本文主要是介绍04. k近邻(k-nearest neighbour,KNN )分类鸢尾花,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
K近邻是一种基本的分类方法,通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最近邻)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20 的整数。
KNN算法的结果很大程度取决于K的选择 .
KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,距离一般使用欧式距离或曼哈顿距离:

导入数据
import numpy as np
import pandas as pd # 直接引入sklearn里面的数据集,iris 鸢尾花
from sklearn.datasets import load_iris ##加载数据
from sklearn.model_selection import train_test_split ## 切分数据集为训练集和测试集
from sklearn.metrics import accuracy_score ## 用来计算分类预测的准确率
iris = load_iris() ## 加载鸢尾花数据
iris
#'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]), 存放的是特征值对应的目标值,和target_name匹配
## 'target_names': array(['setosa', 'versicolor', 'virginica'] 花的类别
## 'feature_names': ['sepal length (cm)', 花萼长度
## 'sepal width (cm)', 花萼宽度
## 'petal length (cm)', 花萼长度
## 'petal width (cm)'], 花萼宽度
x = iris.data ##加载数据
y = iris.target ##一维数组
y = y.reshape(-1,1) ##将一维数组改矩阵,任意行 一列 

2.核心算法实现
# 距离函数定义
def manhadun(a,b): #曼哈顿距离 a为矩阵 b为向量return np.sum(np.abs(a-b),axis=1) # axis = 1 保存为一列def oushi(a,b): ##欧氏距离return np.sqrt(np.sum((a-b)**2,axis=1))# 分类器实现 class Knn(object):## 定义一个初始化方法__init__ 类的构造方法## n_neighbors为近邻的K值 ## dist_func 为 判断距离的方法def __init__(self,n_neighbors=1,dist_func=manhadun):self.n_neighbors = n_neighborsself.dist_func=dist_func ## 训练模型方法 def fit(self,x,y):self.x_train = x self.y_train = y # 模型预测方法:# x 为测试数据def predict(self,x):# 初始化预测分类数据 # 定义一个与传入的x相同行数的值全是0的数组# 其结果的类型应该与训练集的y值一样y_pred = np.zeros((x.shape[0],1),dtype=self.y_train.dtype)# 遍历测试的数据,取出每个数据点的序号和数据x_testfor i,x_test in enumerate(x):# 1.x_test 跟所有训练数据计算距离# 当前的测试数据与每一行的训练数据计算距离distances = self.dist_func(self.x_train,x_test)if i == 0:print(x_test,distances)# 2.得到的距离按照由近到远进行排序,取出索引值# argsort 将所有的数据进行排序,并取出索引值nn_index=np.argsort(distances)# 3.选取距离最近的K个点,保存他们对应的分类类别 # 从训练集里取出K个值# ravel 是将数据转变为一维的数组nn_y = self.y_train[ nn_index[:self.n_neighbors] ].ravel()# 4.统计类别中出现频率最高的那个,赋给y_pred[i]# bincount求的是每个值出现的次数,必须传入的是整数类型y_pred[i] = np.argmax(np.bincount(nn_y))# print(i,'---',x_test)return y_pred3 测试
# 定义一个实例
knn = Knn(n_neighbors=3)# 训练模型
knn.fit(x_train,y_train)
# 传入测试数据,做预测
y_pred = knn.predict(x_test)# 求出预测准确率
accuracy = accuracy_score(y_test,y_pred)print("预测准确率:",accuracy)预测准确率: 0.93333333333333334 分别测试
# 测试不同的距离计算方法和K值对准确率的影响# 定义一个实例
knn = Knn()
# 训练模型
knn.fit(x_train,y_train)#保存结果list
result_list = []# 针对不同的参数选取,做预测
for p in [1,2]:knn.dist_func = manhadun if p==1 else oushi#考虑不同的k取值 #步长为2,避免偶数值dfor k in range(1,10,2):knn.n_neighbors = k # 传入测试数据,做预测y_pred = knn.predict(x_test)# 求出预测准确率accuracy = accuracy_score(y_test,y_pred)result_list.append([k,'manhadun' if p==1 else 'oushi',accuracy])df = pd.DataFrame(result_list,columns=['k','距离函数','预测准确率'])df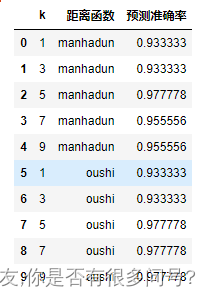
这篇关于04. k近邻(k-nearest neighbour,KNN )分类鸢尾花的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







