本文主要是介绍基于移动设备的OCR识别工作进展(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 模型调研
模型1:Tesseract-OCR
模型2:PaddleOCR
- Android上面有体验版的demo:https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
- PP-OCR模型:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/README_ch.md
- 源代码:https://github.com/PaddlePaddle/PaddleOCR
2 PaddleOCR模型
2.1 基于Android端的PaddleOCR模型部署
详细情况见:http://t.csdn.cn/HjBd8
2.2 手机端Demo测试结果(基于ch_ppocr_mobile_v2.0)
详细情况见:https://blog.csdn.net/weixin_39133209/article/details/126301841
面临的主要问题有:英文模型识别还有问题。

2.3 PaddleOCR安卓Demo存在的问题
http://t.csdn.cn/Irzor
3 MNN推理模型
3.1 技术调研
https://github.com/alibaba/mnn
https://www.mnn.zone/m/0.3/
https://github.com/alibaba/MNNKit
https://www.yuque.com/mnn/cn
https://www.yuque.com/mnn/cn/build_android
3.1.1 Android + MNN + OCR
https://github.com/luoqianlin/mnn-android-ocr-demo
这个工程是2021年2月份的模型了,不过也可以借鉴。
3.1.2 linux/macos/windows + MNN + OCR
https://github.com/DayBreak-u/chineseocr_lite
3.2 我们的工作:Android 编译 MNN及MNN 模型转换
https://blog.csdn.net/qq_40206924/article/details/126570574
3.3 我们的工作:如何利用已有so文件的模型
https://www.linuxquestions.org/questions/programming-9/reading-apis-from-a-so-file-822438/
这个链接提供了四个思路来使用已有so文件的API:
(1)反编译,去看头文件;
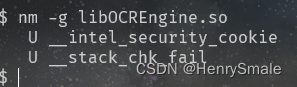
(2)命令:
nm -g your.so | awk 'NF3 && $2"T" { print }"
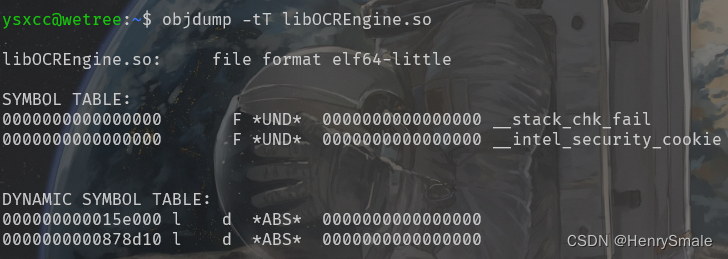
(3)命令:
objdump -d -j .text xx.so
(4)readelf工具
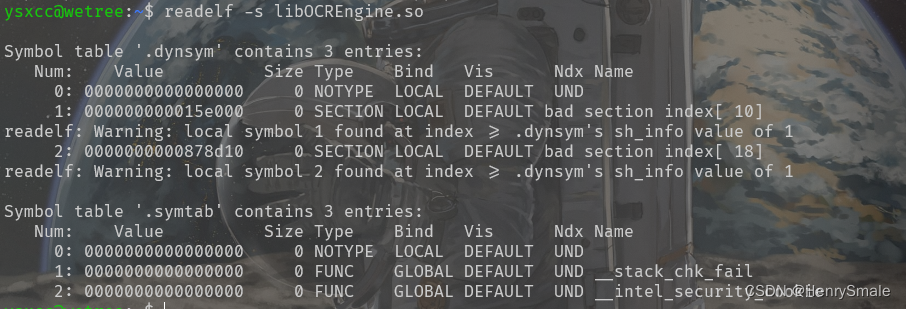
4 NCNN模型
4.1 技术调研
https://ncnn.docsforge.com/
4.1 Android + NCNN + OCR
https://github.com/benjaminwan/OcrLiteAndroidNcnn
这个工程主要支持中文识别,如果是英文识别,还需要更换模型。
4.2 我们的工作:Android 编译 NCNN及测试OcrLiteAndroidNcnn项目
https://blog.csdn.net/qq_44309220/article/details/126582847
OcrLiteAndroidNcnn项目效果测试:
http://t.csdn.cn/dZ1nq
5 模型对比实验
5.1 PaddleOCR和扫描王之间的对比
http://t.csdn.cn/69YAv
5.2 Chinese-Lite、PaddleOCR和扫描王之间的对比
对比的产品有:
- 基于NCNN框架构建的OcrLiteAndroidNcnn
- PaddleOCRv2
- 竞品扫描王
对比的结果如下:
1、较暗图片 Chinese-Lite 弱于PaddleOCR 。Chinese-Lite弱于竞品
2、文字密度:对于稀疏文字,PaddleOCR 效果和 Chinese-Lite 不相上下。Chinese-Lite检测优于竞品,识别弱于竞品;
对于密集文字,Chinese-Lite 检测和 PaddleOCR 同样优秀,识别优于PaddleOCR。Chinese-Lite检测优于竞品,识别弱于竞品。
3、颜色:对于字体颜色,Chinese-Lite 检测和识别优于PaddleOCR。Chinese-Lite 识别弱于竞品;
对于背景颜色,Chinese-Lite 检测优于 PaddleOCR,不会出现漏检,识别率弱于PaddleOCR。Chinese-Lite 识别率弱于竞品。
4、不同角度:
60度:Chinese-Lite 检测和识别优于PaddleOCR,但识别中无法还原正确语序。Chinese-Lite 检测和识别优于竞品。
120度:Chinese-Lite 不能检测和识别。
180度:Chinese-Lite 检测弱于 PaddleOCR,识别优于 PaddleOCR。Chinese-Lite 识别弱于竞品。
5、扭曲变形:
Chinese-Lite 检测识别优于 PaddleOCR,基本能够检测识别出大部分内容;Chinese-Lite 识别弱于竞品。
6、手写体:
Chinese-Lite 对手写体几乎不能检测
总体而言:
PaddleOCR和Chinese-Lite的对比:
- 在检测方面:PaddleOCR 尽可能多地以行为单位,而Chinese-Lite 更多是以几个单词为一个单位。猜测这就是Chinese-Lite会在褶皱方面优于PaddleOCR的原因。PaddleOCR除了褶皱方面以外,总体要优于Chinese-Lite;
- 在识别方面:PaddleOCR 更注重识别出每个字符,而Chinese-Lite 更注重分词(很少出现字母连贯);
- 在识别速度方面:PaddleOCR优于Chinese-Lite。
Chinese-Lite和竞品的对比:
- 竞品整体的效果还是要强于 Chinese-Lite。
先基于paddleocr进行开发,然后去研究Chinese-lite的一些优点,利用Chinese-lite的优点来改进paddleocr的模型。
这篇关于基于移动设备的OCR识别工作进展(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







