tidb专题

等保2.0--安全计算环境--TiDB数据库
在使用本博客提供的学习笔记及相关内容时,请注意以下免责声明:信息准确性:本博客的内容是基于作者的个人理解和经验,尽力确保信息的准确性和时效性,但不保证所有信息都完全正确或最新。非专业建议:博客中的内容仅供参考,不能替代专业人士的意见和建议。在做出任何重要决定之前,请咨询相关领域的专业人士。个人责任:使用本博客内容的风险由用户自行承担。作者不对因使用本博客内容而导致的任何直接或间接损失承担责任。版权

【TiDB原理与实战详解】4、DM 迁移和TiCDC数据同步~学不会? 不存在的!
DM工具数据迁移 1、简介 DM全称TiDB Data Migration , 支持兼容mysql协议的数据库(MySQL、MariaDB、Aurora MySQL),将数据(异步)迁移到TiDB中。支持全量和增量数据传输。可以过滤数据,可以将分库分表的数据合并迁移到TiDB中。 2、DM集群安装配置 生产最低配置(可扩容) 组件数量DM-maste3DM-worker3G

TiDB-从0到1-TiCDC数据同步工具
TiDB从0到1系列 TiDB-从0到1-体系结构TiDB-从0到1-分布式存储TiDB-从0到1-分布式事务TiDB-从0到1-MVCCTiDB-从0到1-部署篇TiDB-从0到1-配置篇TiDB-从0到1-集群扩缩容TiDB-从0到1-数据导出导入TiDB-从0到1-BR工具 一、TiCDC简介 每每介绍TiDB的组件都不得不感叹一下其强大的整体功能性。当使用MySQL还需要在下游挂

星辰考古:TiDB v2.x 回忆杀
前情回顾 在上一篇文章 星辰考古:TiDB v1.0 再回首 中,我们“回忆”了 TiDB v1.0 的内容,本文将介绍 TiDB v2.x 的相关内容。 从 TiDB 2.x 开始,正式引入 TiSpark 大数据组件,用于解决用户复杂的 OLAP 需求,或者 OLTP 和 OLAP 混合场景。 TiDB 2.x 整体架构图“升级”如下。 主要时间线 TiDB 2.x 系列在 2 年时间

爬虫场景,可以使用TiDB替代HBase吗?
爬虫场景是典型的写多读少,咱们先看看HBase和TiDB的架构,再做进一步判断。 一、 HBase主要分为Master Server,region Server的主服务,以及需要HDFS,ZooKeeper的支撑服务。 (1)Master Server用于协调Region Server,而Region Server对外提供自身大量Region单元和wals的读写访问,以及对Region的维护。一

TiDB-从0到1-部署篇
TiDB从0到1系列 TiDB-从0到1-体系结构TiDB-从0到1-分布式存储TiDB-从0到1-分布式事务TiDB-从0到1-MVCCTiDB-从0到1-部署篇 一、TiUP TiUP是TiDB4.0版本引入的集群运维工具,通过TiUP可以进行TiDB的日常运维工作,包括部署、启动、关闭、销毁、弹性扩缩容和升级TiDB集群,以及管理TiDB集群参数。相较二进制、yum等部署方式,Ti

TiDB-从0到1-MVCC
TiDB从0到1系列 TiDB-从0到1-体系结构TiDB-从0到1-分布式存储TiDB-从0到1-分布式事务TiDB-从0到1-MVCC 一、MVCC Multi-Version Concurrency Control 多版本并发控制,其主要解决了读并发的问题。 其维持一个数据的多个版本使读写操作没有冲突。也就是说数据元素X上的每一个写操作产生X的一个新版本,为X的每一个读操作选择一个版
国产数据库TiDB的常用方法
TiDB的常用方法主要涉及安装配置、数据操作、性能调优以及监控和维护等方面。以下是对这些常用方法的归纳和介绍: 1. 安装与配置 安装TiDB:根据官方文档的指引,用户可以按照步骤进行TiDB的安装。配置TiDB:安装完成后,需要对TiDB的相关参数进行配置,包括端口号、数据目录等。这些配置可以在TiDB的配置文件(如tidb.toml)中进行设置。 2. 数据操作 创建数据库和表:使用S
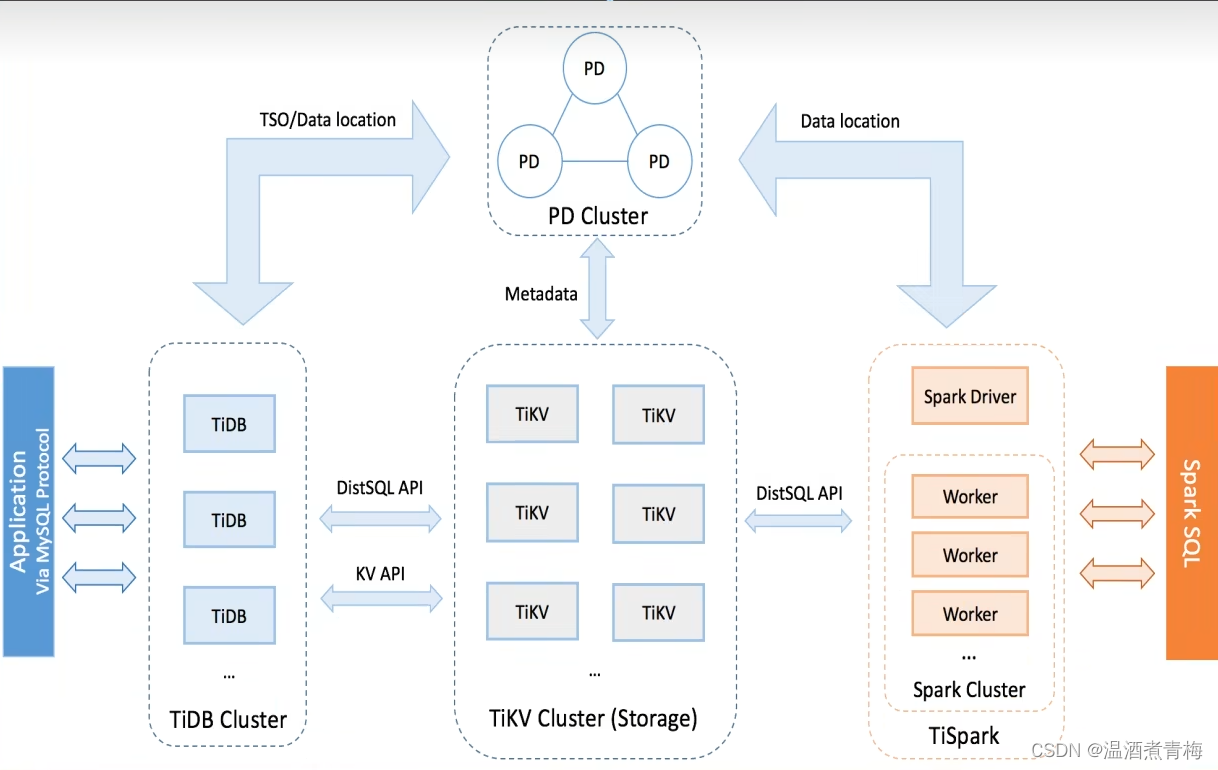
【TiDB 二】TiDB核心特性
TiDB架构组成 TiDB集群主要包括三个核心组件: TiDB Server:负责接收SQL请求,通过PD中存储的元数据找到数据存在哪个TiKV上,并与TiKV交互将查询结果返回用户PD Server:整个集群的管理者,主要存储元数据(数据库、数据表相关的信息),能够实现负载均衡、分配全局唯一的事务IDTiKV Server:负责真正存储数据,本质上是一个KV(键值型)存储引擎 此外,还有用
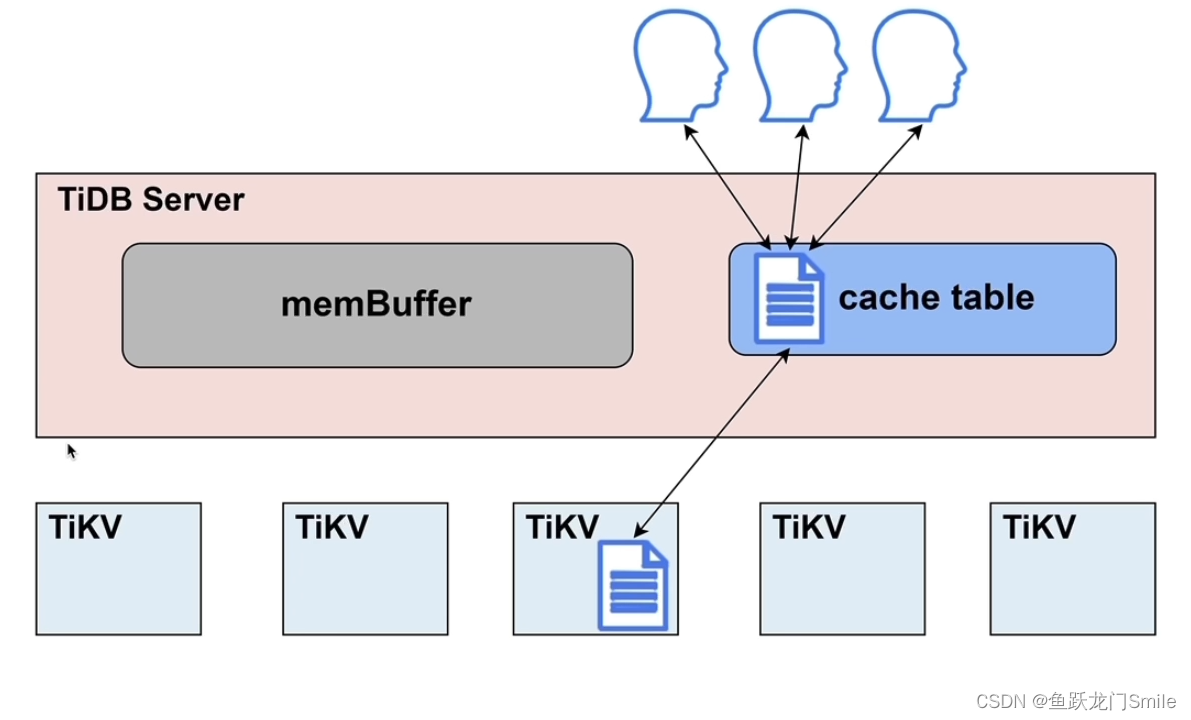
TiDB学习2:TiDB Sever
目录 1. TiDB Server架构 2. sql语句的解析和编译 2.1 Parse 编辑 2.2 compile 3. 行转化为KV对(聚簇表) 编辑4. SQL 读写相关模块 4.1 DistSQL(复杂查询) 4.2 KV(简单查询) 5. 在线DDL相关模块 6. GC机制与相关模块 7. TiDB Server的缓存 8. 热点小表缓存 9. 总结
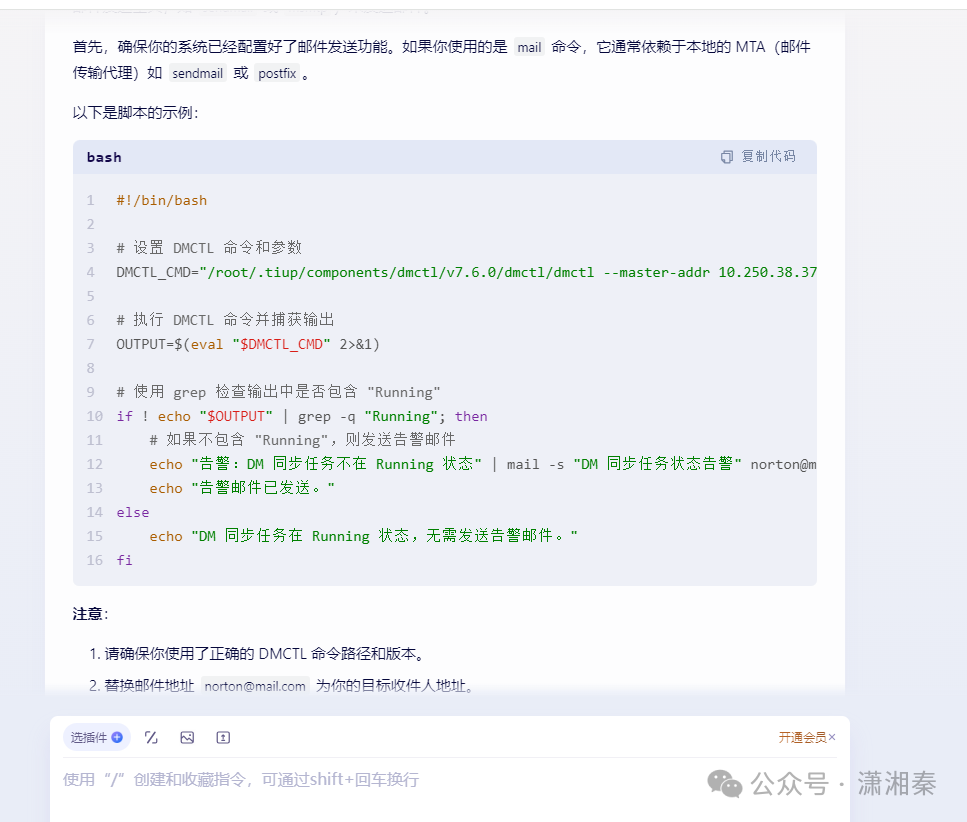
万物皆可监控(shell脚本监控TIDB-DM和DSG同步状态)
监控的方式有很多,常用的有zabbix和prometheus平台,理论上都可以做到对有状态服务的监控,因为我个人对这两个监控平台不是很熟悉,所以一般喜欢使用shell脚本来做监控; 纯oracle 数据库的监控推荐使用EMCC,具体见如下博文。EMCC13.5安装配置手册(详细版)_oracle emcc安装-CSDN博客 shell 脚本监控的优势: 简单灵活:使用Shell脚本可以快速实

TiDB系列之:使用TiUP部署TiDB集群最新版本,同时部署TiCDC的详细步骤
TiDB系列之:使用TiUP部署TiDB集群最新版本,同时部署TiCDC的详细步骤 一、部署TiDB集群二、准备环境三、安装 TiUP四、安装TiUP cluster组件五、初始化包含TiCDC的TiDB集群拓扑文件六、检查和修复集群存在的潜在风险七、查看可以安装的tidb版本八、部署 TiDB 集群:九、查看集群列表十、检查集群状态十一、安全启动十二、再次检查集群状态十三、TiDB集群管理
TiDB系列之:TiDB数据库账号权限,创建TiDB账号,创建数据库,创建表,插入数据
TiDB系列之:TiDB数据库账号权限,创建TiDB账号,创建数据库,创建表,插入数据 一、TiDB账号权限二、创建TiDB账号三、创建数据库,创建表,插入数据 一、TiDB账号权限 TiDB账号权限可以分为系统级权限和对象级权限两种,具体如下: 系统级权限: ALL PRIVILEGES:拥有所有权限。CREATE USER:创建用户。DROP USER:删除用户。RELOA
TiDB - 如何在国内编译
0: 由于天朝的特殊,在国内很不好编译(主要是依赖库下载不了)。 所以记录下编译过程 需要的工具: debian 或者其他linux其他版本。 make,git,golang(最好1.11版本以上) 编译过程 export GOPATH=/data/tidb mkdir -p /data/tidb/src/github.com/pingcap cd $GOPATH/src/

数据库|TiDB-Server API的高效应用指南
一、API介绍 1.Status 显示TiDB 连接数、版本和git_hash 信息 tidb-server_ip:status_port/status {"connections": 0,"version": "5.7.25-TiDB-v6.1.1","git_hash": "5263a0abda61f102122735049fd0dfadc7b7f822"}

TiDB 利用binlog 恢复-反解析binlog
我们知道TiDB的binlog记录了所有已经执行成功的dml语句,类似mysql binlog row模式 ,TiDB官方也提供了reparo可以进行解析binlog,如下所示: [2024/04/26 20:58:02.136 +08:00] [INFO] [config.go:153] ["Parsed start TSO"] [ts=449217508147200000][2024/0
tidb离线本地安装及mysql迁移到tidb
一、背景(tidb8.0社区版) 信创背景下不多说好吧,从资料上查tidb和OceanBase“兼容”(这个词有意思)的比较好。 其实对比了很多数据库,有些是提供云服务的,有些“不像”mysql,综合考虑下用tidb 这种环境的特点:需要本地部署在内网环境上 二、安装 安装前说明: mysql大多数都是单机安装,加一个主从,tidb是支持分布式部署的,本篇就说下单机部署,分布式部署不细说(其实也
TiDB系列之:TiCDC使用Changefeed完成数据同步任务
TiDB系列之:TiCDC使用Changefeed完成数据同步任务 一、Changefeed二、Changefeed 状态流转三、操作Changefeed四、cdc cli管理同步任务1.创建同步任务2.查询同步任务列表3.查询特定同步任务4.停止同步任务5.恢复同步任务6.删除同步任务7.更新同步任务配置8.管理同步子任务处理单元 (processor)9.同步启用了 TiDB 新的 Co
TiDB系列之:认识TiDB数据库,使用TiUP部署TiDB集群,同时部署TiCDC的详细步骤
TiDB系列之:认识TiDB数据库,使用TiUP部署TiDB集群,同时部署TiCDC的详细步骤 一、认识TiDB二、TiDB五大核心特性三、四大核心应用场景四、认识TiUP五、TiUP 生态介绍六、安装 TiUP七、安装TiUP cluster组件八、初始化集群拓扑文件九、部署包含TiCDC的TiDB集群十、执行部署命令十一、查看 TiUP 管理的集群情况十二、检查部署的 TiDB 集群情况
TiDB-PCTP考试复习
前言:本文仅作学习交流使用,对应《TiDB 数据库管理(303)》 补充:本文章仅用于个人学习,未经PingCAP书面许可,任何单位或个人不得将文档内容用于商业目的,或对本文章进行转载、编辑、发布、出售。 课堂测试汇总 Lesson 01: TiDB Cluster 部署 1.下列关于TiUP的说法正确的是?(选2项) A. TiUP 是从 TiDB 6.0 引入的包管理器 B
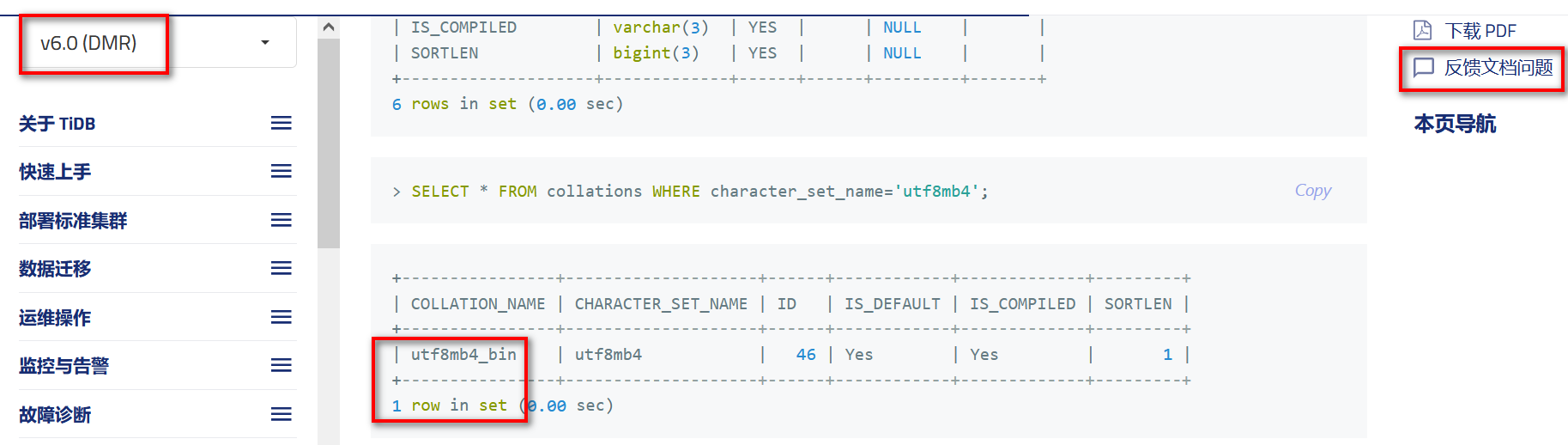
TiDB 6.x 新特性解读 | Collation 规则
对数据库而言,合适的字符集和 collation 规则能够大大提升使用者运维和分析的效率。TiDB 从 v4.0 开始支持新 collation 规则,并于 TiDB 6.0 版本进行了更新。本文将深入解读 Collation 规则在 TiDB 6.0 中的变更和应用。 引 这里的“引”,有两层含义,这第一层是“ 引言”,从 TiDB v6.0 发版说明 中可以了解到,TiDB 6.0
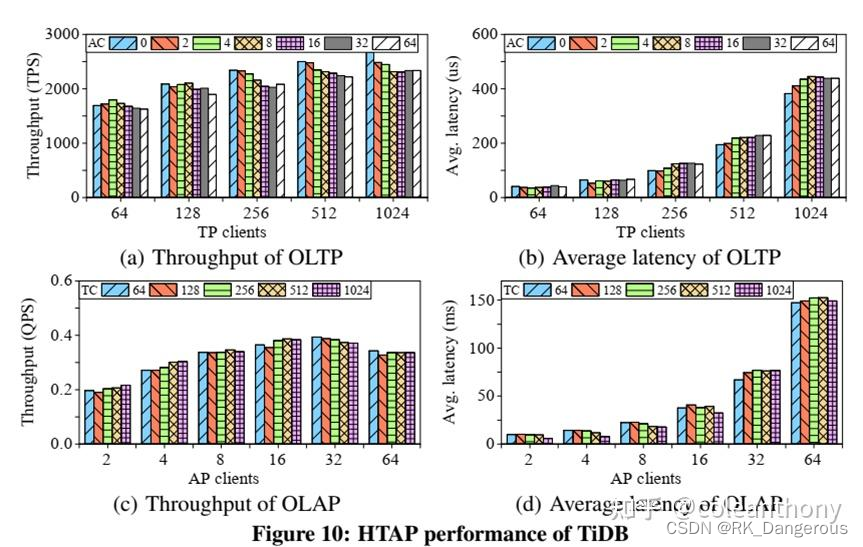
【大数据】TiDB: A Raft-based HTAP Database
文章目录 数据库知识介绍数据库系统的ACID特性分布式系统和CAP理论关系型数据库与非关系型数据库关系型数据库非关系型数据库 OldSQL、NoSQL、NewSQLOldSQLNoSQLNewSQL OLTP、OLAP、HTAP 前言:为什么选择TiDB学习?pingCAP介绍TiDB介绍TiDB的影响力TiDB概括创作背景 论文阅读:TiDB: A Raft-based HTAP Dat

2021年8月国产数据库排行榜:TiDB稳榜首,达梦返前三,Kingbase进十强,各厂商加速布局云生态
8月份的国产数据库流行度排行榜新鲜出炉。本月共有139个数据库参与了排名。 先来看看排行榜前五名。PingCAP的TiDB分数连续第二个月上涨,总分达到630.21,以136.48的分数差拉开了与第二名的差距,榜首地位不易被动摇。7月,PingCAP DevCon 2021盛大召开,同时第二期Hacking Camp也正式开启,这些铺天盖地的资讯和活动对提升TiDB流行度的作用不言而喻。
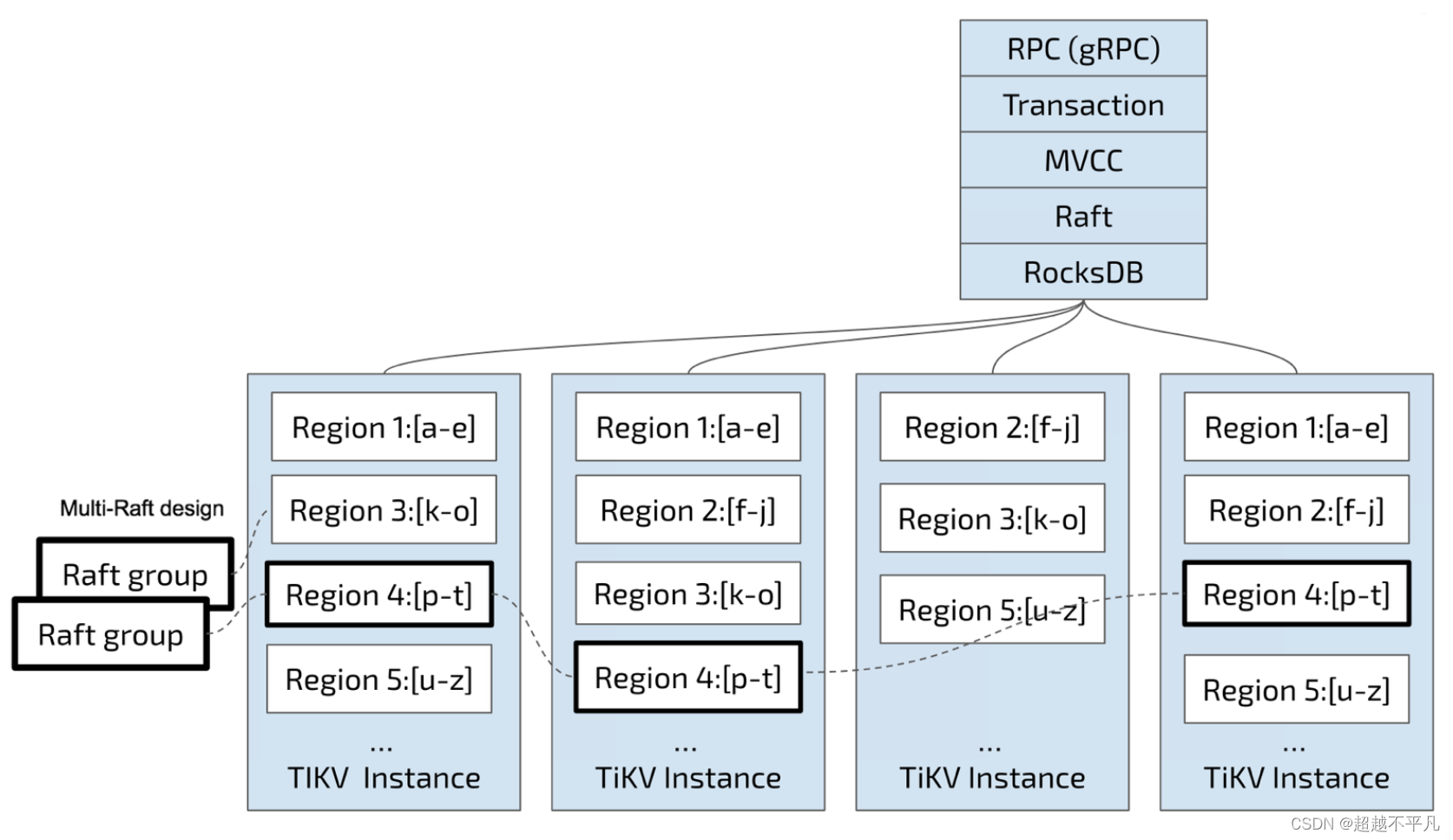
TiDB存储引擎TiKV揭秘
目录 一、TiKV 介绍 二、RocksDB 三、TiKV 与 RocksDB 架构 3.1 用户数据保存 3.2 TiKV 中 Region 一、TiKV 介绍 TiKV 是一个分布式事务型的键值数据库,提供了满足 ACID 约束的分布式事务接口,并且通过 Raft 协议保证了多副本数据一致性以及高可用。TiKV 作为 TiD

TiDB 源码阅读系列文章(十五)Sort Merge Join
什么是 Sort Merge Join 在开始阅读源码之前, 我们来看看什么是 Sort Merge Join (SMJ),定义可以看 wikipedia。简单说来就是将 Join 的两个表,首先根据连接属性进行排序,然后进行一次扫描归并, 进而就可以得出最后的结果。这个算法最大的消耗在于对内外表数据进行排序,而当连接列为索引列时,我们可以利用索引的有序性避免排序带来的消耗, 所以通常在查询优化

社区 | 如何优雅降落到 TiDB 星球?
提到「开源项目 TiDB」人们总是习惯性反应:它在 GitHub 上 Star 数已经超过 17000,并拥有 260+ 位全球各地的 Contributors 。但数据总归是冷冰冰的,不能生动的展现 TiDB 社区的魅力。所以今天推送一篇 TiDB contributor 杜川同学加入 TiDB 社区前后的「心路历程」,他从亲历者的角度告诉你—— + PingCAPer 够 nice 么?