本文主要是介绍2021_ICCV_Gradient Distribution Alignment Certificates Better Adversarial Domain Adaptation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
处理无监督领域适应任务中领域迁移的最新启发式方法是使用对抗学习减少数据分布差异。最近的研究通过将分类器的输出集成到分布散度度量中,改进了传统的具有判别信息的对抗域适应方法。然而,他们仍然遭受着对抗学习的均衡问题,即使判别器完全混淆,也无法保证两个分布之间有足够的相似性。为了克服这个问题,我们提出了一种新的特征梯度分布对齐方法( FGDA ) ( 1 )。我们从理论和实证两方面论证了我们方法的合理性。特别地,我们表明通过约束两个域的特征梯度具有相似的分布,可以减少分布差异。同时,我们的方法在理论上保证了可以获得比传统对抗域自适应方法更紧的目标样本误差上界。通过将所提出的方法与现有的对抗域适应模型集成,我们在两个真实的基准数据集上实现了最先进的性能。
1. Introduction
深度神经网络( Deep Neural Networks,DNNs )在图像分类[ 12、16]、目标检测[ 11、26]和语义分割[ 21、24]等各种应用中取得了令人印象深刻的性能。然而,由于数据分布偏移问题表现在许多不同的方面,如样本选择偏差[ 5 ]、类分布偏移[ 19 ]、协变量偏移[ 29 ]等,DNNs可能无法很好地对新数据进行泛化。无监督领域适应( UDA )旨在通过访问有标签的源数据和无标签的目标数据来解决领域迁移问题[ 8 ]。基本目标是推断领域不变的表示[ 32 ]。
在当前的深度架构中,对抗域自适应( ADA )方法[ 25、22、30、15]被广泛研究,并取得了最先进的性能。领域对抗神经网络( Domain-Adversarial Neural Networks,DANN )作为一项开创性的工作,将对抗学习和领域适应集成到一个极大极小不等式游戏中[ 8 ]。学习一个域判别器来区分源分布和目标分布,而深度分类模型学习对域判别器不可区分的可迁移表示。最近的成功方法表明,区分性分布对齐可以实现更好的域适应[ 25、22、30、15、27、38]。这些研究的核心思想是利用分类器输出或预测提供的判别信息进行目标判别表示学习。
尽管判别信息有助于提升域适应的性能,但我们认为域转换仍然是一个主要的挑战,限制了性能的进一步提升。这样的缺点来自于对抗学习的平衡挑战[ 2 ],即使判别器完全混淆,也不能保证两个分布充分相似,如图1 ( a )和( b )所示。
为了解决这个问题,我们提出了一种称为特征梯度分布对齐( FGDA )的新方法,以进一步减少域偏移。具体来说,FGDA通过特征提取器和判别器之间的对抗学习,学习减少特征梯度在两个域之间的分布差异。当达到均衡时,特征分布差异的值可以最小。
我们借用[ 10、1、37]对对抗扰动的洞察来简单描述所提出方法的原理。样本的输入梯度可以认为是对输入扰动最小的敏感方向,从而最大程度地改变模型的输出[ 1 ]。直觉上,一个样本的特征梯度方向可能倾向于指向其最近决策边界的区域。此外,由于特征梯度指向高度复杂的决策边界(在DNNs中通常可以看到)的不同部分,因此它们之间可能存在显著差异;距离较近的特征梯度可能具有相似的方向。因此,对齐特征梯度鼓励学习执行两个域分布的潜在表示来保持距离。因此,可以减少特征分布差异。由于我们方法的优点,与传统的域适应方法相比,即使两个域的平均特征接近,我们的方法也能进一步减少域偏移,如图1所示,这也在后面的3.7节中进行了理论分析。重要的是,我们进一步证明了对齐特征梯度比传统的对抗域适应方法在目标样本上的期望误差上界更紧。
总之,我们的主要贡献如下:
- 我们提出了一种新的方法FGDA,使用对抗学习来对齐特征梯度,以减少分布差异。与传统方法相比,即使源和目标分布的均值接近,我们的模型也能进一步减小域偏移。
- 我们从理论和实证两个方面证明了我们方法的有效性。特别地,我们证明了我们的方法可以获得比传统的域适应方法更紧的上界。
- 我们进行了大量的实验,以表明所提出的方法不仅能够减少域差异,而且与当前基于特征的对抗域适应方法相比,具有一致的改进。特别地,我们的方法在UDA任务上取得了最先进的性能。
2.Related Work
对抗域自适应( ADA )方法[ 7、34、35]不仅提供了理论保证,而且取得了最先进的性能,最近被广泛研究。受生成式对抗网络( Generative Adversarial Networks,GANs ) [ 9 ]的启发,这些方法在极大极小不等式游戏中学习一个域不变的特征,其中一个特征提取器学习欺骗一个域判别器,而判别器则努力不被欺骗[ 8 ]。与这些特征级方法相比,生成式像素级自适应模型在原始像素空间中执行分布对齐,通过使用图像到图像的转换技术[ 40、20、14、28]将源数据转换到目标域。
尽管它们对从分类[ 7、35、20]到分割[ 28、33、14]的各种任务具有普遍的有效性,但它们不得不面对对抗学习的平衡问题[ 2 ]。因此,当数据分布中存在复杂的多模态结构时,香草ADA方法可能无法捕获这些多模态结构,从而实现无模式失配的分布判别比对[ 22 ]。
为了进一步减少域偏移,最近成功的ADA方法致力于实现区分性分布对齐。其中一种被广泛研究的方法被命名为类条件ADA,它将领域分类器对特征和相应的预测同时进行[ 25、22、30、15]。这些方法旨在近似两个域之间的联合分布对齐,以实现具有判别性的目标特征。另一类ADA研究依靠两个分类器来衡量两个领域的分布差异。利用两个分类器预测的不一致来检测不明确属于某个类别的非鉴别特征。通过与特征提取器进行极大极小不等式博弈,两个分类器优化决策边界以缓解类内领域差异[ 27、38]。
尽管上述努力促进了更好的分布对齐,但对抗训练不可避免的平衡挑战仍然限制了当前ADA方法的性能。为了缓解这一问题,我们在这一研究方向上更进一步,提出了一种特征梯度分布对齐方法,该方法可以在理论上更严格的误差上界下进一步减少分布差异。注意到一个并行工作[ 6 ]与我们的想法不谋而合,并研究了类似的方法。我们独立地利用梯度对齐,但从不同的角度和不同的理论分析。
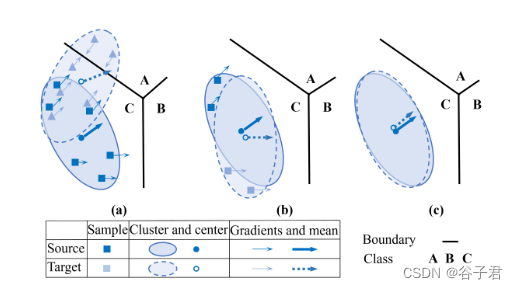
见图1。特征梯度分布对齐( Fgda )示意图。( a ) - ( c ):当两个域的特征因域偏移较大而分布差异较大时,它们在非重叠区域的梯度可能分散在高度复杂的决策边界的不同部分,从而导致较大的梯度分布差异。通过梯度对齐,扩大重叠区域以减少域偏移。( a ) ~ ( b ):当两个均值特征足够接近时,传统对抗域适应方法测量的域偏移趋于零。在这种情况下,常规方法无法进一步减小域偏移。( b ) - ( c ):即使两个均值特征之间的距离较小,由于非重叠区域的梯度明显不同,我们的方法(在特征梯度差异方面)度量的域偏移仍然可以被观察到。FGDA可以证明进一步的域移减少。
3. Methodology
3.1. Preliminaries
对于香草无监督域适应( UDA )任务,给定源域 D s \mathcal{D}_s Ds中 n s n_s ns 个标记样本 { ( x i s , y i s ) } i = 1 n s \left\{\left(x_i^s, y_i^s\right)\right\}_{i=1}^{n_s} {(xis,yis)}i=1ns ,其中 x i s ∈ X s , y i s ∈ Y s x_i^s \in \mathcal{X}_s, y_i^s \in \mathcal{Y}_s xis∈Xs,yis∈Ys和目标域 D t \mathcal{D}_t Dt中 n t n_t nt 个未标记样本 { x j t } j = 1 n t \left\{x_j^t\right\}_{j=1}^{n_t} {xjt}j=1nt ,其中 x j t ∈ X t x_j^t \in \mathcal{X}_t xjt∈Xt。UDA的目标是学习一个分类模型来预测目标域标签 { y j t } j = 1 n t \left\{y_j^t\right\}_{j=1}^{n_t} {yjt}j=1nt ,其中 y j t ∈ Y t y_j^t \in \mathcal{Y}_t yjt∈Yt。整个分类模型由特征提取器 G ( ⋅ ) G(\cdot) G(⋅)和任务分类器 C ( ⋅ ) C(\cdot) C(⋅)组成,期望能够保证分类准则 L ( ⋅ , ⋅ ) \mathcal{L}(\cdot, \cdot) L(⋅,⋅)具有较低的目标风险 E ( x t , y t ) ∼ D t [ L ( C ( G ( x t ) ) , y t ) ] \mathbb{E}_{\left(\mathbf{x}^t, y^t\right) \sim \mathcal{D}_t}\left[\mathcal{L}\left(C\left(G\left(\mathbf{x}^t\right)\right), y^t\right)\right] E(xt,yt)∼Dt[L(C(G(xt)),yt)]。
特征提取器 G ( ⋅ ) G(\cdot) G(⋅)通过 x s \boldsymbol{x}^s xs and x t \boldsymbol{x}^t xt 将 x s \boldsymbol{x}^s xs and x t \boldsymbol{x}^t xt编码到一个公共特征空间,其中 G ( ⋅ ) G(\cdot) G(⋅)可以是任意类型的神经网络, f s , f t ∈ R D f^s, f^t \in \mathbb{R}^D fs,ft∈RD表示源域和目标域的D维特征向量。对于 K K K-way分类任务,将 f s f^s fs and f t f^t ft 送入任务分类器进行预测 z s = C ( f s ) , z t = C ( f t ) \boldsymbol{z}^s=C\left(f^s\right), \boldsymbol{z}^t=C\left(f^t\right) zs=C(fs),zt=C(ft),其中 z s , z t ∈ R k \boldsymbol{z}^s, \boldsymbol{z}^t \in \mathbb{R}^k zs,zt∈Rk 为得分向量。利用源域的真实标注数据,通过最小化标准交叉熵损失来训练分类模型:
L s r c = − E x s ∈ X s , y s ∈ Y s ∑ k = 1 K q k log δ k ( z s ) \mathcal{L}_{\mathrm{src}}=-\mathbb{E}_{\boldsymbol{x}^s \in \mathcal{X}_s, y^s \in \mathcal{Y}_s} \sum_{k=1}^K q_k \log \delta_k\left(z^s\right) Lsrc=−Exs∈Xs,ys∈Ysk=1∑Kqklogδk(zs)
其中 δ k ( z s ) = exp ( z k s ) ∑ l exp ( z l s ) \delta_k\left(z^s\right)=\frac{\exp \left(z_k^s\right)}{\sum_l \exp \left(z_l^s\right)} δk(zs)=∑lexp(zls)exp(zks) 表示向量 z s z^s zs的softmax输出中的第k个元素, q q q是 y s y^s ys 的one-of K K K编码,其中 q k q_k qk对正确类是’ 1 ‘,其余类是’ 0 '。目标是预测目标样本的标签,记为 y ^ t = argmax k ( δ ( z k t ) ) \hat{y}^t=\operatorname{argmax}_k\left(\delta\left(z_k^t\right)\right) y^t=argmaxk(δ(zkt)).
3.2. Framework Overview
我们提出了一个称为特征梯度分布对齐( FGDA )的框架来减少域偏移,如图2所示。我们的核心部分是对抗学习的一部分,用于对齐特征提取器和梯度判别器相互竞争的两个域的特征梯度分布。为了进一步推广我们提出的方法,我们提出了Jacobian正则化项 ∥ J ( f s ) ∥ F 2 \left\|J\left(f^s\right)\right\|_F^2 ∥J(fs)∥F2和自监督伪标记机制,分别用于提高模型泛化性和伪标记质量。此外,我们将说明如何将我们的方法部署在传统的ADA方法上,例如。DANN [ 8 ]、CDAN [ 22 ]和MDD [ 38 ],进一步缩小分布差异。
3.3. Feature Gradient Distribution Alignment
为了获得两个域的特征梯度,我们需要计算目标样本的损失。在训练阶段,利用分类模型的预测结果 y ^ t \hat{y}^t y^t作为在线伪标注计算目标样本的损失 L tgt ( C ( G ( x t ) ) , y ^ t ) \mathcal{L}_{\text {tgt }}\left(C\left(G\left(\mathrm{x}^t\right)\right), \hat{y}^t\right) Ltgt (C(G(xt)),y^t)。
注意到目标域中的损失只用于梯度计算而不是训练整个分类模型。通过反向传播机制,源域和目标域的特征梯度向量可以计算为:
g ( x s , G ) : = [ ∂ L s r c ∂ G ( x s ) 1 ⋯ ∂ L s r c ∂ G ( x s ) d ⋯ ∂ L s r c ∂ G ( x s ) D ] \boldsymbol{g}\left(x^s, G\right):=\left[\frac{\partial \mathcal{L}_{\mathrm{src}}}{\partial G\left(x^s\right)_1} \cdots \frac{\partial \mathcal{L}_{\mathrm{src}}}{\partial G\left(x^s\right)_d} \cdots \frac{\partial \mathcal{L}_{\mathrm{src}}}{\partial G\left(x^s\right)_D}\right] g(xs,G):=[∂G(xs)1∂Lsrc⋯∂G(xs)d∂Lsrc⋯∂G(xs)D∂Lsrc]
g ( x t , G ) : = [ ∂ L t g t ∂ G ( x t ) 1 ⋯ ∂ L t g t ∂ G ( x t ) d ⋯ ∂ L t g t ∂ G ( x t ) D ] g\left(x^t, G\right):=\left[\frac{\partial \mathcal{L}_{\mathrm{tgt}}}{\partial G\left(x^t\right)_1} \cdots \frac{\partial \mathcal{L}_{\mathrm{tgt}}}{\partial G\left(x^t\right)_d} \cdots \frac{\partial \mathcal{L}_{\mathrm{tgt}}}{\partial G\left(x^t\right)_D}\right] g(xt,G):=[∂G(xt)1∂Ltgt⋯∂G(xt)d∂Ltgt⋯∂G(xt)D∂Ltgt]
其中 G ( x s ) d G\left(x^s\right)_d G(xs)d 和 G ( x t ) d G\left(x^t\right)_d G(xt)d 表示特征向量(为方便起见,使用 f d s f_d^s fds and f d t f_d^t fdt 的第d个元素, g ( x s , G ) \boldsymbol{g}\left(x^s, G\right) g(xs,G) and g ( x t , G ) \boldsymbol{g}\left(x^t, G\right) g(xt,G) 表示对应的梯度向量(为了方便使用 g s g^s gs and g t g^t gt )。
为了实现梯度分布对齐的目标,采用了特征提取器和判别器(作为散度估计量)相互竞争的对抗学习。具体来说,判别器是预测源域和目标域特征梯度的域标签,而特征提取器则学习混淆判别器。当达到均衡时,特征分布差异达到最小值。
我们提出的方法中特征梯度对齐的主要目标可以表述为:
min G max D g L a d v = E x t ∈ X t [ log D g ( g ( x t , G ) ) ] + E x s ∈ X s [ log ( 1 − D g ( g ( x s , G ) ) ) ] \begin{aligned} \min _G \max _{D_g} \mathcal{L}_{a d v} & =\mathbb{E}_{\boldsymbol{x}^t \in X^t}\left[\log D_g\left(g\left(\boldsymbol{x}^t, G\right)\right)\right] \\ & +\mathbb{E}_{\boldsymbol{x}^s \in X^s}\left[\log \left(1-D_g\left(g\left(\boldsymbol{x}^s, G\right)\right)\right)\right] \end{aligned} GminDgmaxLadv=Ext∈Xt[logDg(g(xt,G))]+Exs∈Xs[log(1−Dg(g(xs,G)))]
其中 D g ( ⋅ ) D_g(\cdot) Dg(⋅) 是判别器,它输出梯度向量来自目标域的概率。
所提方法的原理如图3所示。最初,由于较大的域偏移,来自不同域的两组点分布差异很大,特征梯度指向高维空间中高度复杂的决策边界的不同部分。因此,两个域的大部分特征梯度明显不同,导致特征梯度分布差异较大。通常情况下,距离较近或较小区域内的特征具有相似的梯度。因此,梯度对齐可以迫使这两组点相互移动并停留在梯度相近的小区域,如图3中的红色虚线圆。换句话说,可以减少域偏移。为了进一步说明域偏移会导致较大的特征梯度差异,我们在图3中进行了分析,其中绘制了每个类在两个域之间的平均梯度距离(注意正常化)
相比之下,对于传统的基于特征的ADA方法,如图1所示,域偏移由判别器 D g : D_g: Dg:衡量: = ∣ E f ∼ D S ~ D g ( f ) − =\mid E_{\boldsymbol{f} \sim \tilde{D_{\mathcal{S}}}} D_g(f)- =∣Ef∼DS~Dg(f)− E f ∼ D T D g ( f ) ∣ E_{\boldsymbol{f} \sim \mathcal{D}_{\mathcal{T}}} D_g(\boldsymbol{f}) \mid Ef∼DTDg(f)∣,其中’ D ~ S \tilde{\mathcal{D}}_{\mathcal{S}} D~S和 D ~ T \tilde{\mathcal{D}}_{\mathcal{T}} D~T 为 D s \mathcal{D}_s Ds 和 D t \mathcal{D}_t Dt在特征空间的诱导分布。存在常数 α \alpha α使得 d i s = α ∣ D g ( E f ∼ D S ‾ f ) − D g ( E f ∼ D T f ) ∣ d i s=\alpha\left|D_g\left(E_{\boldsymbol{f} \sim \overline{\mathcal{D}_{\mathcal{S}}}} f\right)-D_g\left(E_{\boldsymbol{f} \sim \mathcal{D}_{\mathcal{T}}} f\right)\right| dis=α Dg(Ef∼DSf)−Dg(Ef∼DTf) 。当平均特征 E f ∼ D S ‾ f E_{f \sim \overline{\mathcal{D}_{\mathcal{S}}}} f Ef∼DSf 和 E f ∼ D T ‾ f E_{f \sim \overline{D_{\mathcal{T}}}} f Ef∼DTf 接近时,传统方法测量的域偏移dis趋于零,从而反向传播到特征提取器的相应梯度趋于零。因此,不能进一步减小畴移。与之不同的是,我们的方法中,区域位移由dis = ∣ E f ∈ D S ~ D g ( ∇ f L ) − E f ∈ D T ~ D g ( ∇ f L ) ∣ =\left|E_{\boldsymbol{f} \in \tilde{\mathcal{D}_{\mathcal{S}}}} D_g\left(\nabla_{\boldsymbol{f}} \mathcal{L}\right)-E_{\boldsymbol{f} \in \tilde{\mathcal{D}_{\mathcal{T}}}} D_g\left(\nabla_f \mathcal{L}\right)\right| = Ef∈DS~Dg(∇fL)−Ef∈DT~Dg(∇fL) 来度量。类似地,存在常数 β \beta β使得dis our = = = β ∣ D g ( E f ∼ D S ~ ∇ f L ) − D g ( E f ∼ D T ~ ∇ f L ) ∣ \beta\left|D_g\left(E_{\boldsymbol{f} \sim \tilde{\mathcal{D}_{\mathcal{S}}}} \nabla_{\boldsymbol{f}} \mathcal{L}\right)-D_g\left(E_{\boldsymbol{f} \sim \tilde{\mathcal{D}_{\mathcal{T}}}} \nabla_{\boldsymbol{f}} \mathcal{L}\right)\right| β Dg(Ef∼DS~∇fL)−Dg(Ef∼DT~∇fL) .根据图1,即使两个均值特征之间的距离很小,由于非重叠区域存在明显的不同梯度,我们的方法 d i s our d i s_{\text {our }} disour 测量的域偏移仍然可以很大。因此,域偏移可以进一步减小。
定义投入产出雅克比矩阵为:
J k ; d ( f s ) ≡ ∂ z k ∂ f d s ( f s ) J_{k ; d}\left(f^s\right) \equiv \frac{\partial z_k}{\partial f_d^s}\left(f^s\right) Jk;d(fs)≡∂fds∂zk(fs)
其中 z k s z_k^s zks和 f d s f_d^s fds 分别表示特征 f s f^s fs在源域的第k个评分值 z s z^s zs和d个元素。则雅克比正则化定义为:
min G , C L j r = ∥ J ( f s ) ∥ F 2 ≡ { ∑ d , k [ J k ; d ( f s ) ] 2 } \min _{G, C} L_{j r}=\left\|J\left(f^s\right)\right\|_{\mathrm{F}}^2 \equiv\left\{\sum_{d, k}\left[J_{k ; d}\left(f^s\right)\right]^2\right\} G,CminLjr=∥J(fs)∥F2≡⎩ ⎨ ⎧d,k∑[Jk;d(fs)]2⎭ ⎬ ⎫
3.4. Feature-level Jacobian Regularization
多项工作表明,判别性特征有助于提高分布对齐[ 30、27、35]的性能。为了学习更具判别性的特征,本文采用梯度正则化方法最大化分类间隔[ 23、13]。为此,Hoffman等人提出了最小化输入输出梯度矩阵的范数,称为Jacobian矩阵[ 13 ]。类似地,我们在特征层面采用Jacobian正则化,使得特征提取器能够学习到更多远离决策边界的判别性特征,同时分类器能够扩大分类边界。
3.5. Self-supervised Pseudo-labeling
尽管使用模型预测的在线伪标注进行梯度对齐是可行的,但是错误的预测会产生次优的梯度分布,从而阻碍梯度对齐达到最优的性能。
为了在目标域中获得高质量的伪标注,我们将一种无监督的方法集成到我们的框架中,捕获不同类的目标分布,称为自监督伪标记[ 18 ]。在初始训练阶段结束后,对每一个固定的迭代次数执行该策略,生成离线伪标签集合 Y ~ t \widetilde{\mathcal{Y}}_t Y t (利用特征质心预测当前样本的离线伪标注)。一旦得到离线的伪标注,则 y ~ t ∈ Y ~ t \tilde{y}_t \in \widetilde{\mathcal{Y}}_t y~t∈Y t将代替在线的伪标签(在线伪标注是用分类器对当前样本进行预测) ( y ^ t \hat{y}_t y^t )对每个目标样本进行特征梯度计算。
每个类的特征分布的质心也被认为是一个原型表示,其分布应该出现在分类器自信地预测大量样本的区域。质心的更新类似于k - means聚类,通过分类器的置信度对每个目标特征进行加权:
c k ( 0 ) = ∑ x t ∈ X t δ k ( C ~ ( G ~ ( x t ) ) ) G ~ ( x t ) ∑ x t ∈ X t δ k ( C ~ ( G ~ ( x t ) ) ) \boldsymbol{c}_k^{(0)}=\frac{\sum_{\boldsymbol{x}^t \in \mathcal{X}_t} \delta_k\left(\tilde{C}\left(\tilde{G}\left(\boldsymbol{x}^t\right)\right)\right) \tilde{G}\left(\boldsymbol{x}^t\right)}{\sum_{\boldsymbol{x}^t \in \mathcal{X}_t} \delta_k\left(\tilde{C}\left(\tilde{G}\left(\boldsymbol{x}^t\right)\right)\right)} ck(0)=∑xt∈Xtδk(C~(G~(xt)))∑xt∈Xtδk(C~(G~(xt)))G~(xt)
其中, G ~ ( ⋅ ) \tilde{G}(\cdot) G~(⋅) 和 C ~ ( ⋅ ) \tilde{C}(\cdot) C~(⋅) 在上一次迭代中已经过训练,用于在线预测伪标注。每个目标样本的离线伪标签被赋予最近质心的标签:
y ~ t = arg min k M f ( G ~ ( x t ) , c k ( 0 ) ) \tilde{y}^t=\arg \min _k M_f\left(\tilde{G}\left(x_t\right), c_k^{(0)}\right) y~t=argkminMf(G~(xt),ck(0))
式中: M f ( a , b ) M_f(a, b) Mf(a,b) 为 a a a 和 b b b之间的余弦距离度量。最后,根据新的伪标签确定类别质心:
c k ( 1 ) = ∑ x t ∈ X t I ( y ~ t = k ) G ~ ( x t ) ∑ x t ∈ X t I ( y ~ t = k ) , y ~ t = arg min k M f ( G ~ ( x t ) , c k ( 1 ) ) , \begin{aligned} c_k^{(1)} & =\frac{\sum_{\boldsymbol{x}^t \in \mathcal{X}_t} \mathbb{I}\left(\tilde{y}^t=k\right) \tilde{G}\left(\boldsymbol{x}_t\right)}{\sum_{\boldsymbol{x}^t \in \mathcal{X}_t} \mathbb{I}\left(\tilde{y}^t=k\right)}, \\ \tilde{y}^t & =\arg \min _k M_f\left(\tilde{G}\left(\boldsymbol{x}^t\right), \boldsymbol{c}_k^{(1)}\right), \end{aligned} ck(1)y~t=∑xt∈XtI(y~t=k)∑xt∈XtI(y~t=k)G~(xt),=argkminMf(G~(xt),ck(1)),
式中: I \mathbb{I} I 为二元指示函数。当 y ~ l = k \tilde{y}^l=k y~l=k时,函数输出1。式中:9时,类质心和伪标注交替更新多轮。实际观测到,即使这些参数更新一次,仍然可以提高伪标注的质量。
3.6. Overall Learning Objective
为了总结前面的成分,我们在下面给出了总的训练损失。在初始训练阶段,采用特征梯度分布对齐和特征级Jacobian正则化对模型进行训练。相应的目标可以表述为:
min G , C max D g ( L src + λ 1 L a d v + λ 2 L j r ) , \min _{G, C} \max _{D_g}\left(\mathcal{L}_{\text {src }}+\lambda_1 \mathcal{L}_{a d v}+\lambda_2 \mathcal{L}_{j r}\right), G,CminDgmax(Lsrc +λ1Ladv+λ2Ljr),
其中 λ 1 , λ 2 ≥ 0 \lambda_1, \lambda_2 \geq 0 λ1,λ2≥0是两个平衡参数.首先利用在线伪标注( y ^ t \hat{y}^t y^t 计算目标样本的特征梯度 g t \mathbf{g}^t gt,得到式( 1 )的 L a d v \mathcal{L}_{a d v} Ladv。4 .经过固定次数的迭代后,自监督伪标记参与训练。然后将 L a d v \mathcal{L}_{a d v} Ladv改为 L ~ a d v \tilde{\mathcal{L}}_{a d v} L~adv,其中 g t \mathbf{g}^t gt 由离线伪标注 y ~ t \tilde{y}^t y~t 和 L tgt ( ⋅ , y ~ t ) \mathcal{L}_{\text {tgt }}\left(\cdot, \tilde{y}^t\right) Ltgt (⋅,y~t)给出。综上,完全损失为:
min G , C max D g L F G D Λ = L s r c + λ 1 L ~ a d v + λ 2 L j r . \min _{G, C} \max _{D_g} \mathcal{L}_{F G D \Lambda}=\mathcal{L}_{\mathrm{src}}+\lambda_1 \tilde{\mathcal{L}}_{a d v}+\lambda_2 \mathcal{L}_{j r} . G,CminDgmaxLFGDΛ=Lsrc+λ1L~adv+λ2Ljr.
为了展示我们方法的优势,我们将FGDA与一些传统的基于特征的ADA方法,如DANN [ 8 ],CDAN [ 22 ]和MDD [ 38 ] )相结合。组合的简单方法是直接添加一个梯度判别器并重用它们的结构。综合训练损失为:
L F G D A + fada = L s r c + λ 1 L ~ a d v + λ 2 L j r + λ 3 L fada \mathcal{L}_{F G D A+\text { fada }}=\mathcal{L}_{\mathrm{src}}+\lambda_1 \tilde{\mathcal{L}}_{a d v}+\lambda_2 \mathcal{L}_{j r}+\lambda_3 \mathcal{L}_{\text {fada }} LFGDA+ fada =Lsrc+λ1L~adv+λ2Ljr+λ3Lfada
其中 L fada \mathcal{L}_{\text {fada }} Lfada 是基于特征的ADA模型的对抗损失, λ 3 \lambda_3 λ3是其平衡参数。
3.7. Model Analysis
在这一部分,我们对提出的FGDA方法进行了理论和实证分析。首先考虑特征 f = G ( x ) f=G(x) f=G(x) 和一族源分类器 C C C分别在固定的表示空间 F \mathcal{F} F和假设空间 H \mathcal{H} H上。假设C∈H在源域上的误差为 ϵ S ( C ) = E f ∼ D S ~ [ C ( f ) ≠ y ] \epsilon_S(C)=\mathrm{E}_{\boldsymbol{f} \sim \tilde{\mathcal{D}_S}}[C(\boldsymbol{f}) \neq y] ϵS(C)=Ef∼DS~[C(f)=y],其中 D ~ S \tilde{\mathcal{D}}_S D~S 表示源数据分布 D S \mathcal{D}_S DS的诱导特征分布, y y y是特征f的标签。假设 C 1 , C 2 ∈ H C_1, C_2 \in \mathcal{H} C1,C2∈H 之间的分歧由 ϵ S ( C 1 , C 2 ) = E f ∼ D ‾ S [ C 1 ( f ) ≠ C 2 ( f ) ] \epsilon_S\left(C_1, C_2\right)=\mathrm{E}_{\boldsymbol{f} \sim \overline{\mathcal{D}}_S}\left[C_1(\boldsymbol{f}) \neq C_2(\boldsymbol{f})\right] ϵS(C1,C2)=Ef∼DS[C1(f)=C2(f)]给出。为了从未标记数据中估计分布散度,引入了一个理想的联合假设 C ∗ = argmin C ϵ S ( C ) + ϵ T ( C ) C^*=\operatorname{argmin}_C \epsilon_S(C)+\epsilon_T(C) C∗=argminCϵS(C)+ϵT(C)来最小化两个域上的联合误差。然后,给出了目标误差的概率界
ϵ T ( C ) ≤ ϵ S + λ + ∣ ϵ T ( C , C ∗ ) − ϵ S ( C , C ∗ ) ∣ , \epsilon_T(C) \leq \epsilon_S+\lambda+\left|\epsilon_T\left(C, C^*\right)-\epsilon_S\left(C, C^*\right)\right|, ϵT(C)≤ϵS+λ+∣ϵT(C,C∗)−ϵS(C,C∗)∣,
其中 λ = ϵ S ( C ∗ ) + ϵ T ( C ∗ ) \lambda=\epsilon_S\left(C^*\right)+\epsilon_T\left(C^*\right) λ=ϵS(C∗)+ϵT(C∗)是理想联合假设的误差.
为了证明我们提出的方法FGDA的有效性,我们表明我们的方法可以获得比传统的域适应方法更紧的目标域误差上界。主要理论见定理1和定理2。
定理1设 G G G是从 X \mathcal{X} X到 F \mathcal{F} F的固定表示函数, H \mathcal{H} H是VC维 d d d的假设空间.如果将 G G G应用于一个 D s \mathcal{D}_s Ds生成一个大小为 m m m的随机标记样本.特征f取自" D ~ S \tilde{\mathcal{D}}_S D~S or D ~ T \tilde{\mathcal{D}}_T D~T,对应的标签为 y y y。令 U ~ S , U ~ T \tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T U~S,U~T分别表示从 D ~ S \tilde{\mathcal{D}}_S D~S and D ~ T \tilde{\mathcal{D}}_T D~T中抽取的大小为 m ′ m^{\prime} m′的未标记样本集合。则对每个 C ∈ H C \in \mathcal{H} C∈H,至少有 1 − δ 1-\delta 1−δ (在样本的选择上)的概率:
ϵ T ( C ) ≤ ϵ ^ S ( C ) + λ + d ∇ ( U ~ S , U ~ T ) + 4 m ( d log 2 e m d + log 4 δ ) + 4 d log ( 2 m ′ ) + log ( 4 δ ) m ′ = const + d ∇ ( U ~ S , U ~ T ) \begin{aligned} \epsilon_T(C) \leq & \hat{\epsilon}_S(C)+\lambda+d_{\nabla}\left(\tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T\right) \\ & +\frac{4}{m} \sqrt{\left(d \log \frac{2 e m}{d}+\log \frac{4}{\delta}\right)} \\ & +4 \sqrt{\frac{d \log \left(2 m^{\prime}\right)+\log \left(\frac{4}{\delta}\right)}{m^{\prime}}} \\ & =\text { const }+d_{\nabla}\left(\tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T\right) \end{aligned} ϵT(C)≤ϵ^S(C)+λ+d∇(U~S,U~T)+m4(dlogd2em+logδ4)+4m′dlog(2m′)+log(δ4)= const +d∇(U~S,U~T)
其中 ϵ ^ S ( C ) \hat{\epsilon}_S(C) ϵ^S(C)是源样本的经验误差, λ \lambda λ是一个很小的常数, e e e是自然对数的底, d ∇ ( U ~ S , U ~ T ) = d_{\nabla}\left(\tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T\right)= d∇(U~S,U~T)= a sup D g H D ∣ E f ∈ U ~ S D g ( ∇ f L ) − E f ∈ U ~ T D g ( ∇ f L ) ∣ a \sup _{D_g \mathcal{H}_D}\left|E_{\boldsymbol{f} \in \tilde{\mathcal{U}}_{\mathcal{S}}} D_g\left(\nabla_{\boldsymbol{f}} \mathcal{L}\right)-E_{\boldsymbol{f} \in \tilde{\mathcal{U}}_{\mathcal{T}}} D_g\left(\nabla_{\boldsymbol{f}} \mathcal{L}\right)\right| \quad asupDgHD Ef∈U~SDg(∇fL)−Ef∈U~TDg(∇fL) 是引入的 ∇ \nabla ∇-distance, D g D_g Dg 是判别因子, a = 1 min C ( f ) ∈ [ 0 , 1 ] ∇ C L ( C ( f ) , y ) a=\frac{1}{\min _{C(f) \in[0,1]} \nabla_C \mathcal{L}(C(f), y)} a=minC(f)∈[0,1]∇CL(C(f),y)1 .式中 L ( ⋅ ) \mathcal{L}(\cdot) L(⋅) 为损失函数。
定理2当 a ≤ 1 a \leq 1 a≤1时,我们的方法可以获得比传统的域适应方法更紧的上界:
const + d ∇ ( U ~ S , U ~ T ) ≤ +d_{\nabla}\left(\tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T\right) \leq +d∇(U~S,U~T)≤ const + d H ( U ~ S , U ~ T ) +d_{\mathcal{H}}\left(\tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T\right) +dH(U~S,U~T), where d H ( U ~ S , U ~ T ) = sup D g ∈ H D ∣ E f ∈ U ~ S D g ( f ) − E f ∈ U ~ T D g ( f ) ∣ d_{\mathcal{H}}\left(\tilde{\mathcal{U}}_S, \tilde{\mathcal{U}}_T\right)=\sup _{D_g \in \mathcal{H}_D}\left|E_{\boldsymbol{f} \in \tilde{\mathcal{U}}_S} D_g(\boldsymbol{f})-E_{\boldsymbol{f} \in \tilde{\mathcal{U}}_{\mathcal{T}}} D_g(\boldsymbol{f})\right| dH(U~S,U~T)=supDg∈HD Ef∈U~SDg(f)−Ef∈U~TDg(f) . 定理1 - 2的证明可参见补充文献.
、定理1 - 2表明,特征梯度分布差异有助于约束测试误差。换句话说,特征梯度对齐可以减少测试误差。更重要的是,更紧的边界保证了我们提出的方法优于传统的域适应方法。
然而,从经验的角度看,直接计算 ∇ \nabla ∇-distance 可能是困难的。在这项工作中,我们借助域判别器 D g D_g Dg 来近似它。具体来说, D g D_g Dg 试图区分哪些域特征梯度∇f L来自哪个域。 H g \mathcal{H}_g Hg是特征梯度 ∇ f L \nabla_f \mathcal{L} ∇fL上的 ∇ \nabla ∇假设空间.因此,区域偏差 ∣ ϵ T ( C , C ∗ ) − ϵ S ( C , C ∗ ) ∣ \left|\epsilon_T\left(C, C^*\right)-\epsilon_S\left(C, C^*\right)\right| ∣ϵT(C,C∗)−ϵS(C,C∗)∣可以上确界于 ∇ \nabla ∇-distance.详细证明可在补充材料中找到。
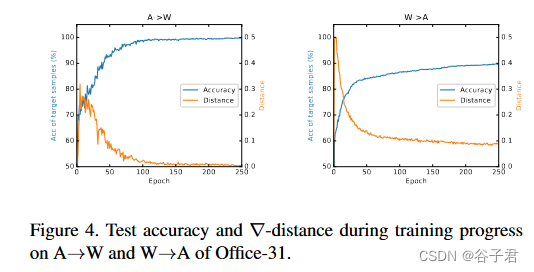
我们在图4中进一步给出了 ∇ \nabla ∇-distance与试验误差的关系。我们考虑一个理想的情况,即目标样本的所有特征梯度都是根据其真实的目标标签计算的。正如观察到的那样,它们之间存在明确的负相关关系。 ∇ \nabla ∇-distance的减小直接导致不同训练历元的测试精度一致提高。直到 ∇ \nabla ∇-distance收敛,A→W和W→A的正确率分别为100 %和90 %。这表明 ∇ \nabla ∇-distance与测试误差高度相关,在两个域之间对齐特征梯度分布类似于用目标伪标注来训练模型。
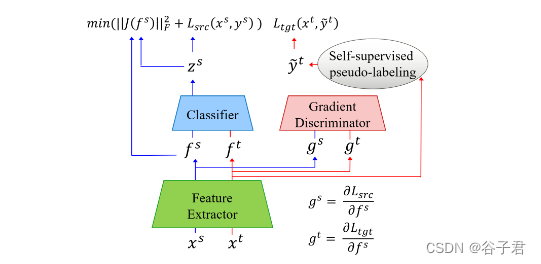
见图2。特征梯度分布对齐的结构。整个结构由多个机制组成:对抗学习(分类器、梯度判别器和特征提取器)、自监督伪标记和Jacobian正则化 ∥ J ( f s ) ∥ F 2 \left\|J\left(f^s\right)\right\|_F^2 ∥J(fs)∥F2,其中后两个机制用于促进对抗学习。
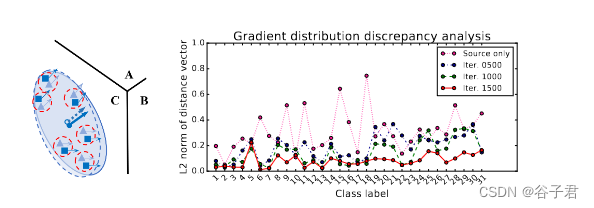
见图3。几何解释:梯度对齐强制两个域的特征停留在梯度相似的小区域(红色虚线圆圈)。数值分析:Office - 31的D→A任务梯度差异分析。
4. Experiments
4.1. Datasets
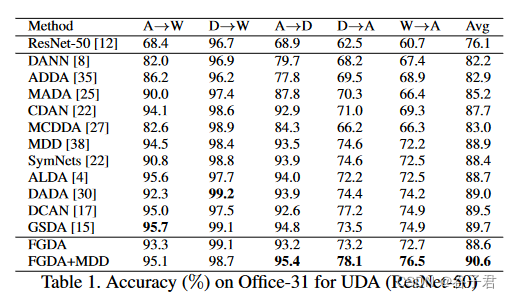
办公室- 31。Office - 31是一个广泛使用的评价视觉域适应算法的数据集。它包括4 652幅图像和31个类别,分别来自三个不同的领域:Amazon ( A )、Webcam ( W )和DSLR ( D )。我们在六种迁移任务A→W,D→W,W→D,A→D,D→A和W→A上评估了所有方法。
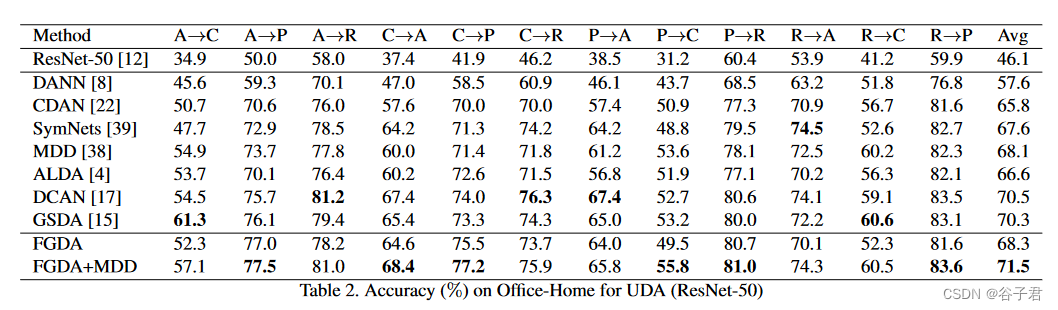
Office - Home是一个更具挑战性的数据集。在办公室和家庭环境中,它由65类15500张图像组成。在四个截然不同的领域:艺术图像( A )、剪贴画( C )、产品图像( P )和真实世界图像( R )上,我们评估了所有的迁移任务。
实施细则。遵循UDA的标准评估协议[ 3 ],将所有有标签的源和无标签的目标实例作为训练数据。为了公平比较,我们使用与被比较方法相同的网络结构。具体地,所有实验均采用ResNet - 50 [ 12 ]作为主干网络,并采用线性层后跟softmax函数作为类别分类器。对于我们的梯度判别器,它由两个隐藏层组成,分别是一个全连接层,然后是ReLu激活函数和Batch Norm层,以及一个对隐藏特征进行线性变换,然后用sigmoid函数激活的域分类器。对抗学习算法的实现类似于原始的DANN [ 8 ],在特征梯度上施加反向梯度层。式中:,单独考察FGDA时, λ 1 \lambda_1 λ1取1。FGDA与MDD结合时[ 38 ],如公式所示。 λ 3 \lambda_3 λ3固定为0 . 5,Office - 31和Office - Home分别取 λ 1 = 1 \lambda_1=1 λ1=1 和 λ 1 = 0.5 \lambda_1=0.5 λ1=0.5 。对于 λ 2 \lambda_2 λ2,从[ 0.05、0.10、0.15、0.20、0.25]中进行搜索,以达到最佳效果。
4.2. Results
我们将所提出的方法与以前的一些ADA方法进行了比较。结果报告于表1和2。Office - 31上W→D的所有结果都是隐藏的,但是参与平均结果的计算,因为大多数模型在这个任务上达到了100 %。MADA [ 25 ]、CDAN [ 22 ]和GSDA [ 15 ]将单个或多个判别器作用于分类器输出以改进DANN [ 8 ]。SymNets [ 39 ]和DADA [ 30 ]通过依赖分类器输出和创造性的对抗学习机制进一步实现领域判别和混淆。MCDDA [ 27 ]和MDD [ 38 ]考虑了两个分类器的不一致以缓解类内分布差异。可以看出,FGDA取得了与MDD相媲美的结果,表明单独使用特征梯度对齐来减少分布差异是可行的。此外,FGDA + MDD在Office - 31数据集上和Office - Home数据集上分别比对比模型的最优结果提高了0.9 %和1.0 %
5. Further Analysis
5.1. Ablation Study
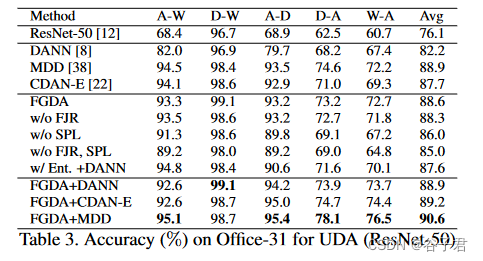
我们的研究从设置一个非适应模型作为第一条基线开始,该基线只需在源数据上微调RestNet - 50 [ 12 ]。为了证明我们的方法相对于基于表示的ADA方法的优势,DANN [ 8 ],CDAN-E [ 22 ]和MDD [ 38 ]将分别与我们的方法结合并作为其他基线。为了研究高质量的伪标注如何提高性能,我们从我们的方法中删除了自监督伪标记( SPL )方法;为了检验梯度正则化的性能,我们还去掉了特征级的Jacobian正则化( FJR );为了验证特征梯度对齐降低分布散度的可行性,我们同时去除FJR和SPL。为了观察损失函数的影响,当只应用特征梯度对齐时,将计算目标域梯度的损失函数由交叉熵改为条件熵最小化( Ent . )。
如表3所示,在相同的网络结构下,FGDA ( w / o FJR、SPL)比DANN有所改进,表明采用梯度作为表示不仅可以减少分布发散,而且可以得到更好的分布对齐效果。FGDA ( w / o FJR )和FGDA ( w / o SPL )能够显著提高FGDA ( w / o FJR、SPL)的性能,证明了各组分的有效性。同时,将FGDA ( w / Ent . )应用到DANN上,虽然没有FGDA + DANN的效果明显,但仍然获得了显著的性能增益。
对于FGDA,它的性能与MDD相当,并且大大优于DANN和CDAN。此外,当FGDA分别与DANN、CDAN - E和MDD结合时,结果证实了将梯度作为度量分布散度的表征单位化确实能够一致地提高基于表征的ADA。
5.2. Visualization Analysis
为了对FGDA有一个直观的认识,并表明梯度对齐确实有助于减少分布差异,我们使用tSNE [ 36 ]在Office - 31上可视化源域和目标域的特征及其梯度。如图5所示,在ResNet - 50 (仅源域)中,源域和目标域的特征分布和梯度分布由于域偏移较大而分布不同。当使用MDD对齐特征分布时,即使特征分布差异已经减小,梯度分布差异依然明显。相比之下,FGDA + MDD在特征和梯度的分布差异上都比MMD表现出更小的优势。此外,观察到目标特征与源特征一样具有判别性,在进行特征梯度对齐后,目标分布是类间分离和类内聚集的。注意,CDAN-E [ 22 ]、FGDA ( w / o FJR、SPL)和FGDA的可视化结果在补充文档中提供。

图5 . Office - 31任务A→W上仅源模型( Rest Net-50 )、MDD和FGDA + MDD的特征分布和梯度分布的t - SNE可视化。蓝色和红色点分别表示源域和目标域样本。
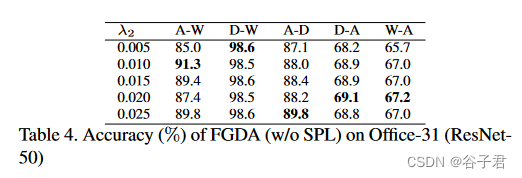
5.3. Sensitivity Analysis
在表4中,我们实证了FGDA ( w / o SPL )中FJR的平衡参数λ 2的影响。从[ 0.05、0.10、0.15、0.20、0.25]中选取 λ 2 \lambda_2 λ2,将Office - 31的所有结果呈现出来进行敏感性分析。虽然 λ 2 \lambda_2 λ2的设定并没有一致的趋势,但我们观察到所选择的参数范围,从0.05到0.25,基本上可以涵盖大部分最好的结果。其他参数 λ 1 \lambda_1 λ1和 λ 3 \lambda_3 λ3的敏感性分析见补充文献。
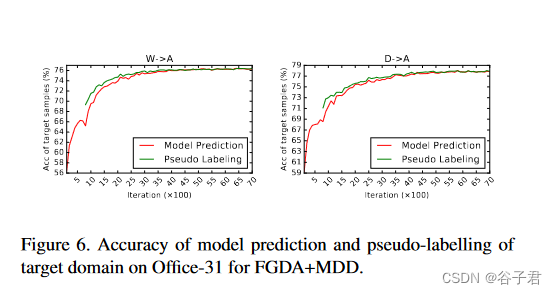
为了研究目标域中的伪标签噪声如何影响性能,在图6中对FGDA + MDD进行了案例分析。值得注意的是,FJR、SPL和MDD在900次迭代后得到应用。最初,即使没有高质量的伪标记,梯度对齐也是有效的。一旦涉及SPL,更精确的目标域梯度分布对性能有明显的促进作用。在使用梯度对齐进行训练时,获得了目标样本更加可分离的特征空间,使得伪标记和模型预测的准确率交替提高。因此,梯度对齐可以从伪标记中获益,反之亦然。除此之外,还有其他方法可以实现高质量的伪标注,如时间集成方法Mean教师模型[ 31 ]。
6. Conclusion
在这项工作中,我们表明现有的对抗域适应方法有一个固有的缺点,即即使判别器完全混淆,也不能保证两个分布之间有足够的相似性。针对这一问题,我们提出了一种新的特征梯度分布对齐方法,该方法能够进一步降低源域和目标域之间的分布差异。我们从理论和实证上证明了通过对齐特征梯度可以减小分布差异。更重要的是,我们提出的新框架在理论上保证了在目标域上可以获得比现有的对抗域自适应方法更严格的误差上界。大量的实验验证了我们提出的新框架可以在两个真实的基准数据上定量和定性地达到最新的性能。
这篇关于2021_ICCV_Gradient Distribution Alignment Certificates Better Adversarial Domain Adaptation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[SWPUCTF 2021 新生赛]web方向(一到六题) 解题思路,实操解析,解题软件使用,解题方法教程](https://i-blog.csdnimg.cn/direct/bcfaab8e5a68426b8abfa71b5124a20d.png)
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)

