本文主要是介绍K8s基础10——数据卷、PV和PVC、StorageClass动态补给、StatefulSet控制器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、数据卷类型
- 1.1 临时数据卷(节点挂载)
- 1.2 节点数据卷(节点挂载)
- 1.3 网络数据卷NFS
- 1.3.1 效果测试
- 1.4 持久数据卷(PVC/PV)
- 1.4.1 效果测试
- 1.4.2 测试结论
- 二、PV、PVC生命周期
- 2.1 各阶段工作原理
- 2.1.1 资源供应
- 2.1.2 资源绑定
- 2.1.3 .资源使用
- 2.1.4 资源回收
- 2.1.5 PVC资源扩容
- 2.2 测试PV回收策略
- 2.2.1 Retain保留策略
- 2.2.2 Recycle回收策略
- 2.3 StorageClass动态供给
- 2.3.1 部署存储插件
- 2.3.2 使用插件
- 三、StatefulSet
- 3.1 控制器介绍
- 3.2 部署实践
- 3.3 集群部署流程
- 3.3.1 etcd案例
- 3.3.2 zookeeper示例
一、数据卷类型
为什么需要数据卷?
- 容器中的文件在磁盘上是临时存放的,这给容器中运行比较重要的应用程序带来一些问题。
- 当容器升级或者崩溃时,kubelet会重建容器,容器内文件会丢失。
- 一个Pod中运行多个容器时,需要共享文件。
- 而K8s 数据卷就可以解决这两个问题。
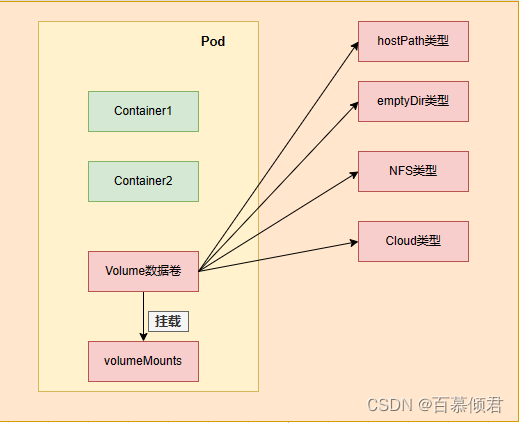
Volume概念:
- Volume是与Pod绑定的(独立于容器)与Pod具有相同生命周期的资源对象。
- 可以将Volume的内容理解为目录或文件,容器若需使用某个Volume,则仅需设置volumeMounts将一个或多个Volume挂载为容器中的目录或文件,即可访问Volume中的数据。
常用的数据卷类型:
- 节点本地(hostPath,emptyDir)
- 网络(NFS,Ceph,GlusterFS)
- 公有云(AWS EBS)
- K8S资源(configmap,secret)
概念图:
1.1 临时数据卷(节点挂载)
概念:
- emptyDir卷是一个临时存储卷,与Pod生命周期绑定一起,如果Pod删除了卷也会被删除。
应用场景:
- Pod中容器之间数据共享,是从Pod层面上提供的技术方案。
- 当一个Pod内有多个容器,且都分布在同一个节点上时,则数据共享;若pod内的多个容器不在同一个节点上时,数据不共享。
特点:
- kubelet会在Node的工作目录下为Pod创建EmptyDir目录。
- 可以将该节点上的某pod工作目录EmptyDir下的数据挂载到该pod容器里,从而实现本地数据共享。
- 只有在pod所在的节点上才能看到本地数据。
- Pod删除后,本地数据也会被删除。
- 此种模式没有参数应用,其他模式都有参数应用。
缺点:
- 不能持久化。当node1节点上的Pod删除后,会触发健康检查重新拉起容器,此时新容器在node2节点,node2节点上看不到之前Node1节点上容器数据,因为被删除了。
参考地址:
- K8S官网地址
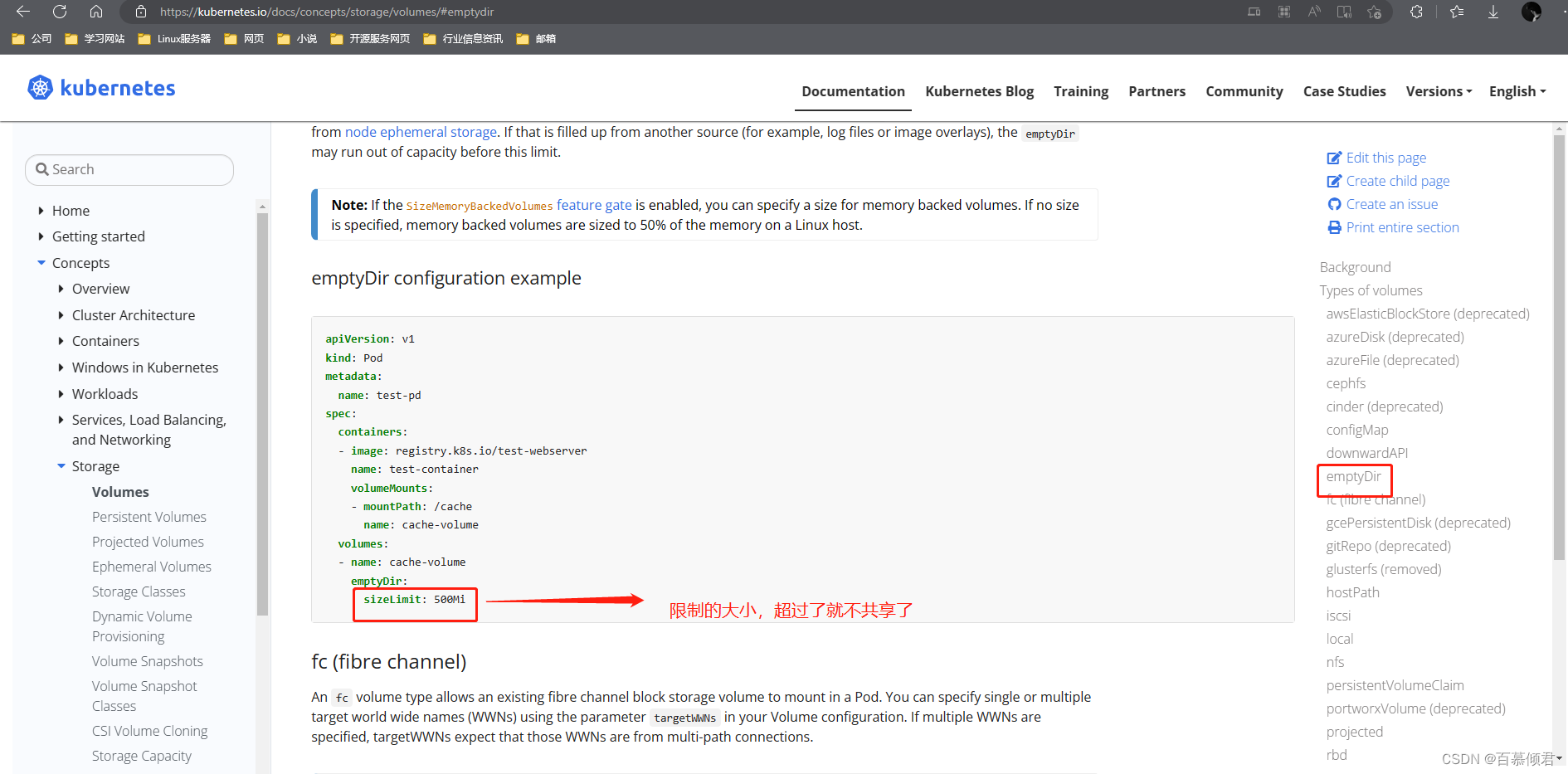
1.编辑yaml文件,创建pod容器。
[root@k8s-master bck]# cat my-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: my-pod ##容器名称
spec:containers:- name: writeimage: centoscommand: ["bash","-c","for i in {1..100};do echo $i >> /data/hello;sleep 1;done"]volumeMounts: ##定义引用数据卷- name: data ##引用哪个数据卷,通过数据卷名称来引用。mountPath: /data ##将本地数据卷挂载到容器里哪个路径下。- name: readimage: centoscommand: ["bash","-c","tail -f /data/hello"]volumeMounts:- name: datamountPath: /datavolumes: ##定义数据卷- name: data ##数据卷名称emptyDir: {} ##数据卷类型[root@k8s-master bck]# kubectl apply -f my-pod.yaml
2.进入容器验证数据是否共享。
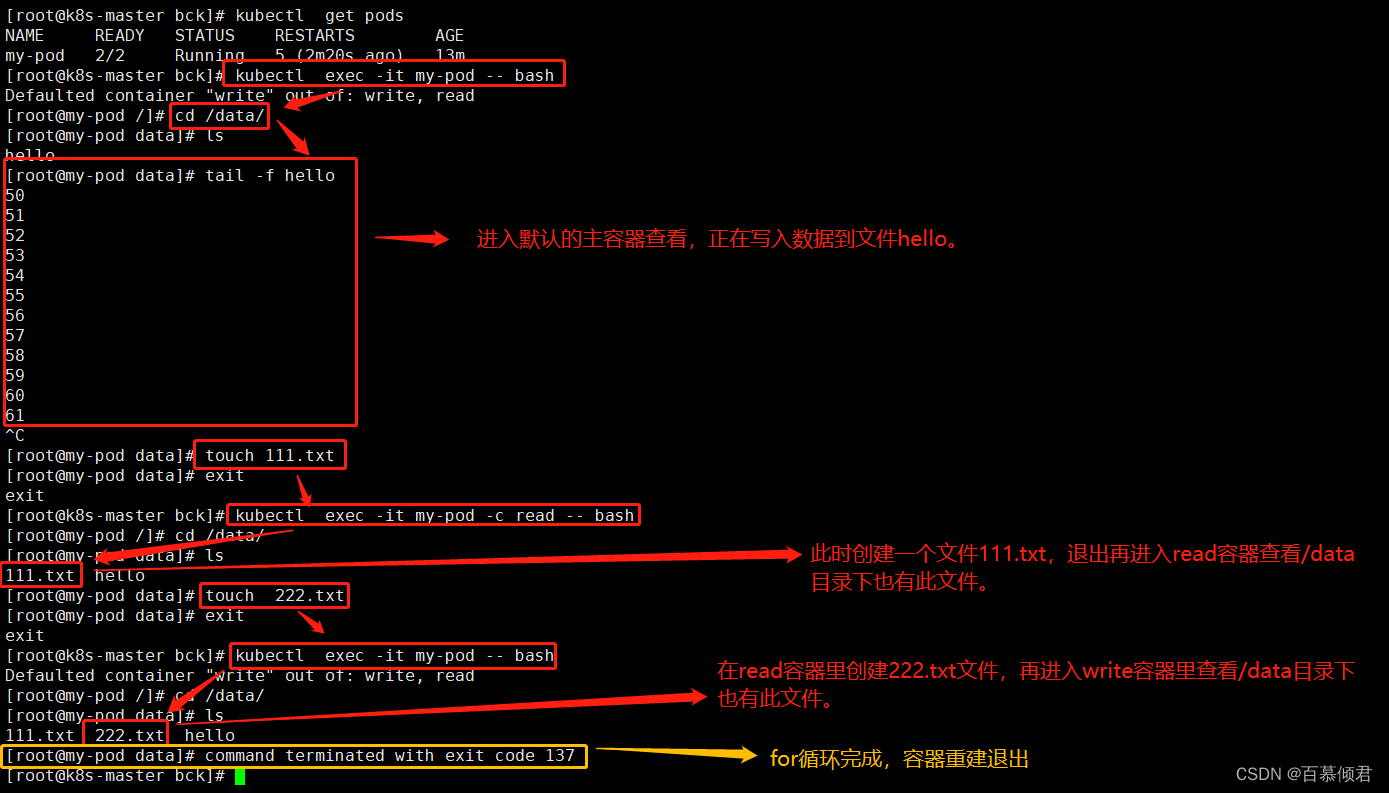
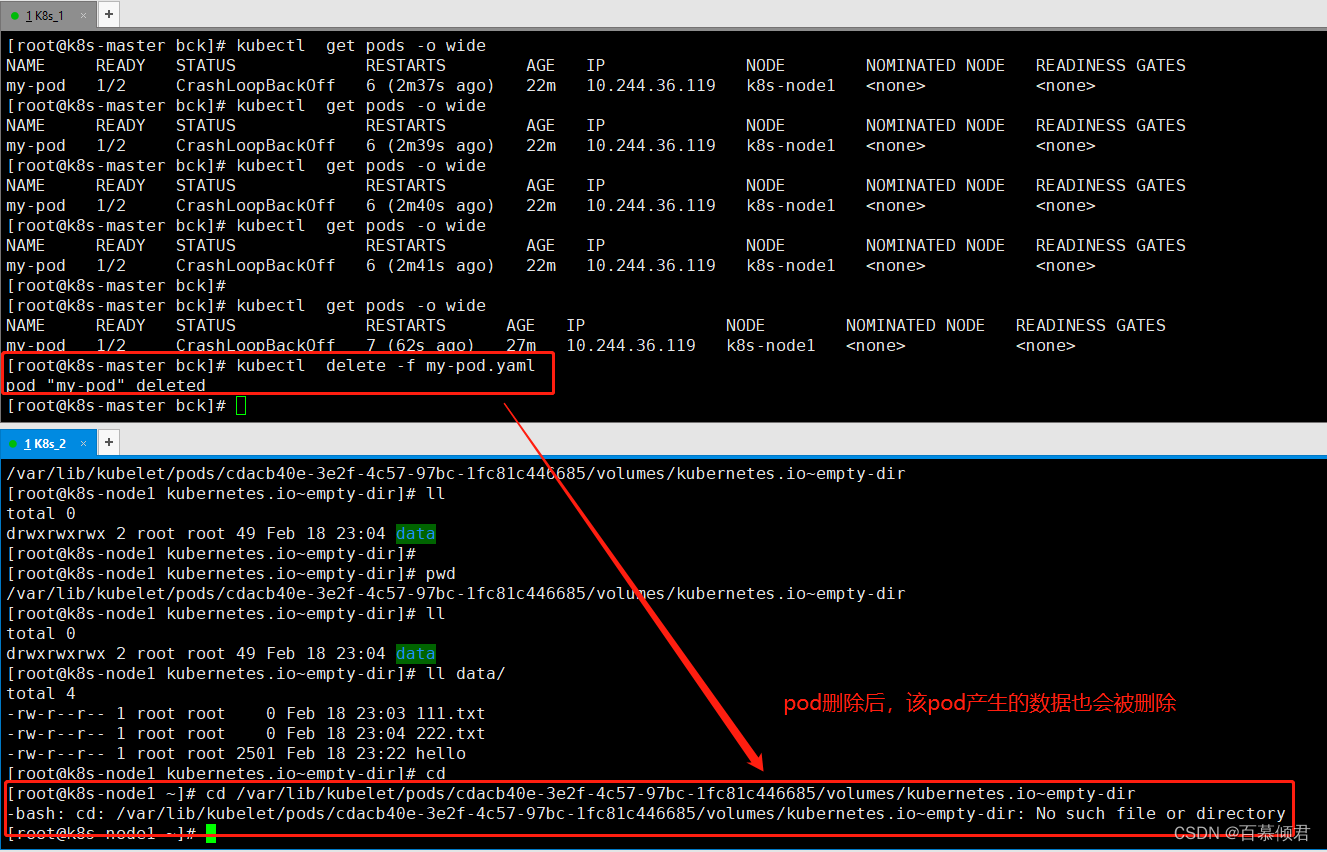
3.查看该pod容器在哪个节点上,进入该节点查找本地数据。
[root@k8s-node1 ~]# cd /var/lib/kubelet/pods/cdacb40e-3e2f-4c57-97bc-1fc81c446685/volumes/kubernetes.io~empty-dir

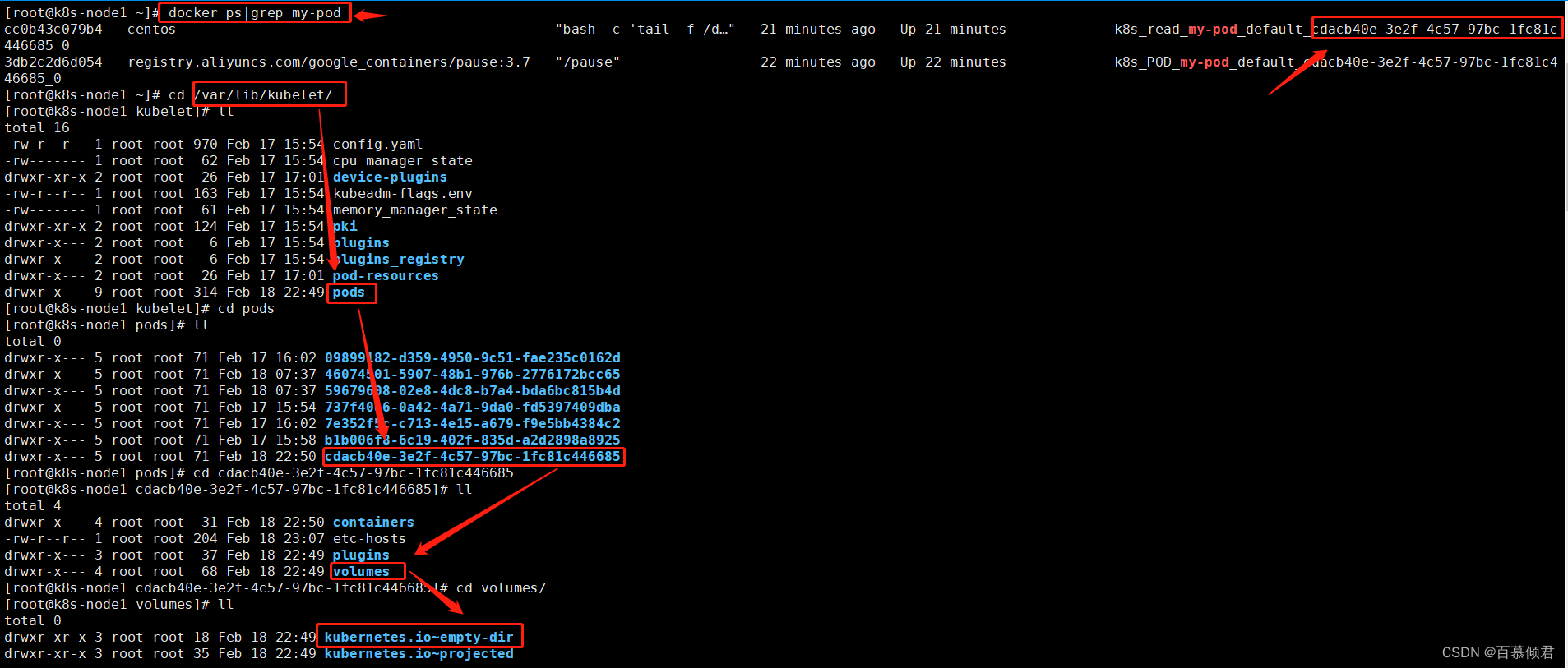

4.删除pod,数据目录也会被删除。
1.2 节点数据卷(节点挂载)
概念:
- hostPath卷:挂载Node文件系统(Pod所在节点)上文件或者目录到Pod中的容器。
- 和 emptyDir数据卷一样,只能在pod容器所在的node节点上查看到挂载目录文件数据,但区别是hostPath数据卷挂载不会因为删除pod而导致宿主机上的挂载目录文件消失。
缺点:
- 不能持久化。当node1节点上的Pod删除后,会触发健康检查重新拉起容器,此时新容器在node2节点,node2节点上看不到之前Node1节点上容器数据,因为被删除了。
应用场景:
- 容器应用的关键数据需要被持久化到宿主机上。
- 需要使用Docker中的某些内部数据,可以将主机的/var/lib/docker目录挂载到容器内。
- 监控系统,例如cAdvisor需要采集宿主机/sys目录下的内容。
- Pod的启动依赖于宿主机上的某个目录或文件就绪的场景。
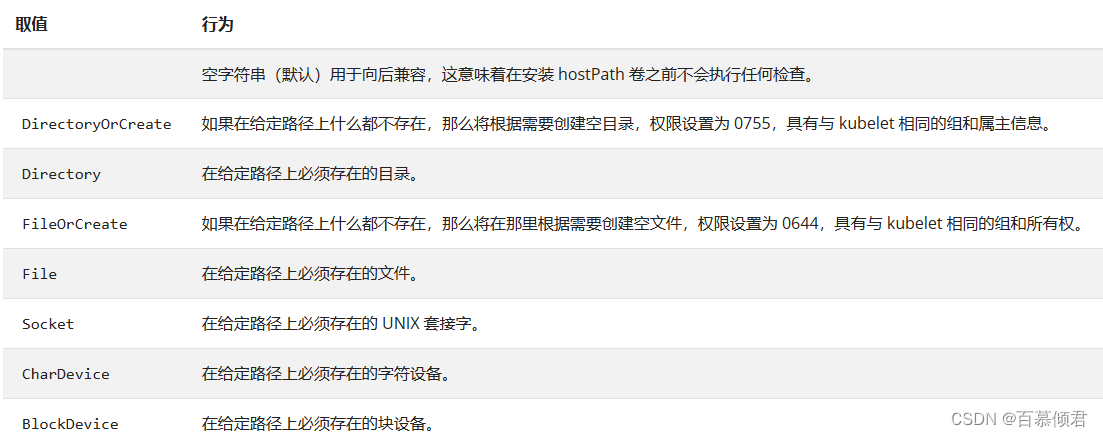
type字段的取值类型:
- htstPath数据卷有个可选字段type。
- FileOrCreate 模式不会负责创建文件的父目录。 如果欲挂载的文件的父目录不存在,Pod 启动会失败。 为了确保这种模式能够工作,可以尝试把文件和它对应的目录分开挂载
注意事项:
- HostPath 卷存在许多安全风险,最佳做法是尽可能避免使用 HostPath。 当必须使用 HostPath 卷时,它的范围应仅限于所需的文件或目录,并以只读方式挂载。
- 如果通过 AdmissionPolicy 限制 HostPath 对特定目录的访问,则必须要求 volumeMounts 使用 readOnly 挂载以使策略生效。
1.编辑yaml文件,将宿主机上的/tmp目录挂载到test容器里的/data目录下,数据卷为data。
[root@k8s-master bck]# cat hostPath.yaml
apiVersion: v1
kind: Pod
metadata:name: pod2
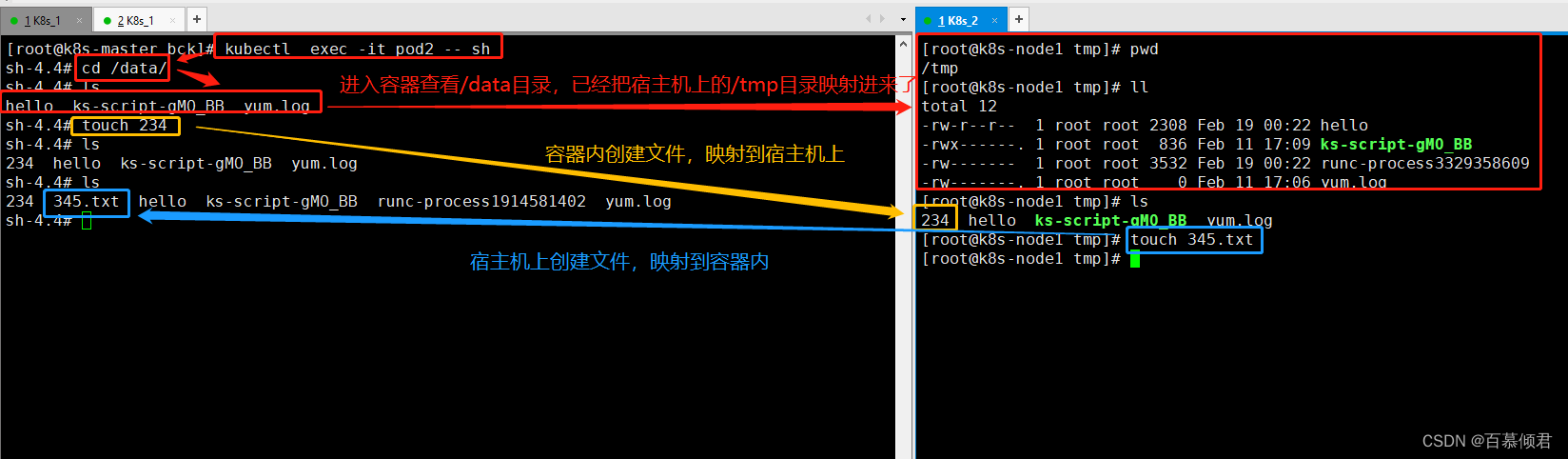
spec:containers:- name: testimage: centoscommand: ["bash","-c","for i in {1..1000};do echo $i >> /data/hello;sleep 1;done"]volumeMounts:- name: datamountPath: /datavolumes:- name: datahostPath:path: /tmptype: Directory
2.导入yaml,进入容器查看/data目录已经把节点机器上的/tmp目录映射进来,我这里的pod2部署在node1节点上的,就去node1节点上看,其他节点不共享数据看不到。
3. 修改yaml,同时挂载2个目录,根据数据卷的名称识别一一挂载。
[root@k8s-master bck]# cat hostPath.yaml
apiVersion: v1
kind: Pod
metadata:name: web
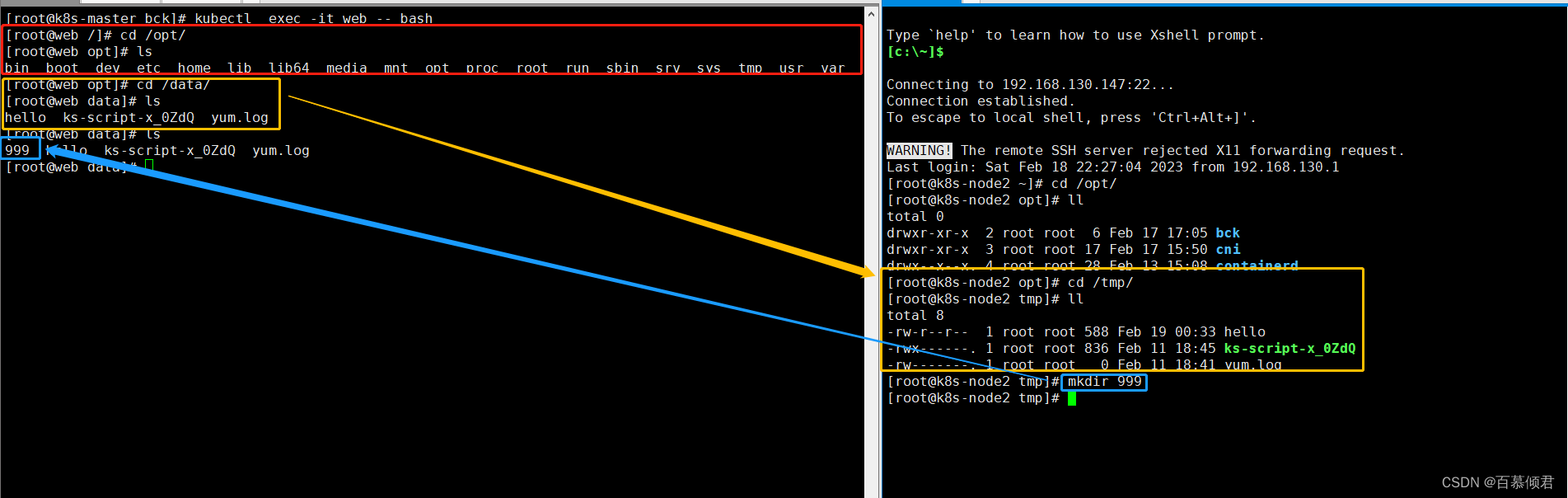
spec:containers:- name: webimage: centoscommand: ["bash","-c","for i in {1..1000};do echo $i >> /data/hello;sleep 1;done"]volumeMounts:- name: datamountPath: /data- name: qingjunmountPath: /optvolumes:- name: datahostPath:path: /tmptype: Directory- name: qingjunhostPath:path: /type: Directory
4.进入Pod所在节点,进入容器,查看。
1.3 网络数据卷NFS
概念:
- NFS是一个主流的文件共享服务器,NFS卷提供对NFS挂载支持,可以自动将NFS共享路径挂载到Pod中。
注意事项:
- 每个Node上都要安装nfs-utils包。
概念图:
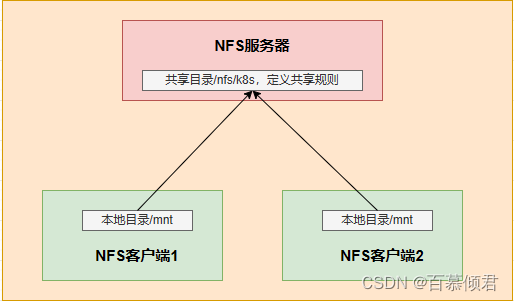
1.选择一台服务器作为NFS服务器。我这里选择的是node2。
1.安装nfs服务。
[root@k8s-node2 ~]# yum -y install nfs-utils2.创建共享目录,名字自取,并编辑共享规则:只能是192.168.130.0网段的机器上的root用户访问,具备读写权限。
[root@k8s-node2 ~]# mkdir -p /nfs/k8s
[root@k8s-node2 ~]# cat /etc/exports
/nfs/k8s 192.168.130.0/24(rw,no_root_squash)3.启动服务,并设置开机自启。
[root@k8s-node2 ~]# systemctl start nfs
[root@k8s-node2 ~]# systemctl enable nfs
2.在其他所有节点上安装nfs客户端,不然无法挂载。
[root@k8s-master bck]# yum -y install nfs-utils
[root@k8s-node1 ~]# yum -y install nfs-utils#挂载。在其他工作节点上挂载,将192.168.130.147上的/nfs/k8s目录挂载到本地的/mnt/目录下。
[root@k8s-node1 ~]# mount -t nfs 192.168.130.147:/nfs/k8s /mnt/#取消挂载。
[root@k8s-node1 ~]# umount /mnt/

3.此时在node1节点上的/mnt/下操作,就相当于在NFS服务器上的/nfs/k8s目录下操作。

4.查看容器内的挂载情况。
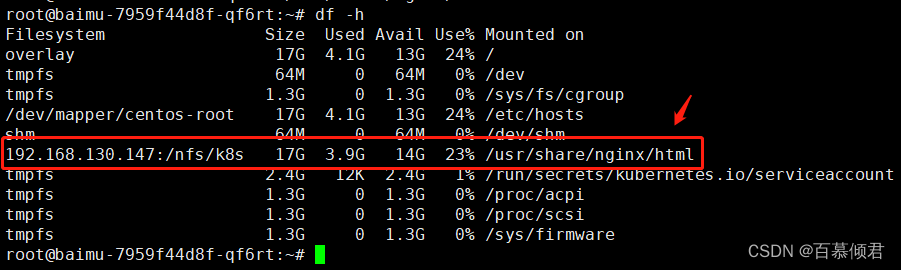
1.3.1 效果测试
1.编辑yaml文件,创建pod容器。
[root@k8s-master bck]# cat qingjun.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: baimuname: baimu
spec:replicas: 3selector:matchLabels:app: baimutemplate:metadata:labels:app: baimuspec:containers:- image: nginxname: nginxvolumeMounts: ##定义挂载规则。- name: mq ##指定挂载哪个数据卷。mountPath: /usr/share/nginx/html ##指定将数据挂载到容器里的哪个目录下。volumes: ##定义挂载卷。- name: mq ##挂载卷名称。nfs:server: 192.168.130.147 ##指定nfs服务器地址,网络能通。path: /nfs/k8s ##指定nfs服务器上的共享目录。
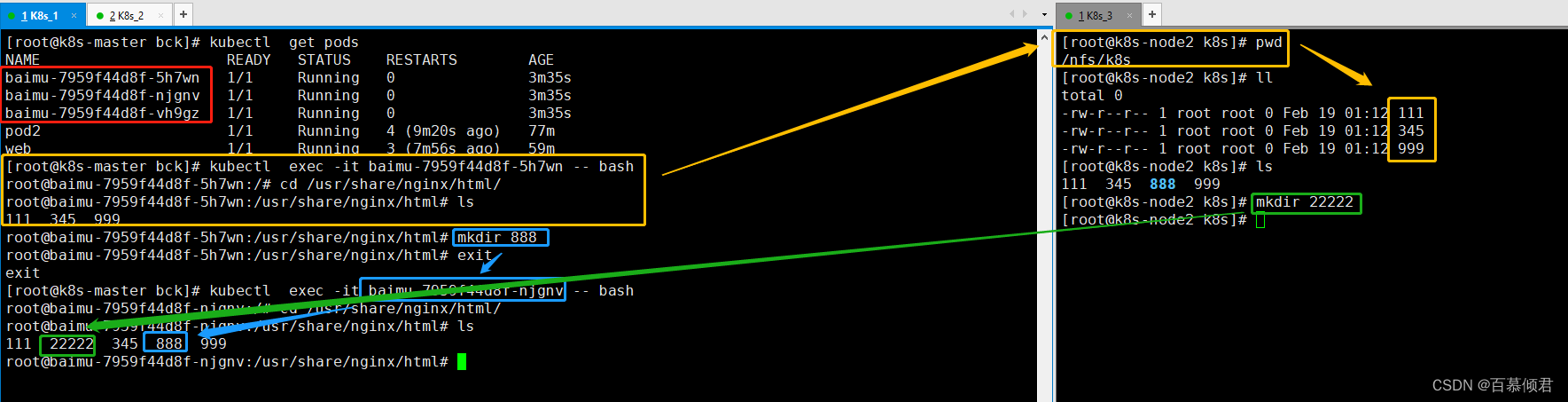
2.数据共享测试。
- 创建一组pod,内有3个容器,查看进入容器验证。
- 先进入第一个容器的挂载目录,查看已经将nfs服务器上的/nfs/k8s目录下的内容挂载进来。
- 创建888目录,nfs服务器上查看888目录被创建。
- 退出第一个容器,在nfs服务器共享目录下创建22222目录,再进入第二个容器查看22222目录被同步创建。
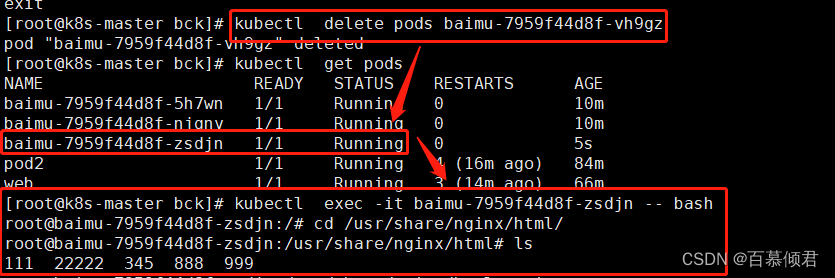
3.重建pod,新pod数据共享测试。
- 删除podl里的第三个容器,等待新容器被创建运行。
- 进入新容器挂载目录,查看该目录下也共享nfs服务器上的共享目录。
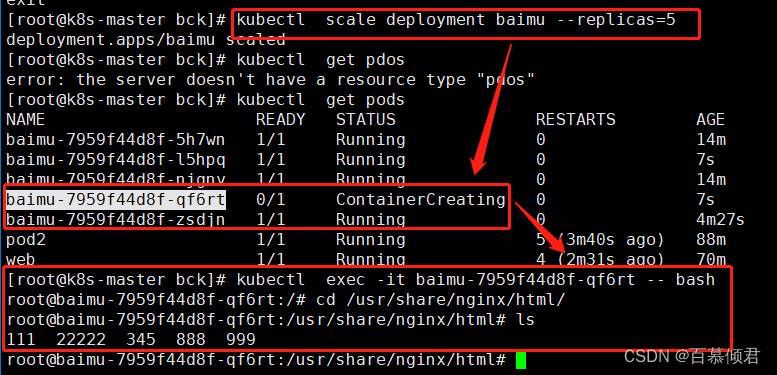
4.扩容新pod数据共享测试。
- 扩容副本到5个。
- 进入新容器的挂载目录,查看该目录下也共享nfs服务器上的共享目录。
1.4 持久数据卷(PVC/PV)
为什么会有PVC、PV?
- 提高安全性。上文我们使用nfs挂载出来的信息都是记录在yaml文件中,安全性低。
- 职责分离。当后端需要用到存储时,作为非专业人士来说,存储这块的工作量是需要专门的运维大佬来做的,而后端只需要简单的提交你程序所需要的存储大小即可,这样一来就可以职责分离。
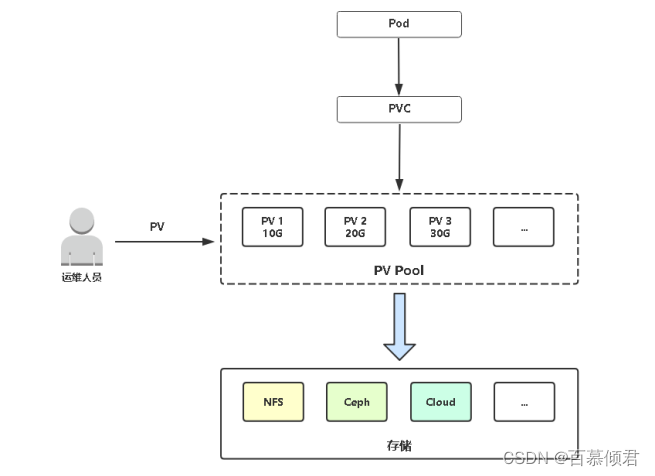
概念:
- PersistentVolume(PV):由管理员创建和配置,将存储定义为一种容器应用可以使用的资源,使得存储作为集群中的资源管理。
- PersistentVolumeClaim(PVC):用户来操作,是对存储资源的一个申请,让用户不需要关心具体的Volume实现细节。
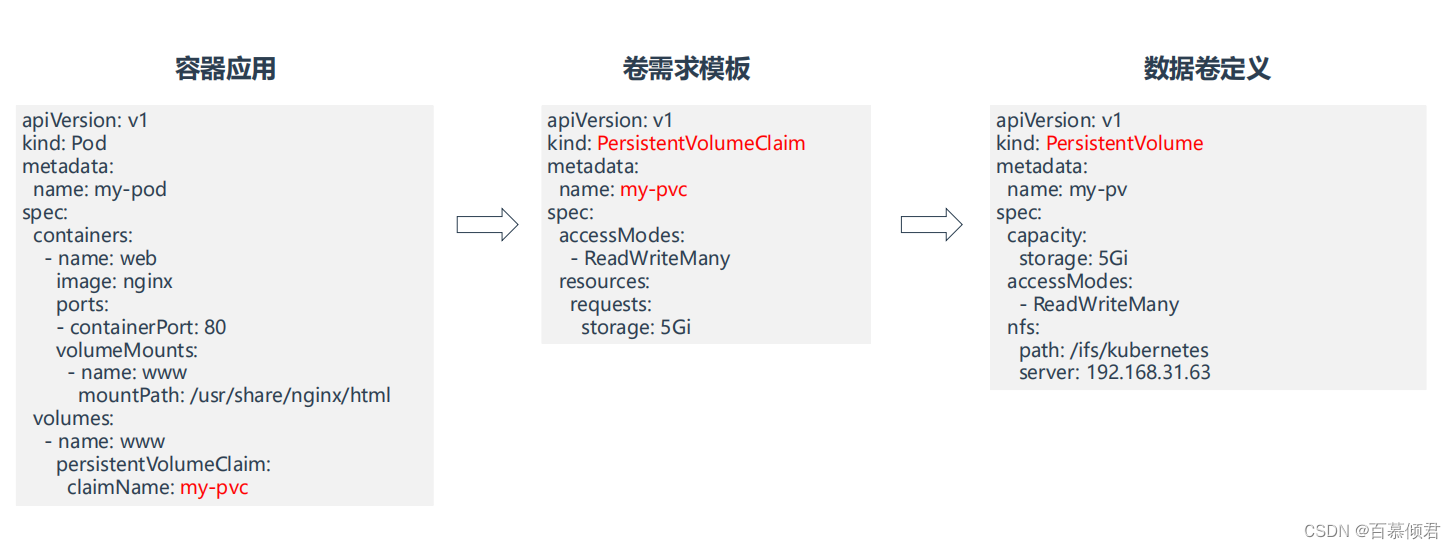
概念图:
- 管理员需要提前定义pv,是手动的,也能自动创建需要依赖过StorageClass资源,后面讲。
- 用户在创建pod时,需要在yaml里定义pvc,内容包括pvc名称、申请资源大小、访问模式。
- K8s通过PVC查找匹配到合适的PV,并挂载到Pod容器里。
1.用户定义pod和pvc。
[root@k8s-master bck]# cat web1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: web1name: web1
spec:replicas: 3selector:matchLabels:app: web1template:metadata:labels:app: web1spec:containers:- image: nginxname: nginxvolumeMounts:- name: mqmountPath: /usr/share/nginx/htmlvolumes:- name: mqpersistentVolumeClaim:claimName: qingjun ##这里的名称需要与PVC名称一致。
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: qingjun ##PVC名称
spec:accessModes:- ReadWriteMany ##访问模式,ReadWriteOnce、ReadOnlyMany或ReadWriteMany。resources:requests:storage: 5Gi ##程序要申请的存储资源。
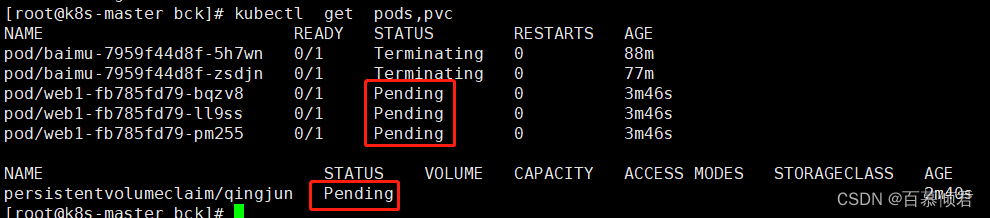
2.导入yaml,查看pod和pvc都处于等待状态,是因为此时还没有关联到pv。
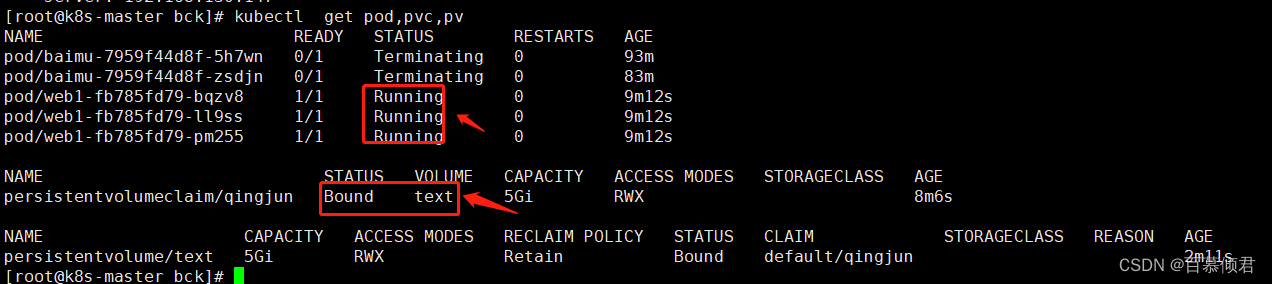
3.管理员定义创建pv,导入yaml,pvc和Pod状态改变。
[root@k8s-master bck]# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: text ##PV名称,自定义。
spec:capacity:storage: 5Gi ##容量。accessModes:- ReadWriteManynfs:path: /nfs/k8s ##定义nfs挂载卷共享目录。server: 192.168.130.147 ##指定nfs服务器地址。
4.进入Pod容器验证数据共享。Pod滚动升级、扩容也都会共享数据,测试方法同上文的nfs测试流程。
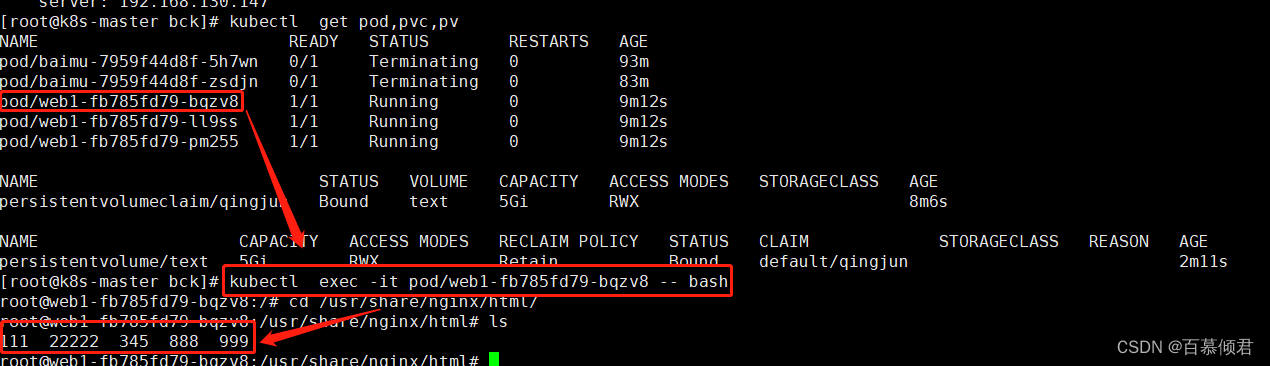
1.4.1 效果测试
1.先在nfs服务器上创建多个目录,作为多个pv挂载目录。
[root@k8s-node2 k8s]# pwd
/nfs/k8s
[root@k8s-node2 k8s]# mkdir pv0001
[root@k8s-node2 k8s]# mkdir pv0002
[root@k8s-node2 k8s]# mkdir pv0003
2.创建3个pv,分别为:
- pv0001,内存5G,挂载nfs服务器为192.168.130.147,挂载目录为/nfs/k8s/pv0001。
- pv0002,内存25G,挂载nfs服务器为192.168.130.147,挂载目录为/nfs/k8s/pv0002。
- pv0003,内存50G,挂载nfs服务器为192.168.130.147,挂载目录为/nfs/k8s/pv0003。
[root@k8s-master bck]# cat pv-all.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: pv0001
spec:capacity:storage: 5GiaccessModes:- ReadWriteManynfs:path: /nfs/k8s/pv0001server: 192.168.130.147
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv0002
spec:capacity:storage: 25GiaccessModes:- ReadWriteManynfs:path: /nfs/k8s/pv0002server: 192.168.130.147
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv0003
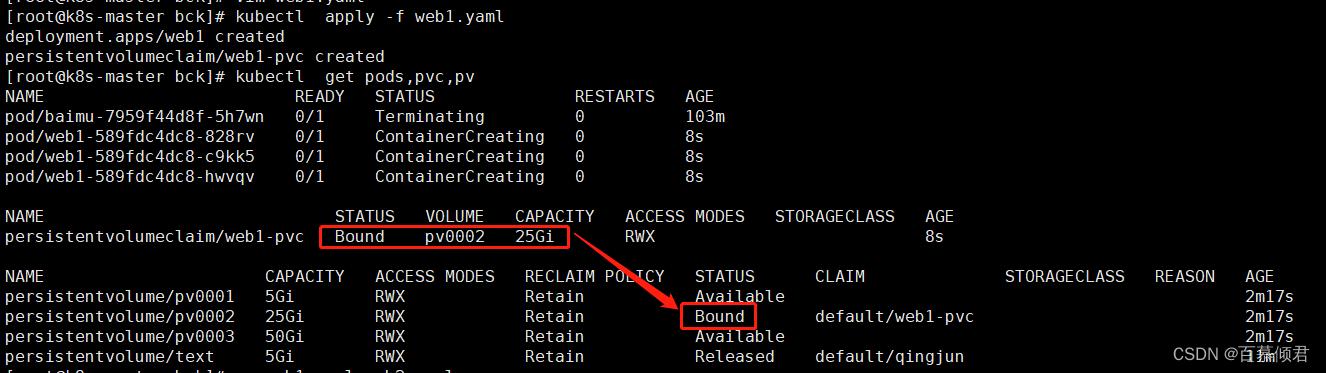
spec:capacity:storage: 50GiaccessModes:- ReadWriteManynfs:path: /nfs/k8s/pv0003server: 192.168.130.147[root@k8s-master bck]# kubectl apply -f pv-all.yaml

3.创建第一个pvc,名称为web1-pvc,申请资源10G。此时pv和内存为25G的pv0002绑定在一起。
[root@k8s-master bck]# cat web1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: web1name: web1
spec:replicas: 3selector:matchLabels:app: web1template:metadata:labels:app: web1spec:containers:- image: nginxname: nginxvolumeMounts:- name: mqmountPath: /usr/share/nginx/htmlvolumes:- name: mqpersistentVolumeClaim:claimName: web1-pvc---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: web1-pvc
spec:accessModes:- ReadWriteManyresources:requests:storage: 10Gi
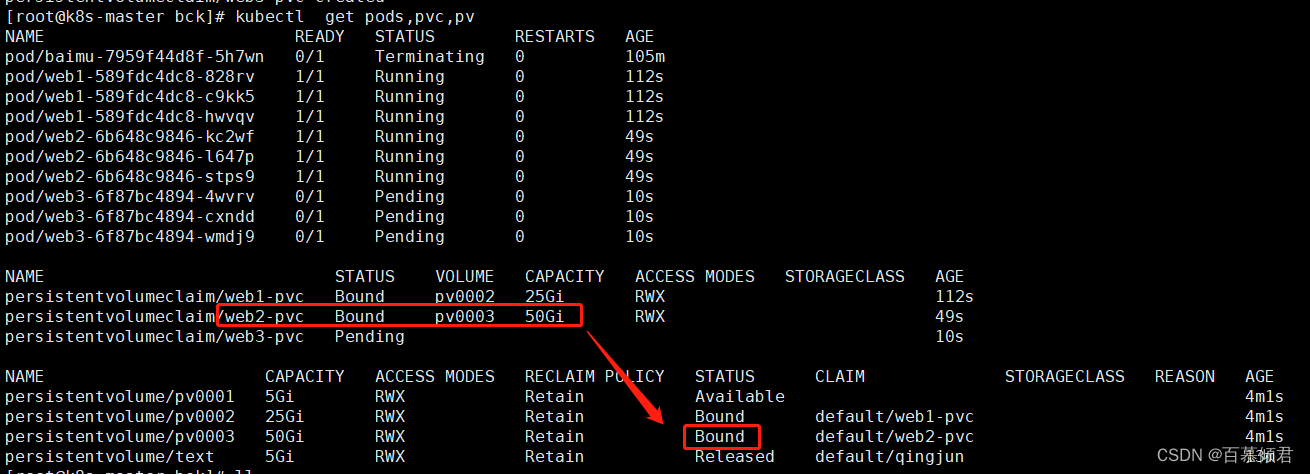
4.创建第二个pvc,名称为web2-pvc,申请资源25G。此时pv和内存为50G的pv0003绑定在一起。
[root@k8s-master bck]# cat web2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: web2name: web2
spec:replicas: 3selector:matchLabels:app: web2template:metadata:labels:app: web2spec:containers:- image: nginxname: nginxvolumeMounts:- name: mqmountPath: /usr/share/nginx/htmlvolumes:- name: mqpersistentVolumeClaim:claimName: web2-pvc---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: web2-pvc
spec:accessModes:- ReadWriteManyresources:requests:storage: 25Gi[root@k8s-master bck]# kubectl apply -f web2.yaml
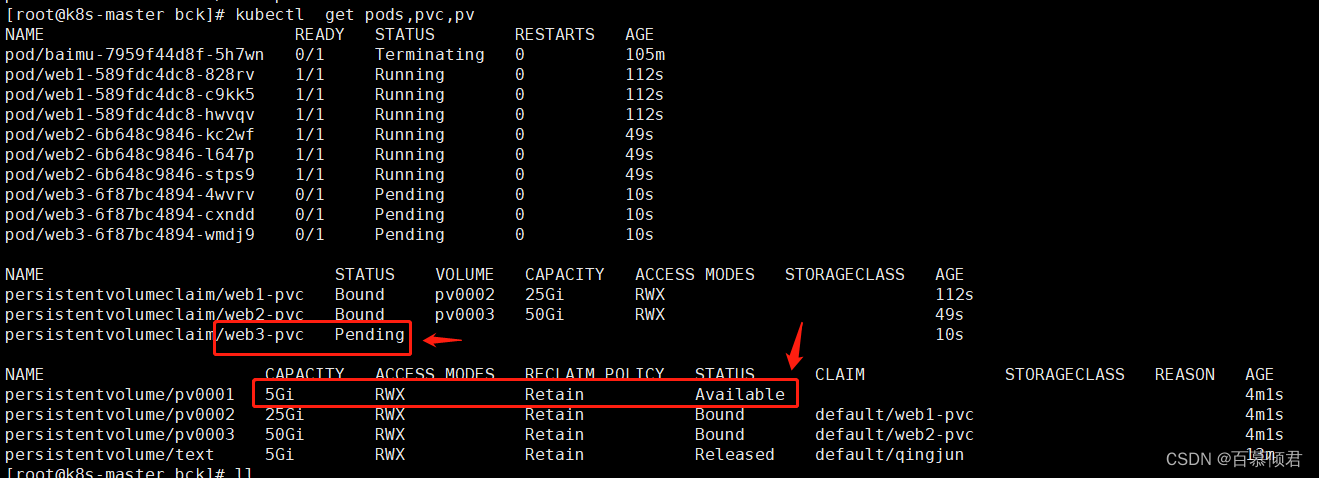
5.创建第三个pvc,名称为web3-pvc,申请资源6G。此时pv没有和剩余的pv0001绑定。为什么呢?
[root@k8s-master bck]# cat web3.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: web3name: web3
spec:replicas: 3selector:matchLabels:app: web3template:metadata:labels:app: web3spec:containers:- image: nginxname: nginxvolumeMounts:- name: mqmountPath: /usr/share/nginx/htmlvolumes:- name: mqpersistentVolumeClaim:claimName: web3-pvc---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: web3-pvc
spec:accessModes:- ReadWriteManyresources:requests:storage: 6Gi
1.4.2 测试结论
pvc与pv怎么匹配的?
- 主要根据存储容量和访问模式。我们定义pvc、pv的yaml文件里,都有这两个字段,并不是说创建了3个pv,再创建的3个pvc就能一一对上,还要根据第二点,存储容量。
存储容量怎么匹配的 ?
- 向上就近容量匹配。比如上文的web1-pvc,它的申请容量为10G,那再已有的三个pvc里面,容量分别为5G、25G、50G,就去匹配向上的、匹配就近的25G;当web2-pvc来匹配时,它的申请容量为25G,再剩下的两个pvc里面,就去匹配向上就近的50G;剩下的web3-pvc匹配时,它的申请容量为6G,再仅剩的一个pvc5G,是满足不了“向上就近原则”,所以就没匹配中。
pv与pvc的关系:
- 一对一
容量能不能限制?
- 目前容量主要用作pvc与pv匹配的,具体的限制取决于后端存储。
二、PV、PVC生命周期
- AccessModes(访问模式):AccessModes 是用来对 PV 进行访问模式的设置,用于描述用户应用对存储资源的访问权限,访问权限包括下面几种方式:
- ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载。常用于块设备存储(云硬盘)。
- ReadOnlyMany(ROX):只读权限,可以被多个节点挂载。常用于数据共享(文件系统存储)。
- ReadWriteMany(RWX):读写权限,可以被多个节点挂载
- RECLAIM POLICY(回收策略):指PVC删除之后,PV是去是留的一种策略。
目前 PV 支持的策略有三种:
- Retain(保留): 保留数据,需要管理员手工清理数据。
- Recycle(回收):清除 PV 中的数据,效果相当于执行 rm -rf /ifs/kuberneres/*
- Delete(删除):与 PV 相连的后端存储同时删除
- STATUS(状态):
一个 PV 的生命周期中,可能会处于4中不同的阶段:
- Available(可用):表示可用状态,还未被任何 PVC 绑定。
- Bound(已绑定):表示 PV 已经被 PVC 绑定。
- Released(已释放):PVC 被删除,但是资源还未被集群重新声明。
- Failed(失败): 表示该 PV 的自动回收失败。
2.1 各阶段工作原理
生命周期阶段:
- 我们可以将PV看作可用的存储资源,PVC则是对存储资源的需求。
- PV和PVC的生命周期包括资源供应(Provisioning)、资源绑定(Binding)、资源使用(Using)、资源回收(Reclaiming)几个阶段。
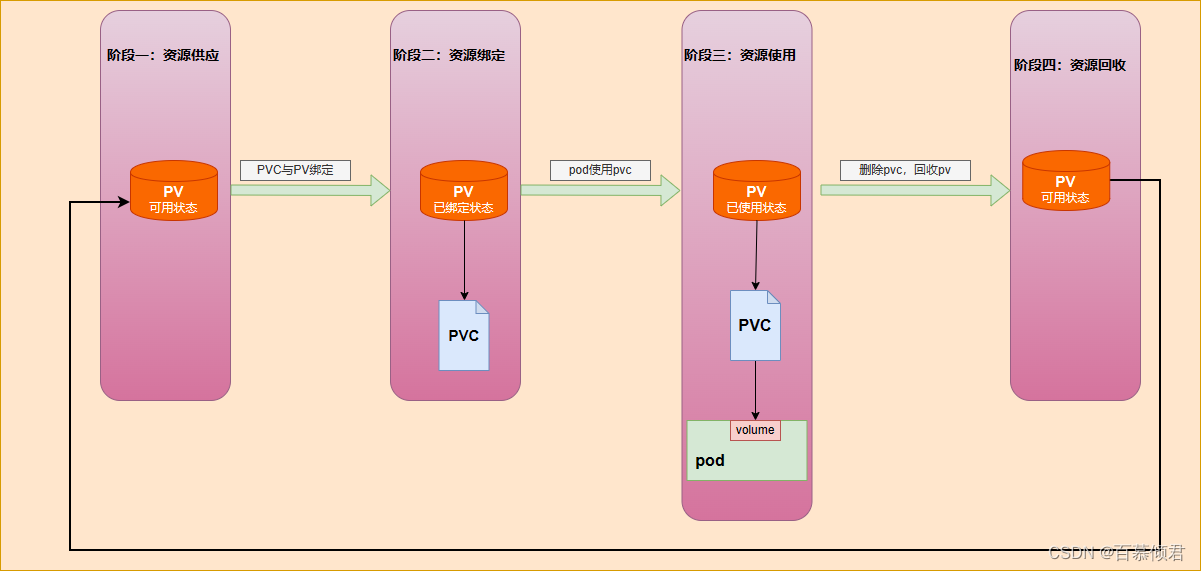
2.1.1 资源供应
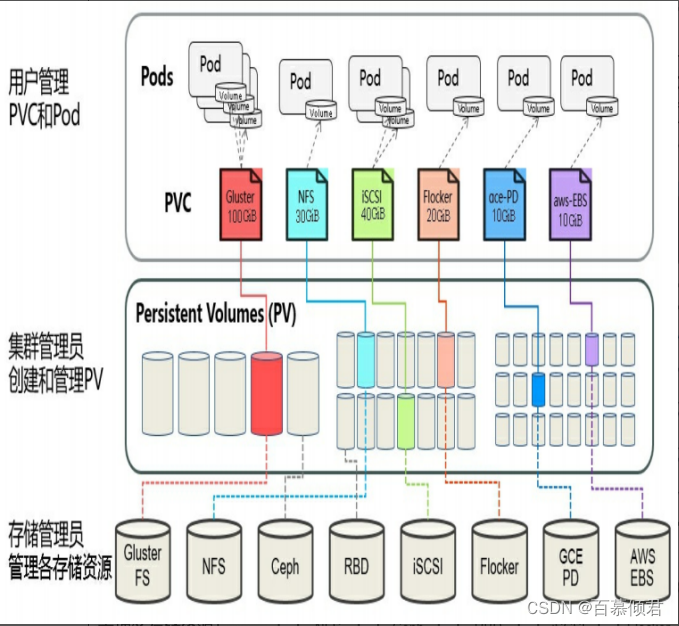
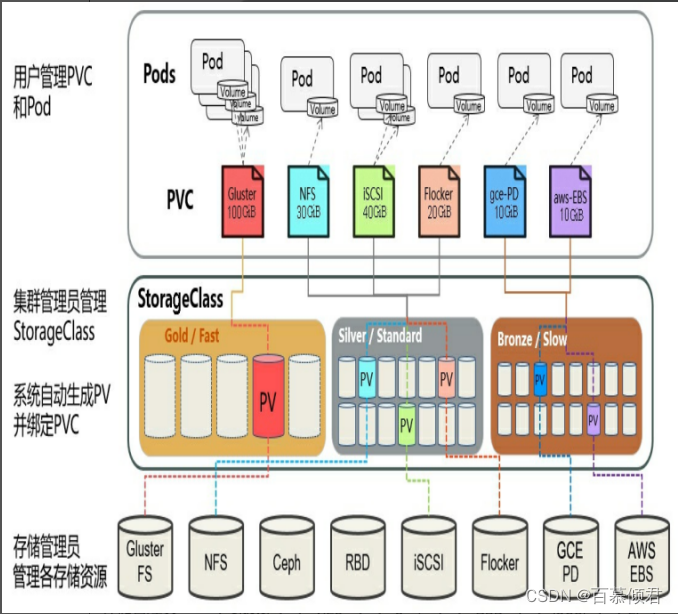
- K8s支持两种资源供应模式:静态模式(Static)和动态模式(Dynamic),资源供应的结果就是将适合的PV与PVC成功绑定。
- 静态模式:运维预先创建许多PV,在PV的定义中能够体现存储资源的特性。
- 动态模式:运维无须预先创建PV,而是通过StorageClass的设置对后端存储资源进行描述,标记存储的类型和特性。用户通过创建PVC对存储类型进行申请,系统将自动完成PV的创建及与PVC的绑定。如果PVC声明的Class为空"",则说明PVC不使用动态模式。另外,Kubernetes支持设置集群范围内默认的StorageClass设置,通过kube-apiserver开启准入控制器DefaultStorageClass,可以为用户创建的PVC设置一个默认的存储类StorageClass。
静态模式工作原理图:
动态模式原理图:
2.1.2 资源绑定
- 当用户定义PVC后,系统将根据PVC对存储资源的请求(存储空间和访问模式)在提前创建好的PV中选择一个满足要求的PV,并与PVC绑定。
- 若系统中没有满足要求的PV,PVC则会无限期处于Pending状态,直到系统管理员创建了一个符合其要求的PV。
- PV只能一个PVC绑定,绑定关系是一对一的,不会存在一对多的情况。
- 若PVC申请的存储空间比PV拥有的空间少,则整个PV的空间都能为PVC所用,可能会造成资源的浪费。
- 若资源供应使用的是动态模式,则系统在为PVC找到合适的StorageClass后,将自动创建一个PV并完成与PVC的绑定。
2.1.3 .资源使用
- 若Pod需要使用存储资源,则需要在yaml里定义Volume字段引用PVC类型的存储卷,将PVC挂载到容器内的某个路径下进行使用。
- 同一个PVC还可以被多个Pod同时挂载使用,在这种情况下,应用程序需要处理好多个进程访问同一个存储的问题。
使用中的存储对象保护机制:
- PV、PVC存储资源可以单独删除。当删除时,系统会检测存储资源当前是否正在被使用,若仍被使用,则对相关资源对象的删除操作将被推迟,直到没被使用才会执行删除操作,这样可以确保资源仍被使用的情况下不会被直接删除而导致数据丢失。
- 若删除的PVC有被使用时,则会等到使用它的Pod被删除之后再执行,此时PVC状态为Terminating。
- 若删除的PV有被使用时,则会等到绑定它的PVC被删除之后再执行,此时PV状态为Terminating。
2.1.4 资源回收
- 回收策略,指PVC删除之后,PV是去是留的一种策略。目前 PV 支持的策略有三种:
- Retain(保留): 保留数据,需要管理员手工清理数据。
- Recycle(回收):清除 PV 中的数据,效果相当于执行 rm -rf /ifs/kuberneres/*
- Delete(删除):与 PV 相连的后端存储同时删除
2.1.5 PVC资源扩容
- PVC在首次创建成功之后,还可以在使用过程中进行存储空间的扩容。
- 支持PVC扩容的存储类型有:AWSElasticBlockStore、AzureFile、AzureDisk、Cinder、FlexVolume、GCEPersistentDisk、Glusterfs、Portworx Volumes、RBD和CSI等。
扩容步骤:
- 先在PVC对应的StorageClass中设置参数“allowVolumeExpansion=true”。
- 修改pvc.yaml,将resources.requests.storage设置为一个更大的值。
扩容失败恢复步骤:
- 设置与PVC绑定的PV资源的回收策略为“Retain”。
- 删除PVC,此时PV的数据仍然存在。
- 删除PV中的claimRef定义,这样新的PVC可以与之绑定,结果将使得PV的状态为“Available”。
- 新建一个PVC,设置比PV空间小的存储空间申请,同时设置volumeName字段为PV的名称,结果将使得PVC与PV完成绑定。
- 恢复PVC的原回收策略
2.2 测试PV回收策略
2.2.1 Retain保留策略
- Retain策略表示在删除PVC之后,与之绑定的PV不会被删除,仅被标记为已释放(released)。PV中的数据仍然存在,在清空之前不能被新的PVC使用,需要管理员手工清理之后才能继续使用。
- 清理步骤:
- 删除PV资源对象,此时与该PV关联的某些外部存储提供商(例如AWSElasticBlockStore、GCEPersistentDisk、AzureDisk、Cinder等)的后端存储资产(asset)中的数据仍然存在。
- 手工清理PV后端存储资产(asset)中的数据。
- 手工删除后端存储资产。如果希望重用该存储资产,则可以创建一个新的PV与之关联。
1.如图。已有一个pv和pvc关联绑定,进入容器查看验证成功。
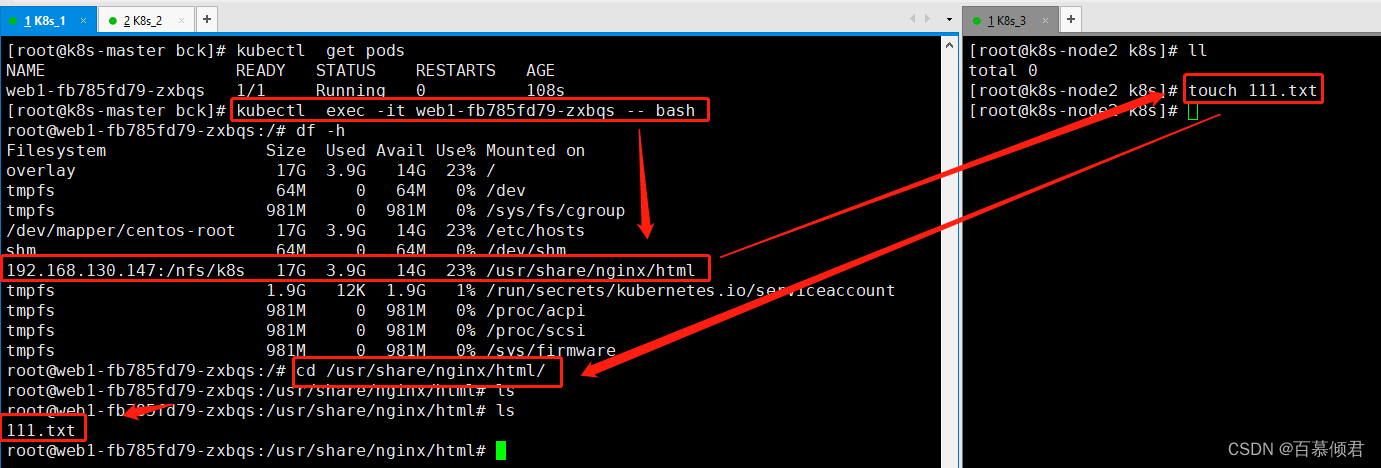
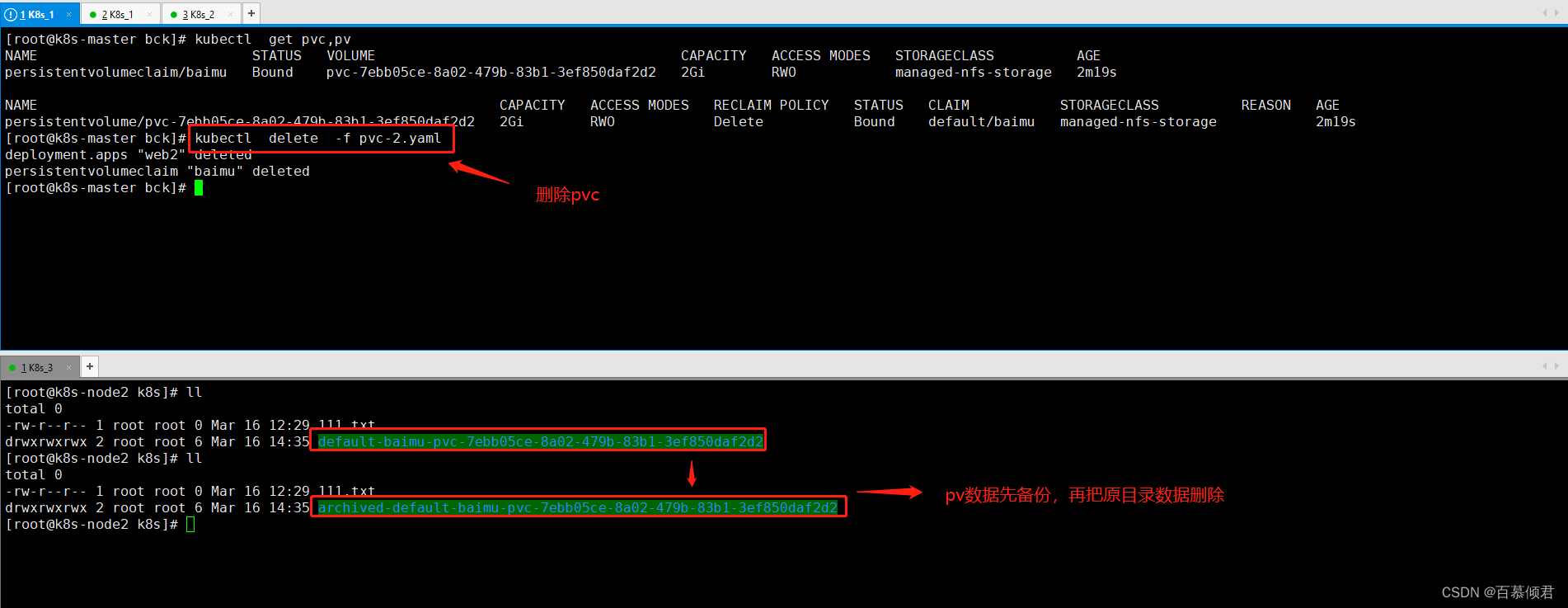
2.删除pvc,查看pv状态变为Released已释放状态。此时的pv不可用,需要把pv里面的数据转移到其他机器做备份。
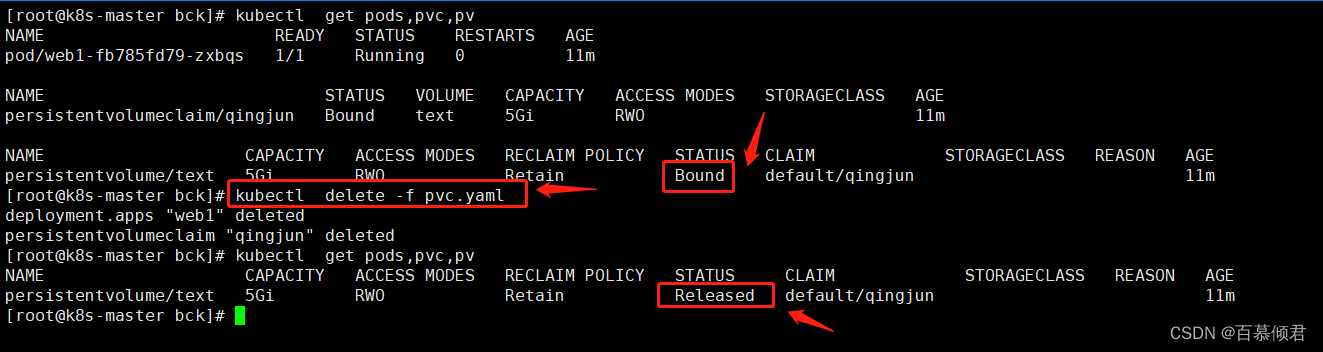
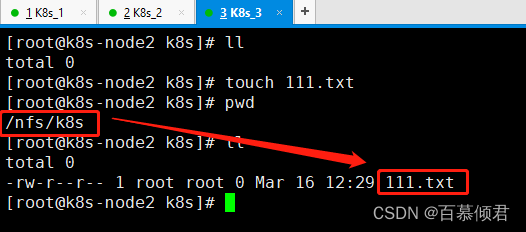
3.也就是nfs机器上的共享目录下的数据。
2.2.2 Recycle回收策略
- Recycle和Delete策略都是和存储类配合使用才能测出效果。
- 回收策略 Recycle 已被废弃,取而代之的建议方案是使用动态制备,单独创建一个pod来进行删除操作。
- 目前只有HostPort和NFS类型的Volume支持Recycle策略,其实现机制为运行rm-rf/thevolume/*命令,删除Volume目录下的全部文件,使得PV可以被新的PVC使用。
- 删除模板:
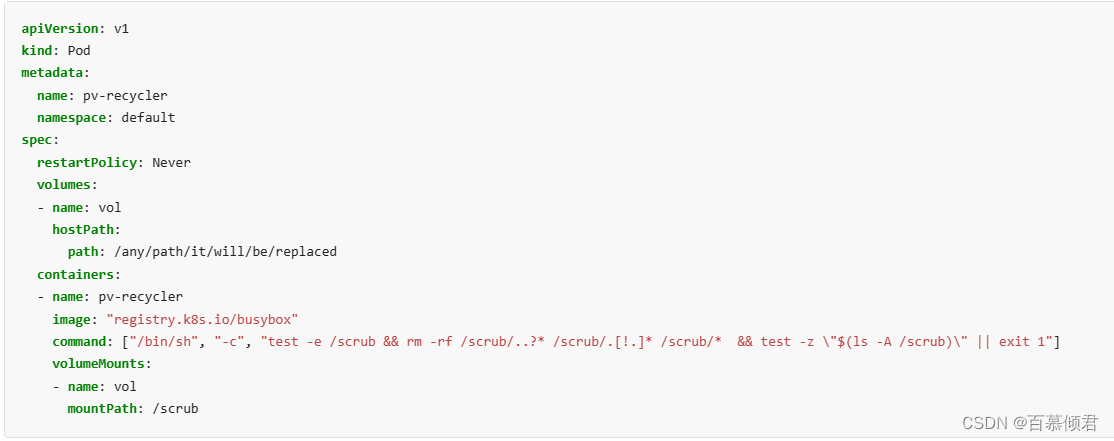
1.创建pv时,添加策略参数。
[root@k8s-master bck]# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: text1 ##PV名称,自定义。
spec:persistentVolumeReclaimPolicy: Recycle ##Recycle回收策略。capacity:storage: 10Gi ##容量。accessModes:- ReadWriteOncenfs:path: /nfs/k8s server: 192.168.130.147
2.导入pv.yaml后,再创建pvc与之绑定。
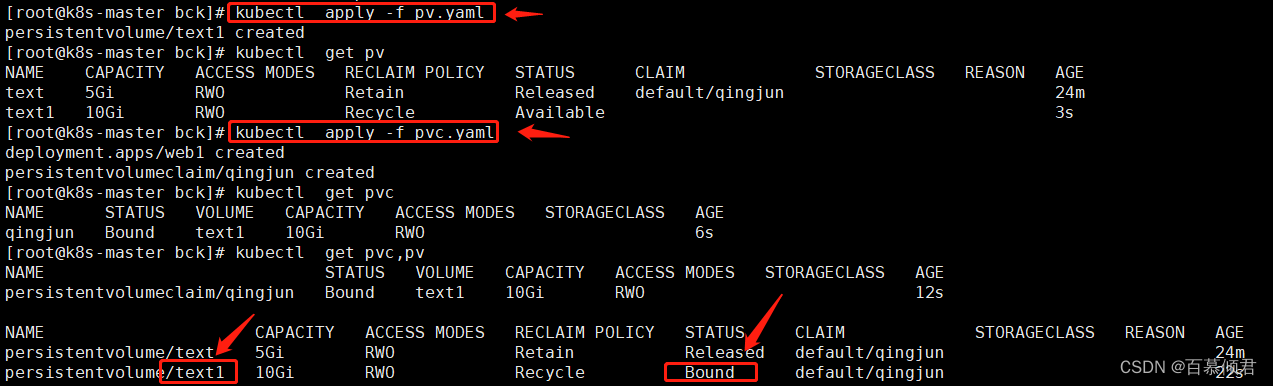
3.删除pvc,pv的数据被删除,也就是nfs服务器的共享目录下的数据被删除。

4.这里没有被删除是因为删除操作要拉取国外的一个镜像生成一个新容器,这个容器去删除pv里的数据,所以这里就拉取失败了。若要使用该策略,需要提前拉取这个镜像。


2.3 StorageClass动态供给
什么是静态供给?
- 我们前面演示时,都是手动写pv.yaml文件提前创建好存储大小不同的pv,当有pvc需求时就会根据需求大小去匹配对应的pvc从而绑定。关键词是手动创建,所以维护成本高。
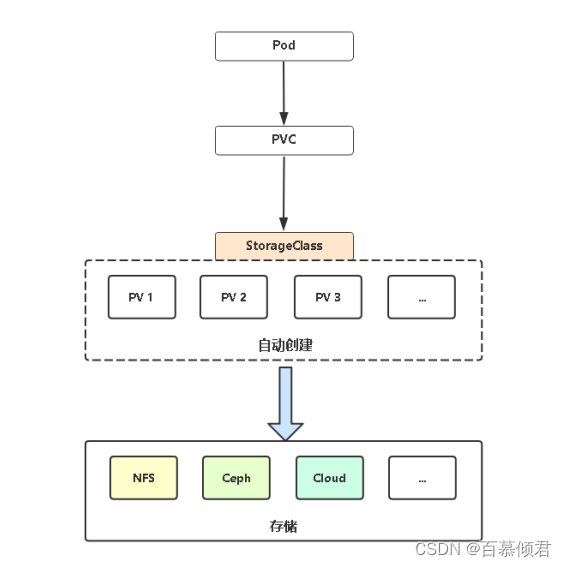
什么是动态供给?
- 为了解决静态供给的缺点,K8s开始支持PV动态供给,使用StorageClass对象实现。
- 当有pvc需求时,就可以自动创建pv与之绑定。关键词是自动生成。
静态供给概念图:
动态供给概念图:
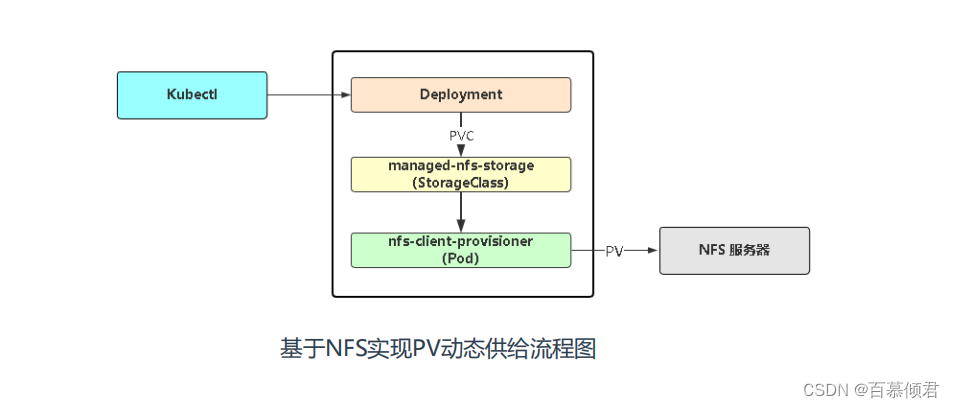
实现PV动态补给流程步骤:
- 部署动态供给程序,是以容器方式部署的,调取api server 获取指定自己的pvc。
- 创建pod时,在pod.yaml里定义pvc资源,并在pvc资源下面指定存储类。
- 调取后端nfs服务器创建共享目录,再调取api server创建pv,从而实现自动创建pv动作。
- 流程图:
2.3.1 部署存储插件
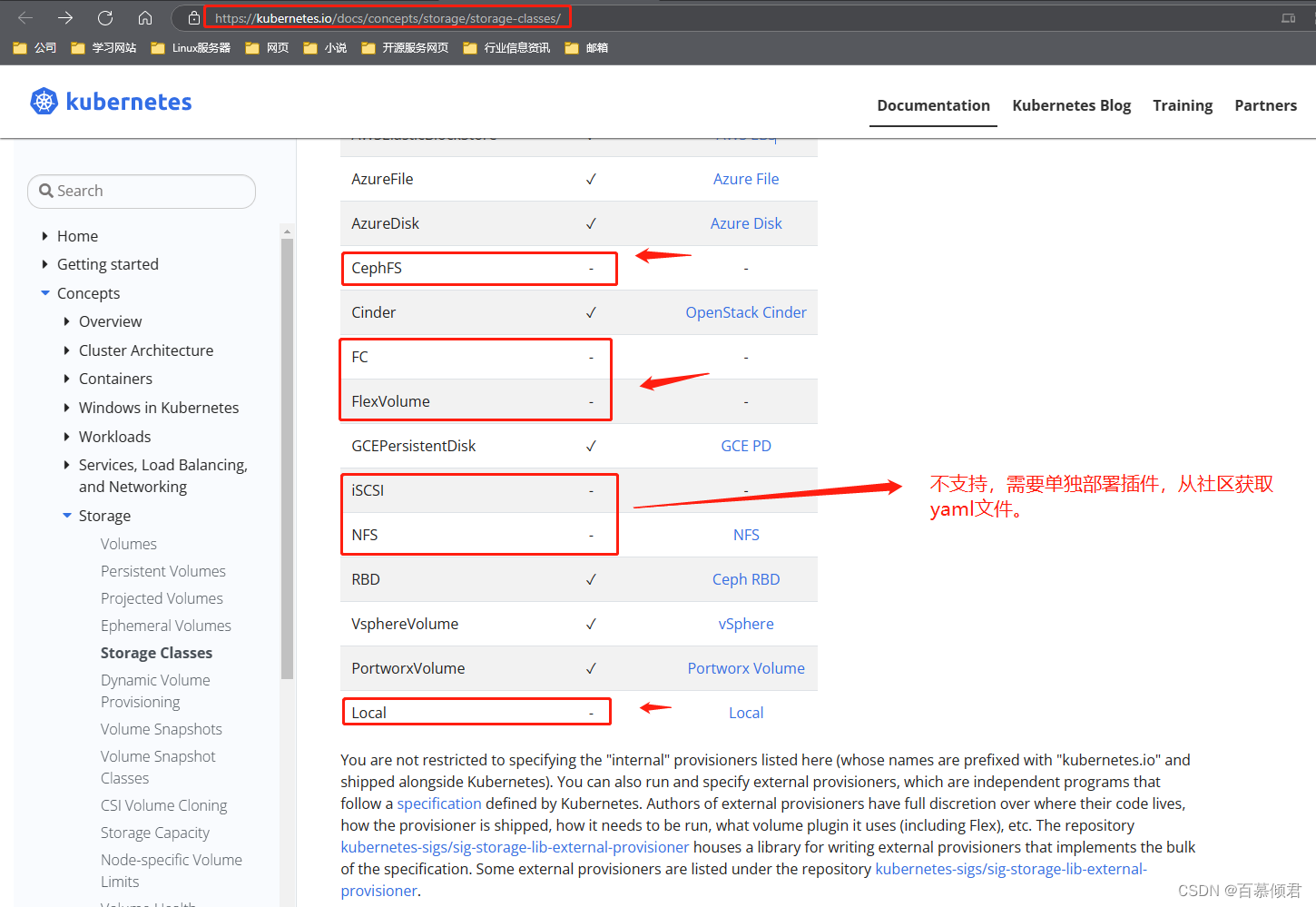
- 支持动态补给的存储插件
- 社区获取各存储插件yanl文件
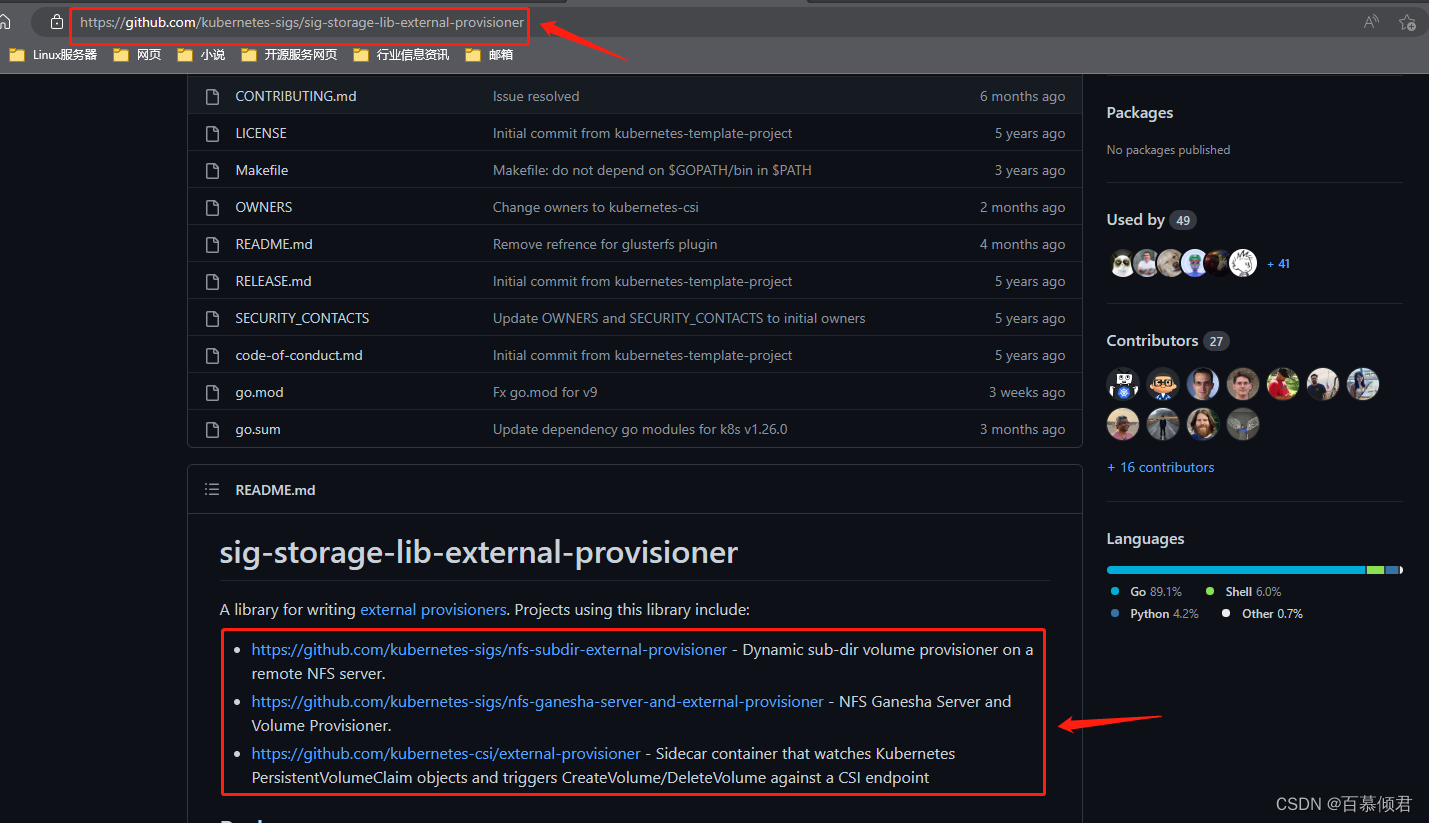
- nfs获取地址路径
- 文件地址,下载这三个yaml文件上传到服务器。
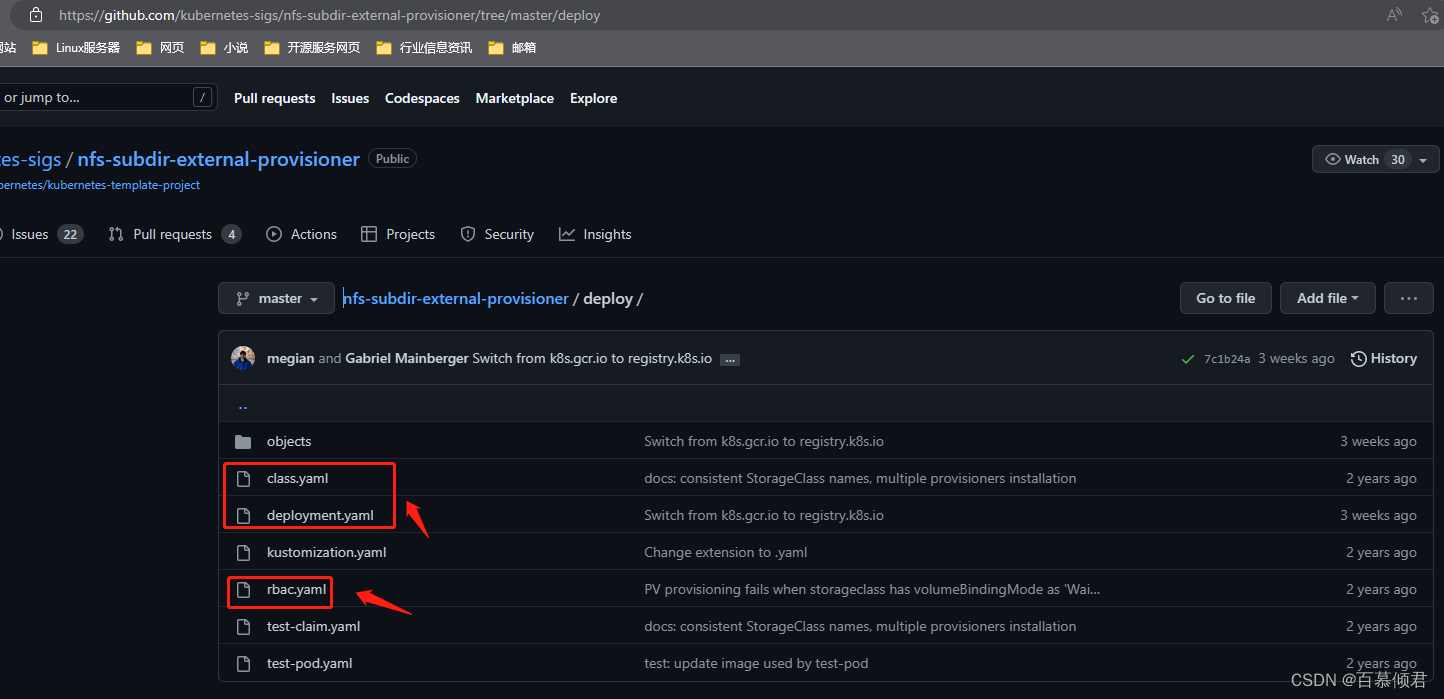
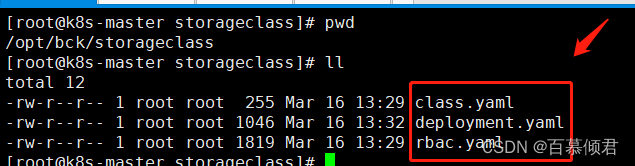
1.将这个三个文件上传至服务器,修改其中两个yaml文件参数。
[root@k8s-master storageclass]# cat class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: managed-nfs-storage ##自定义名称。
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:archiveOnDelete: "false"[root@k8s-master storageclass]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-client-provisionerlabels:app: nfs-client-provisioner# replace with namespace where provisioner is deployednamespace: default
spec:replicas: 1strategy:type: Recreateselector:matchLabels:app: nfs-client-provisionertemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisionercontainers:- name: nfs-client-provisionerimage: lizhenliang/nfs-subdir-external-provisioner:v4.0.1volumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: k8s-sigs.io/nfs-subdir-external-provisioner ##与class.yaml文件里的名称保持一致。- name: NFS_SERVERvalue: 192.168.130.147 ##修改nfs服务器地址- name: NFS_PATHvalue: /nfs/k8s ##修改nfs服务器共享目录。volumes:- name: nfs-client-rootnfs:server: 192.168.130.147 ##修改nfs服务器地址path: /nfs/k8s ##修改nfs服务器共享目录。
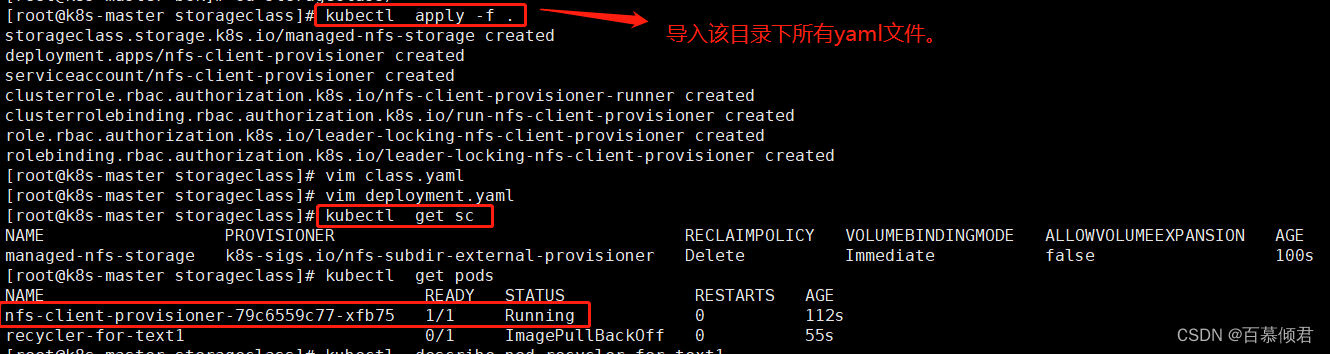
2.导入yaml文件,查看存储类。
- kubectl apply -f rbac.yaml # 授权访问apiserver
- kubectl apply -f deployment.yaml # 部署插件,需修改里面NFS服务器地址与共享目录。
- kubectl apply -f class.yaml # 创建存储类。
- kubectl get sc # 查看存储类
2.3.2 使用插件
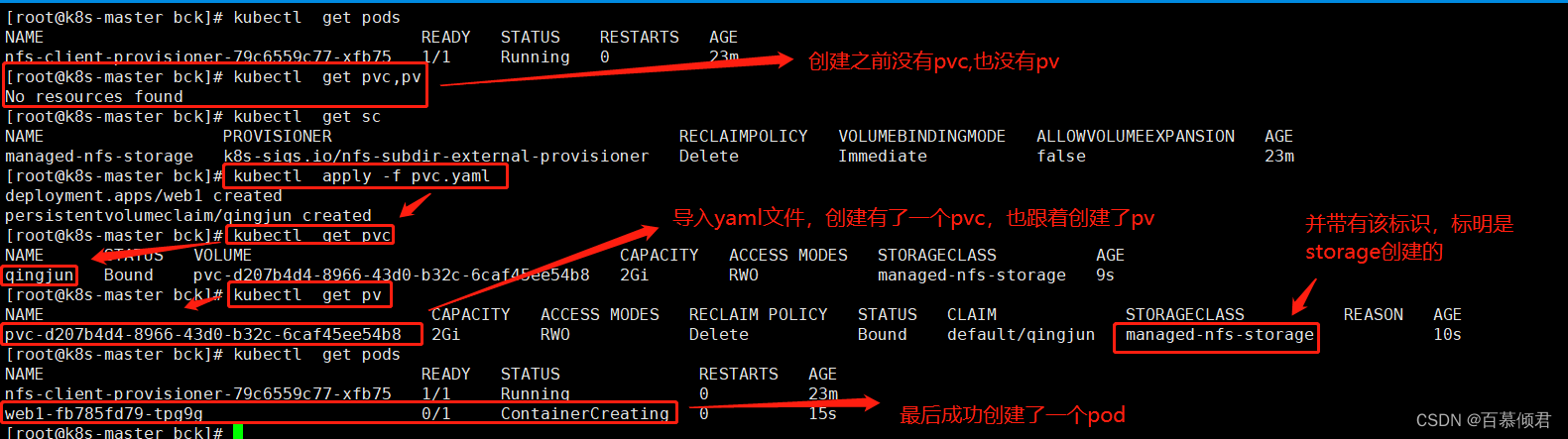
1.编辑yaml文件创建pvc,指定使用哪个存储类,也就是我们上面创建的sc。
[root@k8s-master bck]# cat pvc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: web1name: web1
spec:selector:matchLabels:app: web1template:metadata:labels:app: web1spec:containers:- image: nginxname: nginxvolumeMounts:- name: mqmountPath: /usr/share/nginx/htmlvolumes:- name: mqpersistentVolumeClaim:claimName: qingjun
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: qingjun
spec:storageClassName: "managed-nfs-storage" ##添加此行,指定使用已创建的sc。accessModes:- ReadWriteOnceresources:requests:storage: 2Gi
2.创建pvc后会自动创建一个pv,并且是绑定状态,带有storage标识,最后成功创建了deploy。
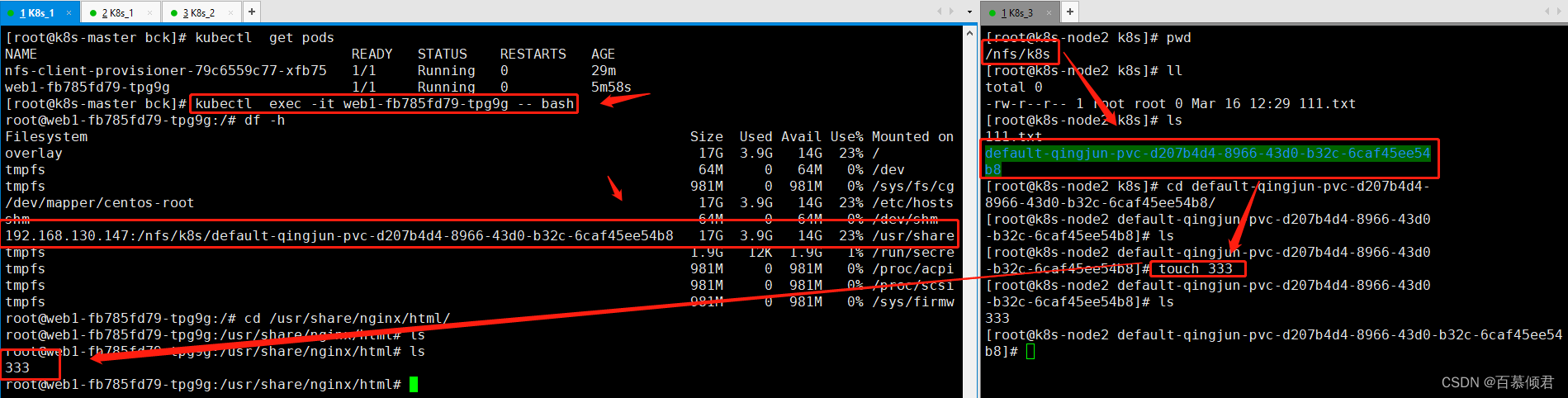
3.进入pod检查。会在共享目录里随机生成一个目录,
/nfs/k8s/default-qingjun-pvc-d207b4d4-8966-43d0-b32c-6caf45ee54b8default:代表命名空间。
qingjun:代表pvc名称。
pvc-d207b4d4-8966-43d0-b32c-6caf45ee54b8:代表pv名称。
4.此时删除pvc,会发现pv及其数据也会被删除,是因为默认的回收策略是“Delete”。


5.修改归档删除策略。
[root@k8s-master storageclass]# cat class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: managed-nfs-storage
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:archiveOnDelete: "true" ##默认为flase,代表直接删除不备份。修改成true代表先备份再删除。[root@k8s-master storageclass]# kubectl delete -f class.yaml #删除原来的。
[root@k8s-master storageclass]# kubectl apply -f class.yaml #再导入新的,更新。
三、StatefulSet
3.1 控制器介绍
StatefulSet控制器作用:
- StatefulSet控制器用于部署有状态应用,满足一些有状态应用的需求。
控制器特点:
- Pod有序的部署、扩容、删除和停止。
- Pod分配一个稳定的且唯一的网络标识。
- Pod分配一个独享的存储。
无状态与有状态:
- 无状态:Deployment控制器设计原则是,管理的所有Pod一模一样,提供同一个服务,也不考虑在哪台Node运行,可随意扩容和缩容。这种应用称为“无状态”。例如Web服务集群,每个工作节点上都有一个nginx容器,它们之间不需要互相业务“交流”,具备这个特点的应用就是“无状态”。
- 有状态:像分布式应用这种,需要部署多个实例,实例之间有依赖关系,例如主从关系、主备关系,这种应用称为“有状态”,例如MySQL主从、Etcd集群。
无状态应用特点:
- 每个pod一模一样。
- 每个pod之间没有连接关系。
- 使用共享存储。
有状态应用特点:
- 每个pod不对等,承担的角色不同。
- pod之间有连接关系。
- 每个pod有独立的存储。
StatefulSet与Deployment区别:
- 前者有身份,后者没有。
- 身份三要素:域名、主机名、存储(PVC)
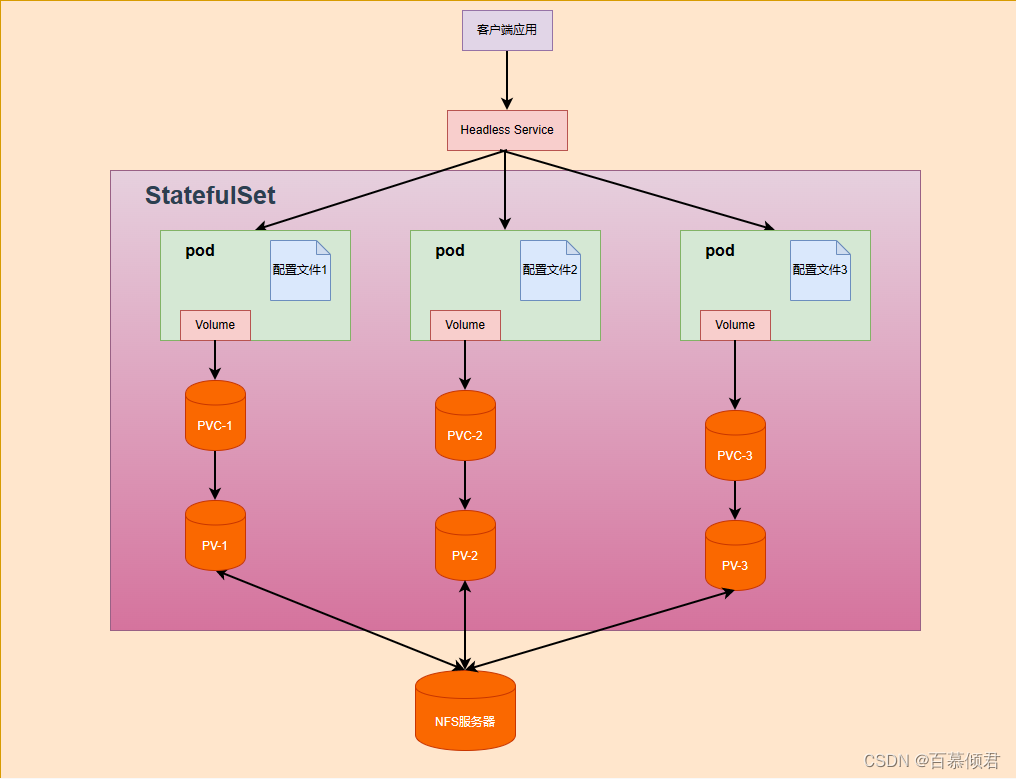
3.2 部署实践
需要稳定的网络ID(域名):
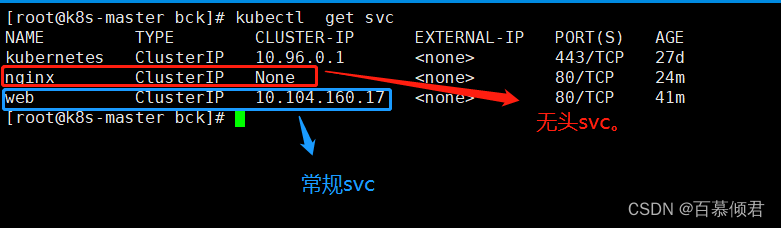
- 使用Headless Service(相比普通Service只是将spec.clusterIP定义为None)来维护Pod网络身份。
- 并且添加serviceName:“nginx”字段指定StatefulSet控制器要使用这个Headless Service。
- DNS解析名称:< statefulsetName-index >.< service-name > .< namespace-name >.svc.cluster.local
需要稳定的存储:
- StatefulSet的存储卷使用VolumeClaimTemplate创建,称为卷申请模板,当StatefulSet使用VolumeClaimTemplate创建一个PersistentVolume时,同样也会为每个Pod分配并创建一个编号的PVC。
- 第一步,先创建正常的svc,名为web。
1.创建一个deployment和svc。
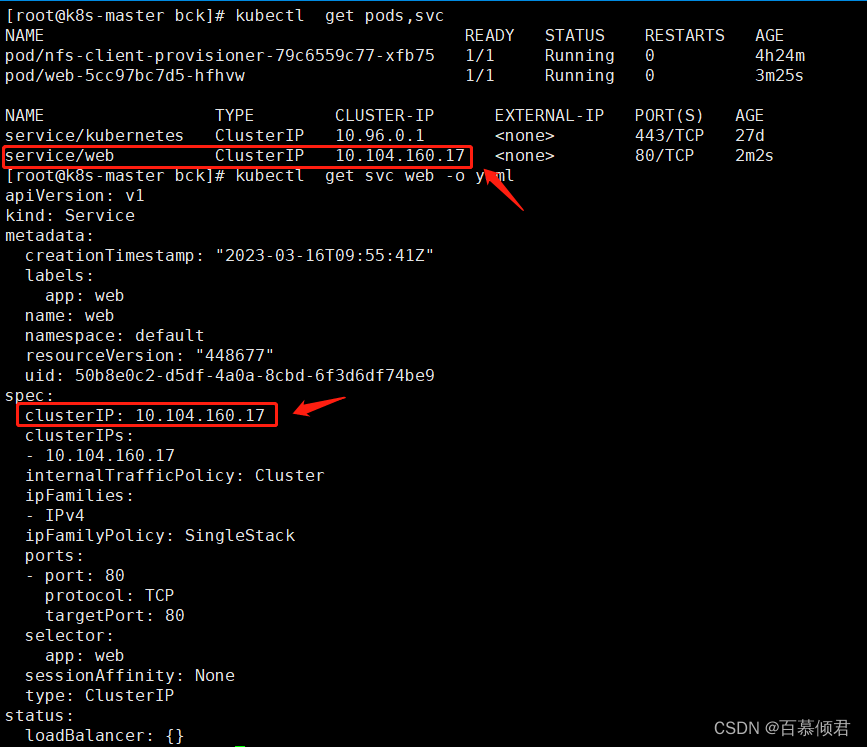
[root@k8s-master bck]# kubectl create deployment web --image=nginx
[root@k8s-master bck]# kubectl expose deployment web --port=80 --target-port=80
2.导出svc的yaml文件,可以看出这里的ClusterIP,这种情况下容器内的通信都是以这个ClusterIP来进行。
- 第二步,再创建statefulset,引用第二个状态为None的svc。
3.创建statefulset。yaml中是先创建了第二个svc,状态为None,再创建statefulset指定储存类和这个None状态的svc。
[root@k8s-master bck]# cat statefulset.yaml
apiVersion: v1
kind: Service
metadata:name: nginxlabels:app: nginx
spec:ports:- port: 80name: webclusterIP: None ##添加此行,使其变成一种识别标签,供后面的pod使用。selector:app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: nginx
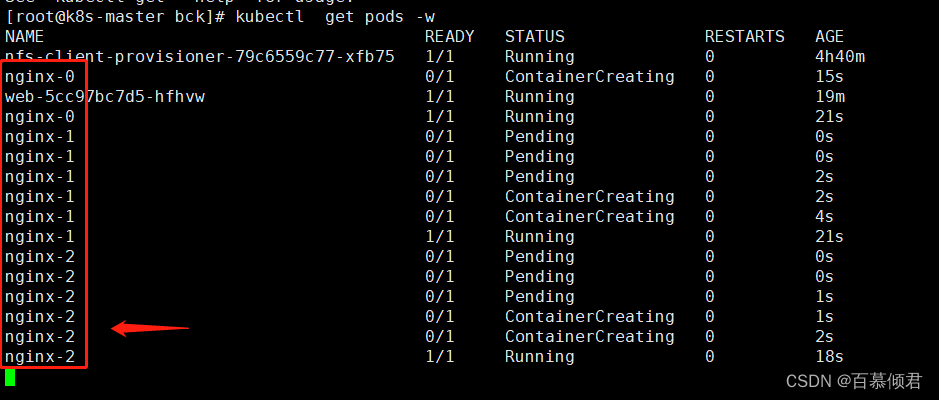
spec:selector:matchLabels:app: nginx serviceName: "nginx" ##指定哪个svc的名称。replicas: 3 minReadySeconds: 10 template:metadata:labels:app: nginx spec:terminationGracePeriodSeconds: 10containers:- name: nginximage: nginxports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates: ##statefulset独有配置,deployment不支持此配置。是给每个pod分配各自的pv、pvc。- metadata:name: wwwspec:accessModes: [ "ReadWriteOnce" ]storageClassName: "managed-nfs-storage" ##指定哪个存储类。使用kubectl get sc查看。resources:requests:storage: 1Gi
5.导入yaml,查看会依次创建三个Pod,因为yaml里指定的就是3个副本。
[root@k8s-master bck]# kubectl apply -f statefulset.yaml
6.对比两个svc。
7.创建测试容器bs。
[root@k8s-master bck]# kubectl run bs --image=busybox:1.28.4 -- sleep 240h
[root@k8s-master bck]# kubectl exec -it bs -- sh
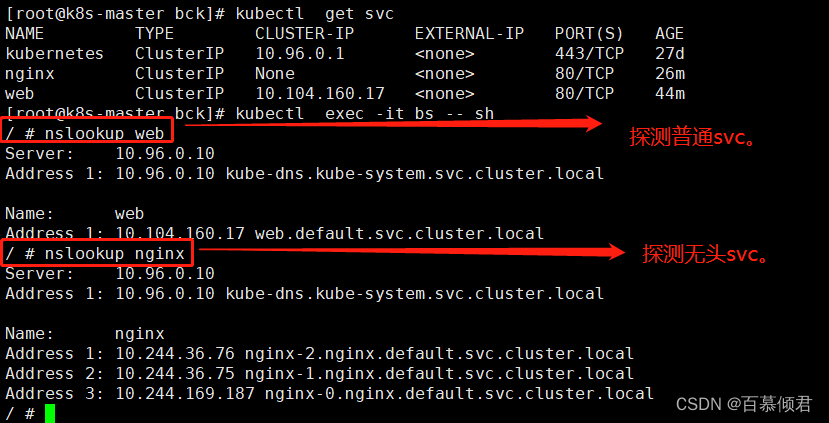
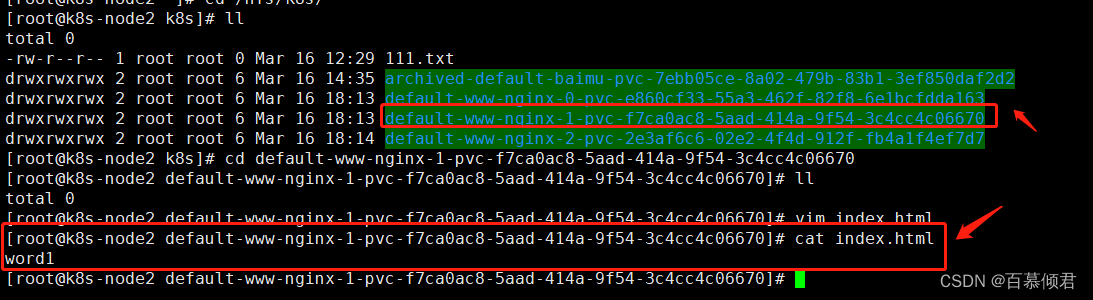
8.查看nfs服务器共享目录,进入对应目录,创建一个index.html文件,再次就能访问了。
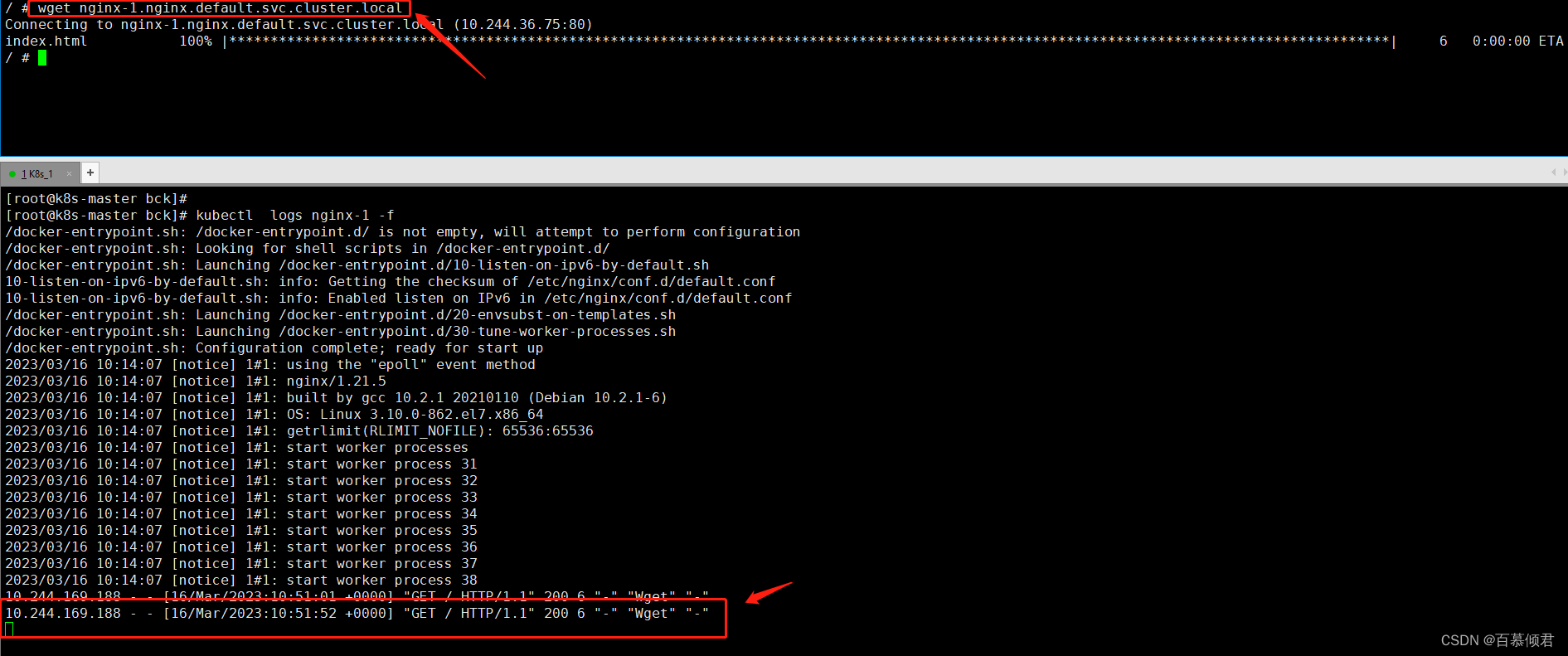
3.3 集群部署流程
- 集群一般都是三个节点,也就是需要提前写三个yaml文件。
- 需要写一些脚本。
- 通过配置文件中的节点名称、IP、存储目录区分3个pod的角色,。
部署一个etcd集群思路:
- 需要有3个副本,每个pod里只能指定一个镜像,所以需要保证启动的3个副本容器,每一个都能按照自己的角色 (配置文件) 启动。
- 根据当前主机名可以判定用户当前启动的是第几个容器,就用哪个配置文件后动。比如etcd-0.conf、etcd-1.conf、etcd-2.conf。
3.3.1 etcd案例
- etcd集群yaml文件实例
apiVersion: apps/v1
kind: StatefulSet
metadata:labels:k8s-app: infra-etcd-clusterapp: etcdname: infra-etcd-clusternamespace: default
spec:replicas: 3selector:matchLabels:k8s-app: infra-etcd-clusterapp: etcdserviceName: infra-etcd-clustertemplate:metadata:labels:k8s-app: infra-etcd-clusterapp: etcdname: infra-etcd-clusterspec:containers:- image: lizhenliang/etcd:v3.3.8imagePullPolicy: Alwayscommand:- /bin/sh- -ec- |HOSTNAME=$(hostname)echo "etcd api version is ${ETCDAPI_VERSION}"# 生成连接etcd集群节点字符串# 例如http://etcd-0.etcd.default:2379,http://etcd-1.etcd.default:2379,http://etcd-2.etcd.default:2379eps() {EPS=""for i in $(seq 0 $((${INITIAL_CLUSTER_SIZE} - 1))); doEPS="${EPS}${EPS:+,}http://${SET_NAME}-${i}.${SET_NAME}.${CLUSTER_NAMESPACE}:2379"doneecho ${EPS}}# 获取etcd节点成员hash值,例如740e031d5b17222dmember_hash() {etcdctl member list | grep http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380 | cut -d':' -f1 | cut -d'[' -f1}# 生成初始化集群节点连接字符串# 例如etcd-0=http://etcd-0.etcd.default:2380,etcd-1=http://etcd-1.etcd.default:2380,etcd-2=http://etcd-1.etcd.default:2380initial_peers() {PEERS=""for i in $(seq 0 $((${INITIAL_CLUSTER_SIZE} - 1))); doPEERS="${PEERS}${PEERS:+,}${SET_NAME}-${i}=http://${SET_NAME}-${i}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380"doneecho ${PEERS}}# etcd-SET_IDSET_ID=${HOSTNAME##*-}# 向已有集群添加成员 (假设所有pod都初始化完成)if [ "${SET_ID}" -ge ${INITIAL_CLUSTER_SIZE} ]; thenexport ETCDCTL_ENDPOINTS=$(eps)# 判断成员是否添加MEMBER_HASH=$(member_hash)if [ -n "${MEMBER_HASH}" ]; then# 成员hash存在,但由于某种原因失败# 如果datadir目录没创建,可以删除该成员# 检索新的hash值if [ "${ETCDAPI_VERSION}" -eq 3 ]; thenETCDCTL_API=3 etcdctl --user=root:${ROOT_PASSWORD} member remove ${MEMBER_HASH}elseetcdctl --username=root:${ROOT_PASSWORD} member remove ${MEMBER_HASH}fifiecho "添加成员"rm -rf /var/run/etcd/*# 确保etcd目录存在mkdir -p /var/run/etcd/# 休眠60s,等待端点准备好echo "sleep 60s wait endpoint become ready,sleeping..."sleep 60if [ "${ETCDAPI_VERSION}" -eq 3 ]; thenETCDCTL_API=3 etcdctl --user=root:${ROOT_PASSWORD} member add ${HOSTNAME} --peer-urls=http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380 | grep "^ETCD_" > /var/run/etcd/new_member_envselseetcdctl --username=root:${ROOT_PASSWORD} member add ${HOSTNAME} http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380 | grep "^ETCD_" > /var/run/etcd/new_member_envsfiif [ $? -ne 0 ]; thenecho "member add ${HOSTNAME} error."rm -f /var/run/etcd/new_member_envsexit 1ficat /var/run/etcd/new_member_envssource /var/run/etcd/new_member_envs# 启动etcdexec etcd --name ${HOSTNAME} \--initial-advertise-peer-urls http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380 \--listen-peer-urls http://0.0.0.0:2380 \--listen-client-urls http://0.0.0.0:2379 \--advertise-client-urls http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2379 \--data-dir /var/run/etcd/default.etcd \--initial-cluster ${ETCD_INITIAL_CLUSTER} \--initial-cluster-state ${ETCD_INITIAL_CLUSTER_STATE}fi# 检查前面etcd节点是否启动,启动后再启动本节点for i in $(seq 0 $((${INITIAL_CLUSTER_SIZE} - 1))); dowhile true; doecho "Waiting for ${SET_NAME}-${i}.${SET_NAME}.${CLUSTER_NAMESPACE} to come up"ping -W 1 -c 1 ${SET_NAME}-${i}.${SET_NAME}.${CLUSTER_NAMESPACE} > /dev/null && breaksleep 1sdonedoneecho "join member ${HOSTNAME}"# 启动etcd节点exec etcd --name ${HOSTNAME} \--initial-advertise-peer-urls http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380 \--listen-peer-urls http://0.0.0.0:2380 \--listen-client-urls http://0.0.0.0:2379 \--advertise-client-urls http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2379 \--initial-cluster-token etcd-cluster-1 \--data-dir /var/run/etcd/default.etcd \--initial-cluster $(initial_peers) \--initial-cluster-state newenv:- name: INITIAL_CLUSTER_SIZE # 初始集群节点数量value: "3"- name: CLUSTER_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: ETCDAPI_VERSIONvalue: "3"- name: ROOT_PASSWORDvalue: '@123#'- name: SET_NAMEvalue: "infra-etcd-cluster"- name: GOMAXPROCSvalue: "4"# 关闭pod,自动清理该节点信息lifecycle:preStop:exec:command:- /bin/sh- -ec- |HOSTNAME=$(hostname)member_hash() {etcdctl member list | grep http://${HOSTNAME}.${SET_NAME}.${CLUSTER_NAMESPACE}:2380 | cut -d':' -f1 | cut -d'[' -f1}eps() {EPS=""for i in $(seq 0 $((${INITIAL_CLUSTER_SIZE} - 1))); doEPS="${EPS}${EPS:+,}http://${SET_NAME}-${i}.${SET_NAME}.${CLUSTER_NAMESPACE}:2379"doneecho ${EPS}}export ETCDCTL_ENDPOINTS=$(eps)SET_ID=${HOSTNAME##*-}# 从集群中移出etcd节点成员if [ "${SET_ID}" -ge ${INITIAL_CLUSTER_SIZE} ]; thenecho "Removing ${HOSTNAME} from etcd cluster"if [ "${ETCDAPI_VERSION}" -eq 3 ]; thenETCDCTL_API=3 etcdctl --user=root:${ROOT_PASSWORD} member remove $(member_hash)elseetcdctl --username=root:${ROOT_PASSWORD} member remove $(member_hash)fiif [ $? -eq 0 ]; then# 删除数据目录rm -rf /var/run/etcd/*fifiname: infra-etcd-clusterports:- containerPort: 2380name: peerprotocol: TCP- containerPort: 2379name: clientprotocol: TCPresources:limits:cpu: "1"memory: 1Girequests:cpu: "0.3"memory: 300MivolumeMounts:- mountPath: /var/run/etcdname: datadirupdateStrategy:type: OnDeletevolumeClaimTemplates:- metadata:name: datadirspec:storageClassName: "managed-nfs-storage" accessModes:- ReadWriteOnceresources:requests:storage: 2Gi
---
apiVersion: v1
kind: Service
metadata:labels:k8s-app: infra-etcd-clusterapp: infra-etcdname: infra-etcd-clusternamespace: default
spec:clusterIP: Noneports:- name: infra-etcd-cluster-2379port: 2379protocol: TCPtargetPort: 2379- name: infra-etcd-cluster-2380port: 2380protocol: TCPtargetPort: 2380selector:k8s-app: infra-etcd-clusterapp: etcdtype: ClusterIP
3.3.2 zookeeper示例
- zookeeper参考地址
apiVersion: v1
kind: Service
metadata:name: zk-hslabels:app: zk
spec:ports:- port: 2888name: server- port: 3888name: leader-electionclusterIP: Noneselector:app: zk
---
apiVersion: v1
kind: Service
metadata:name: zk-cslabels:app: zk
spec:ports:- port: 2181name: clientselector:app: zk
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:name: zk-pdb
spec:selector:matchLabels:app: zkmaxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: zk
spec:selector:matchLabels:app: zkserviceName: zk-hsreplicas: 3updateStrategy:type: RollingUpdatepodManagementPolicy: OrderedReadytemplate:metadata:labels:app: zkspec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- zktopologyKey: "kubernetes.io/hostname"containers:- name: kubernetes-zookeeperimagePullPolicy: Alwaysimage: "registry.k8s.io/kubernetes-zookeeper:1.0-3.4.10"resources:requests:memory: "1Gi"cpu: "0.5"ports:- containerPort: 2181name: client- containerPort: 2888name: server- containerPort: 3888name: leader-electioncommand:- sh- -c- "start-zookeeper \--servers=3 \--data_dir=/var/lib/zookeeper/data \--data_log_dir=/var/lib/zookeeper/data/log \--conf_dir=/opt/zookeeper/conf \--client_port=2181 \--election_port=3888 \--server_port=2888 \--tick_time=2000 \--init_limit=10 \--sync_limit=5 \--heap=512M \--max_client_cnxns=60 \--snap_retain_count=3 \--purge_interval=12 \--max_session_timeout=40000 \--min_session_timeout=4000 \--log_level=INFO"readinessProbe:exec:command:- sh- -c- "zookeeper-ready 2181"initialDelaySeconds: 10timeoutSeconds: 5livenessProbe:exec:command:- sh- -c- "zookeeper-ready 2181"initialDelaySeconds: 10timeoutSeconds: 5volumeMounts:- name: datadirmountPath: /var/lib/zookeepersecurityContext:runAsUser: 1000fsGroup: 1000volumeClaimTemplates:- metadata:name: datadirspec:accessModes: [ "ReadWriteOnce" ]resources:requests:storage: 10Gi
这篇关于K8s基础10——数据卷、PV和PVC、StorageClass动态补给、StatefulSet控制器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








