本文主要是介绍基于硬区域加权损失的可分卷积神经网络的头颈CT高危器官自动分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于硬区域加权损失的可分卷积神经网络的头颈CT高危器官自动分割
Automatic Segmentation of Organs-at-Risk from Head-and-Neck CT using Separable Convolutional Neural Network with Hard-Region-Weighted Loss
摘要
目的:从不确定的头颈部HAN CT图像中准确地分割危险器官(OAR)
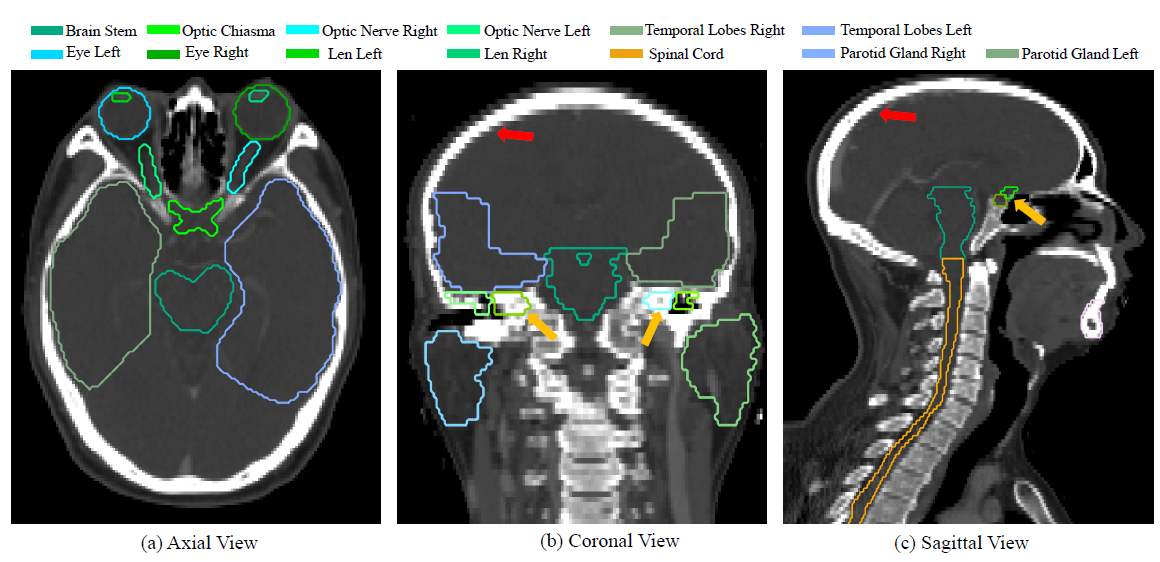
难点:CT中软组织对比度低,OAR尺寸高度不平衡,较大的切片间距。大型和小型OAR的尺寸严重不平衡,容易使自动分割偏向较大的器官,如图一所示。
解决方法:首先,我们提出了一种分段线性函数(SLF)来转换CT图像的强度;其次,我们介绍了一种新的2.5D网络(命名为3D-SepNet),专门设计用于处理各向异性间距的临床CT扫描。第三,我们提出了一种新的硬度感知损失函数,该函数关注硬体素以实现精确分割。
并且,医生不仅关心分割结果有多么精准,而且还关心预测结果的置信度。为此,还研究了一下预测中的不确定性及其与误分割的关系。
方法
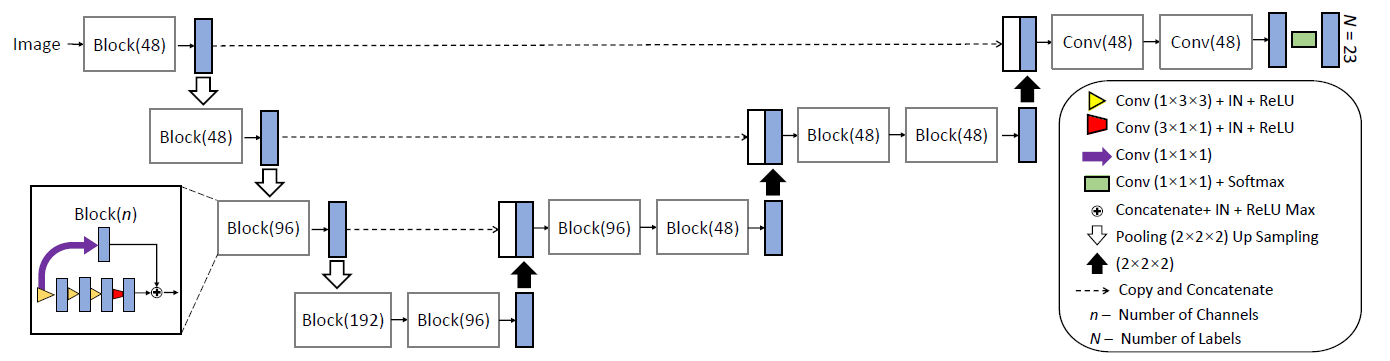
分割架构如图二所示,由4个部分组成,首先,我们使用分段线性函数(SLF)来获得输入图像的多个强度转换副本,以获得不同OAR的更好对比度。其次,对于每一份强度转换后的图像,我们采用一种结合切片内和切片间卷积的3D-SepNet网络来处理大的切片间间距。第三,我们提出了一种新的硬体素加权策略,该策略更加关注小器官和大/容易器官中的硬体素,并可以与现有的损失函数相结合。最后,我们将几个用不同的SLF和损失函数训练过的模型进行加权融合得到最终的分割结果,同时得到分割的不确定性估计

分段线性函数SLF
朴素线性函数NLF和分段线性函数SLF,原始HU值为h,变换之后强度为x,如图三所示
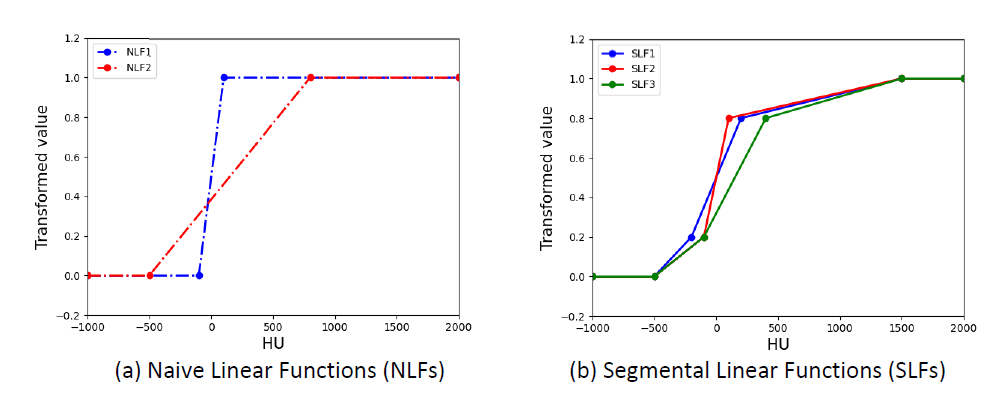
本文K取4,使用3种不同的SLF,其中[h1,h2,h3,h4]分别设[-500,-200,200,1500],[-500,-100,100,1500]和[-500,-100,400,1500]。并使用NLF1和NLF2进行了比较,分别设为[h1,h2]为[-100,100]以软组织为重点及[-500,800]设置为较大的窗口宽度。
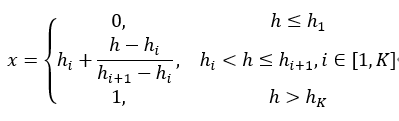
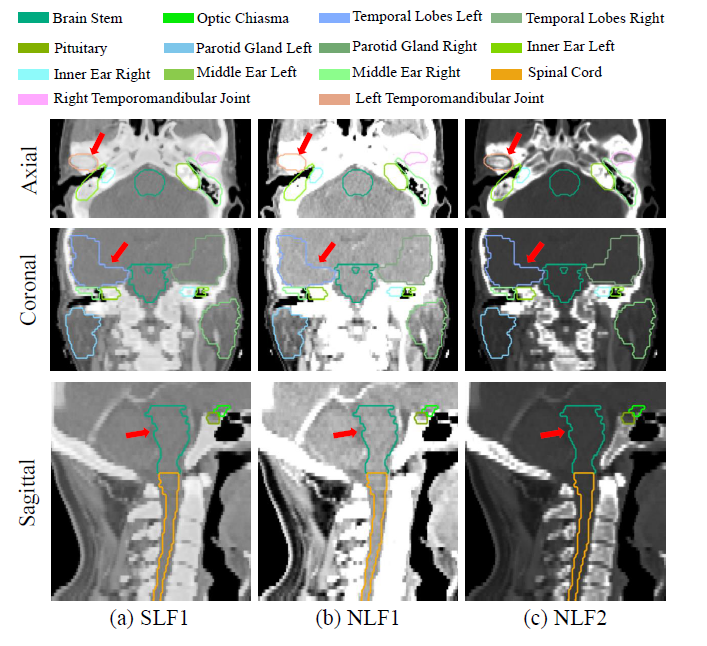
图四显示了不同强度变换公式(SLF1、NLF1和NLF2)应用于HAN CT扫描的视觉比较结果。NLF1可以抑制骨骼,提高软组织的可见性,而NLF2可以提高骨骼的可见性,但软组织难以区分。SLF1对软组织和骨骼都有较高的可见性,这有利于对具有复杂强度分布的多个OAR进行分割。
网络架构
提出了一个2.5D网络结合切片内卷积和切片间卷积来处理这个问题。如图五所示,提出的网络是基于3D U-Net的骨架。由于我们实验图像的切片间和切片内体素间距分别约为3 mm和1 mm,小器官只能穿过几片,使用标准的3D卷积会模糊其边界,并会影响精度。我们提出使用空间可分离卷积,将带有3 × 3 × 3核的标准3D卷积分离为带有1 × 3 × 3核的切片内卷积和带有3 × 1 × 1核的切片间卷积。考虑到切片间间隔较大,我们在每三次切片内卷积后再进行一次切片间卷积。在每个卷积层之后使用实例归一化(IN)和ReLU。为了更好的收敛,每个块都使用了1 × 1 × 1卷积层的跳跃连接。为了获得更好的性能,我们将编码路径中的特征映射与解码路径中的相应特征映射连接起来。最后一层1×1×1卷积与softmax函数提供分割概率。
注意硬体素
p c ( x ) p_c(x) pc(x)是体素x类别为c的预测概率, g c ( x ) g_c(x) gc(x)是对应的金标准,α>0为超参数, w c ( x ) w_c(x) wc(x)为加权函数, p c w ( x ) p_c^w(x) pcw(x)为加权预测概率。图六显示了不同α值的加权函数 w c ( x ) w_c(x) wc(x)对 g c ( x ) g_c(x) gc(x)=1和 g c ( x ) g_c(x) gc(x)=0的影响。
当 g c ( x ) g_c(x) gc(x)=1时, p c w ( x ) p_c^w(x) pcw(x)低于 p c ( x ) p_c(x) pc(x);当 g c ( x ) g_c(x) gc(x)=0时, p c w ( x ) p_c^w(x) pcw(x)高于 p c ( x ) p_c(x) pc(x)。说明加权预测比原始预测离金标准更远,加权的较硬区域会对反向传播产生较大的影响,得到更多的改进空间,使网络更多地关注硬体素,将其称为注意硬体素ATH。在训练过程中,ATH和 L E X P L_{EXP} LEXP相结合,即使用 A T H − L E X P ATH-L_{EXP} ATH−LEXP损失函数。 L E X P L_{EXP} LEXP为DSC损失和指数交叉熵的加权和。
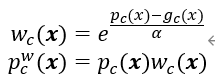

模型集成和不确定性估计
使用三种ALF和两种α=0.5和α=1进行训练
c类预测概率图和对应测试图像的权值分别表示为 p c i p_c^i pci和 w c i w_c^i wci, w c i w_c^i wci分别设为5,4,3,1,1,1。测试图像c类的最终概率图为:

假设Y(x)为体素x的预测标签,通过N个模型的预测,可以得到一组值 Y = y 1 ( x ) , y 1 ( x ) , . . . , y N ( x ) Y={y_1(x),y_1(x),...,y_N(x)} Y=y1(x),y1(x),...,yN(x),体素的不确定性可以近似为
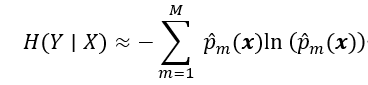
实验和结果
-
数据集
StructSeg 2019挑战训练数据集,包括50名鼻咽癌患者的CT,40张图像进行训练,其余10张图像进行测试
强度变换与损失函数的比较
定量比较:使用3种强度变换函数和3种损失函数的3D-SepNet

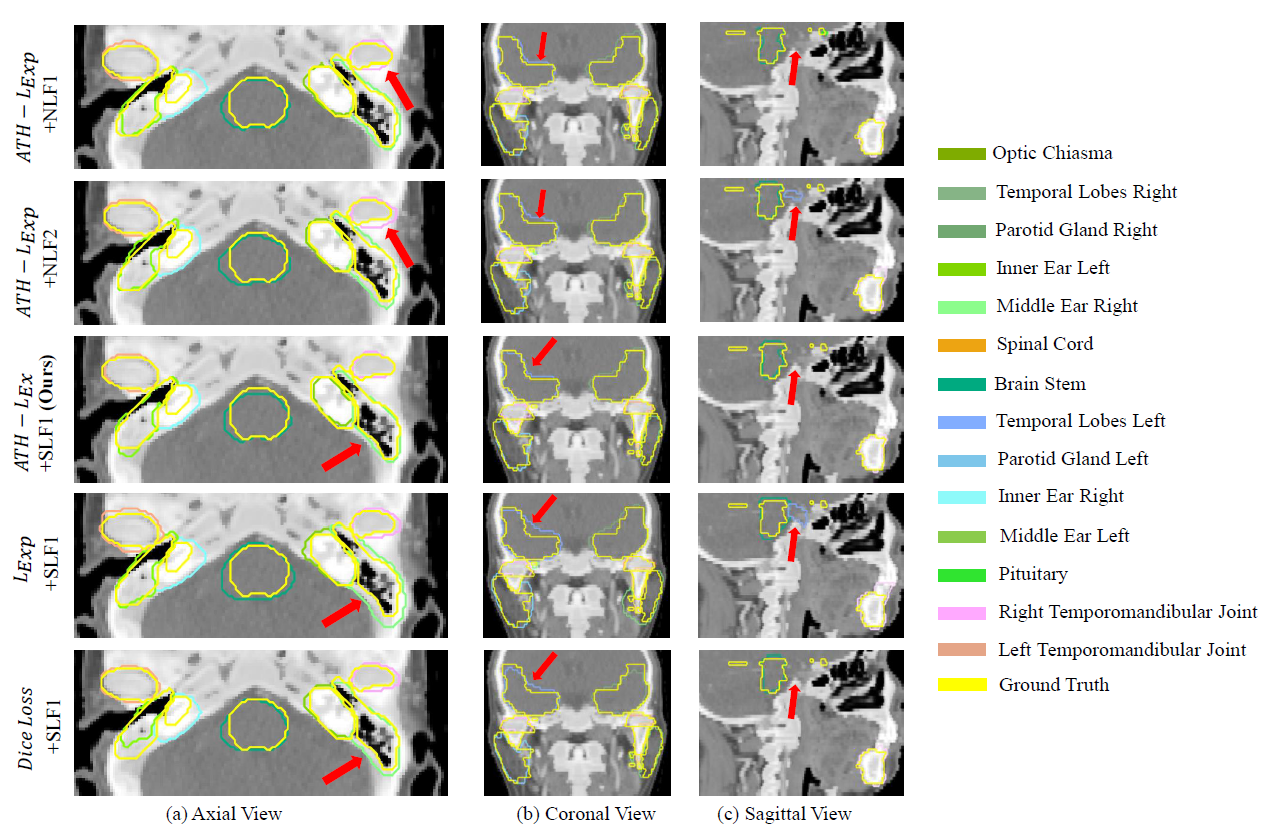
定性比较:基于上述五种模型的分割结果的可视化比较。
网络对比
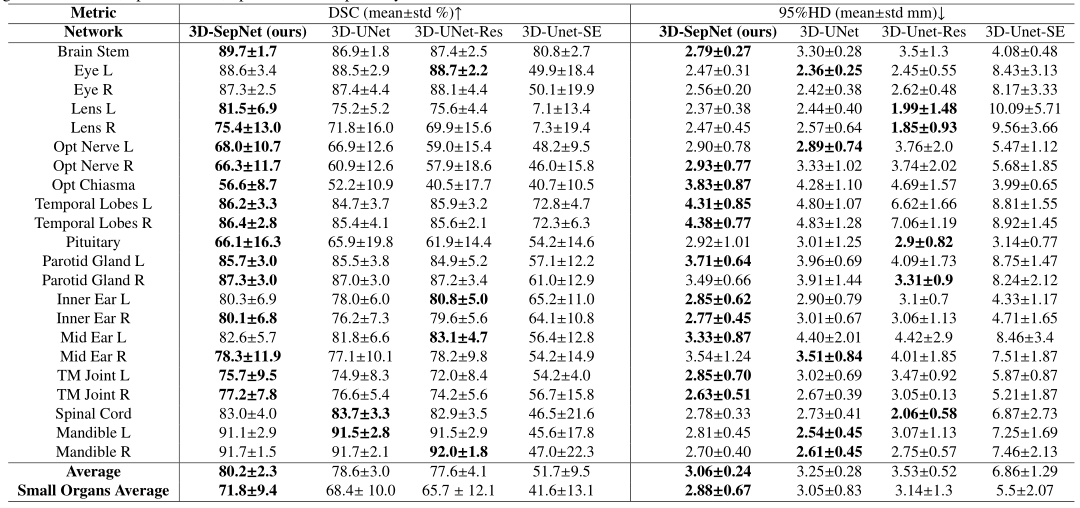
将3D Sep-Net与3D U-Net的三种变体进行比较:原始版本、添加SE块和添加残差连接。且我们的3D SepNet的参数约为3D UNet的1/3。结果如表二所示
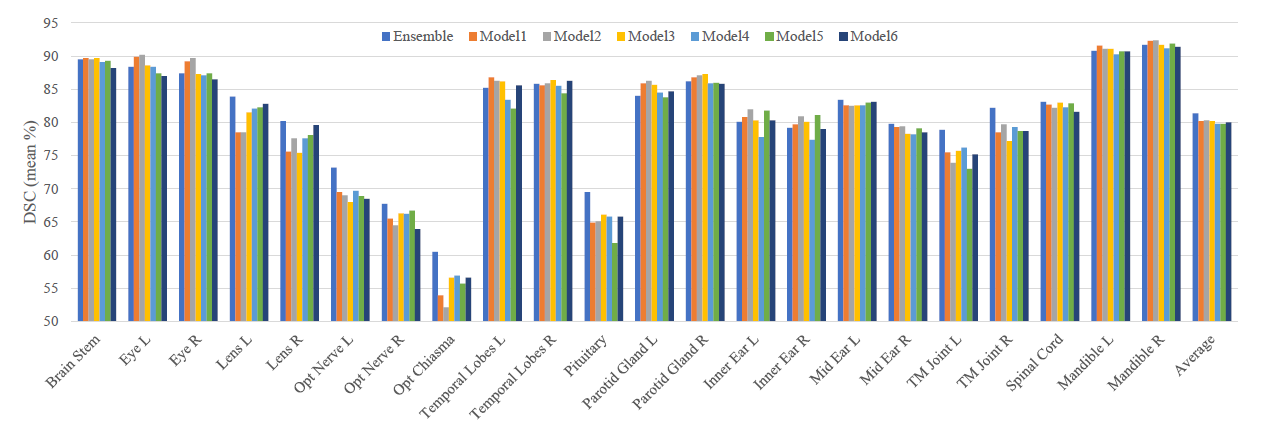
集成和不确定性估计结果
单一的强度变换函数和单一的损失函数很难实现所有OAR的最佳性能,不同的SLF和损失函数是相辅相成的。
我们的集成基于6个训练过的模型,包含三个SLF的组合,它们的损失函数为α=0.5和α=1的 A T H − L E X P ATH-L_{EXP} ATH−LEXP
图9为6种模型及其集成用于OAR的分割的定量比较。结果表明,模型集合对所有OAR的平均DSC提高了1%。对小器官如晶状体、视交叉和垂体的平均DSC提高了5%左右。
RC1Oy-1613988469503)]
结果表明,预测OAR区域中存在的不确定区域更容易出现误分割,值得关注。
这篇关于基于硬区域加权损失的可分卷积神经网络的头颈CT高危器官自动分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





