本文主要是介绍TiDB-从0到1-MVCC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

TiDB从0到1系列
- TiDB-从0到1-体系结构
- TiDB-从0到1-分布式存储
- TiDB-从0到1-分布式事务
- TiDB-从0到1-MVCC
一、MVCC
Multi-Version Concurrency Control 多版本并发控制,其主要解决了读并发的问题。
其维持一个数据的多个版本使读写操作没有冲突。也就是说数据元素X上的每一个写操作产生X的一个新版本,为X的每一个读操作选择一个版本。由于消除了数据库中数据元素读和写操作的冲突,从而具有更好的性能。特别是对于数据库读和写两种方法,他们不用等待其他同时进行的相同数据写和读的完成。在并发事务中,数据库写只等待正在对同一行数据进行更新的写,这是现有的行级锁的弱点。同时MVCC回收不需要的和长时间不用的内存,防止内存空间的浪费。
在传统关系型数据库中,MVCC的实现方式通常还与事务的隔离级别有关。如MySQL中
- RC隔离级别下,事务中可以立即读取到其他事务commit过的readview数据(通过redo产生最新的read view)
- RR级别下,事务中从第一次查询开始,生成一个一致性readview,直到事务结束(通过undo历史链表)
二、TiDB中的MVCC
通过判断列簇中是否有主锁决定是否要读历史版本数据。
1、场景
假设test表中现在有三行数据
id:1,name:Tom
id:2,name:Andy
id:4,name:Tony
事务一:
Begin(start_ts=100)
update test set name='Jack' where id=1;
update test set name='Candy' where id=2;
Commit;(commit_ts=110)
事务二:
Begin(start_ts=115)
update test set name='Tim' where id=1;
update test set name='Jerry' where id=4;
未执行Commit;
此时TSO来到120,并分别读取test表中id=1、2、4的数据,TiDB内部是如何处理的呢?
2、数据存储逻辑
首先来看下目前TiKV中数据、锁是什么样了
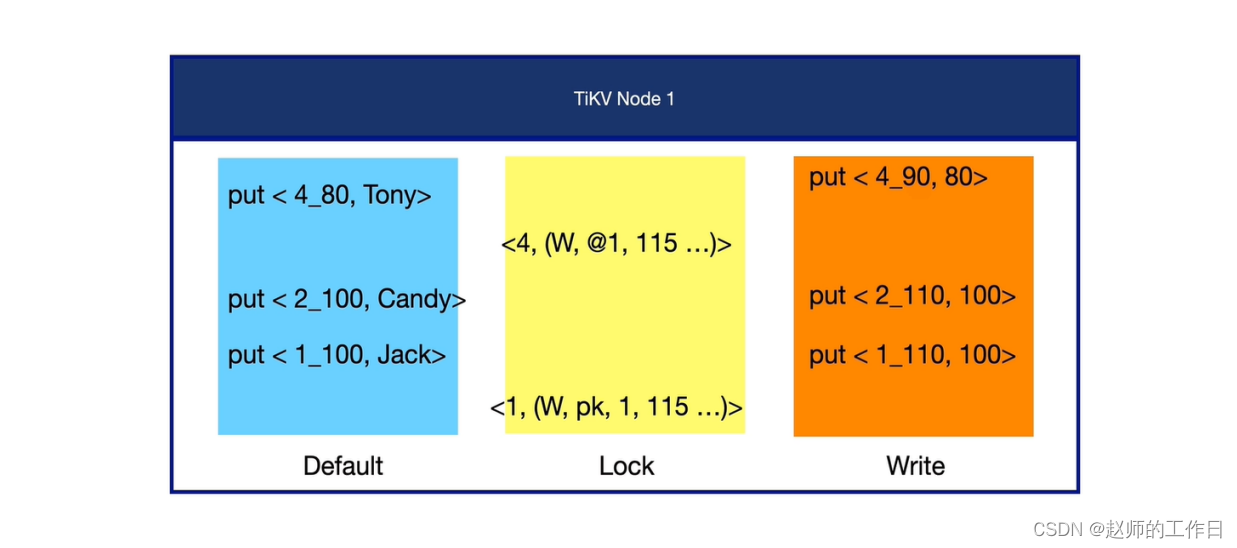
可以看到,在默认列簇中存储的是最新的Commit过的数据。
而写列簇中记录了这些数据的start_ts和commit_ts以及主键信息。
在锁列簇中记录了所有(当前、之前)的锁信息。
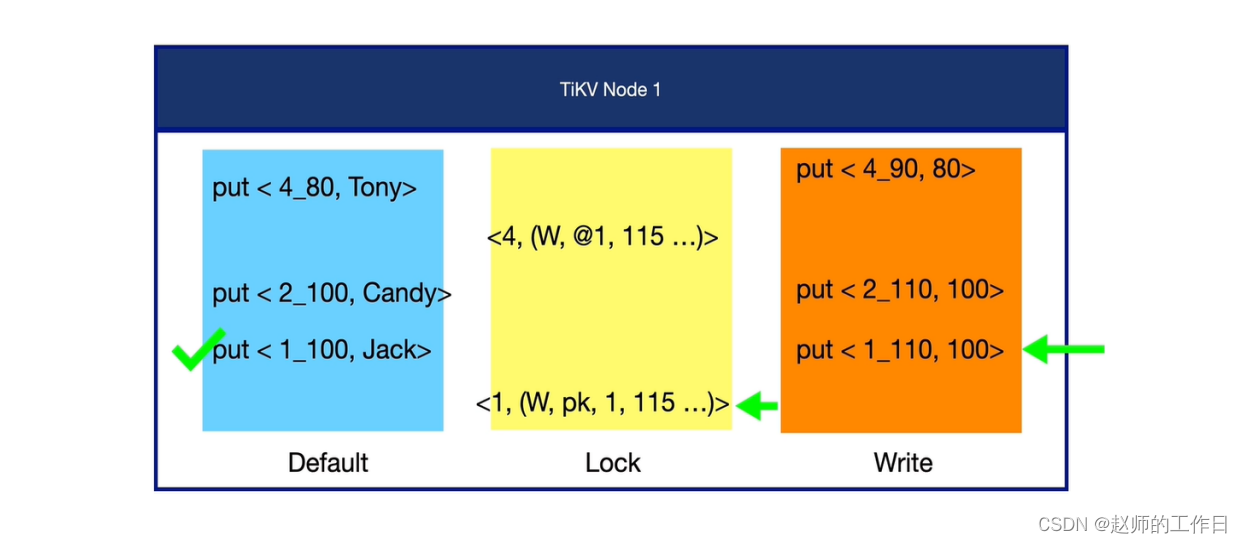
3、读取数据(id=1)
读取id=1的数据行 (从又向左,依次读取写列簇、锁列簇、默认列簇)
首先在写列簇中找到id=1的最新一条数据,这里主要目的是拿到id=1数据最后一次操作的两个TSO (可能id=1的有很多,之前说过,TiDB中数据的更新都是以插入的形式存在);
接着去锁列簇中看是否有id=1的相关锁信息:发现确实有一条,在start_ts=115时加的主锁,但是没有锁释放的数据,说明start_ts=115的事务还没有提交。这里也符合我们设立的场景(事务二未提交)。
当找到start_ts=115且没有提交锁信息,最后去默认列簇中找到TSO在115以前,id=1的最新数据 (再次强调可能id=1的有很多,因为TiDB中数据的更新都是以插入的形式存在)
最终读取到id=1的数据,name=Jack。
结果符合预期。
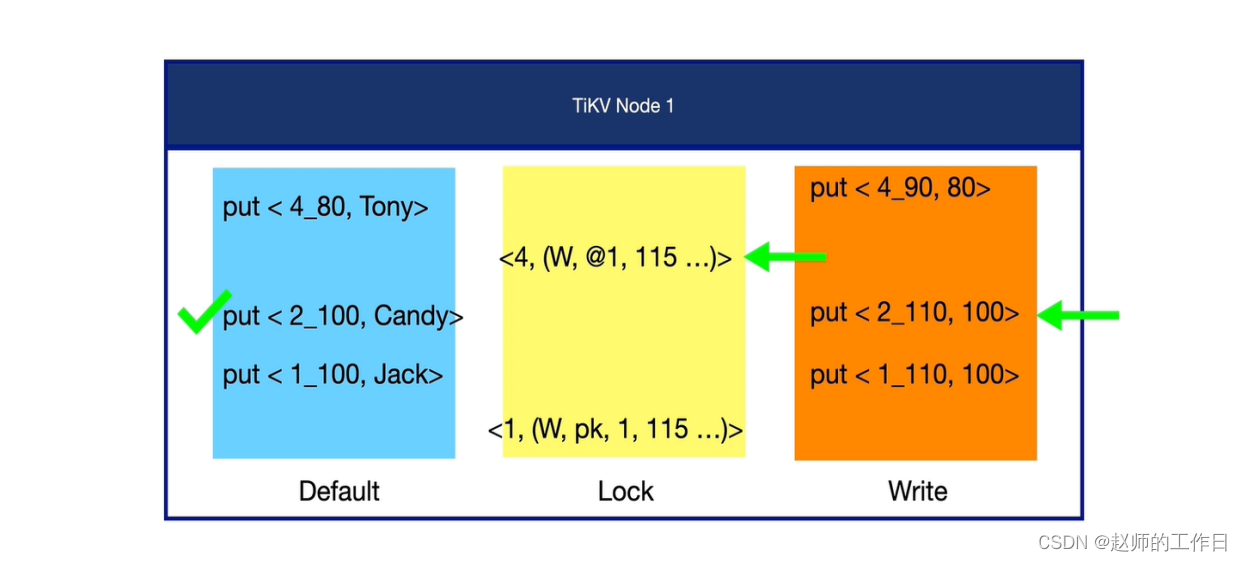
4、读取数据(id=2)
首先在写列簇中找到id=2的最新一条数据的两个TSO;
接着去锁列簇中看是否有id=2的相关锁信息:发现并没有。
所以直接去默认列簇中找到start_ts=100的id=2的数据即可.
最终读取到id=2的数据,name=Candy。
结果符合预期。
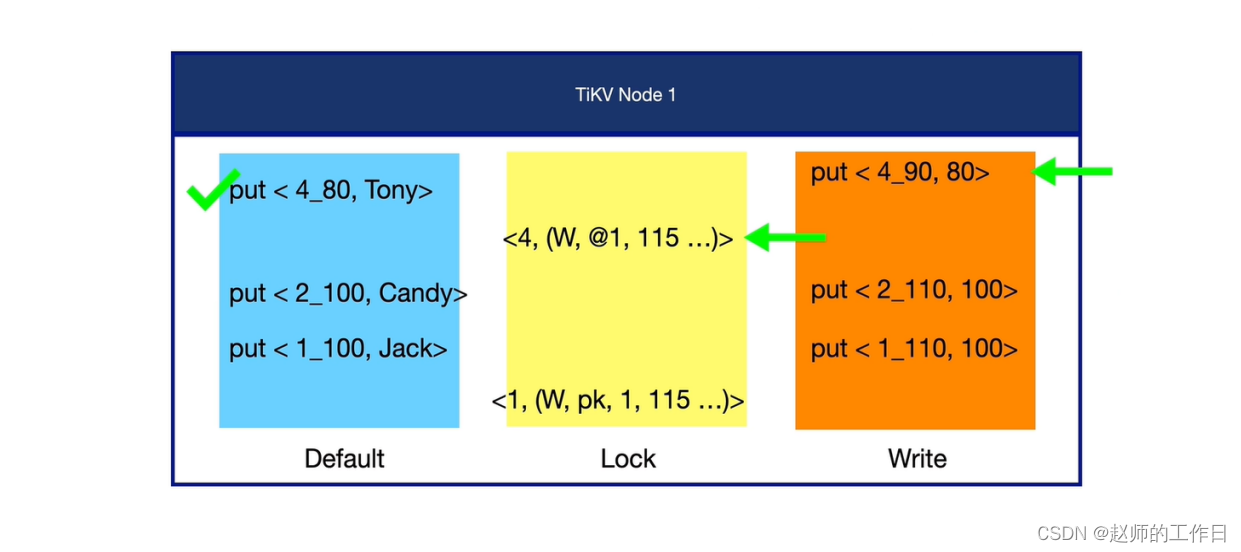
5、读取数据(id=4)
首先在写列簇中找到id=4的最新一条数据;
接着去锁列簇中看是否有id=4的相关锁信息:发现确实有一条,在start_ts=115时加的跟随锁,但是没有锁释放的数据,说明start_ts=115的事务还没有提交。这里也符合我们设立的场景(事务二未提交)。
当找到start_ts=115且没有提交锁信息,最后去默认列簇中找到TSO在115以前,id=4的最新数据
最终读取到id=4的数据,name=Tony。
结果符合预期。
彩蛋
TiDB以三个逻辑列簇+TSO版本号的方式实现了MVCC可以说非常的巧妙,但是带来的一大问题就是在高并发读写时可能存在历史版本堆积的情况,从而导致读写变慢。这时就需要控制好GC的时间来保证性能。

这篇关于TiDB-从0到1-MVCC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







