本文主要是介绍阿里AAAI2018论文解读:轻量网络训练框架、GAN中文命名实体识别、英俄翻译等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击有惊喜
【论文简介】像点击率预估这样的在线实时响应系统对响应时间要求非常严格,结构复杂,层数很深的深度模型不能很好的满足严苛的响应时间的限制。为了获得满足响应时间限制的具有优良表现的模型,我们提出了一个新型框架:训练阶段,同时训练繁简两个复杂度有明显差异的网络,简单的网络称为轻量网络(light net),复杂的网络称为助推器网络(booster net),相比前者,有更强的学习能力。两网络共享部分参数,分别学习类别标记,此外,轻量网络通过学习助推器的soft target来模仿助推器的学习过程,从而得到更好的训练效果。测试阶段,仅采用轻量网络进行预测。我们的方法被称作“火箭发射”系统。在公开数据集和阿里巴巴的在线展示广告系统上,我们的方法在不提高在线响应时间的前提下,均提高了预测效果,展现了其在在线模型上应用的巨大价值。
【方法框架】
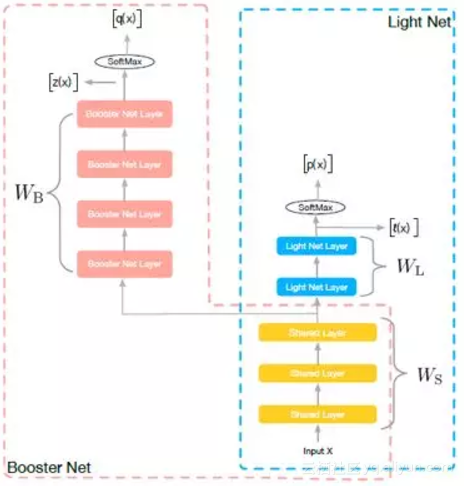
图1:网络结构
如图1所示,训练阶段,我们同时学习两个网络:Light Net 和Booster Net, 两个网络共享部分信息。我们把大部分的模型理解为表示层学习和判别层学习,表示层学习的是对输入信息做一些高阶处理,而判别层则是和当前子task目标相关的学习,我们认为表示层的学习是可以共享的,如multi task learning中的思路。所以在我们的方法里,共享的信息为底层参数(如图像领域的前几个卷积层,NLP中的embedding), 这些底层参数能一定程度上反应了对输入信息的基本刻画。
【论文链接】https://arxiv.org/abs/1708.04106
2. 基于对抗学习的众包标注用于中文命名实体识别
《Adversarial Learning for Chinese NER from Crowd Annotations》
【团队名称】业务平台事业部
【主要作者】杨耀晟,张梅山,陈文亮,王昊奋,张伟,张民
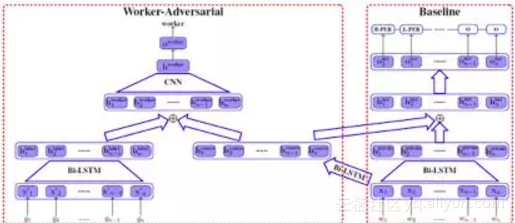
【文章简介】为了能用较低的成本获取新的标注数据,我们采用众包标注的方法来完成这个任务。众包标注的数据是没有经过专家标注员审核的,所以它会包含一定的噪声。在这篇文章中,我们提出一种在中文NER任务上,利用众包标注结果来训练模型的方法。受到对抗学习的启发,我们在模型中使用了两个双向LSTM模块,来分别学习众包标注数据中的公有信息和属于不同标注员的私有信息。对抗学习的思想体现在公有块的学习过程中,以不同标注员作为分类目标进行对抗学习,从而优化公有模块的学习质量,使之收敛于真实数据(专家标注数据)。我们认为这两个模块学习到的信息对于任务学习都有积极作用,并在最终使用CRF层完成ner标注。
【模型如下】
3. 句法敏感的实体表示用于神经网络关系抽取
《Syntax-aware Entity Embedding for Neural Relation Extraction》
【团队名称】业务平台事业部
【作者】何正球,陈文亮,张梅山,李正华,张伟,张民
【论文简介】句法敏感的实体表示用于神经网络关系抽取。关系抽取任务大规模应用的一个主要瓶颈就是语料的获取。近年来基于神经网络的关系抽取模型把句子表示到一个低维空间。这篇论文的创新在于把句法信息加入到实体的表示模型里。首先,基于Tree-GRU,把实体上下文的依存树放入句子级别的表示。其次,利用句子间和句子内部的注意力,来获得含有目标实体的句子集合的表示。
【主要方法】
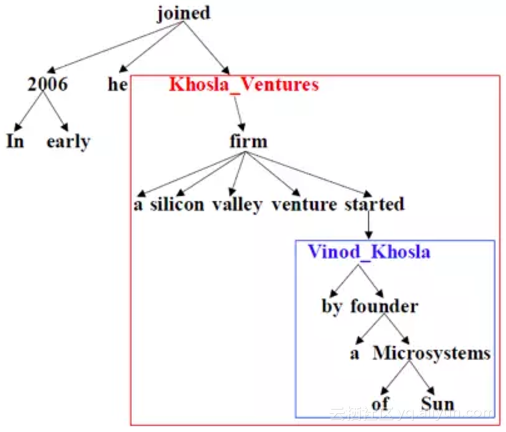
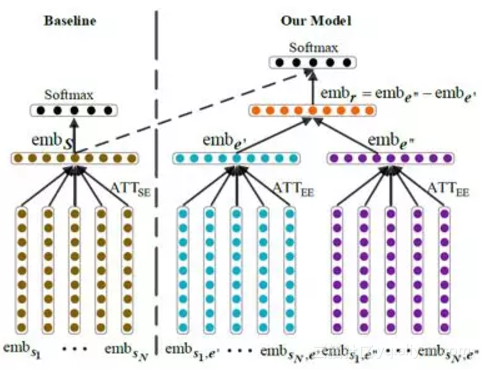
首先,基于依存句法树,利用基于树结构的循环神经网络(Tree-GRU)模型生成实体在句子级别的表示。如上图所示,有别于仅仅使用实体本身,我们能够更好地表达出长距离的信息。具体的实体语义表示如下图所示。我们使用Tree-GRU来获得实体的语义表示。
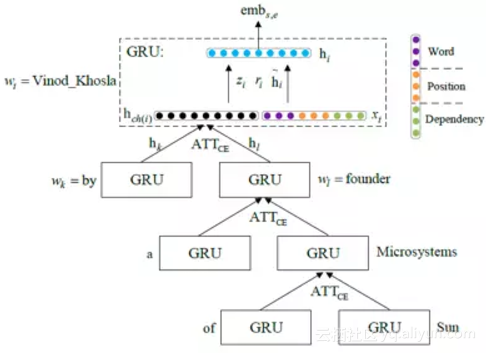
其次,利用基于子节点的注意力机制(ATTCE,上图)和基于句子级别的实体表示注意力机制(ATTEE,下图)来减轻句法错误和错误标注的负面影响。
4. 一种基于词尾预测的提高英俄翻译质量的方法
Improved English to Russian Translation by Neural Suffix Prediction
【团队】iDst-NLP-翻译平台
【作者】宋楷/Kai Song(阿里巴巴), 张岳/Yue Zhang(新加坡科技设计大学), 张民/Min Zhang (苏州大学), 骆卫华/Weihua Luo(阿里巴巴)
【论文简介】神经网络翻译模型受限于其可以使用的词表大小,经常会遇到词表无法覆盖源端和目标端单词的情况,特别是当处理形态丰富的语言(例如俄语、西班牙语等)的时候,词表对全部语料的覆盖度往往不够,这就导致很多“未登录词”的产生,严重影响翻译质量。
已有的工作主要关注在如何调整翻译粒度以及扩展词表大小两个维度上,这些工作可以减少“未登录词”的产生,但是语言本身的形态问题并没有被真正研究和专门解决过。
我们的工作提出了一种创新的方法,不仅能够通过控制翻译粒度来减少数据稀疏,进而减少“未登录词”,还可以通过一个有效的词尾预测机制,大大降低目标端俄语译文的形态错误,提高英俄翻译质量。通过和多个比较有影响力的已有工作(基于subword和character的方法)对比,在5000万量级的超大规模的数据集上,我们的方法可以成功的在基于RNN和Transformer两种主流的神经网络翻译模型上得到稳定的提升。
【词尾预测网络】在NMT的解码阶段,每一个解码步骤分别预测词干和词尾。词干的生成和NMT原有的网络结构一致。额外的,利用当前step生成的词干、当前decoder端的hidden state和源端的source context信息,通过一个前馈神经网络(Feedforward neural network)生成当前step的词尾。网络结构如下图:
点击有惊喜

这篇关于阿里AAAI2018论文解读:轻量网络训练框架、GAN中文命名实体识别、英俄翻译等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






