forest专题

1034 forest
大水题,WA到吐了,结果发现犯了一弱智错误,擦 1.定义dept[]数组,主要用bfs ,将子节点的dept值累加父节点的dept值,遍历一颗或者若干树。从根节点(bepointed[]值为false的点)出发遍历全棵树。 2.存储方式:邻接表存边 vector+queue , #include <iostream>#include<queue>#include<vector>

孤立森林 Isolation Forest 论文翻译(上)
README 自己翻译的+参考有道,基本是手打的可能会有很多小问题。 括号里的斜体单词是我觉得没翻译出那种味道的或有点拿不准的或翻译出来比较奇怪的地方,尤其是profile、swamping和masking这三个词不知道怎样更准确。 欢迎指正和讨论,需要Word版可以留言。 孤立森林 摘要 大多数现有的基于模型的异常检测算法构建了一个正常实例的特征轮廓(profil
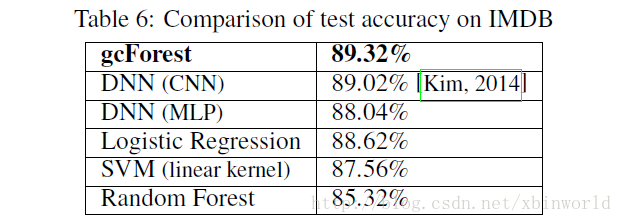
Deep Forest,非神经网络的深度模型
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 深度学习最大的贡献,个人认为就是表征学习(representation learning),通过端到端的训练,发现更好的features,而后面用于分类(或其他任务)的输出function,往往也只是普通的softmax(或者其他一些经典而又简单的方法)而已,所以,只要特征足够好,分类

hdu3987 Harry Potter and the Forbidden Forest 最小割割边最少
题意:给一个n个点构成的有向图,起点为0,终点为n-1。每条边有一个权值,删除一条边的代价为边权。问如何删除使得0和n-1不 联通且代价最小,在这种情况下至少要删除多少条边。 思路:首先保证代价最小,很容易想到是最小割,但是不知怎么保证割边最少= =看了大神博客。。恍然大悟。。模型真是见得 少。。我们设一个较大的值N(N>数据给的最大边数),将边权变成w*N+1,那么最后求得的最大流对N取
Random Forest GBDT XGBOOST LightGBM面试问题整理
一.知识点 二.特征重要性评估 基于树的集成算法有一个很好的特性,就是模型训练结束后可以输出模型所使用的特征的相对重要性,便于理解哪些因素是对预测有关键影响,有效筛选特征。 Random Forest 袋外数据错误率评估 由于RF采用bootstrapping有放回采样, 一个样本不被采样到的概率为 limm→∞(1−1m)m=1e≈0.368 lim m → ∞
hdu 4941 Magical Forest(hash映射)
题目链接:hdu 4941 Magical Forest 题目大意:给定N,M和K,表示在一个N*M的棋盘上有K个棋子,给出K个棋子的位置和值,然后是Q次操作,对应的是: 1 a b :交换a和b两行2 a b : 交换a和b两列3 a b :查询a b这个位置上棋子的值,没有棋子的话输出0 解题思路:一开始X[i]

HDU 4941 Magical Forest
题目链接~~> 做题感悟:这题开始看时感觉很难,后来发现行和列没关系,属于有想法的一类的题目。 解题思路: 因为所给的数据范围很大,开数组根本开不下,但是一看水果的数量并不大,可以从这里下手。细心观察一下发现行和列是没有关系的,交换行的时候没必要考虑列的感受,反之亦然,这样用map 离散化一下,然后用双重map 标记一个水果的位置,交换的时候只交换映射的值就
机器学习之快速森林分位数回归(Fast Forest Quantile Regression)
快速森林分位数回归(Fast Forest Quantile Regression)是一种用于回归任务的机器学习方法,旨在预测目标变量的特定分位数值。与传统回归模型不同,分位数回归能够提供目标变量的不同分布信息,而不仅仅是均值预测。这在需要估计不确定性范围或分布特征的应用中非常有用。 1. 核心概念 回归树:用于回归任务的决策树,通过一系列分裂条件预测连续目标变量。随机森林:通过集成多棵回归树
【scikit-learn006】随机森林(Random Forest)ML模型实战及经验总结(更新中)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架随机森林(Random Forest)相关知识体系 3.欢迎批评指正,欢迎互三,跪谢一键三连! 3.欢迎批评指正,欢迎互三,跪谢一键三连! 3.欢迎批评指正,欢迎互三,跪谢一
Isolation Forest | 隔离森林论文阅读
Note of Isolation Forest 论文:https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf 一、介绍 作者认为,异常数据存在两个显著的特性: 数量少,甚至是极少与正常数据有显著的属性值差异 简单来说,异常是少且非常不同的。 因此,作者要做的就是找出这些异常点,而不是为正常数据建模(传统方法
HDOJ 4941 Magical Forest
题目: Magical Forest Time Limit: 24000/12000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) Total Submission(s): 389 Accepted Submission(s): 186 Problem Description The
1142A Walk Through the Forest
题目大意: 公司和家之间隔着一片森林,回家的路有多条,但是每两个岔路口之间只有一条直通的路,如果从公司出发,走a->b这条路的前提是a到家的距离要比b到家的距离远。现在问你最多有多少种走法! 解题思路: 没认真分析完题目就开始写代码的都是瞎搞,分析完题目后不认真写代码的都是扯淡,出现bug后只会找关键点错误的更是傻逼,为了赋值的时候多写了个==找了大半天,oh!no!.
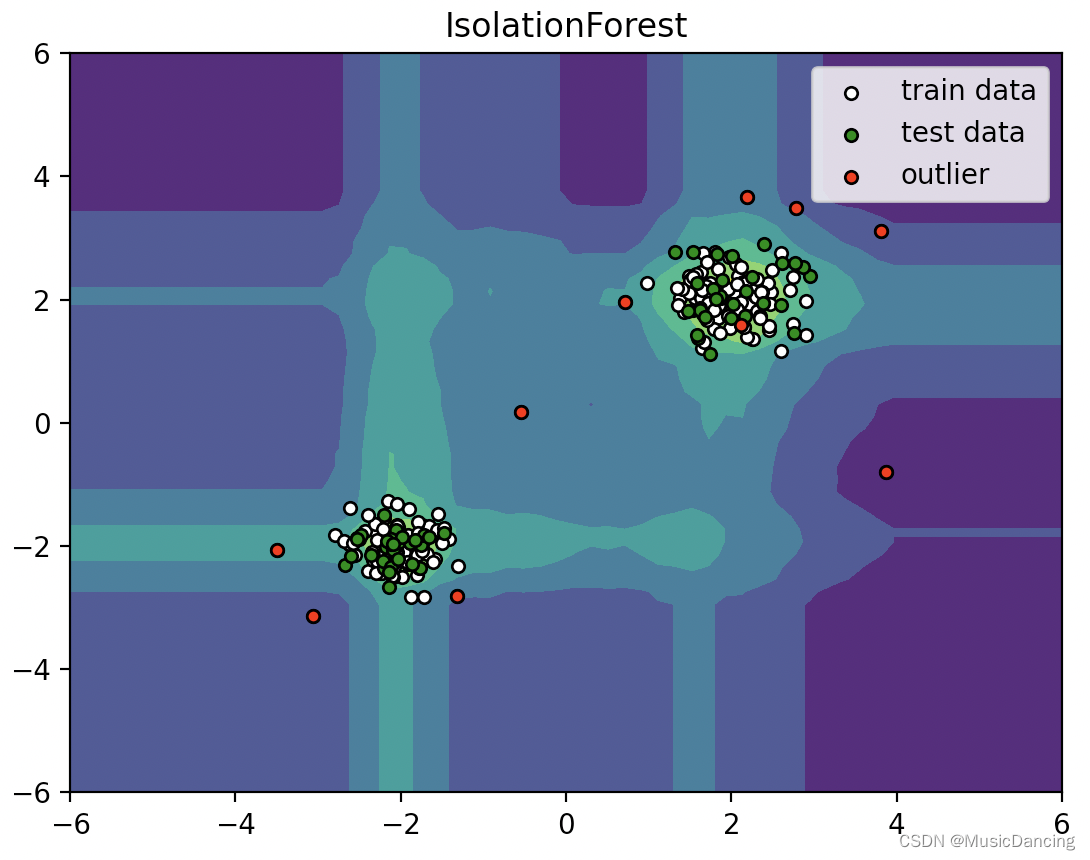
Isolation Forest 简介
1. 简介 孤立森林 iForest(Isolation Forest)是一种无监督学习算法,用于识别异常值。其基本原理是:异常数据由于数量较少且与正常数据差异较大,因此在被隔离时需要较少的步骤。 两个假设: 1. 异常的值是非常少的(如果异常值很多,可能被识别为正常的); 2. 异常值与其他值的差异较大(主要是全局上都为异常的异常,局部小异常可能发现不了,因为差异并不大)
1118. Birds in Forest并查集
1118. Birds in Forest Hash会误将这个当成两棵树,而出现问题。 例如: ① 1 2 3 ② 4 5 6 ③ 3 7 4 #include<iostream>#include<set>using namespace std;const int maxn = 10010;set<int> st;int n, m, k;int fa[maxn], cnt[ma
Java基础学习: Forest - 极简 HTTP 调用 API 框架
文章目录 一、介绍参考: 一、介绍 Forest是一个开源的Java HTTP客户端框架,专注于简化HTTP客户端的访问。它是一个高层的、极简的轻量级HTTP调用API框架,通过Java接口和注解的方式,将复杂的HTTP请求细节隐藏起来,使HTTP请求与业务之间实现松耦合。这样,开发人员可以专注于自己的业务逻辑,同时轻松处理各种HTTP请求。 Forest能够将HTTP的所有请
poj 1873 The Fortified Forest (位运算枚举 + 凸包周长)
题目链接:http://poj.org/problem?id=1873 大意:有一片N棵树的森林,要从中砍掉几棵树做成篱笆,把剩下的树围起来 输入:给N课树,每棵树的坐标是x,y,每棵树有一个vi和li分别代表砍掉这棵树的花费和砍掉后可做成篱笆的长度 输出:被砍掉树的编号(从1开始)、把剩下的树围起来后剩下的篱笆米数。 思路:暴力枚举..用01表示哪些树被砍了,维护一个可行的最小值,
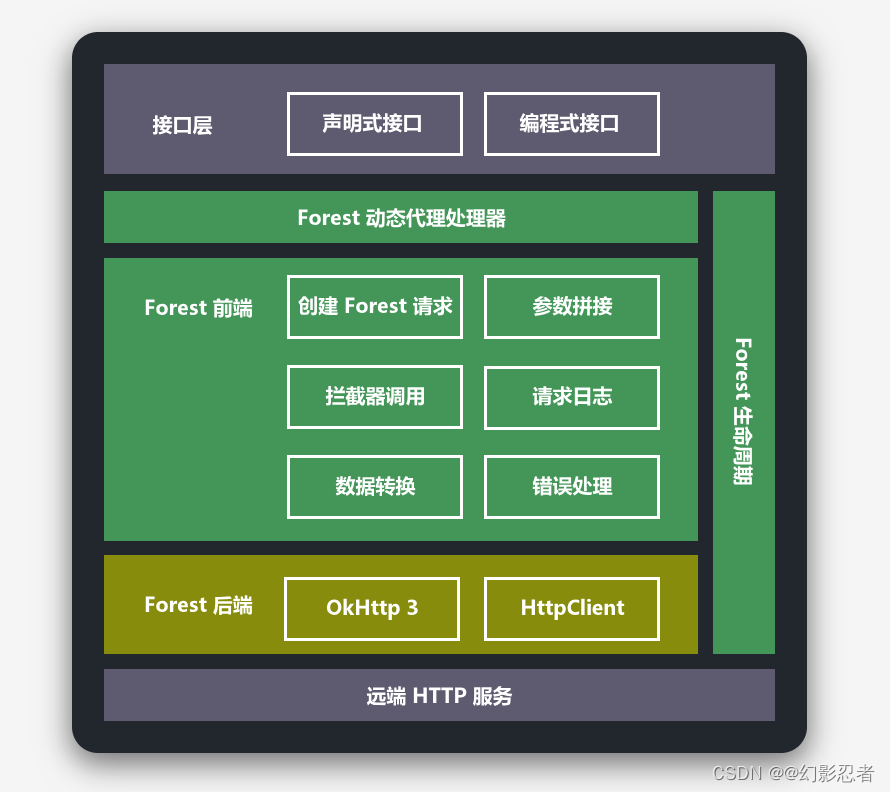

4.3.4.集成学习(一) - 袋装法(Bagging),提升法(Boosting),随机森林(Random Forest)
简介 集成学习(Ensemble Learning)是通过聚合多个分类器的预测结果来提高分类的准确率。比如,在集成学习中,会生成多个分类树模型,从中选取表现较好的那些树模型,在通过投票等筛选方式决定最终输出的分类器。在聚合算法中,以Bagging,Boosting与Random Forest(随机森林)最为典型。这三个算法,因为能够显著改善决策树的缺陷而被广泛应用。 一句话解释版本: Bag

SpringBoot整合forest(调用彩云API获取所有城市的实时天气)
Forest简介: Forest是一个高层的、极简的轻量级HTTP调用API框架。相比于直接使用Httpclient您不再用写一大堆重复的代码了,而是像调用本地方法一样去发送HTTP请求。 环境配置: 因为本项目想要将调用得到的数据存进数据库,所以我在创建springBoot项目的时候勾选了以下的模块,具体的mybatis配置请看这篇博客 除了上面的环境,还需要添加本篇博客的主题fore

Mountain Lake - Forest Pack
从头开始构建的50个岩石森林资源集合,充分利用了HDRP。还支持Universal 和Built-In。 支持Unity 2020.3+、高清渲染管线、通用渲染管线、标准渲染管线。导入包后,按照README中的说明进行操作。 Mountain Lake - Rock & Tree Pack是一个由50个准备好的资源组成的集合,从头开始构建,以充分利用高清渲染管道。这些资源经过精心雕刻、纹理化和
forest--声明式HTTP客户端框架-spring-b oot项目整合
Forest 是一个开源的 Java HTTP 客户端框架,它能够将 HTTP 的所有请求信息(包括 URL、Header 以及 Body 等信息)绑定到您自定义的 Interface 方法上,能够通过调用本地接口方法的方式发送 HTTP 请求。 官方链接: 🎁 新手介绍 | Forest 阿丹: 在之前的技术栈中没有涉及到这里,但是在近期的项目中涉及到了http请求
随机森林回归(Random Forest Regression)
什么是机器学习 随机森林回归(Random Forest Regression)是一种基于集成学习的回归算法,它通过整合多个决策树的预测结果来提高模型的性能和鲁棒性。随机森林是一种Bagging(Bootstrap Aggregating)方法,它通过对训练数据进行有放回的随机抽样(bootstrap抽样)构建多个决策树,并且在每个决策树的节点上使用随机特征子集来进行分裂。 以下是随机森林回归
随机森林(Random Forest)
随机森林(Random Forest)是一种集成学习方法,通过组合多个决策树来提高模型的性能和鲁棒性。随机森林在每个决策树的训练过程中引入了随机性,包括对样本和特征的随机选择,以提高模型的泛化能力。以下是随机森林的基本原理和使用方法: 基本原理 随机抽样: 随机森林对训练数据进行自助采样(Bootstrap Sampling),即从原始训练集中有放回地抽取样本,创建多个不同的训练子集。随机选择
![PAT甲级1118 Birds in Forest :[C++题解]并查集](https://img-blog.csdnimg.cn/20210211210241572.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoaXpoZW5nX0xp,size_16,color_FFFFFF,t_70)
PAT甲级1118 Birds in Forest :[C++题解]并查集
文章目录 题目分析题目链接 题目分析 来源:acwing 分析:并查集的合并和查询。 问:一张照片上的鸟如何合并?相邻的合并(笔者采用的方式)或者全合并到第一只鸟就行,遍历一遍。所有照片中的鸟,合并的次数累加到变量cnt中。问:如何统计鸟的数量?用一个bool数组,出现过的置为true。遍历一遍统计true的个数就是所有的鸟的数量total。问:如何统计树的数量?首先说一

Isolation Forest算法总结
一. iForest算法原理 Isolation Forest[简称iForest]由Isolation Tree[简称iTree]构成。 1. iTree 2. iForest 参考文献: [1] Isolation Forest [2] Isolation-based Anomaly Detection [3] 异常挖掘Isolation Forest:0x1
C - The Fortified Forest(凸包)
Once upon a time, in a faraway land, there lived a king. This king owned a small collection of rare and valuable trees, which had been gathered by his ancestors on their travels. To protect his trees