本文主要是介绍机器学习实验一:KNN算法,手写数字数据集(使用汉明距离)(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
KNN-手写数字数据集:
使用sklearn中的KNN算法工具包( KNeighborsClassifier)替换实现分类器的构建,注意使用的是汉明距离;

运行结果:(大概要运行4分钟左右)

代码:
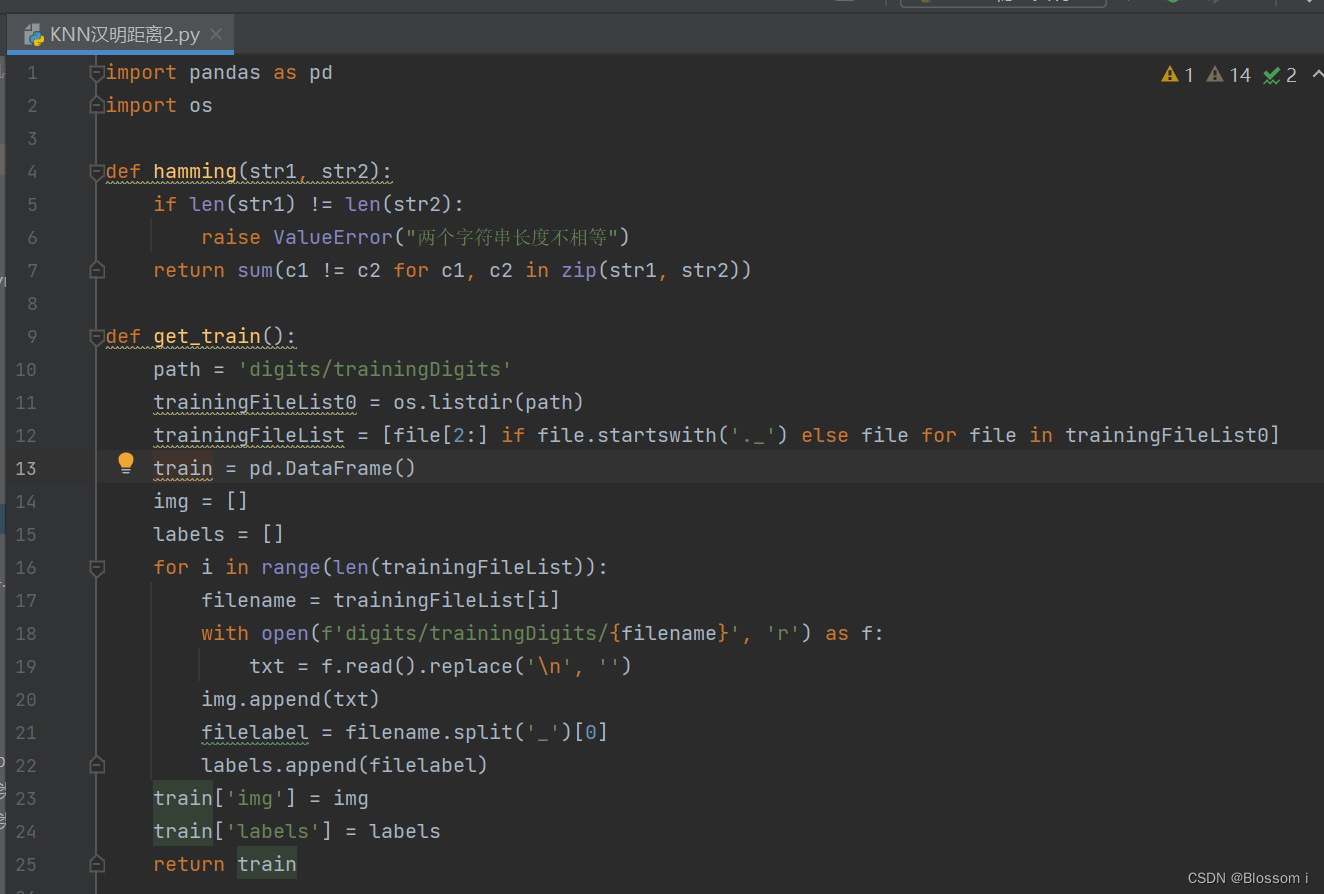
import pandas as pd
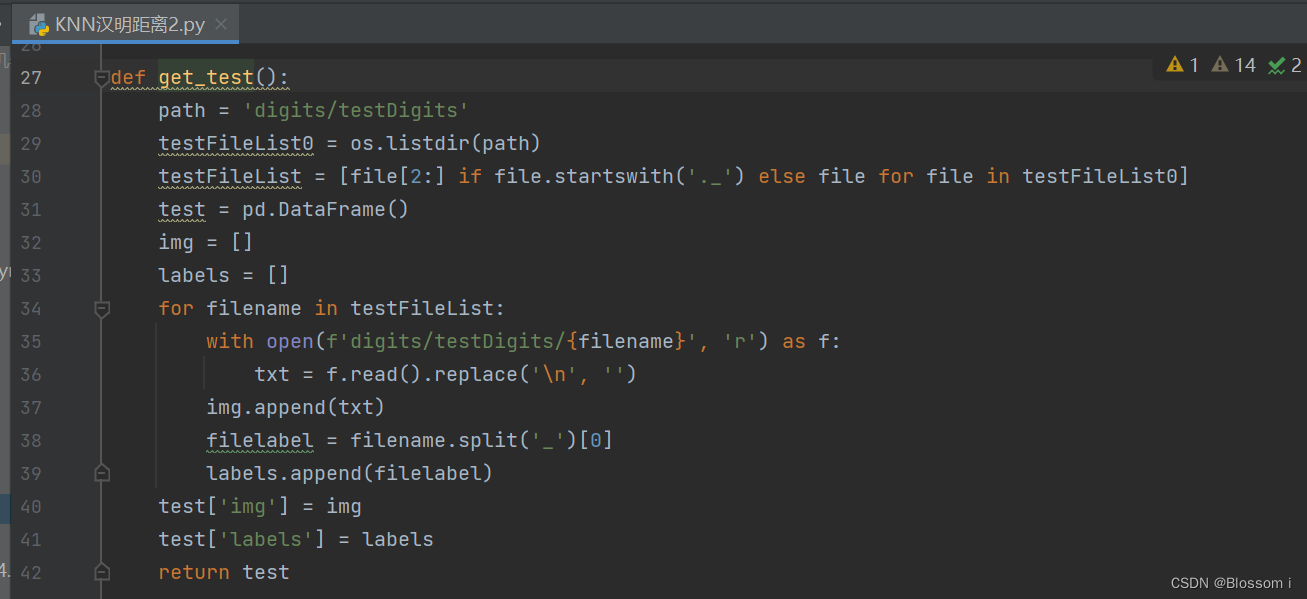
import osdef hamming(str1, str2):if len(str1) != len(str2):raise ValueError("两个字符串长度不相等")return sum(c1 != c2 for c1, c2 in zip(str1, str2))def get_train():path = 'digits/trainingDigits'trainingFileList0 = os.listdir(path)trainingFileList = [file[2:] if file.startswith('._') else file for file in trainingFileList0]train = pd.DataFrame()img = []labels = []for i in range(len(trainingFileList)):filename = trainingFileList[i]with open(f'digits/trainingDigits/{filename}', 'r') as f:txt = f.read().replace('\n', '')img.append(txt)filelabel = filename.split('_')[0]labels.append(filelabel)train['img'] = imgtrain['labels'] = labelsreturn traindef get_test():path = 'digits/testDigits'testFileList0 = os.listdir(path)testFileList = [file[2:] if file.startswith('._') else file for file in testFileList0]test = pd.DataFrame()img = []labels = []for filename in testFileList:with open(f'digits/testDigits/{filename}', 'r') as f:txt = f.read().replace('\n', '')img.append(txt)filelabel = filename.split('_')[0]labels.append(filelabel)test['img'] = imgtest['labels'] = labelsreturn testdef handwritingClass(train, test, k):n = train.shape[0]m = test.shape[0]result = []for i in range(m):dist = []for j in range(n):d = str(hamming(train.iloc[j, 0], test.iloc[i, 0]))dist.append(d)dist_l = pd.DataFrame({'dist': dist, 'labels': train.iloc[:, 1]})dr = dist_l.sort_values(by='dist')[:k]re = dr.loc[:, 'labels'].value_counts()result.append(re.index[0])result = pd.Series(result)test['predict'] = resultacc = (test.iloc[:, -1] == test.iloc[:, -2]).mean()print(f'模型预测准确率为{acc:.5f}')return test# 获取训练集和测试集
train = get_train()
test = get_test()# 调用函数
handwritingClass(train, test, 3)
这篇关于机器学习实验一:KNN算法,手写数字数据集(使用汉明距离)(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






