本文主要是介绍从零开始手写VIO课件逻辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一讲 概述与课程介绍
- 1-9页说的是课程的概要:第四页说了这门课主要讲什么
• IMU 的工作原理和噪声方程(第二讲)
• 视觉与 IMU 紧耦合的基础理论(第三讲)
• 从零开始实现 VIO 紧耦合优化器(仅基于 Eigen)(四讲之后) - 10-20页说的是VIO的概述:第十一至十四页说了什么是VIO,什么是IMU(组成、精度、使用场景等),和相机有什么不同,二者的优劣对比;第十五页说了这两个传感器融合有什么好处,注意IMU可以为视觉快速运动提供定位;第十六页说了VIO还可以和其他传感器融合;第十七到十九页说了两种融合方案:松耦合与紧耦合,并说了为什么选紧耦合;第二十页说了本课程要探讨的问题。
- 21-3页说了一些推导公式的预备知识:第二十二页到二十四页说了一些符号约定;第二十五到二十八页说了四元数,包括乘法法则,与角轴角度的转化公式,四元数关于时间的导数,并得到时间导数公式与四元数更新方程。第二十九、三十页分别说了旋转矩阵的导数公式与李代数上的更新方程,二十九页有一个泊松公式。第三十一到三十四讲了一些常用的雅克比矩阵推到方法,具体推导细节自己推导笔记上有。第三十五页说VIO一般不用SE(3)上进行推导,用SO(3)+t 这种形式。
第 2 讲 IMU 传感器
第二讲重要的主要是IMU的误差模型、运动模型以及离散时间方法。
第 3 讲基于优化的 IMU 与视觉信息融合
- 3-6页主要讲的是视觉SLAM中的BA问题,已知是什么(三维点坐标、位姿这些初始值是知道的,测量值是这个特征点在不同图片上的二维坐标),问题是什么,解决途径是什么;并在第六页说了以BA为基础构建VIO信息融合问题需要解决的三个问题:构建残差、 设定多个信息源的权重(就是协方差)、求解。
- 27-37页在讲如何构建残差:视觉与IMU。
第二十八、二十九页分别给出了VIO系统的残差形式与系统优化的状态量有哪些。注意二十八页中的先验残差那部分是后面滑动窗口算法才讲;第二十九页比较重要,需要注意看:视觉部分状态量只有逆深度(个数为滑窗内关键帧看到的landmark数目)。IMU部分是pvq以及ba bg,其中ba bg我们优化的是他的均值,而他本身的不确定性是在后面协方差上进行反应(误差的传递,受noise影响)。
第三十页、三十一页说了VIO视觉部分基于逆深度的重投影误差的推导:就是我们最开始初始化,初始化出来的是逆深度,根据(21)式可以得到相机坐标系下的坐标。等又来了一个观测,这个坐标就可以投影到另一个观测的归一化相机坐标系去,就得到了一个关于逆深度的重投影误差(23)式。
第三十二到三十五页在推导IMU的预积分公式,pvq的。这里面有个问题就是积分模型与预积分模型有哪些区别,用预积分模型的好处是什么。答案在33页
第三十六、三十七页把测量值引进来,根据预积分公式写出预积分误差形式,并用中值定理进行离散化,最后得到IMU误差形式。 - 38-59页在讲如何求协方差:只有IMU的协方差哦,那视觉的呢,视觉的协方差是自己设定哦。预计分量的协方差为什么要推导呢,因为一个IMU数据的方差我们是很容易标定的,但是预积分用了很多个IMU数据,所以我们需要多个IMU数据求协方差的理论。
第三十八、三十九页:总所周知,如果想对非线性系统研究,就要先以线性系统进行引入,把非线性系统理论往线性上靠,到时候一个一阶近似就好了。而这部分就是在说线性系统误差传递是什么样子:误差传递的两部分是前段时间传过来的误差与本时刻的误差。我们也可以推断,如果从第i时刻开始误差推导,那么第i时刻的协方差Σ=0.
第四十到四十五页就再建立了IMU求协方差的公式。前面说了线性系统,从这里开始说非线性系统咋往上靠的,有两种方法:基于一阶泰勒展开的误差递推方程与基于误差随时间变化的递推方程的。我们最后用第二种方法,经过推导得到公式。
第四十六到五十九说的就是上面得到的公式里面细节的推导。 - 7-26页与60-76页在讲最后一个问题:求解。求解包含两个大部分,一个是求解器与残差雅克比的计算(60-76页)。7-26页先主要讲了一下这个最小二乘问题的求解过程,并计算了几种求解器,当然后面我们也要介绍舒尔补加速的这种方法。
第八到十二页讲了最小二乘问题在线性系统的情况下是怎么处理的。首先他有一个F(X)这是一个cost function,然后主要的想法是对这个F(x+δx)进行泰勒展开,并提出了下降法、牛顿法与阻尼法三种方法求解这个问题。
第十三页开始谈非线性最小二乘问题,注意这里是对非线性的残差进行的泰勒一阶展开,而不是线性系统的对cost function进行展开,但观察(7)式可以发现这种对残差进行一阶泰勒展开整理后和对cost function二阶泰勒展开式子接近,所以我们就和线性系统凑上了,按照线性的求解方法凑呗。后面提出了GN与LM方法求解,其中包括LM方法中阻尼因子的选取方法与更新策略。第二十一到二十五页主要在说鲁棒核函数,对它怎么实现进行推导,注意(17)式非常重要,编代码就在这里编。
第60-76页在讲残差雅克比矩阵的推导。

第4讲 基于滑动窗口算法的VIO系统:可观性与一致性
- 首先说了SLAM问题的概率建模,主要还是多次观测似然转化为后验估计,然后去-log转换为最小二乘问题;这里的区别主要是针对多元的高斯分布问题,协方差或者说信息矩阵会怎么变化呢?是对上节课中协方差问题的引申(多元),与此同时带出来的问题就是:既然多元了,之后如何丢弃变量。
- 借助了两个样例说明协方差矩阵以及信息矩阵中零元素对应变量之间什么关系,是否有相关性的问题。
- 接下来说如果移除变量,协方差矩阵以及信息矩阵怎么变?解答了第一部分引出来的问题。(协方差直接去掉就行,信息矩阵需要进行边缘化与舒尔补才行)。
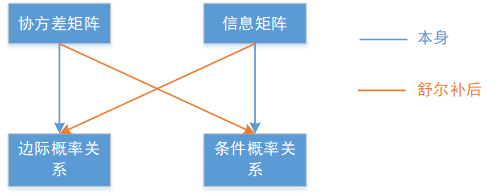
- 17页-19页说了舒尔补的定义,如何推导出的定义,以及舒尔补的好处是啥(快速求解矩阵M的逆,你可以想着这个M是协方差矩阵,那么容易求他的逆也就容易求他的信息矩阵)。20页开始说舒尔补在多元高斯分布中的应用了,你想着本身有一个P(a,b) 他的协方差矩阵为K,信息矩阵也就是K-1了,那么对这个多元高斯分布进行舒尔补后得到一个边际概率P(a)与条件概率P(a|b),那这两个概率的协方差矩阵和K有什么关系(22页),信息矩阵和K-1又有什么关系呢(24页),然后在25页举了个例子。
PS:其实分解出边际概率很重要,我们想去除某个变量,例如P(x1,x2,x3)想去除x3,我们要算的东西是从P(x1,x2,x3)的信息矩阵中算出P(x1,x2)的信息矩阵,那你看这东西不就相当于把P(x1,x2,x3)进行舒尔补操作后得到一个P(x1,x2)这个边际概率与一个P(x1,x2|x3)这个条件概率。所以要注意边际概率的信息矩阵与原信息矩阵的相关性与计算方法是十分重要的(24页25页多看看) - 第三小节说了滑动窗口算法:27页到34页,28页给出了最小二乘模型,注意ri那里指的是残差,并给出了多元边这个例子;29页说了乘上雅克比的信息矩阵与普通协方差逆的信息矩阵分别代表的含义:前者表示求解的方差,即测量的不确定性;后者表示残差的方差;30-31页给出了信息矩阵(乘上J的)求法,在求出雅克比之后,用累加方法加出来的,注意稀疏性。32-33页说了为什么要用滑动窗口以及怎么去除旧变量,这就涉及前面所讲的边缘概率了,也就是24-25页的知识。34页给了个例子说明怎么操作。
- 第四小节说了滑动窗口算法引入的可观性问题以及FEJ算法。36-39页举了一个例子来说明滑窗会出现的问题
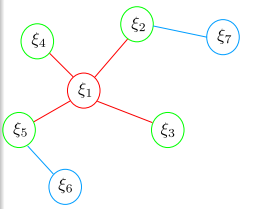
就是说这个系统假如在K时刻想要marg掉ξ1,这用舒尔补之后会对ξ2ξ3ξ4ξ5造成影响,遗留下来了先验信息,而且这部分先验信息用的雅克比矩阵还是K时刻雅克比,但是ξ2ξ5后面还要连着ξ6ξ7,这两个连接部分就出问题了,ξ2ξ5在后续和ξ6ξ7更新中肯定要算新的雅克比,比如K’时刻的雅克比,但是他俩在先验信息那部分用的还是K时刻的雅克比,这就让算信息矩阵这操作变成了两部分
40-42页说上面这变成两部分了造成啥影响呢,就是零空间发生变化了,引入错误信息了,就是不可观的东西变成可观的了。不可观可能的理解就是对于一个情况是有一些解的,可观可能就一个解了。关于41页的图在DSO公开课笔记里面有描述。
43页说了单目相机与单目相机+IMU分别对应几个自由度不可观。44页说了FEJ算法,就是让K’时刻还用K的雅克比呗,大体就这意思,雅克比不变但姿态更新。这种算法是在线性化误差与一致性中间取折中,如果非线性化严重的场所就不必要用FEJ,可能造成线性化误差过大,得不偿失。
第 5 讲 后端优化实践:逐行手写求解器
- 1-5页主要讲的是最小二乘问题的solver求解器流程:建立误差函数→计算雅克比→使用第四讲的方法累加计算信息矩阵→写出Hδx = b的形式→进行舒尔补加速求解→迭代求解→更新状态量x;第4页说了舒尔补是如何加速求解的:把δx分成pose部分与landmark部分,先求出pose部分δx,然后再求landmark部分δx。第6页说了solver中的一些问题,比如H矩阵不满秩怎么办 如何实现fix操作 这些 比较重要。
- 第9页 第12页 第14页比较重要。9页说了marg的两种形式:滑窗用的marg与加速用的marg;12页说了在滑窗marg中一个很重要的问题,就是marg后虽然先验信息矩阵保持不变,但是他的那些先验残差必须跟着更新(残差在b里,希望记住),怎么更新就在这页PPT中。14页里面有个加阻尼的比较重要。
第 6 讲 前端 Frontend
- 第一节(2-10页)在说前端的工作。第2页说了SLAM框架借此引出前端,第3页说了前端有的问题:步骤(初始化、追踪、重定位)、参数化、关键帧选取;4-7页开始说与后端相比,前端对SLAM系统来说更重要;8-10页开始说了前端的不同方法的定性比较与优缺点,注意第10页说的直接法实现效果与选点数量关系较大。
- 第二节(11-19页)说特征点提取与匹配。12-15页在说特征点的提取:12页说了一个双目与RGBD直接就可以初始化的知识点,当时为什么就不注意呢;13-15说了角点提取,说了Harris、Fast、GFTT这些角点提取方法,注意每一个像素周围小块都是要计算梯度分布以及det与trace(可以多看看)。16-19在说光流跟踪:16页说了光流跟踪的光度不变假设(注意推导出来的式子,之前都不注意),17页说了Warp function光流(可以一看),18页说了金字塔光流,适用于运动比较快的情况,19页说了光流在SLAM中的应用以及局限性,其中局限性说的挺全的,可以多看看
- 第三节(20-29页)说关键帧与三角化:21-24页说关键帧,说明了一些问题:为什么要选择关键帧(后端实时性差;相机不动的话),如何选取关键帧:这里面需要注意VIO来说,应该定期选择关键帧,如果相机不动的话按理说不插入关键帧,但是IMU有ba与bg 的影响,不插不行。其中需要注意几点:后端只优化关键帧,非关键帧不优化;24页DSO的插入关键帧策略。25-31页说了三角化:25页比较重要,26-31需要自己推一下

第 7 讲 VINS 初始化和 VIO 系统
- 3-6页首先回顾了VIO的相关知识,第四页单说了IMU的相关知识:①传感器模型(就是w a的模型) ②IMU的预积分,得到pvq ③IMU协方差的传递,说了怎么计算协方差。 第五页说了视觉相关的知识:注意视觉内部尺度是统一的。 第六页引出问题,他们这两部分要如何联系起来呢:他俩之间的外参怎么算;IMU与世界坐标系怎么对齐;他俩的轨迹怎么对齐,也就是尺度怎么算;IMU的初始速度与bias怎么算呢。这就引出了后面的VIO初始化
- 7-19页讲了VINS系统如何初始化的:
第八页介绍了系统的两个几何约束:旋转约束与平移约束。这两个约束十分重要。
第九页走总体介绍了视觉与IMU的对齐流程:
①估计IMU与视觉的外参。
②估计IMU中陀螺仪的bias(加速度计的不用估计,他很小容易湮灭不说,对系统影响也很小)
③估计重力方向、速度与尺度。
④对重力方向进行进一步的优化。
⑤把IMU的坐标系与视觉坐标系进行对齐,也就是求出来qwc0。注意前两步用的是八页介绍的旋转约束,三四步用平移约束,第五步用的是第四步估计出来的重力方向。
第十、十一页介绍了如何求外参:这个就是两条路列一个等式,这两个等式一个主要用了预积分理论,另一个主要用了视觉方面的pnp方法,这个等式可以转换成相减为零的方程Ax=0的形式,然后把多个时刻产生的方程累加起来,进行SVD分解,最小奇异值对应的特征向量就是外参。注意十一页介绍了线性方程组合时候用了鲁棒核权重,还有个判别式子(8)。
第十二页介绍了如何求陀螺仪的bias:他是根据旋转约束,令相机测量的qckck+1=(一堆) 把那一堆东西作为一个最小二乘问题去对待,然后去雅克比矩阵,构建正定方程HX=b来求解bg
第十三至十五讲的是如何初始化重力方向、速度与尺度:他的核心思路就是要建立一个观测方程,然后做成最小二乘问题,那就先确定待估计的量,然后根据预积分的约束以及平移约束来构建一个等式,这个等式可以整理为观测方程形式,之后就可以建立最小二乘式子。注意13式→14式自己推一下。
第十六、十七页讲的是如何优化重力方向:为什么要优化重力方向呢,因为上面的约束中没有重力方向模长必选是9.81这个约束,造成三维变量gc0有两个自由度,那咱们就把它重新参数化,让他有两个参数,就是在球面上引入两个基向量,这两个参数用来调整重力的方向。再把重新参数化的gc0代回上面得到的观测方程,同样,待估计量也跟着变了,不是g了而是w
第十八页讲的是如何把IMU的坐标系与世界坐标系对齐:23式子很重要。主要用的两个量是gw与gc0。
第十九页说了初始化的一些问题:为什么没有估计加速度计的bias,为什么只估计了旋转没有管平移呢。 - 20-22:页介绍了VIO的系统:第二十页说了VIO的三大块:前端 后端与初始化。第二十一页说了后端中的优化变量,滑动窗口残差三大块:先验残差、视觉残差与IMU残差。注意鲁棒核函数只用来去除视觉的outlier。IMU是没有鲁棒核函数的。
第 8 讲 VINS 回顾与展望
- 3-6页是这个课程的回顾:第三页说了特征点法、直接法与IMU的信息是否高斯分布问题;4-6页的逻辑就是从概率问题是可以转化为最小二乘问题的,注意这里我们有一个假设就是观测量是多元高斯分布的。然后说了最小二乘问题分为建模与求解两方面:建模的核心就是要确定残差与协方差矩阵,关于残差IMU就是预积分误差,视觉就是重投影误差;协方差矩阵的话,IMU就是得用第三讲中协方差的传递,视觉的协方差是咱们自己设置的。求解的核心就是求解器与雅克比矩阵,这在第六页有说明。
- 7-13页推荐了VIO的一系列论文:包括综述类,基于滤波类、基于优化类、一致性相关、不同残差模型的(线、面、光度误差)、多传感器融合方面的论文。注意线特征对于光度变化比较大,快速旋转这些情况表现比较好,但是慢,实际工程中不常用。
这篇关于从零开始手写VIO课件逻辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









