本文主要是介绍【论文分享】Automated Vulnerability Detection in Source Code Using Deep Representation Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文名:Automated Vulnerability Detection in Source Code Using Deep Representation Learning
开源数据集:https://osf.io/d45bw/
简介
软件漏洞很多,且造成了很严重的威胁。作者用机器学习做了源码级的漏洞检测系统。并且用三个静态分析工具(clang、flawfinder、cppcheck)做了一个打标签的数据集。基于这个数据集,作者使用深度学习做了一个漏洞检测工具。在真实软件包和juliet test做了评估。结果表明他们的深度特征学习是一个可行的方法来构建漏洞检测。
数据

数据集主要分为三部分:
- Juliet test
- 有标签
- 但只是代码片段,和真实代码差异较大
- debian
- 无标签
- 真实代码
- github
- 无标签
- 真实代码,数量多,有很多低质量代码
由于debian和github都没有标签,作者用三个静态分析工具(clang、flawfinder、cppcheck)来给这些代码打标签。
为了从函数源码中生成有用的特征,作者弄了个C/C++词法分析器去尽可能地使来自不同仓库的代码词法表示标准化。这样就可以只用156长度来表示代码。另外,一些不影响编译的代码,比如注释,都会被丢掉。
数据预处理的一个重要步骤是移除重复的函数。开源代码可能有很多包,这些包内可能有重复函数。这些重复的可能会影响性能指标和导致过拟合。为了解决这个问题,论文实现了一个很严格的去重过程。移除了任何带有重复源码的lexed表示或者重复的编译特征向量。这个编译特征向量由函数的控制流图、每个基本块里的操作和变量的def-use提取生成的。两个函数如果有相似的指令级行为或者函数性就有可能有相似的lex表示或者高度相关的漏洞。table1的passing curation表示的就是去重后还剩的数量,可以看出基本去掉了90%。
在函数级别对代码漏洞打标签是个难题。作者认为,常见的打标签的方法有静态分析、动态分析和commit-message/bug report tagging。
作者认为动态分析太耗时了,对LibTIFF就需要一天。也不适合他们。
提交信息标记这种方法难度高,生成标签质量低。在作者的测试结果中,人类和机器学习算法都不擅长使用提交信息来预测有无漏洞。作者认为这种方法大量减少了可以打标签的候选函数,以及需要后续人工检查,所以不适合他们的大数据集。
于是作者用三个开源静态分析工具(clang,flawfinder,cppcheck),来生成标签。每个静态分析器从不同的角度去检测。比如,clang就主要是去检查语法、变成风格这类。flawfinder主要针对CWE,并不针对其他方面,比如风格。因此作者整合了三个静态分析器,并且将他们的输出过滤来排除不是漏洞的,从而创建健壮的标签。由于有些CWE不会导致crash,虽然静态分析器也会把他们标记出来,但作者这里把他们的标签设定为no vulnerable。

方法
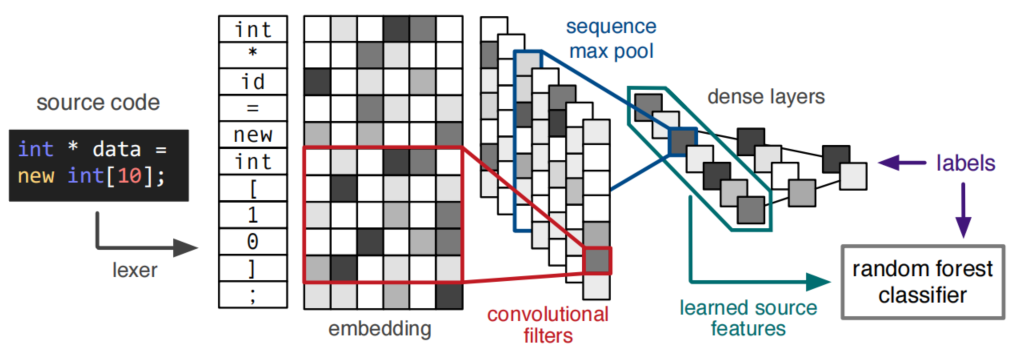
1.embedding
- 维度:k=13
- 高斯噪声
- $\mu=0 $
- σ 2 = 0.01 \sigma^{2}=0.01 σ2=0.01
2.feature extraction
CNN
- filter size : m= 9
- # of filter : n = 512
RNN
- GRU hidden state size n ’ = 256 n^{’}=256 n’=256
3.pool
4.dense layers
- 50% drop out
5.training
- batch size : 128
- learning rate : CNN( 5 ∗ 1 0 − 4 5*10^{-4} 5∗10−4) RNN( 1 ∗ 1 0 − 4 1*10^{-4} 1∗10−4)
- adam + cross entropy loss
结果
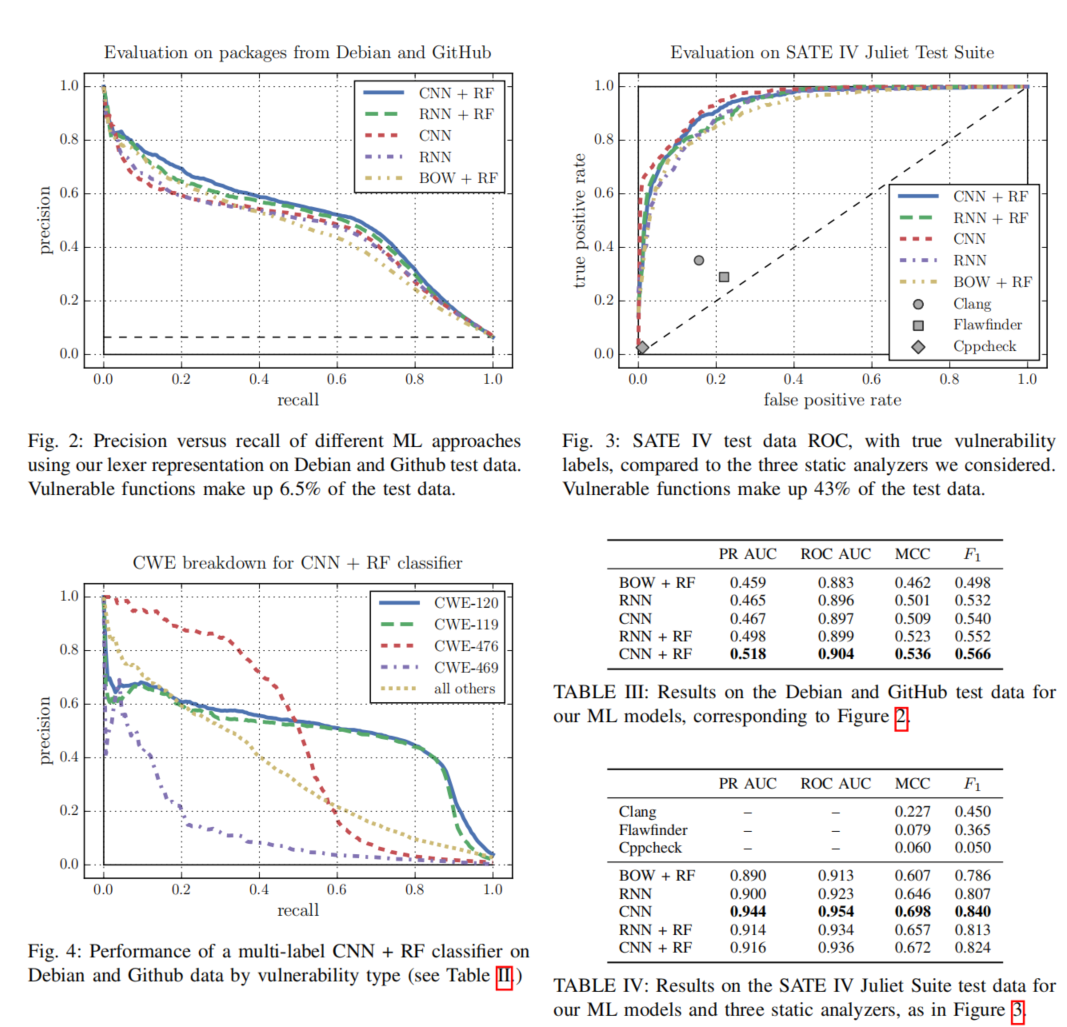
从结果来看,这里CNN要表现得比RNN好。另外,CNN训练得更快,并且需要更少的参数。并且在juliet test上的效果要好得多。这是因为juliet test的数据特征都比较相似。
在所有静态分析工具里,clang在juliet test的表现最好,但和ML比还是差点意思。
作者认为他们的ML方法比传统的静态分析要好,主要好在以下几点:
- 作者的传统词法分析器和ML模型可以快速地对大型仓库和源代码评分。
- 由于ML方法输出的是概率,所以可以调整概率的阈值来实现理想的准确率和召回率。
- 可以用可视化技术来帮助理解为什么算法做了这个决策。
感想
在一篇综述看到这篇论文,看到引用次数还蛮多的,有92次,感觉有点意思就细看了一下。文章总体思路很简单,就是自己做了个数据集,然后用简单的神经网络CNN、RNN来试一试。但是从结果来看,好像对于真实代码不是很理想。深度学习检测漏洞这个方向还有待发展。
这篇关于【论文分享】Automated Vulnerability Detection in Source Code Using Deep Representation Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





