本文主要是介绍MAR for the segmentation of the intra cochlear anatomy in CT images of the ear with 3D cGAN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 一、介绍
- (一)医学背景
- (二)相关工作
- 二、方法
- (一)网络结构
- (二)损失函数
- 1.对抗损失
- 2.重建损失
- 3.总体损失
- 三、实验
- (一)实验数据
- (二)实验过程
- 1.对比实验
- 2.评价指标
- (三)实验结果
- 1.point-to-point errors
- 2. MSSIM
- 3.消融实验
- 总结
摘要
原文:
WANG, JIANING, NOBLE, JACK H., DAWANT, BENOIT M… Metal artifact reduction for the segmentation of the intra cochlear anatomy in CT images of the ear with 3D-conditional GANs[J]. Medical image analysis,2019. DOI:10.1016/j.media.2019.101553.
背景:人工耳蜗(CIs)是通过外科手术植入的神经修复设备,用于治疗重度听力损失。CIs在植入后基于植入位置和耳蜗内解剖结构(ICA)进行编程,以改善听力。因此,使用植入前后的CT图像,来定位植入电极和ICA的相对位置十分重要。
问题:有些患者没有植入前的CT图像,而植入后CT图像由于金属伪影的影响,图像质量较差,之前作者也开发了两种算法来分割植入后CT图像的ICA,但效果远比使用植入前CT图像的要查。
方法:通过GAN网络,从植入后的CT图像中生成植入前的CT图像,也就是去除金属伪影。
结果:3D-cGAN大大改善了直接对植入后CT图像进行分割的结果,且MSSIM比2D-cGAN的值有显著提高。
一、介绍
(一)医学背景
耳蜗是内耳的一个组成部分。它是一个螺旋形腔,位于骨迷路内,包含两个主要腔:前庭阶和鼓室阶。下图为耳蜗内解剖结构(ICA). CI用于改善听力,需要在植入后进行编程,而CI编程的效果对CI电极和ICA结构之间的空间关系敏感。因此需要定位CI和ICA的相对关系,首先要把ICA分割出来。
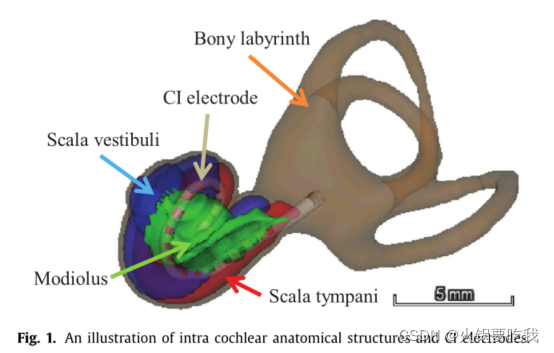
(二)相关工作
- Zhao等人提出在植入后CT图像中自动定位CI电极的方法。
Zhao, Y., Dawant, B.M., Labadie, R.F., Noble, J.H., 2018. Automatic localization of closely-spaced cochlear implant electrode arrays in clinical CTs. Med. Phys. 45 (11), 5030–5040. doi: 10.1002/mp.13185 .
Zhao, Y., Chakravorti, S., Labadie, R.F., Dawant, B.M., Noble, J.H., 2019. Automatic graph-based method for localization of cochlear implant electrode arrays in clinical CT with sub-voxel accuracy. Med. Image Anal. 52, 1–12. doi: 10.1016/j.media.2018.11.005 . - PreCTseg:为了在植入前CT图像中对ICA进行定位,其中ICA仅部分可见,Noble等人开发了一种算法,称为PreCTseg。PreCTseg依赖于一个主动加权模型,该模型通过高分辨率的microCT扫描创建,其中ICA结构清晰可见。
Noble, J.H., Labadie, R.F., Majdani, O., Dawant, B.M., 201 1. Automatic segmentation of intracochlear anatomy in conventional CT. IEEE Trans. Biomed. Eng. 58 (9), 2625–2632. doi: 10.1109/TBME.201 1.2160262. - PostCTseg1:单侧植入CI电极,通过扫描另一侧未植入电极的耳蜗,并分割它的ICA结构,然后将分割的ICA结构映射到植入耳。
- PostCTseg2:双侧植入CI电极,基于标准形状模型分割ICA结构。
Noble, J.H., Labadie, R.F., Gifford, R.H., Dawant, B.M., 2013. Image-guidance enables new methods for customizing cochlear implant stimulation strategies. IEEE Trans. Neural Syst. Rehabil. Eng. 21 (5), 820–829. doi: 10.1 109/TNSRE.2013. 2253333 .
二、方法
(一)网络结构
为了消除植入后CT图像的金属伪影,采用了cGAN这一模型。cGAN由生成器G和判别器D组成。该网络的输入为植入后CT图像x,首先由生成器生成无伪影的图像G(x),然后判别器需要判断生成图像G(x)和植入前图像y的真伪。D的训练目标是能正确区分G(x)和y,而G的目标是使D不能正确区分G(x)和y,从而欺骗D。两者交替进行训练,最后G能所生成的图像G(x)达到亦真亦假。
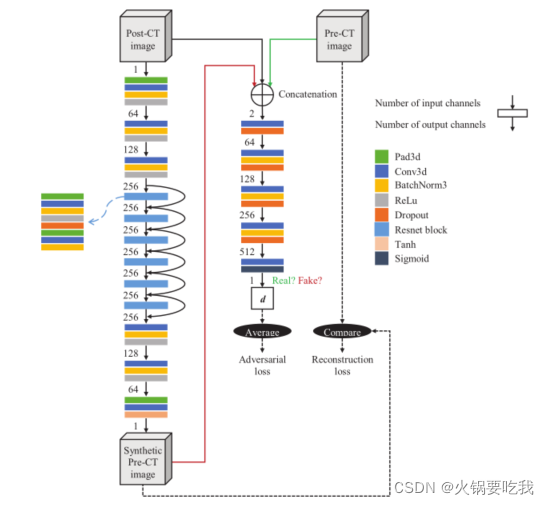
上图为网络结构图,左侧一列为生成器G,中间一列为判别器D。生成器由3个卷积模块+6个resnet模块+3个卷积模块组成,其输入为3D植入后CT图像,输出为生成的植入前CT图像。判别器为一个全卷积网络,输入为植入后CT图像和植入前CT图像的拼接(或植入后CT图像和生成图像的拼接),判别器输出 d 是一个3D数组,di,j,k 的值表明输入图像的第(i,j,k)个patch是真的或者假的,最后的输出是 d 的平均值。
(二)损失函数
1.对抗损失
GAN网络的普遍损失函数,在这就不介绍了。通过上述训练目标的讲解,应该比较好理解。
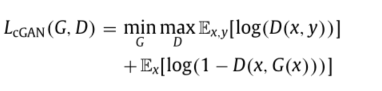
2.重建损失
2017年Isola等人提出仅有对抗损失是不足够的,而将传统重建损失与对抗损失结合有利于提高网络性能。比较常用的重建损失为L1 loss,即:
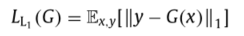
Isola, P., Zhu, J., Zhou, T., Efros, A .A ., 2017. Image-to-image translation with conditional adversarial networks. In: CVPR arXiv: 1611.070 04 .
在这篇文章中,最终的目的是在CT图像中定位ICA,因此围绕耳蜗的小区域图像是该工作的感兴趣区域,因此在计算重建损失(L1 loss)时,可以给这部分区域赋予更高的权重。为了达到这一目的,可以引入一个权重矩阵,给感兴趣区域区域赋予权重 (Nin+Nout)/Nin,而不感兴趣区域的权重为1. Nin 表示感兴趣区域的像素点,Nout 为不感兴趣区域的像素点。但是如何区分感兴趣区域和不感兴趣区域呢,文章中直接用一个框把感兴趣区域框了出来。
因此,重建损失(L1 loss)可以写成:

W就是权重矩阵,由 (Nin+Nout)/Nin 和 1 组成。
3.总体损失
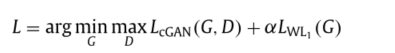
在这里 a = 100.
三、实验
(一)实验数据
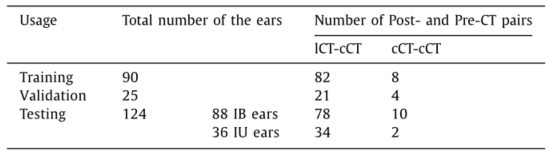
252对植入CI前后的耳蜗CT图像,其中90对用于训练,25对用于验证,137对用于测试。
实验数据如下图所示,IB表示单侧植入IC,IU表示双侧植入IC,至于为什么要这么分呢,因为前面介绍相关工作时介绍的PostCTseg1和PostCTseg2,需要用到这一信息。"lCT-cCT "表示耳朵在术后用lCT扫描,术前用cCT扫描;"cCT-cCT "表示耳朵在术后和术前都使用cCT扫描。ICT和cCT是两种扫描仪,因此得到的分辨率不一样,这样只要把它们采样的 0.4×0.4×0.4 mm3 即可,并分割为96×96×96的patch.
(二)实验过程
1.对比实验
对比工作:PostCTseg1, PostCTseg2(在相关工作中有介绍) 和 2D-cGANs(作者之前的工作,基于pix2pix框架)
2D-cGANs原文:Wang, J., Zhao, Y., Noble, J.H., Dawant, B.M., 2018. Conditional generative adversarial networks for metal artifact reduction in CT images of the ear. Med. Image Comput. Comput. Assist Interv.
2.评价指标
(1)point-to-point errors(P2PEs)
评价CT图像的ICA分割准确度,从而比较生成图像的图像质量。具体操作为,对植入前后的图像都用PreCTseg方法进行分割,分割得到的输出是鼓阶、前庭阶和耳蜗轴的网格面片(mesh),其顶点数是预先定义好的,前庭阶、鼓阶和耳蜗轴的顶点数分别为3344,3132,和17947。以植入前CT图像的分割结果为标准,便可以通过计算对照组分割后顶点位置与标准位置的距离,从而得到分割误差。
(2)MSSIM
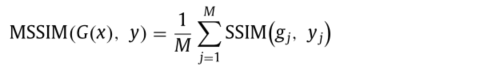
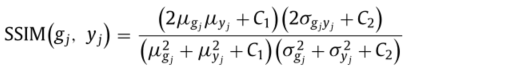
gj, yj 是第 j-th 个 G(x)和y的局部图像块,注意:这里作者只是计算了感兴趣区域,也就是上述提到的方框内的SSIM,并非是完成图像的图像块。
(三)实验结果
1.point-to-point errors

上图为分割后P2PEs可视化图像,第一行的红绿蓝表示ICA的三种组成:前庭阶、鼓阶和耳蜗轴,第二、三、四行表示P2PEs的值。左下角的colorbar表示P2PEs的颜色映射,颜色越红表示误差越大,越蓝表示误差越小。共三组图像,由左到右伪影越来越强。从图中看,由左到右,颜色越来越红,误差越大。纵向比较,3D-cGANs耳蜗颜色大部分为蓝色,表明误差较小。
2. MSSIM
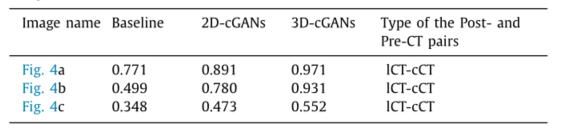
下表为上图3个例子的MSSIM的值,这里的baselines指的是PostCTseg方法。可以看出3D-cGANs的MSSIM值最大。
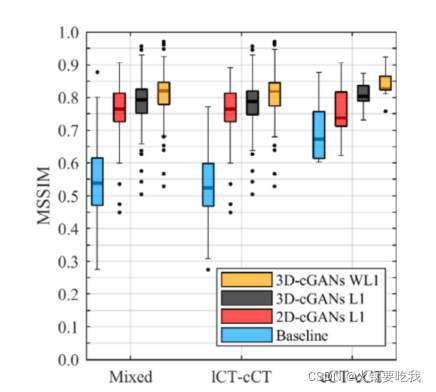
下图为124个测试数据MSSIM的值。MSSIM总体趋势:3D-cGANs WL1 > 3D-cGANs L1 > 2D-cGANs L1 > Baseline.说明重建损失采取WL1比直接采用L1更好。
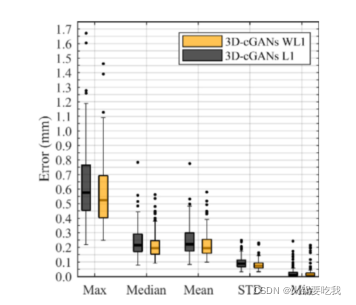
3.消融实验
L1损失和WL1
总结
这是第一次通过GANs来消除或减少CT图像中金属伪影的工作。此外,3D-cGANs的效果比2D-cGANs更好,并且更快,因为2D-cGANs需要先将3维图像转换为一张张的2维图像,再进行图像生成,最后再合成3维图像。
这篇关于MAR for the segmentation of the intra cochlear anatomy in CT images of the ear with 3D cGAN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!