key的相似度),并统计max,std,mean相似度。更进一步,统计top3,top5相似度的max,std,mean。
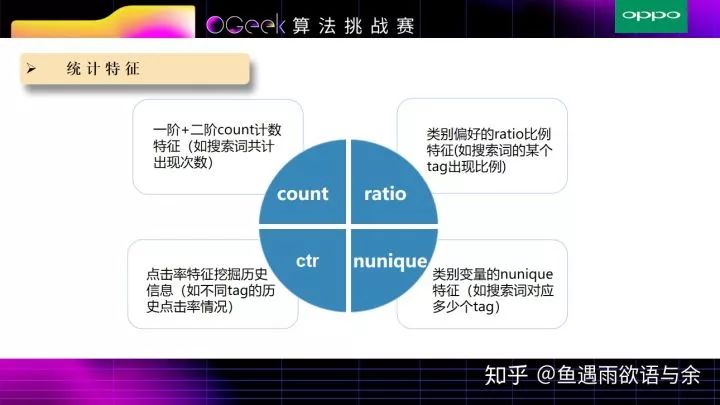
这些也是CTR问题传统特征,同时对于这些特征的构造也是直接照办之前的开源
鱼遇雨欲语与余:2018腾讯广告算法大赛总结/0.772229/Rank11
链接:https://zhuanlan.zhihu.com/p/38034501

由于赛题的特殊性,给了我们验证集,通过观察训练集和验证集的数据,我们发现存在热点转移的情况,例如关于某个明星,title 1是高热点转换网页,可是到了验证集中,这位明星的高热点title是另外的一些网页,说明实时热点性比较强。因此我们对CTR的使用方法进行如下调研。
我们这边采用了多种方式来防止过拟合,分别是多折交叉提取特征,平滑,以及采样。
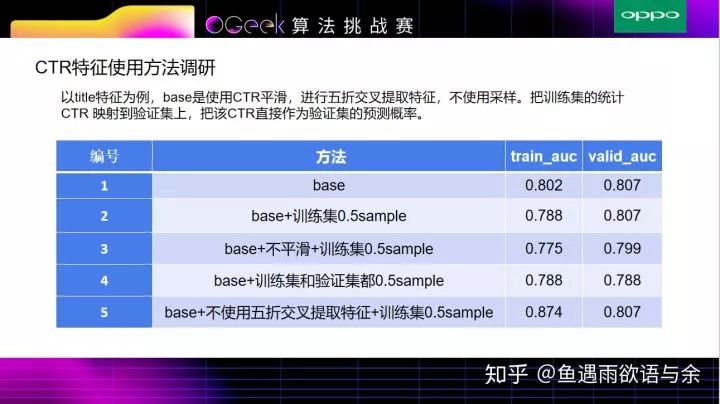
从表格中(5)可以看出,不使用五折交叉提取特征,训练集的auc比验证集的auc高很多,这就非常容易过拟合,导致线上结果很差,
(2)->(3)的过程就是相差了一个平滑,从而导致训练集和验证集上的auc都有所下降;此外,在我们的方法中加入了0.5的采样,是为了使得训练集和验证集结果都不会过拟合。
上表(4)所示,对训练集和验证集均加入0.5的采样之后,训练集和验证集的auc都会有所降低,当然对非常近的数据可能不利,但是对训练集和测试集相隔比较远的数据,随热点的转移,CTR也会有所改善。
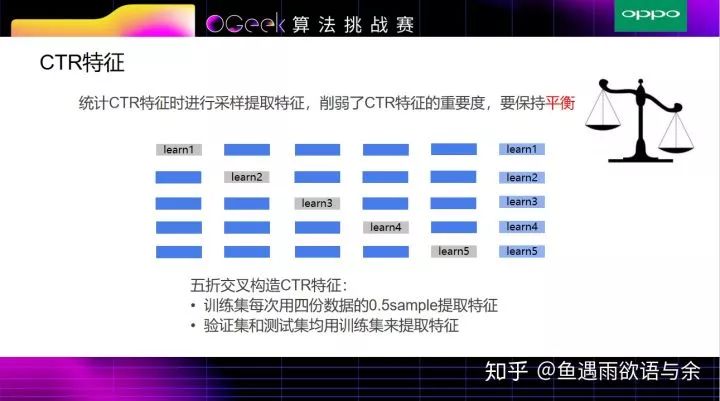
经过调研,我们使用0.5sample构造CTR特征,主要目的是目的是为了削弱ctr的特征重要度。
5. 算法模型
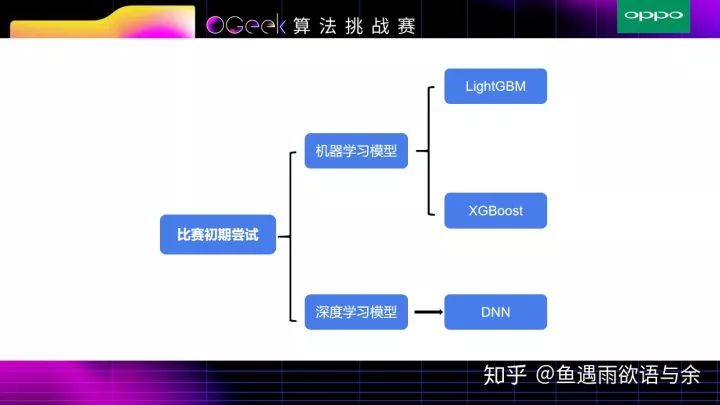
对于此次比赛我们对传统机器学习模型以及深度模型都进行了尝试。
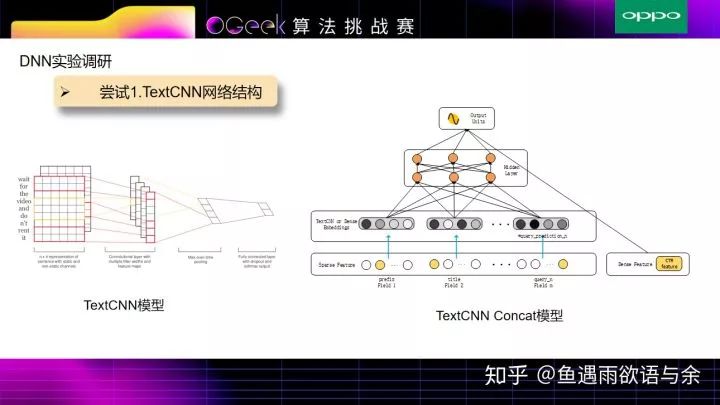
TextCNN是经典的文本特征提取网络,TextCNN Concat模型 输入是tag,prefix,title,query_prediction(query_prediction对其进行拆分成10条,查询词为文本,查询词概率为权重)+特征工程中的统计特征, 接着将所有基础的文本特征通过TextCNN来提取,非文本特征通过全连接层来提取,上述几部分结合作为最终的特征层。由于模型过于简单,并没有特征之间(title,prefix)的深层次关联,导致效果很一般。
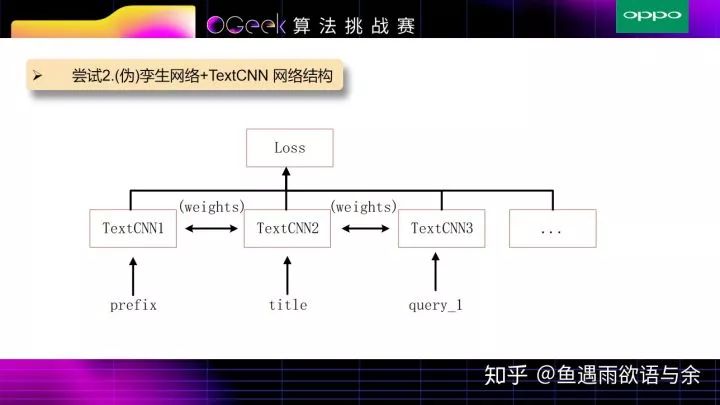
因为只用TextCNN结构的网络缺少prefix和title之间相似度的衡量,所以另外加了孪生网络或伪孪生网络来度量prefix和title之间相似度,以及prefix和query,title和query之间的相似度,并同样加入统计概率作为权重
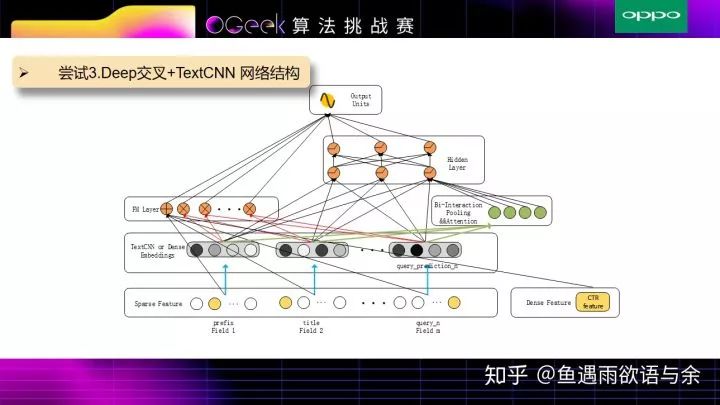
实验结果发现,由于prefix和title的长度有一些差别,反而用伪孪生网络比孪生网络取得了更好一些的效果,所以在上述模型中,prefix,title和query_prediction中并没有用共享权值(伪孪生网络)。该模型结合了TextCNN,DeepFM,AFM等相关操作。
具体流程如下:输入分为两部分,对于prefix,title和query_prediction进行TextCNN操作提取文本特征,tag和统计特征通过全连接层获取对应的Embedding特征。
接着一部分是DeepFM模型,来获取浅层特征和交叉特征,其中query_prediction的统计概率作为query文本向量的权重。
另外一部分是AFM相关操作,就是Bi-Interaction Pooling && Attention,对每两两Field的文本特征向量进行交叉,由于不同文本向量交叉的特征重要性不同,所以此处加入Attention,简单来说就是对不同文本向量交叉的特征加权平均得到向量再放入Deep层进行更深层次的训练。
主要进行了以上几种深度学习模型,经过试验对比,尝试3能取得最好的效果,但由于数据量不是特别大,并没有取得比LightGBM模型更好的效果,虽然该模型与LightGBM模型融合有所提高,但是作为NN模型在200万规模的数据集上稳定性不够强,结果值会产生一定的波动,且模型受限于2个,所以最终提交的成绩并没有使用该模型。
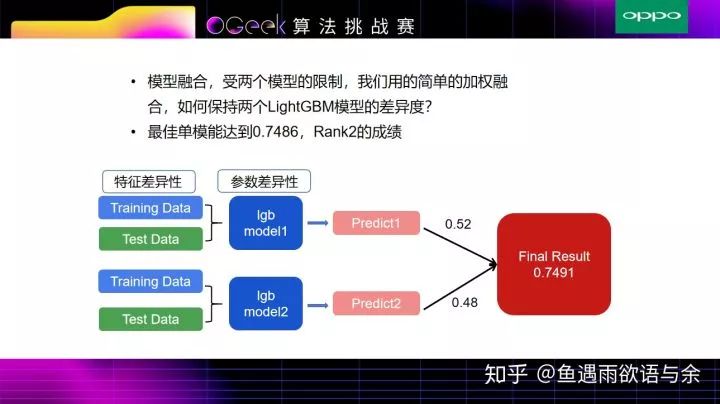
我们最终融合方案也比较简单,主要进行加权融合,权重的确定看的是线下分数。
6. 思考总结

优点:
能够对数据和业务经过细致的分析,挖掘更深层次的特征,更好的描述实体关系。
在模型方面仅使用稳定性比较高的LightGBM,并且具有很好的解释性。
从特征提取到模型训练仅使用三个小时完成,可以更高效的生成结果。
单模型取得top2的成绩,从特征提取到模型训练可以短时间完成。
不足:
为了保证模型的泛化性没有对特征集合进行精细选择,从而损失一定的准确性。
没有构造出较大差异性的第二模型,导致最终成绩在单模0.7486的成绩上未能
获得很大的提升。
欢迎指正与交流,有问题直接加作者qq418811687。
Github链接:
https://github.com/fanfanda/OGeek-Competition
可以“阅读原文”进入作者知乎查看。

这篇关于搜索推荐算法挑战赛OGeek-完整方案及代码(亚军)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





