本文主要是介绍Tidb duration 耗时异常上升案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:顾大伟
原文来源: https://tidb.net/blog/83e8d296
背景
360网盾Tidb集群拥有120TB 的存储量,运维复杂度很高,平时出问题排查比较困难,8月24号开发反馈业务阻塞了好久了,大约8.19号开始的,反馈消费很慢,业务最近只是例行删除了几T数据,以往经验过几天就自己恢复了,影响不大,但是这次持续一周响应耗时还是逐步增加,排查分析最终通过调优Tikv 参数解决
=》 问题排查过程
① 看监控
开发反馈的业务阻塞监控,19号开始业务消费一直很慢,24号到达最高峰
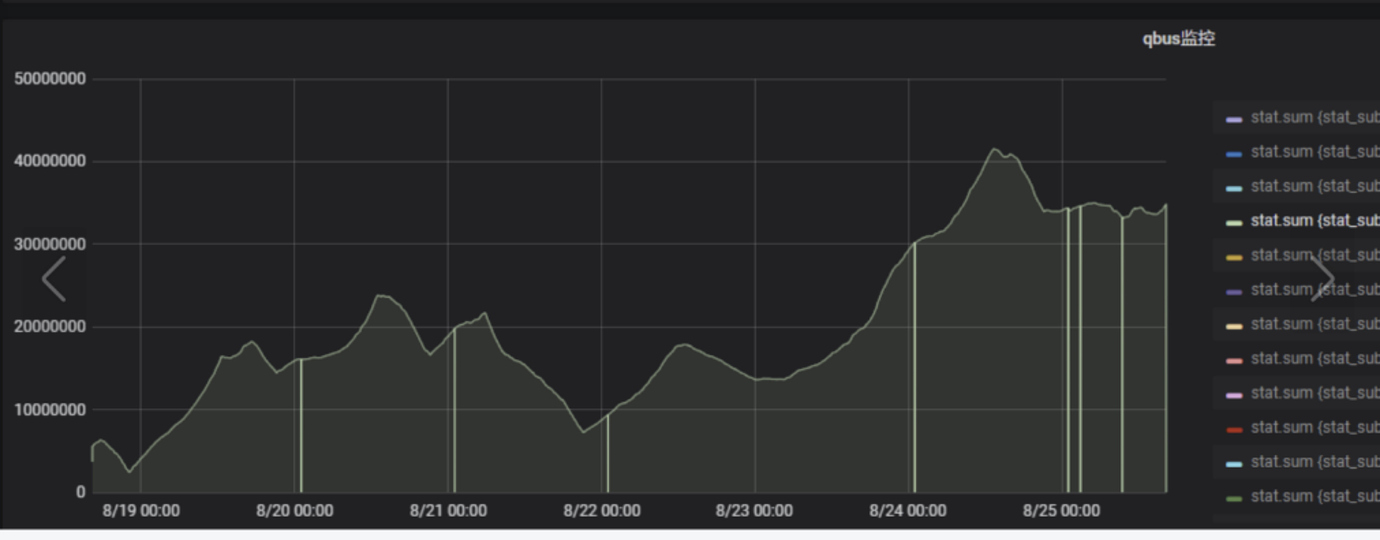
查看80 duration 耗时占用达到几百ms,明显较高存在问题\
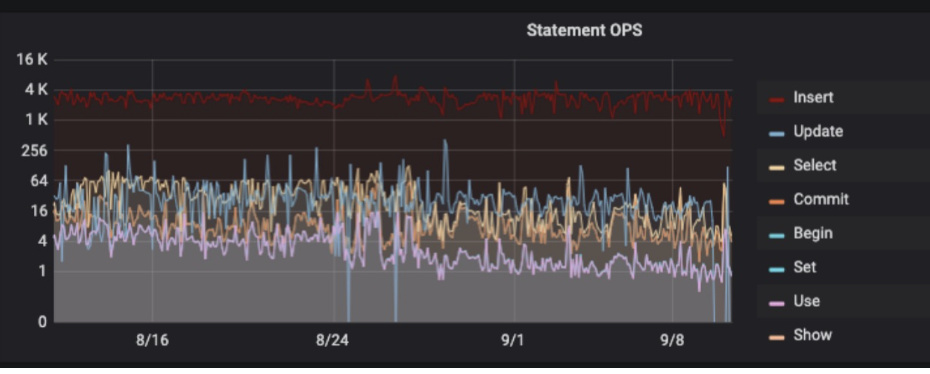
查看最近30天的TiDB-Statement OPS ,显示并没有明显的变化,说明业务确实没上新\
查看TIKV-Trouble-Shooting -Server is Busy\
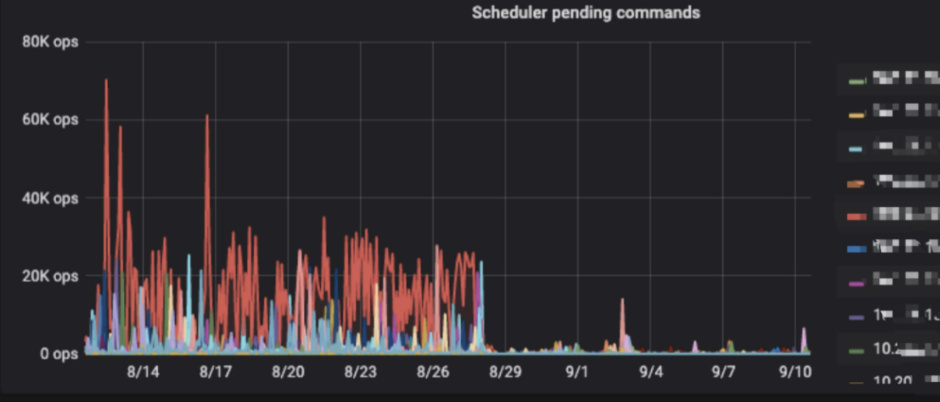
看上去是49 这台机器相对负载比较高,登陆机器查看确实系统负载比较高,同时tikv 日志显示存在大量的[error-response] [err="Key is locked (will clean up) primary_lock,存在索引写写冲突,本身tikv 每个节点region 已经20多w,官方建议不超过每个tikv 3w,超过就会出各种奇葩问题,data容量达到4TB 以上,所以系统负载一直不低,没办法机器资源不够,目前一直在删数据中…继续看监控\
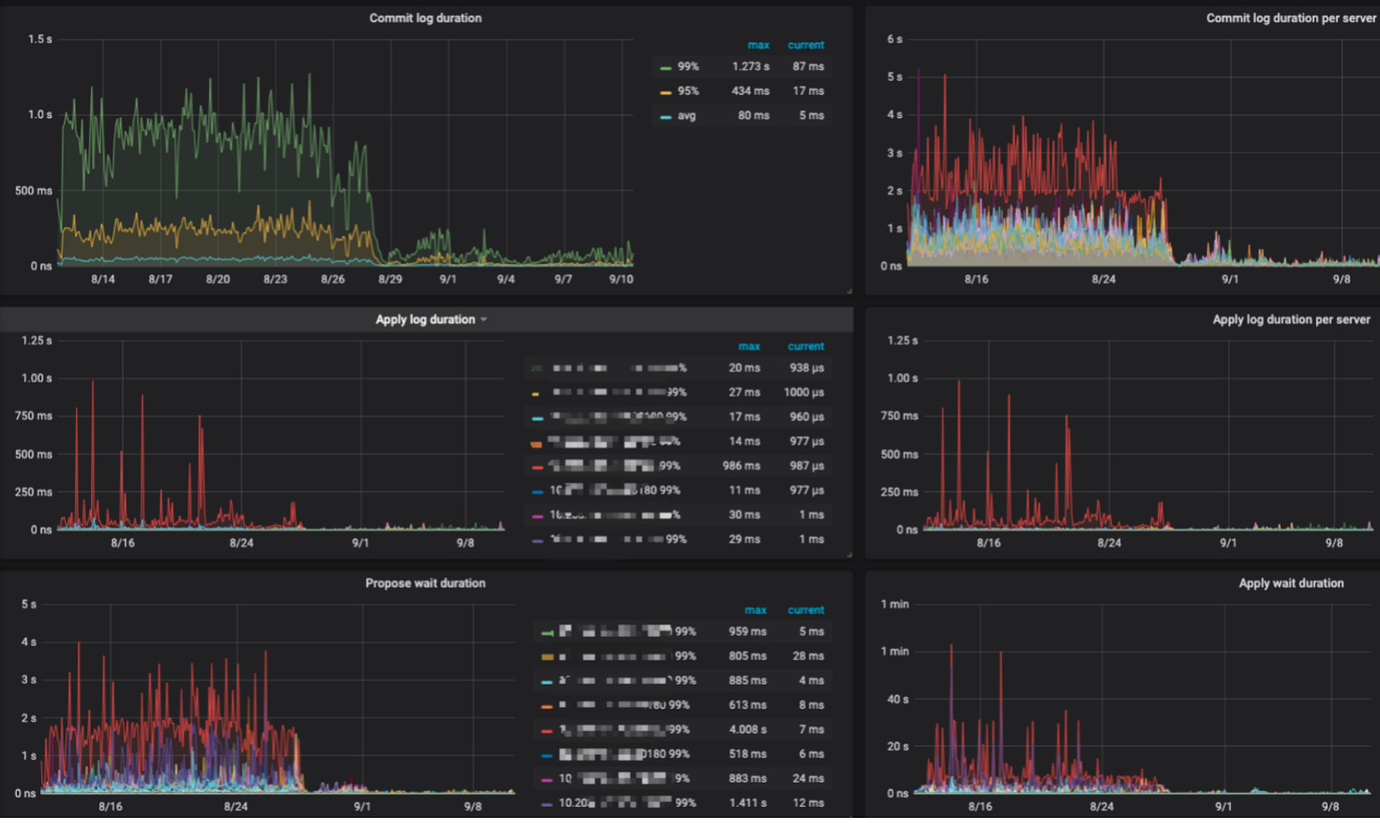
上面49节点显示commit log耗时达到2s以上,apply log 也很慢,说明Tikv 层面写入存在瓶颈,查看本节点region 个数并不存在超多现象,磁盘和cpu内存指标和其它机器一样,业务硬件问题,但是commit log 耗时严重,说明在二阶段提交的时候存在耗时严重问题,大概率和业务逻辑存在写写冲突有关系,但是目前tidb 4.x 默认是已经是悲观锁了已经很大程度降低这种情况了
版本差异
在 v3.0.8 版本之前,TiDB 默认采用乐观事务模型,在事务执行过程中并不会做冲突检测,而是在事务最终 COMMIT 提交时触发两阶段提交,并检测是否存在写写冲突。当出现写写冲突,并且开启了事务重试机制,则 TiDB 会在限定次数内进行重试,最终重试成功或者达到重试次数上限后,会给客户端返回结果。因此,如果 TiDB 集群中存在大量的写写冲突情况,容易导致集群的 Duration 比较高。
另外在 v3.0.8 及之后版本默认使用悲观事务模式,从而避免在事务提交的时候因为冲突而导致失败,无需修改应用程序。悲观事务模式下会在每个 DML 语句执行的时候,加上悲观锁,用于防止其他事务修改相同 Key,从而保证在最后提交的 prewrite 阶段不会出现写写冲突的情况。
②慢日志分析
发现大量的insert 耗时超过10s,主要耗时在prewrite 阶段和commit 阶段,这也和监控显示基本相符

③ 根据监控现象查询官方文档和asktug
https://docs.pingcap.com/zh/tidb/stable/tidb-troubleshooting-map
对照官方建议的参数调优,调整[raftstore] raft-max-inflight-msgs =2048 来增大raft的滑动窗口大小,Raft 本身是有流控机制的,当达到限制的时候会导致commit log 放缓,延时增高,默认256,所以尝试增加来看看效果
指定节点reload TIKV 参数
tiup cluster reload tidb_shbt_01 -R tikv -N xxxx
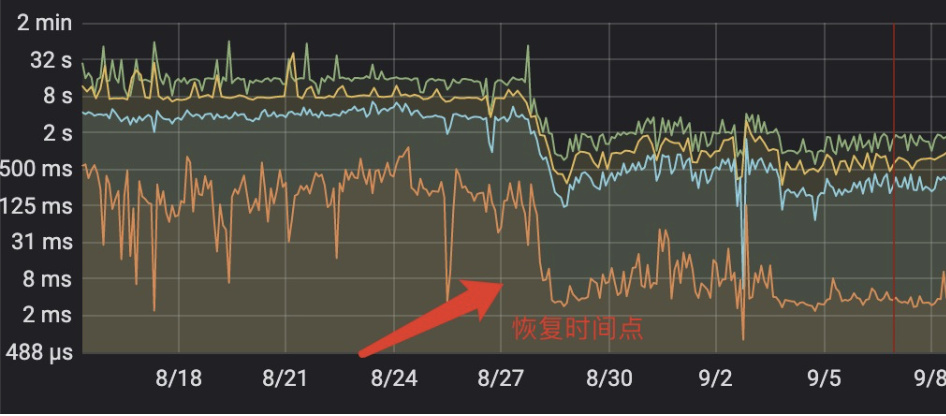
恰巧周五晚上,修改完成后,看上去duration 在逐渐降低,周末两天观察
周一业务反馈已经完全恢复了?,监控80 duation 耗时确实显著下降了 
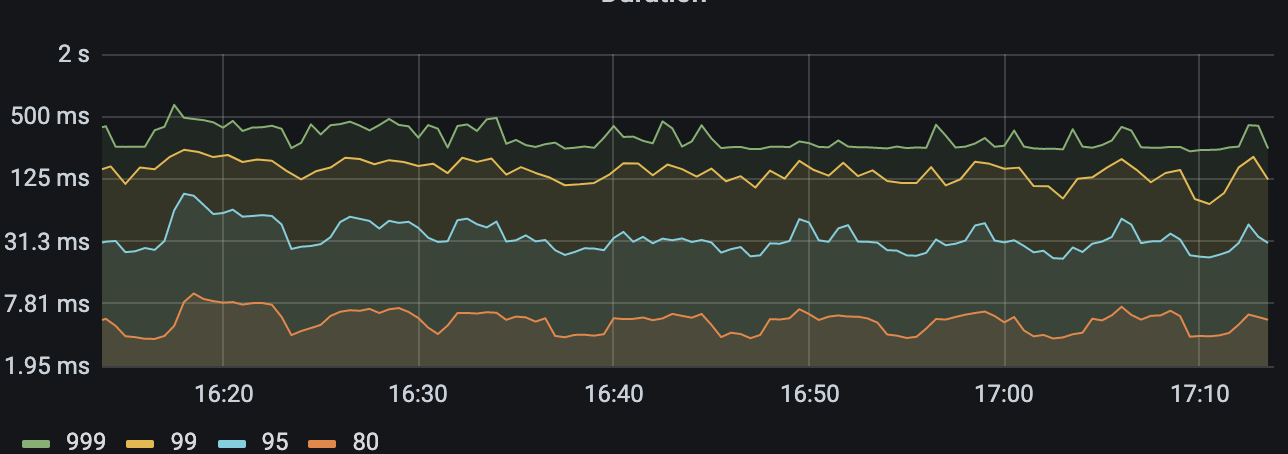
该集群同时存在大量的唯一索引写写冲突后期经过优化insert 耗时也明显提升,同时经过升级为5.7.25-TiDB-v5.0.4 后,整体集群性能提升了不止一个档次,所以建议大家及时升级到5.x的稳定版,对“内功”确实有很大提升,目前的duration 监控如下
总结:
感谢pingcap 苏丹老师在问题处理中提供的帮助,给我提供了一些问题处理思路,通过类似次问题处理,更加熟悉了Tidb,对使用运维Tidb 更有信心
这篇关于Tidb duration 耗时异常上升案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





