本文主要是介绍使用 Amazon SageMaker 为新用户提供实时音乐推荐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言
这是一篇由来自 iHeartRadio 的 Matt Fielder 和 Jordan Rosenblum 撰写的客座博文。用他们自己的话说,“iHeartRadio 是一个流媒体音频服务,每个月的用户达数千万,每天的注册人数累计上万。”
个性化是用户体验的重要组成部分,我们希望在用户生命周期中尽早提供有用的推荐。注册后直接出现的音乐推荐让我们的用户感觉到,我们可以快速了解到他们的兴趣爱好,从而降低用户流失的可能性。但是,我们如何为收听历史记录为零的用户提供个性化内容呢?

本博文介绍了我们如何利用用户在注册时提供的信息来实时创建个性化体验。虽然新用户没有任何收听历史记录,但他们通常会在注册过程中选择一些类型偏好并填写一些特征信息。我们首先显示对这些属性的分析,这可以揭示我们用于个性化的有用模式。接下来,我们会描述一个模型,该模型使用这些数据来预测每位新用户最喜欢的音乐。最后,我们将展示如何在注册后立即使用 Amazon SageMaker https://aws.amazon.com/sagemaker/ 实时提供这些预测,并将这些预测作为推荐提供给新用户,这将显著提高 A/B 测试中的用户参与度。
新用户收听模式
在构建模型之前,我们希望确定数据中是否存在任何有趣的模式,这些模式可能会表明有些东西需要学习。
我们的第一个假设是,不同特征背景的用户往往会喜欢不同类型的音乐。例如,在其他背景信息相同的情况下,一名 50 岁的男性可能会比一名 25 岁的女性更喜欢古典摇滚。如果这个假设基本成立,那么我们可能无需等待收集用户的收听历史记录即可生成有用的推荐 – 我们仅通过用户在注册时提供的类型偏好和特征信息即可生成有用的推荐。
为了进行分析,我们特别关注了用户注册后两个月的收听行为,并将其与用户在注册时提供的信息进行了比较。这两个月的时间间隔确保我们可以重点关注那些使用我们产品的活跃用户。至此,我们应该对用户的喜好有了非常明显的了解。它还确保了初始注册和营销影响都已消退。
下图中的时间线显示了用户从注册到注册后两个月的收听行为。

然后,我们比较了男性新用户和女性新用户对不同类型的收听分布情况。结果证实了我们的假设,即音乐偏好中存在与特征信息相关的模式。例如,您会注意到体育以及新闻与谈话类更受男性欢迎。使用这些数据可能会改进我们的推荐,尤其是对于收听历史记录为零的用户。
下图总结了用户性别与偏好类型之间的关系。
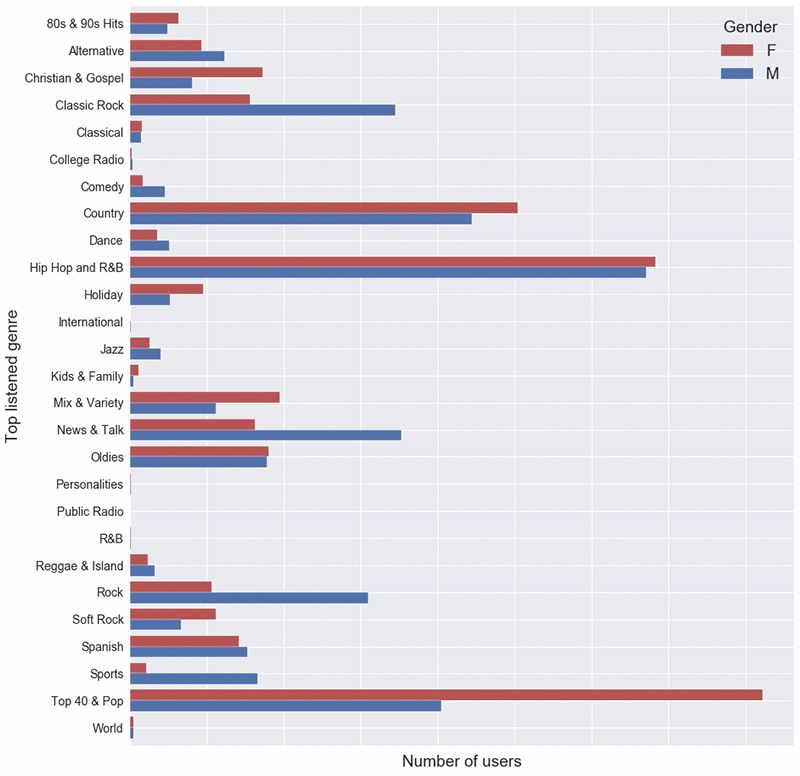
我们的第二个假设是,品味相似的用户可能会表达他们不同的类型需求。此外,与我们的用户对某一类型的理解相比,iHeartRadio 对它的定义可能略有不同。对于某些类型来说,情况似乎确实如此。例如,我们注意到,许多用户告诉我们他们喜欢 R&B 音乐,而实际上他们收听的是我们内部归类为嘻哈的音乐。这更多的是因为对类型的理解具有一定的主观色彩,不同的用户对同一类型会有不同的定义。
预测类型
现在,我们已经有了一些初步的分析证据,表明特征和类型偏好对于预测新用户行为是有用的,因此我们开始构建和测试一个模型。我们希望模型能够系统地学习特征背景和类型偏好与收听行为之间的关系。如果成功,当新用户加入我们的平台时,我们就可以使用该模型向其显示基于正确类型的内容。
与分析阶段一样,我们将“成功的预测”定义为能够呈现用户在注册后两个月会自然收听的内容。最终,进入我们模型训练数据的用户都是活跃的听众,他们有时间探索我们应用程序中的产品。因此,目标变量是用户在注册后两个月最常收听的类型,而特征是用户的特征属性和注册期间选择的类型组合。
与大多数建模练习一样,我们从最基本的建模技术入手,在本使用案例中是指多标签逻辑回归。在下面的热图中,我们抽样分析了训练模型中的特征系数及其与后续收听行为的关系。非特征模型的特征是用户在注册时所选类型的多热编码。正方形越亮(即权重越大),模型特征与用户在注册后的第二个月内收听的类型的关系越紧密。
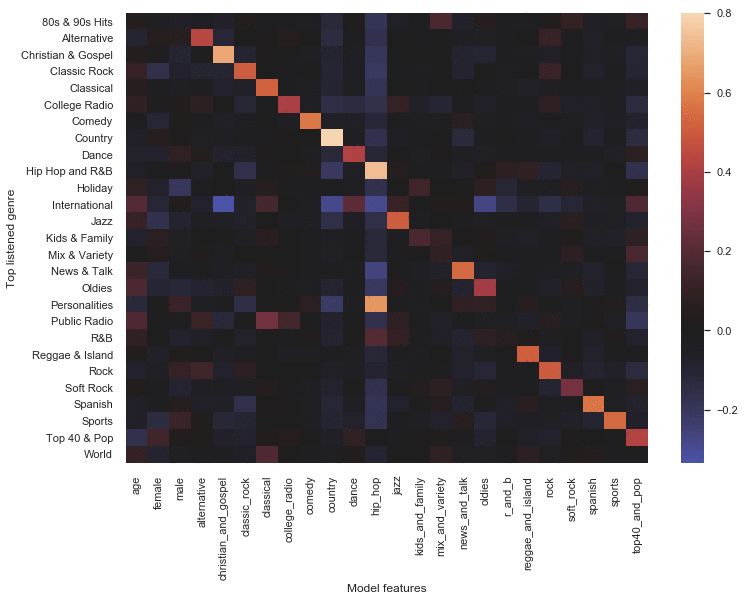
当然,我们能够识别出一些初始模式。首先,我们发现,总的来说,如果用户只选择 1 种类型时,他们最终会收听这种类型。但是,选择某些特定类型(如“儿童与家庭”、“混合与综合”或 R&B)的用户的收听趋势则不太明确。其次,有意思的是,从年龄来看,我们的模型发现年轻用户更喜欢“另类 40 大金曲与流行音乐”,而年长用户则更喜欢“国际”、“爵士乐”、“新闻与谈话”、“老歌精选”和“公共广播”。第三,让我们特别感兴趣的是,我们的模型可以了解到选择古典音乐的用户也倾向于收听“世界”、“公共广播”和“国际”类型。
逻辑回归虽然有助于探索我们的特征与收听行为的关系,但也存在几个缺点。可能最重要的是,它不能合理地处理用户选择多种类型的情况,因为线性模型中的交互是隐式相加。换句话说,它无法适当地权衡多种类型选择中的交互。对我们来说,这是一个主要问题,因为那些愿意透露类型偏好的用户通常会选择多种类型,平均会选择四种类型。
我们探索了一些更先进的技术,例如基于树的模型和前馈神经网络,这些技术可以弥补逻辑回归的缺点。我们发现,与我们构建的神经网络相比,基于树的方法可以呈现最佳结果,而且复杂性不高。与逻辑回归相比,它们还为我们提供了有意义的提升,并且不太容易发生过拟合训练集的情况。最后,鉴于 LightGBM 的速度、防止过拟合的能力以及卓越的性能,我们决定使用它。
我们很高兴看到,我们模型的离线指标明显优于简单基线。针对用户的基线推荐是他们选择的最热门的类型(无论他们的成员构成如何),这就是我们的实时内容轮播过去在应用程序中的工作方式。我们发现,根据历史离线数据,向新用户发送三种基于类型的模型建议,在 77% 的情况下都捕获到了他们实际偏好的类型。与基线相比,这相当于得到了 15% 的提升。
实时显示预测
现在我们有了一个看起来可行的模型,我们该如何实时显示这些预测呢?过去,在 iHeartRadio,我们的大多数模型都使用 Airflow https://airflow.apache.org/ 进行批量(例如每天或每周)训练和评分,并通过 Amazon DynamoDB https://aws.amazon.com/dynamodb/ 等键值数据库来提供服务。但是,在这种情况下,新用户推荐仅在我们实时评分和提供服务时才具有价值。用户注册后,我们必须立即准备根据注册信息向用户提供基于类型的相应预测。当然,我们无法预知用户的注册信息。如果我们等到第二天再提供这些推荐,那将为时已晚。这就是我们使用 Amazon SageMaker 的原因。
Amazon SageMaker 允许我们托管实时模型终端节点,这些终端节点可以在注册后立即向用户显示预测。它还提供了便捷的模型训练功能。可以使用多个选项来部署模型,包括使用现有的内置算法容器(例如随机森林或 XGBoost)、使用预构建的容器镜像、扩展预构建的容器镜像或构建自定义容器镜像。我们决定选择最后一种,将我们自己的算法打包到自定义镜像中。这为我们提供了最大的灵活性,因为截至撰写本文时,LightGBM 的内置算法容器尚不存在。因此,我们打包了自己的自定义评分代码,并构建了一个 Docker 镜像,将该镜像推送到 Amazon Elastic Container Registry (Amazon ECR) https://aws.amazon.com/ecr/ 用于模型评分。
我们屏蔽了 Amazon API Gateway https://aws.amazon.com/api-gateway/ 后面的 Amazon SageMaker 终端节点,以便外部客户端可以 Ping 它来获取推荐,同时确保 Amazon SageMaker 后端在私有网络中的安全。API Gateway 将参数值传递给 Amazon Lambda https://aws.amazon.com/lambda/ 函数,该函数依次分析这些值并将其发送到 Amazon SageMaker 终端节点,获取模型响应。Amazon SageMaker 还允许根据流量自动扩展模型评分实例。我们只需要定义每个实例每秒所需的请求数以及要扩展到的最大实例数。这让我们能够轻松地将终端节点的使用范围扩展到 iHeartRadio 的各种使用案例中。在我们运行测试的 10 天内,我们的终端节点未发生任何调用错误,平均模型延迟约为 5 毫秒。
有关 Amazon SageMaker 的更多信息,请参阅将自带算法或模型与 Amazon SageMaker 结合使用 https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms.html 、Amazon SageMaker 自带算法示例 https://github.com/awslabs/amazon-sagemaker-examples/blob/master/advanced_functionality/scikit_bring_your_own/scikit_bring_your_own.ipynb 和 Call an Amazon SageMaker model endpoint using Amazon API Gateway and Amazon Lambda https://aws.amazon.com/blogs/machine-learning/call-an-amazon-sagemaker-model-endpoint-using-amazon-api-gateway-and-aws-lambda/ 。
在线结果
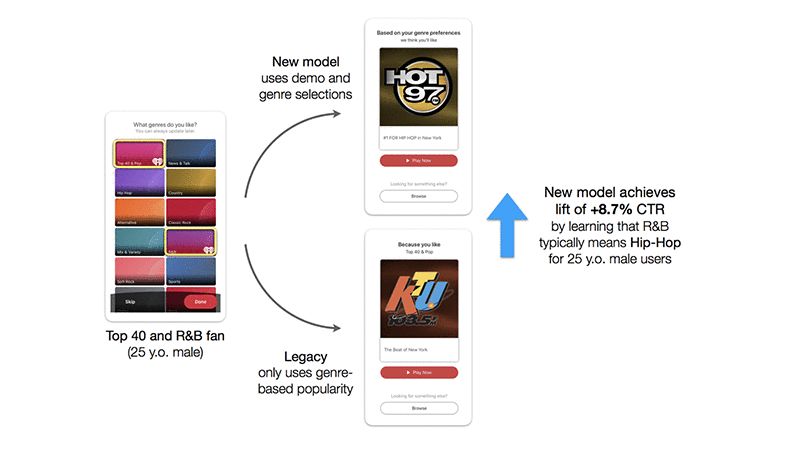
我们在上面证明了我们的模型在离线测试中表现良好,但我们也必须在生产应用中进行测试。我们使用 Amazon SageMaker 上托管的模型对其进行了测试,在注册后直接以应用内消息的形式向新用户推荐相关的广播电台。我们将这种模型与商业规则进行了比较,后者只会简单推荐归类为用户选择类型之一的热门广播电台。我们运行了 10 天 A/B 测试,对每组进行平均分配。点击了我们模型预测的用户群体对广播电台的点击率提高了 8.7%!而在点击的用户中,广播收听时间也很长。
下图显示,实时预测使得点击率比基线提高 8.7%,并举例说明 A/B 测试组的情况。
后续步骤和未来工作
事实已经表明,新用户会对 Amazon SageMaker 终端节点上托管的类型预测模型提供的相关内容做出响应。在我们的最初概念验证中,我们仅向部分新注册用户推出了这一方法。接下来需要将此测试扩展到更大的用户群,并在我们的内容轮播中为几乎没有收听历史记录的新用户默认显示这些推荐。我们还希望将这些类型的模型和实时预测的应用范围扩展到其他个性化使用案例中,例如在我们的应用程序中对各种内容轮播和磁贴进行排序。最后,我们将继续探索能够实时流畅提供模型预测的技术,包括本博文中提到的 Amazon SageMaker 以及 FastAPI https://fastapi.tiangolo.com/ 等其他技术。
感谢数据科学团队和数据工程团队在测试 Amazon SageMaker 概念验证的整个过程中提供的支持以及对该博文的有用反馈,特别是 Brett Vintch 和 Ravi Theja Mudunuru。也可以通过 iHeartMedia,在 Medium https://tech.iheart.com/real-time-music-recommendations-for-new-users-with-amazon-sagemaker-364b346d07db 上获取本博文。
本篇作者
Matt Fielder
iHeartRadio 的工程部执行副总裁
Jordan Rosenblum
iHeartRadio Digital 的高级数据科学家


听说,点完下面4个按钮
就不会碰到bug了!
这篇关于使用 Amazon SageMaker 为新用户提供实时音乐推荐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






