本文主要是介绍Automated Website Fingerprinting through Deep Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Automated Website Fingerprinting through Deep Learning(自动提取特征,DL)
1.Abstract
攻击的成功很大程度上取决于所选的特征集
这篇文章利用深度学习实现了特征的自动提取(现在流行的特征提取方法有两种:(手工提取and自动提取)
2.Introduction
1.对于Tor的简单介绍
2.介绍一些WF的相关工作
3.自动提取特征是本文工作的重点
4.现有的一些方案过度 **focuses on feature engineering to compose and select the most salient features for website identifification.**Thus, these attacks are sensitive to changes in the traffific that would distort those features.(意思是说这些攻击的泛化性不好,没有提取更深层的特征)
在Tor网络中部署隐藏这些特性的对策就足以抵御此类攻击。
4.文章的贡献
4.1 自动提取特征
4.2 提供更大的数据 数据集url: https://distrinet.cs.kuleuven.be/software/tor-wf-dl/.
3.Background
该部分介绍了一些机器学习攻击的相关方法以及深度学习的应用
WF攻击的发展历程 机器学习方法---->深度学习方法
(1)Tor的第一次攻击是基于朴素贝叶斯分类器的[1],特征是包长度的频率分布,不过准确率比较低,后来进行改进,利用支持向量机(SVM)从而提高了准确率
[1] D. Herrmann, R. Wendolsky, and H. Federrath, “Website Fingerprinting: Attacking Popular Privacy Enhancing Technologies with the Multinomial Na¨ıve-Bayes Classififier,” in ACM Workshop on Cloud Computing Security*. ACM, 2009, pp. 31–42.
(2)Cai利用基于编辑距离的自定义内核的SVM,但是这些攻击的假设太理想化,不切实际
(3)接下来的三种方法比前述的工作准确率都要高
3.1 Wang-kNN 基于KNN算法
3.2 CUMUL 基于一个带有径向基函数(RBF)内核的SVM,使用数据包长度的累计之和
3.3 k-Fingerprinting 基于随机森林,但是随机森林不用于分类,而是用于特征转换,将转换的特征使用KNN进行分类
上述的一些攻击,特征的选取大都是手工选取,基于专家知识,泛化性不强,这些传统的方法同时也需要超参数调优,不过规模要比DNN小得多
4.Threat model

5.Data Collection
深度学习的训练依赖于海量的数据,之前的工作中,收集的数据相对有限
1.Data collection methodology
通过分布式的方法实现了数据爬取。利用云端的16台虚拟机,每台虚拟机启动15个进程,通过Tor Browser对Alexa Top的网站主页进行访问,每次访问时间达到285次时便kill掉重启下一次进程。利用tcpdump工具对访问数据包进行抓取。
从流量中提取元数据,并丢弃加密的有限负载
数据包提取方式是模仿WT的,从TCP流量包中提取Tor序列,并编码成-1和+1的序列
2.Datasets (如何选择和获取数据的)
(1) Closed world CW900 ---->收集了900个网页的流量包
(2) Revisit over time 不同时间再次访问网站采集数据
(3) Open world
6.Evaluation
1.Reevaluation of state-of-the-art

Second-exp-Conclusion:
1.CUMUL的效果明显好于其他两种
2.随着trace数目的增多分类的准确率在逐渐提高
Third-exp-Conclusion:

1.随着封闭世界的规模增大,性能会下降(Table1)
2.找到C和γ的最优SVM参数的时间随着规模的增加而变长
2.Deep Learning for Website Fingerprinting
1.Problem defifinition
深度神经网络(DNN,Deep neural networks)是DL的基础,它利用了许多层的非线性数学数据转换来进行自动的层次特征提取和选择。
( f t , c t ) (f_t,c_t) (ft,ct) 其中 f t f_t ft 是特征向量, c t c_t ct 对应的网站的标签
对于DL分类器来说,输入的形式可能变为 ( r t , c t ) (r_t,c_t) (rt,ct) 其中 r t r_t rt 是一个可以由神经网络解释的流量跟踪的原始表示
输入的是可变长的-1,+1的序列
1.DNN中相应的DL算法中,评估了三种神经网络
(1) feedforward(前馈)---->SDAE 由去噪自动编码器(DAE)组成的深度前馈神经网络
自动编码器(AE)是一种专门为通过降维来进行特征学习而设计的前馈网络
(2) convolutional(卷积)------->CNN 卷积神经网络
卷积层也用于特征提取
(3) recurrent(循环)----->LSTM
它的设计允许学习数据中的长期依赖关系,使分类器能够解释时间序列
输入的序列就是关于Tor的时间序列
2.Hyperparameter tuning and model selection(调整参数)
攻击者选择一个DNN模型来进行WF攻击,攻击者应该调整DNN的超参数以实现最佳的分类性能,对于参数的调整存在穷举网格搜索,随机搜索和其他搜索方法。
本文的策略如下:
(1)选择数据集,并将其随机分为训练集、验证集、测试集,比例分别为90%,5%,5%
(2)模型必须有足够的参数,同时为了防止过拟合,训练的参数数量要远少于可用的训练实例
(3)当选择最优的参数之后,攻击者将模型应用于整个数据集进行WF攻击

上图表示了三种方法在经过参数调优后的结果
3.Closed world evaluation
利用两个性能指标进行评估,分别是test accuracy(classifification success rate,需要最大化) 和test loss(损失函数,最小化),在实验中对性能影响最大的是训练数据的数量(每个网站的的流量跟踪量)

首先区分trace数量和CWN的区别
trace 是对单个网页采集的流量
CWN 对N个网页进行采集
1.随着trace的增加,相应的分类的正确率也在增加,但是正确率只在前期增加比较快,到后期增速放缓

2.随着size的增大,分类器的准确率也在不断下降
4.Concept drift evaluation
1.概念漂移: 在预测分析和机器学习的概念漂移表示目标变量的统计特性随着时间的推移以不可预见的方式变化的现象。随着时间的推移,模型的预测精度将降低。
2.出现概念漂移的原因可能是分类器学习了临时特征,忽略了稳定的特征。抵御概念漂移的模型是能够成功捕捉与网站指纹最相关的显著流量特征,从而随着时间的推移保持性能。

5. Open world evaluation
1.ROC曲线
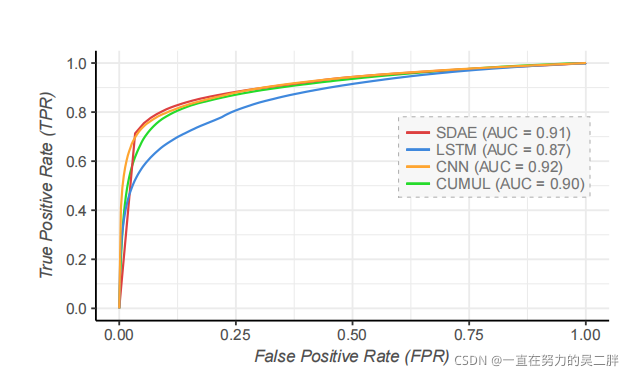
7.Discussion
1.只分析了对访问主页的攻击,省略了所考虑的网站内的其他页面
2.利用深度学习来提取特征,因此提取出来的特征不是显式特征,可能是基于抽象的隐式不可解释特征
3.对抗样本攻击可以考虑用来防御基于深度学习的WF攻击
这篇关于Automated Website Fingerprinting through Deep Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









