本文主要是介绍R语言 随机森林 Random Forest 交叉验证 error.cv Gini指数画图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机器学习RandomForest, 随机森林, 分类回归
#自己的一些记录。 提供参考吧。
#可以直接复制到R运行
#加载包
library(randomForest)
#加载数据
data=read.csv("L6_filter.csv",row.names = 1,header=T)
#设置随机种子数,确保以后再执行代码时可以得到一样的结果
set.seed(123456789)
#数据随机采样设置70%数据用作训练集 30%用作测试集
train_sub = sample(nrow(data),7/10*nrow(data))
train_data = data[train_sub,]
test_data = data[-train_sub,]
#数据预处理 factor的作用是打上标签或者类别
train_data$zq101 = as.factor(train_data$zq101) #zq101是我的分组信息
test_data$zq101 = as.factor(test_data$zq101)
#筛选mtry个数
n<-length(names(train_data))
set.seed(123456789) #一些网友说每次随机森林前面都要跑一下
for(i in 1: (n-1)){
mtry_fit<-randomForest(zq101~. ,data=train_data,mtry=i)
err<-mean(mtry_fit$err.rate)
print(err)
}
##试验性训练模型,使用训练集构建随机森林
#ntree和mytry分布根据后面的步骤确定 决策树的数量,默认是500,
#mtry每个分组中随机的变量数一般是变量数开根,每棵树使用的特征个数
#mtry指定节点中用于二叉树的变量个数 ??randomForest
set.seed(123456789) #一些网友说每次随机森林前面都要跑一下
train_randomforest <- randomForest(zq101 ~ .,data = train_data,
ntree =500, mtry=8, importance=TRUE ,
proximity=TRUE)
#判断树的数量,树的数量大于?的时候就基本稳定了
plot(train_randomforest)
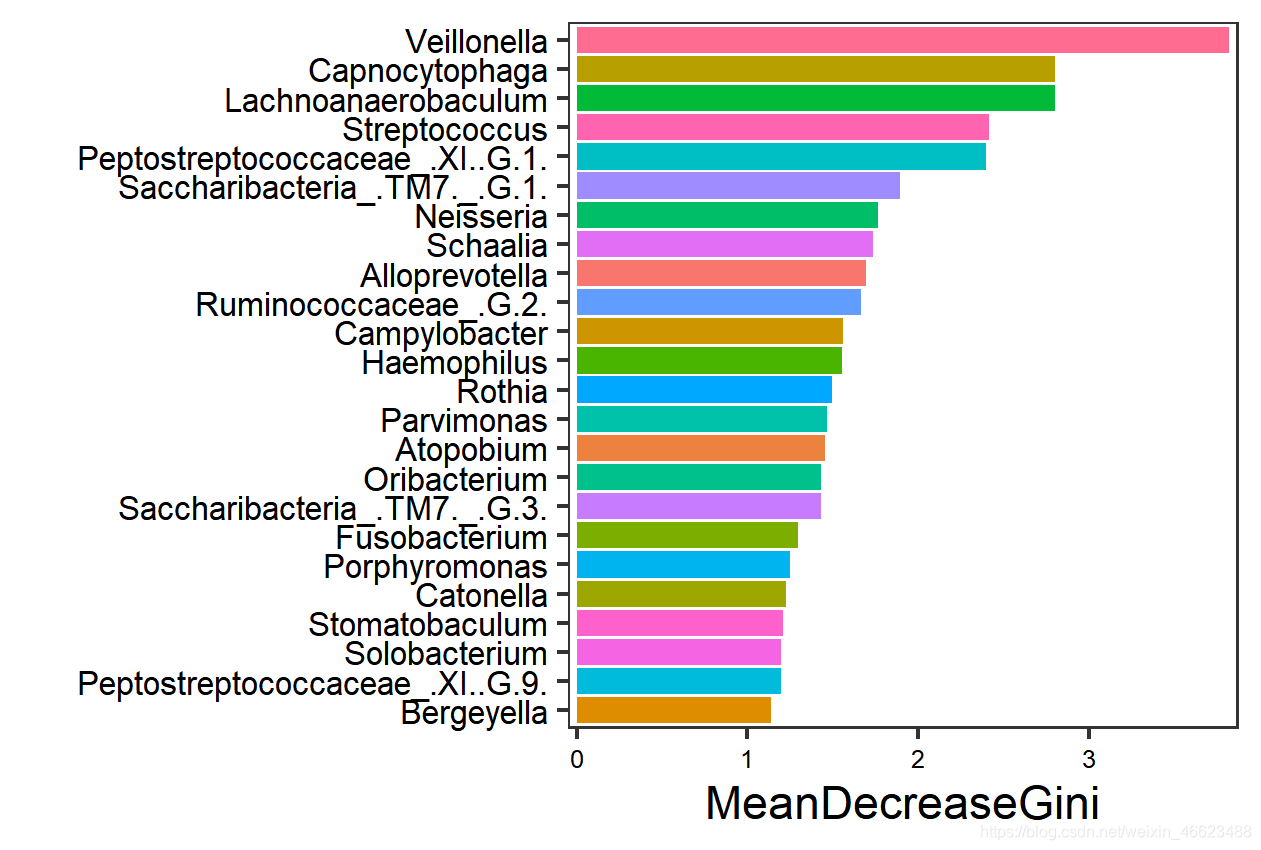
#查看变量的重要性
train_randomforest$importance
#对于变量重要性的判断,也可以通过画图的方式直观显现:
varImpPlot(train_randomforest, main = "variable importance",
n.var = 25) #var代表显示前?个变量
#对测试集进行预测??predict
pre_ran <- predict(train_randomforest,newdata=test_data)
#将真实值和预测值整合到一起
obs_p_ran = data.frame(prob=pre_ran,obs=test_data$zq101)
#输出混淆矩阵
table(test_data$zq101,pre_ran,dnn=c("真实值","预测值"))
#ROC曲线和AUC值??ROC
library(pROC)
ran_roc <- roc(test_data$zq101,as.numeric(pre_ran),ci=TRUE)
ran_roc
plot(ran_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),
grid.col=c("green", "red"), max.auc.polygon=TRUE,
auc.polygon.col="skyblue", print.thres=TRUE,
main='随机森林模型ROC曲线,mtry=3,ntree=500')
#随机森林连续型变量 ??predict #对比下上一个也有加颜色的,type可以选择3个参数
fitted.prob<-predict(train_randomforest,newdata=test_data,type="prob")
roc_prob<-roc(as.ordered(test_data$zq101),fitted.prob[,2],ci=T) #计算ROC
auc(roc_prob)
roc_prob$ci
#??plot.roc
plot.roc(roc_prob,col="mediumblue",legacy.axes=TRUE)
roc_prob$ci
#导出图片 pdf 6*8
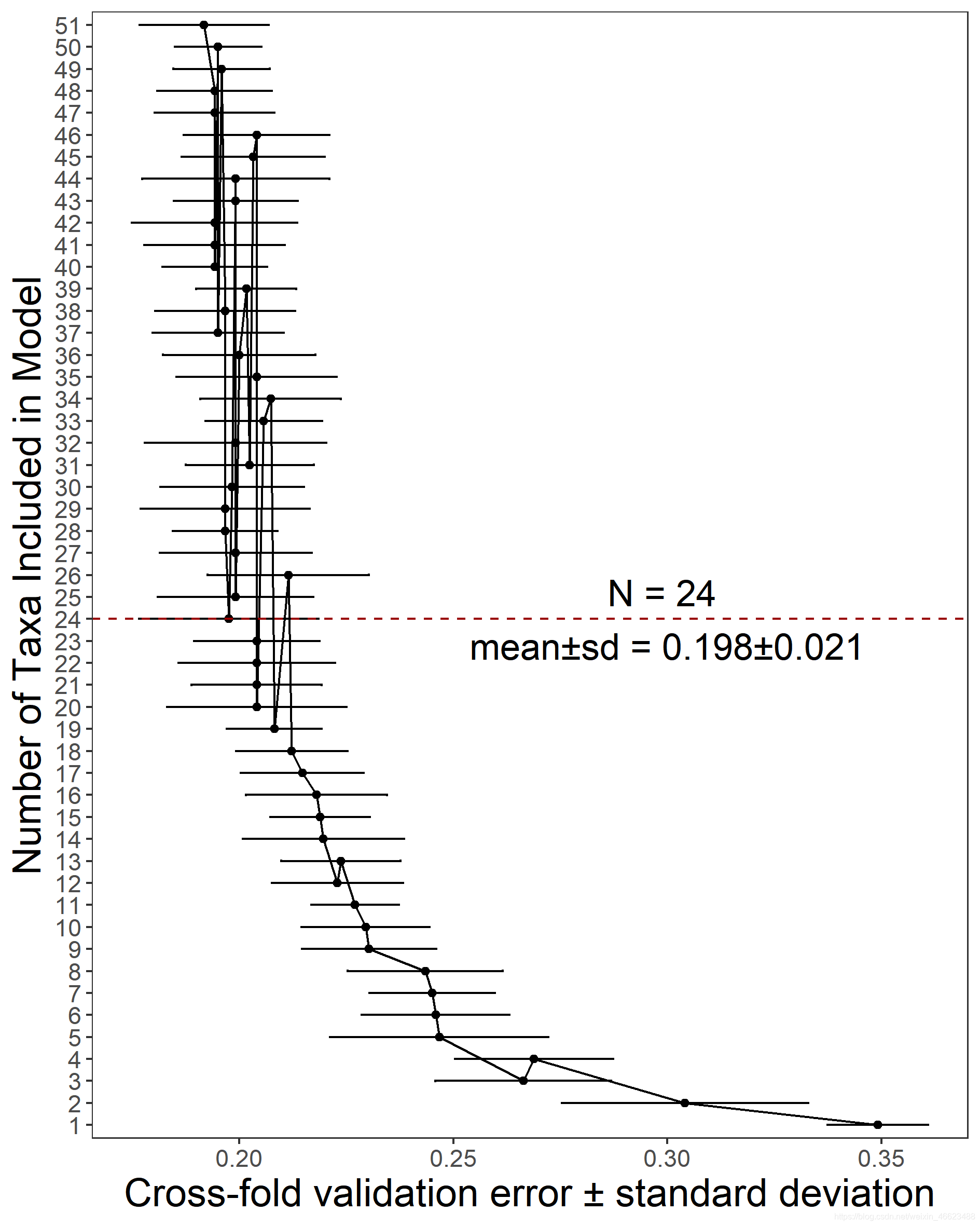
#交叉验证
set.seed(1264759)
data$zq101 = as.factor(data$zq101)
data1 <-data[,2:53]
#交叉验证中添加随机数的训练集、分组、交叉验证的次数
#step是样本改变的倍数(输出的x轴) #step可以改变看下结果,其实是一次变量数
result <- rfcv(data1, data$zq101, cv.fold=5,scale="log", step=0.99)
# 绘制错误率曲线,观察错误率与使用Markers数量的变化
with(result, plot(n.var, error.cv, log="x", type="o", lwd=2))
result$error.cv
##使用replicate多次交叉验证??replicate
result <- replicate(10, rfcv(data1, data$zq101, cv.fold=5,scale="log", step=0.99),
simplify=FALSE)
error.cv <- sapply(result, "[[", "error.cv")
matplot(result[[1]]$n.var, cbind(rowMeans(error.cv), error.cv), type="l",
lwd=c(2, rep(1, ncol(error.cv))), col=1, lty=1, log="x",
xlab="Number of variables", ylab="CV Error")
#显示误差行均值
row_mean = apply(error.cv,1,mean)
min(row_mean)
提取绘制折线图
a=data.frame(result[[1]][["error.cv"]])
b=data.frame(result[[2]][["error.cv"]])
c=data.frame(result[[3]][["error.cv"]])
d=data.frame(result[[4]][["error.cv"]])
e=data.frame(result[[5]][["error.cv"]])
f=data.frame(result[[6]][["error.cv"]])
g=data.frame(result[[7]][["error.cv"]])
h=data.frame(result[[8]][["error.cv"]])
i=data.frame(result[[9]][["error.cv"]])
j=data.frame(result[[10]][["error.cv"]])
#合并并删除
error_cbing=cbind(a,b,c,d,e,f,g,h,i,j)
rm(a,b,c,d,e,f,g,h,i,j)
#均数+标准差
row_mean = apply(error_cbing,1,mean)
row_mean2=data.frame(row_mean)
row_sd= apply(error_cbing,1,sd)
row_sd=data.frame(row_sd)
row_mean_sd=cbind(row_mean2,row_sd)
#改下名字
names(row_mean_sd)[1]="mean"
names(row_mean_sd)[2]="sd"
xa=rownames(row_mean_sd)
xxa=data.frame(xa)
row_mean_sd2=cbind(xxa,row_mean_sd)
#error_sum$xa = factor(error_sum$xa,ordered=TRUE)
#str(error_sum)
#先把数据导出,手动变成因子化
#删掉一部分折线点 #xmin=lowSD, xmax=highSD
row_mean_sd2$lowSD=row_mean_sd2$mean-row_mean_sd2$sd
row_mean_sd2$highSD=row_mean_sd2$mean+row_mean_sd2$sd
write.table(row_mean_sd2,"折线图.csv",sep=",",row.names=TRUE,col.names=TRUE)
#数据可视化,散点图 分组情况
MDSplot(train_randomforest,train_data$zq101,palette = rep((2:8),2),cex=0.5)
#然后看一下样本之间的距离
#看做每个样本映射到2维空间中的坐标,每一维空间是一个分类特征,
#但是不是最原始的4个特征,而是由4个特征衍生得到的新的分类特征,
#根据这个坐标,可以画一张散点图,得到每个样本基于两个分类变量的分组情况
data.mds <- cmdscale(1 -train_data$proximity, eig=TRUE)
plot(data.mds$points, col = rep(c("red", "blue", "green"), each = 50))
#一些想法 或原理学习
#random forest结果是有随机性的,因为每次训练单个数都是通过Bootstrap随机取样
#所以每次结果不同是正常的。
#每次运行结果都是随机初始值的
#所以你在运行前加一个代码:set.seed(100)括号里面的数字是可以自己设定的,
#相当于固定下来那个随机值,每次运行都设定相同的值结果就会一样了
#OOB estimate of error rate 表明了分类器的错误率为4%
Gini指数绘图(后续提供)
误差折线图 (后续提供)
这篇关于R语言 随机森林 Random Forest 交叉验证 error.cv Gini指数画图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








