gini专题

信息增益、信息增益率、Gini
1、 C4.5继承了ID3的优点,并改进了:(1)使用信息增益率来选择属性,克服了用信息增益选择属性时偏向值多的不足;(2)在构树过程中进行剪枝;(3)能够完成对连续属性的离散化处理;(4)能够对不完整数据进行处理; 2、 信息增益、信息增益率、Gini这三个指标均是决策树用来划分属性的时候用到的,其中信息增益(Info Gain)用于ID3,Gini用于CART,信息增益率(Info Ga

风控建模 数据对照篇:WOE IV 回归系数 P值 相关系数 共线性指标 膨胀因子 KS AUC GINI PSI
最重要的事情开始都会讲:建模是始终服务于业务的,没有业务的评分卡就没有灵魂 每一个指标段对应的评价如下,就当做各位的参考表数据吧。希望可以对大家有帮助 第一部分 指标图表以及英文简介 第二部分 指标对应参考数据 需要说明的是,由于对应的目标客群不同,可能各个指标所提供标准不同,可能银行和小贷公司对于KS的标准不相同,银行相对严格,小贷公司可能包含其余的策略性规则,因此可能KS相对比较小

迹象权数WOE、信息值IV、kS值、GINI系数
WOE和IV使用来衡量变量的预测能力,值越大,表示此变量的预测能力越强。 WOE=ln(累计正样本占比/累计坏样本占比) IV=(累计正样本占比-累计坏样本占比)*WOE 信息值(IV)预测能力<0.03无预测能力0.03~0.09低0.1~0.29中0.3~0.49高0.5~极高 KS和GINI系数用来衡量数据对好坏样本的区分能力 KS 值,累计客户分布百分比,由小到大排列,两者之间的
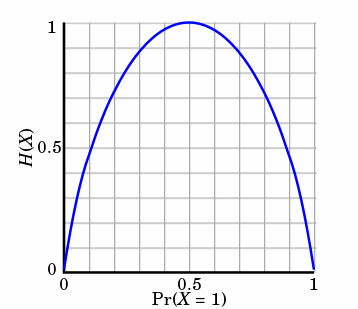
决策树中的熵、条件熵、信息增益和Gini指数计算示例
文章目录 信息熵条件熵信息增益公式计算 Gini指数计算示例 信息 首先我们从什么是信息来着手分析: I ( X = x i ) = − l o g 2 p ( x i ) I_{(X = x_i)} = -log_2p(x_i) I(X=xi)=−log2p(xi) I ( x ) I(x) I(x)用来表示随机变量的信息, p ( x i ) p(x_i) p
信息、信息熵、条件熵、信息增益、信息增益率、GINI指数、交叉熵、相对熵
在信息论与概率统计学中,熵(entropy)是一个很重要的概念。在机器学习与特征工程中,熵的概念也常常是随处可见。自己在学习的过程中也会常常搞混,于是决定将所有与熵有关的概念整理总结,方便查看和学习。 1. 信息 它是熵和信息增益的基础概念。引用香农的话,信息是用来消除随机不确定性的东西。如果一个带分类的事物集合可以划分为多个类别,则其中某个类(xi)的信息定义:
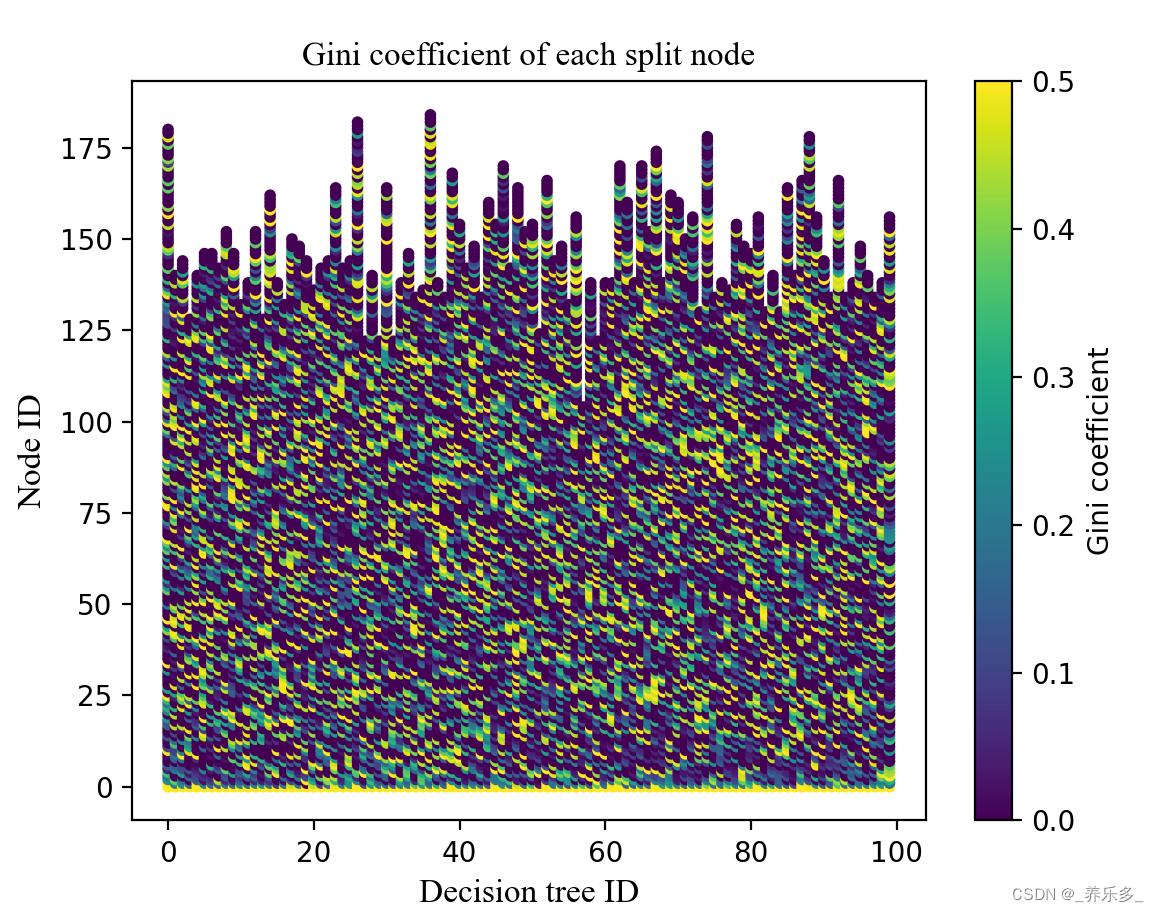
python:计算随机森林每个决策树分裂节点的Gini系数,并绘制散点图
作者:CSDN @ _养乐多_ 本文记录了运行随机森林分类算法的时候,每个随机决策树的分裂节点的Gini系数,并将其可视化,绘制成散点图,横坐标是决策树ID,纵坐标是节点ID,Gini系数使用点表示,不同大小的Gini系数颜色不一样。代码使用python语言实现。 文章目录 import matplotlib.pyplot as pltfrom sklearn.en
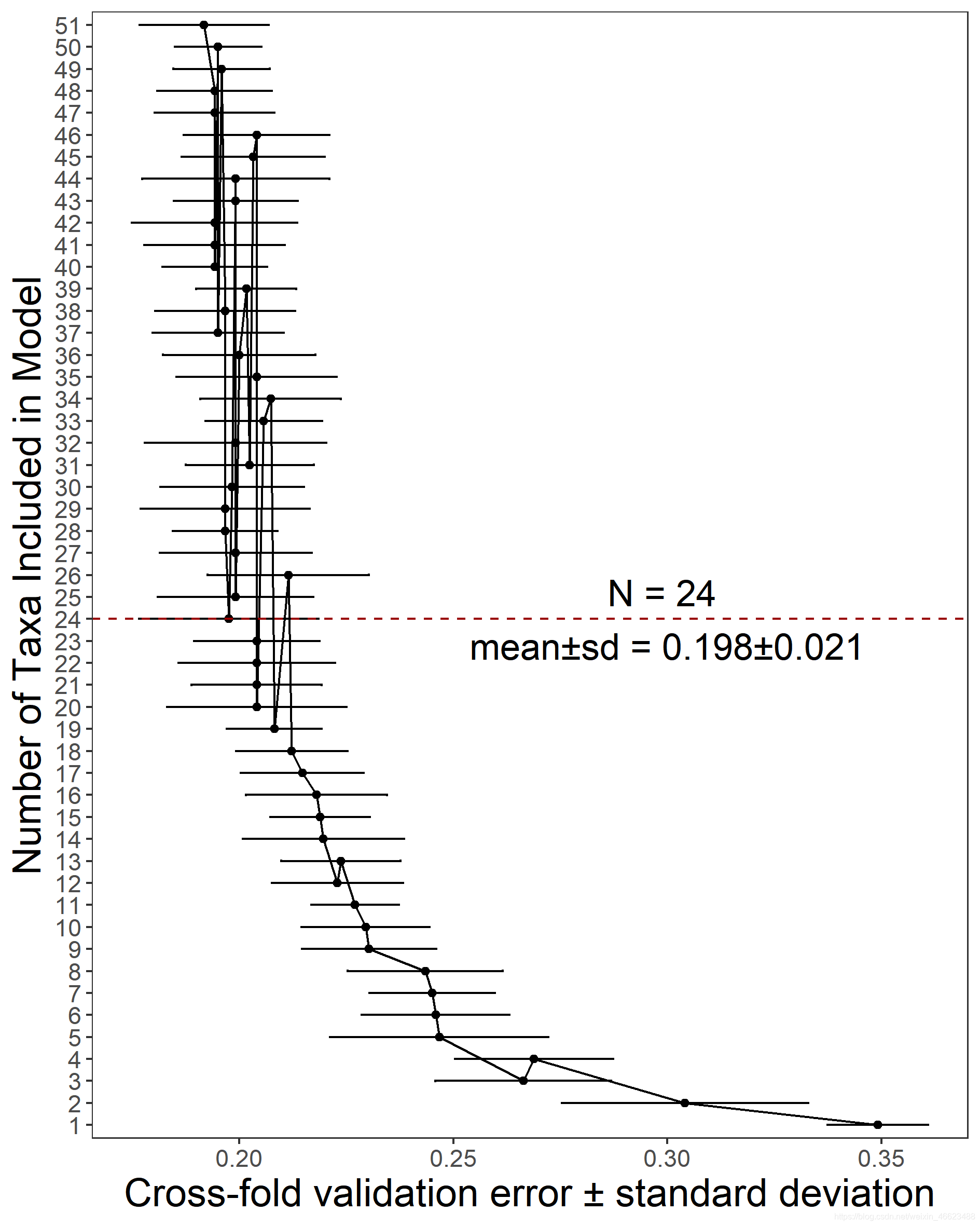
R语言 随机森林 Random Forest 交叉验证 error.cv Gini指数画图
机器学习RandomForest, 随机森林, 分类回归 #自己的一些记录。 提供参考吧。 #可以直接复制到R运行 #加载包 library(randomForest) #加载数据 data=read.csv("L6_filter.csv",row.names = 1,header=T) #设置随机种子数,确保以后再执行代码时可以得到一样的结果 set.seed(12345

决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)...
1. 1、问题的引入 2、一个实例 3、基本概念 4、ID3 5、C4.5 6、CART 7、随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? 一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不?