本文主要是介绍语音合成论文优选:脑机接口的语音合成Advancing Speech Synthesis using EEG,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
(这周主要看一个有趣的研究方向:脑机接口中的语音合成。粗略的搜了一下2020年的基于脑电图语音合成的文章,几篇文章都是出自德克萨斯大学奥斯汀分校脑机接口实验室,真是一招鲜,吃遍天呀!我感觉脑机接口的未来还有很长的路,尤其EEG数据的分析和清洗,使EEG数据的noise更少。另外人类和其它物种的EEG之间是否存在某种信息关系,是否可以通过EEG来进行万物交流?这样你可以听到动物们的声音,也可以回答动物)
Advancing Speech Synthesis using EEG
本文章是德克萨斯大学奥斯汀分校脑机接口实验室在2020.05.03更新的文章,主要的工作使用脑电图EEG来合成语音,具体的文章链接
https://arxiv.org/pdf/2004.04731.pdf
1 研究背景
脑机接口的研究已经发展很长时间,在语音方面通常使用脑信息来进行语音识别和语音合成,其中脑信息的获取主要包括侵入式和非侵入式。侵入式方式的信心获取是通过手术把芯片植入到大脑中,这样可以减少很多噪声。非侵入式的信息获取是使用电子传感器通过头皮来获取信息,常用的就是脑电图(EEG),这种方式更加安全和廉价。基于EEG的语音合成主要使用EEG来预测声学特征,其训练数据的获取是当参与者录取音频的时候,同时获取其脑电图来获取<EEG, audio>的并行数据。本文提出基于attention的回归模型,效果优于以前的回归模型。
(说个题外话,脑机接口的语音合成还是非常有趣,至少可以做到玄幻中的"内功传音",想想这种场面:两个人戴着脑电波采集器并发射给对方,对方接受脑电波后合成语音,通过播放器可以听到对方的悄悄话。另外,研究脑机接口的语音合成更关键点是EEG数据,使用的语音合成的架构都十分简单)
2 详细设计
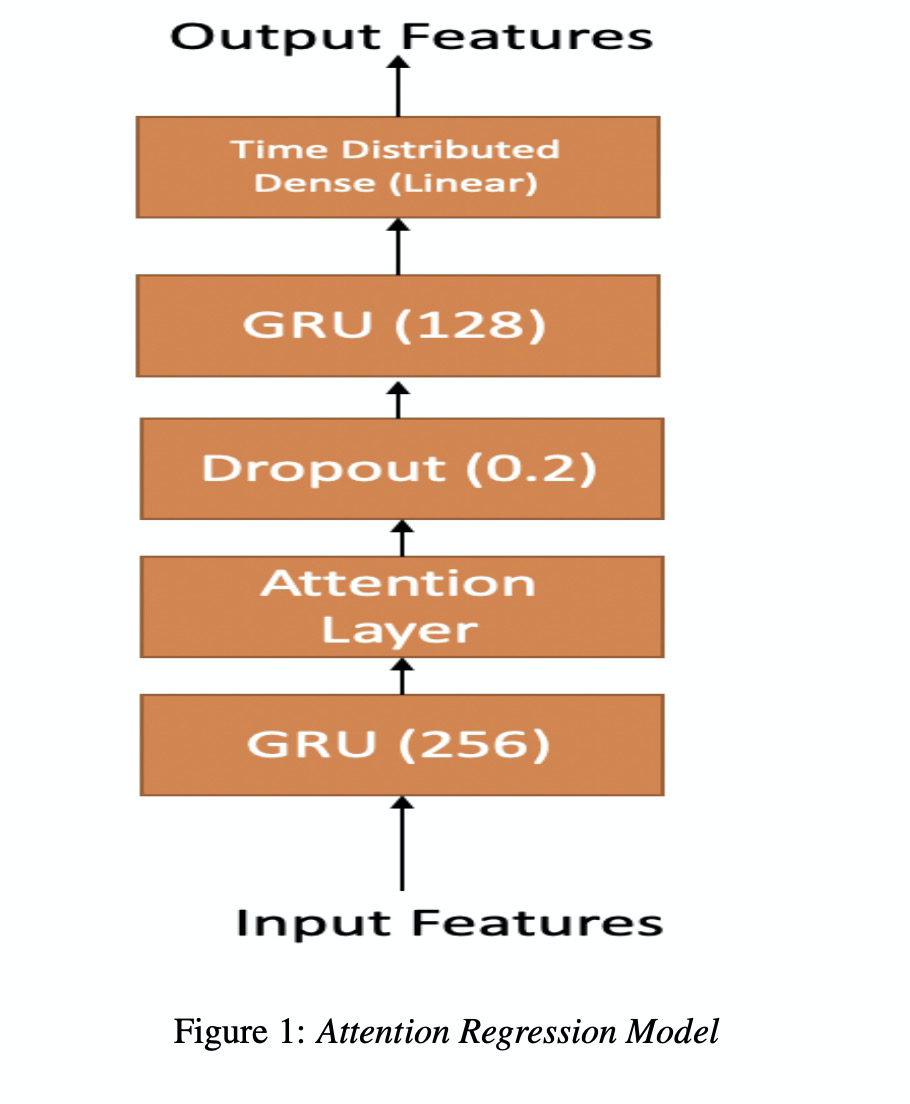
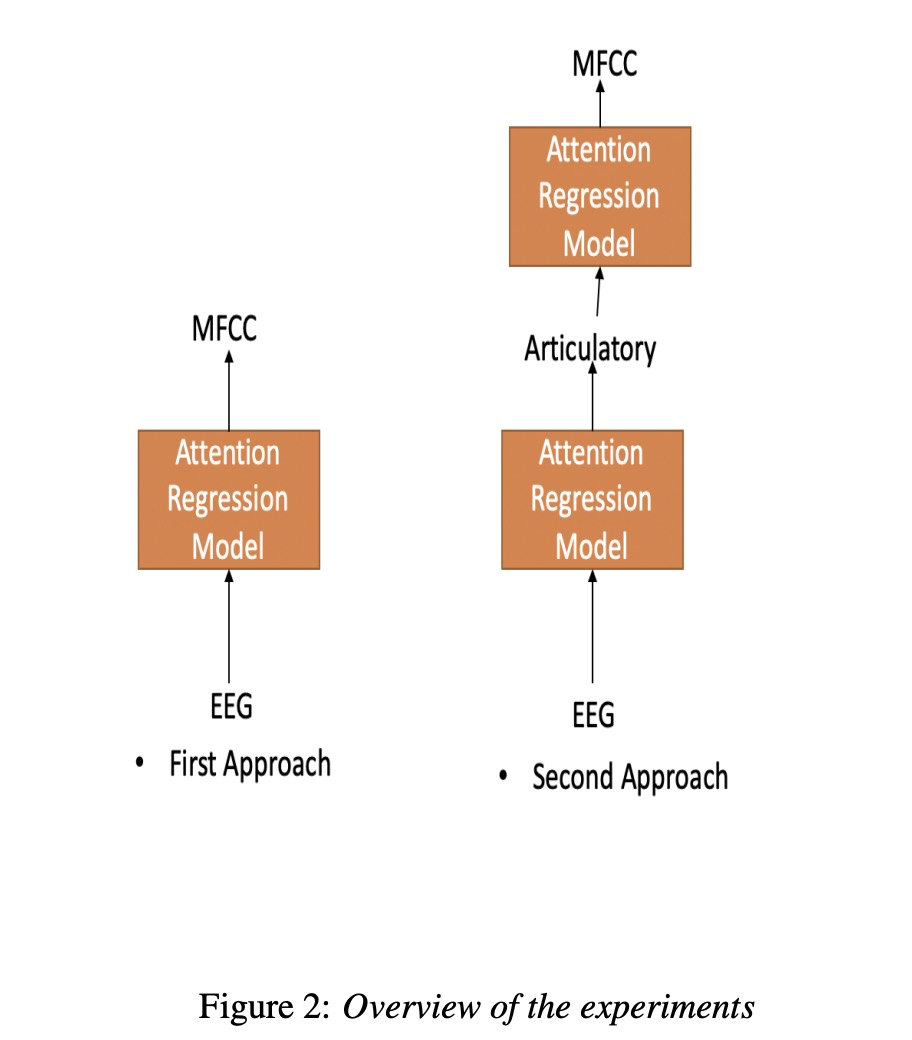
本文主要是使用attention机制来优化基于EEG的语音合成,其中attention机制主要如下的公式1~3。我们可以看一下图1所示的架构,该架构很简单,就不再阐述(这类似的图在接下来的几篇文章都会出现)。图2展示了两种实验方式,直接从EEG转成声学特征MFCC,第二种是先使用EEG转成发音的特征articulatory,然后再转成MFCC。
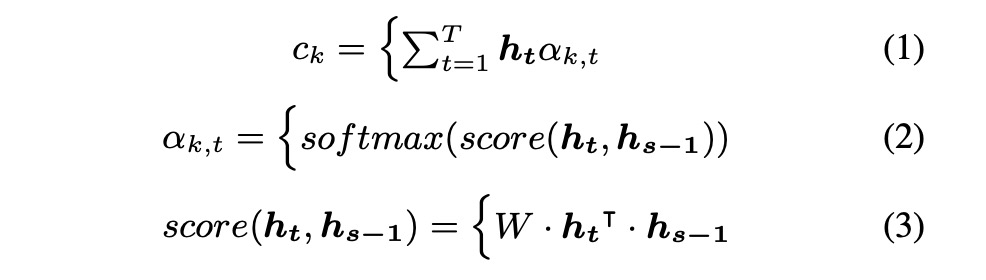
3 实验
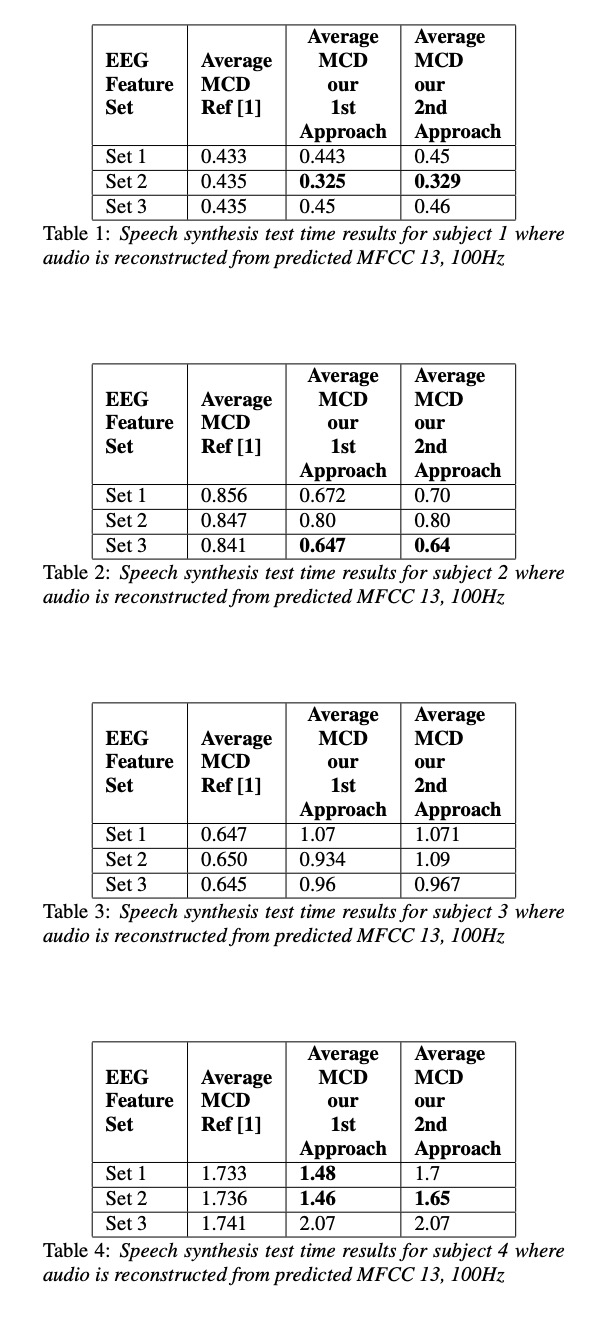
本文实验主要包括4位参加者,其中set 1,set2 , set3的区别是EEG的维度分别为30, 50 和93。table1~4显示各测试结果,其中第1种方法比第2种方法低一些(作者说不是MCD越低就是合成音频越好,但本文章又说比以前的方案低多了。)table 5展示了MFCC 128为结果,图3图4展示语音重构的结果。(可惜没放出样音,样音一听就一耳了然了)
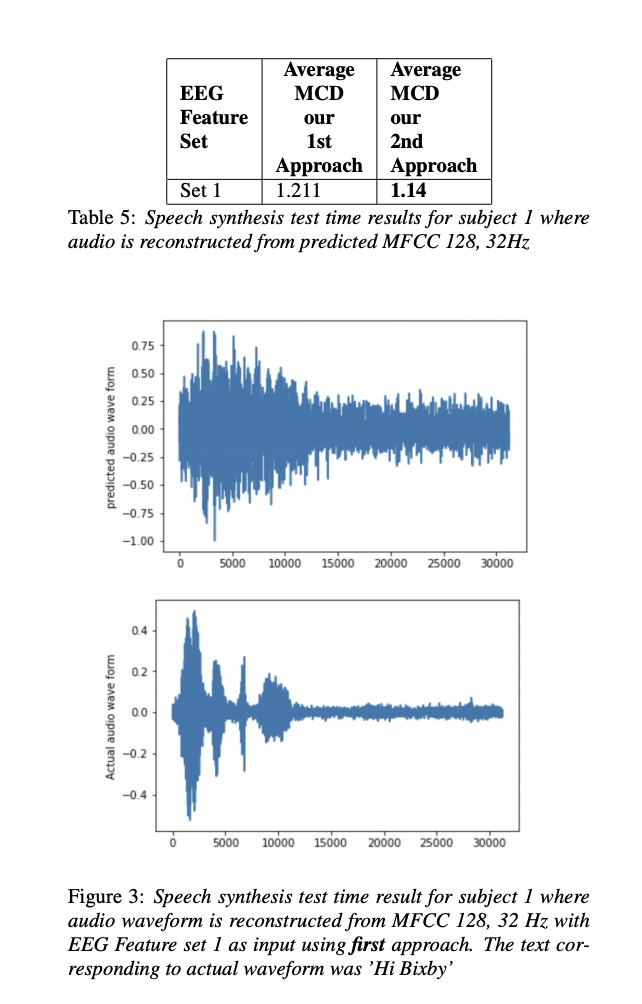
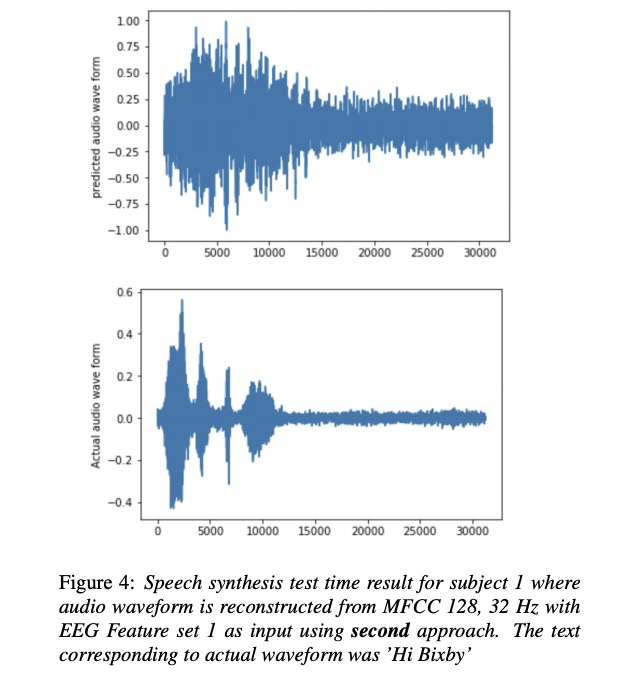
4 总结
本文主要使用attention机制来优化基于EEG的语音合成,合成的语音可懂度更高。(其实我感觉EEG的分析和清洗才是未来的工作)
这篇关于语音合成论文优选:脑机接口的语音合成Advancing Speech Synthesis using EEG的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







