本文主要是介绍XGBOOST(Extreme Gradient Boosting)算法原理详细总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上篇我们对传统的GBDT算法原理进行了探讨,本篇我们来探讨一个具有王者地位的算法:XGBOOST(Extreme Gradient Boosting
)。XGBOOST是来自于华盛顿大学的一个研究项目,2016年由陈天奇和Carlos Guestrin在KDD上发表:XGBoost: A Scalable Tree Boosting System。自此之后,XGBOOST不仅在kaggle比赛中赢得一席之地,而且也推动了工业领域的一些前沿应用的发展。XGBOOST是我们处理中小型结构化数据必须要掌握的一个杀手锏。
本篇我们主要参考陈天奇博士介绍XGBOOST的PPT:Boosted Trees 。
1)CART回归树
CART回归树既可以处理分类任务又可以处理回归任务。CART算法对训练样本集的每个特征递归的进行二分判断,将特征空间划分为有限的单元,每个单元具有一定的权重。简单的可以认为,CART回归树是一个叶子节点具有权重的二叉决策树。CART回归树有两个特点:
- 决策规则和决策树是一样的;
- 决策树的每个叶子节点都包含一个权重;
下图就是一个回归决策树的示例:
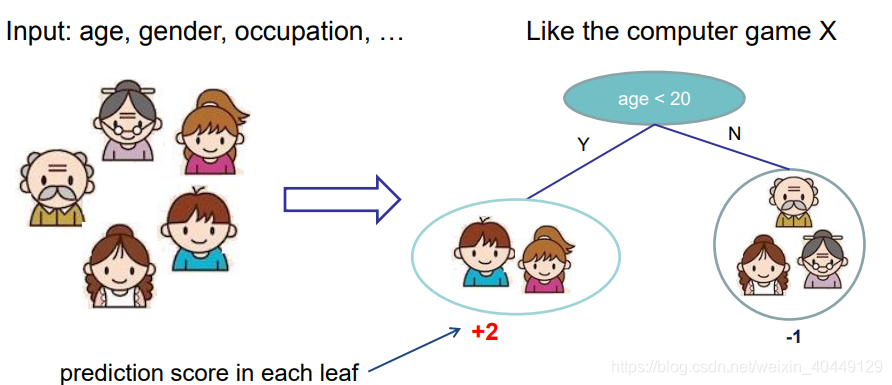
假如某决策树的叶子节点数目为 T T T,每个叶子节点的权重为 w → = { w 1 , w 2 , . . . w T } \overrightarrow{w}=\left\{w_1,w_2,...w_T\right\} w={w1,w2,...wT},样本 x x x落在叶节点 q q q中,决策树模型 f ( x ) f(x) f(x)可以定义为:
f t ( x ) = w q ( x ) w ∈ w → , q : R d → { 1 , 2 , . . . T } f_t(x) = w_{q(x)} \quad w \in \overrightarrow{w},q:R^d\rightarrow \left\{1,2,...T\right\} ft(x)=wq(x)w∈w,q:Rd→{1,2,...T}
从上式中可以看出,决策树的两个核心为:树的结构 q q q,叶节点的权重 w w w。确定树的结构和叶节点的权重便可以确定一颗决策树。
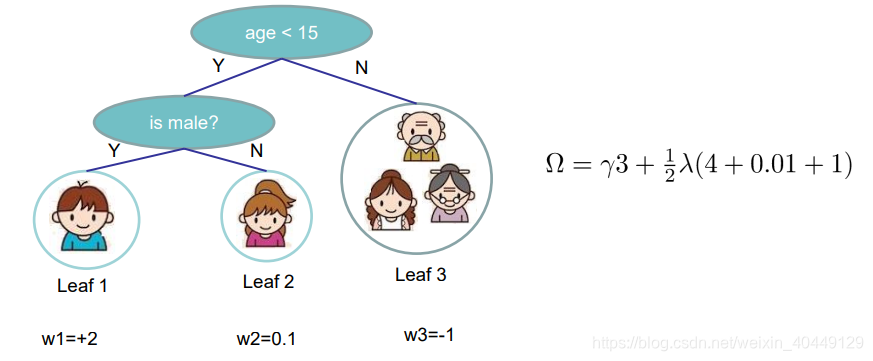
在决策树算法原理中我们了解到,决策树比较容易过拟合,因此会对决策树进行剪枝操作。那么我们该如何衡量决策树的复杂度呢?我们可以使用,树的深度,叶节点数量,叶子节点权重的 L 2 L2 L2正则等。这里我们使用叶节点的数量和叶子节点权重的 L 2 L2 L2正则表示决策树模型的复杂度,数学表达式为:
Ω ( f t ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f_t) =\gamma T+\frac{1}{2} \lambda \sum_{j=1}^Tw_j^2 Ω(ft)=γT+21λj=1∑Twj2
其中, T T T为叶节点的个数, w w w为叶节点所对应的权重, γ \gamma γ为收缩系数, λ \lambda λ为 L 2 L2 L2平滑系数。下图即为一个决策树模型复杂度的示例:
2)XGBOOST目标函数
XGBOOST基于Boosting框架,它采用的是前向优化算法,即从前往后,逐渐建立基模型来优化逼近目标函数,具体过程如下:
y ^ i ( 0 ) = 0 \hat y_i^{(0)}=0 y^i(0)=0
y ^ i ( 1 ) = f 1 ( x i ) = y ^ i ( 0 ) + f 1 ( x i ) \hat y_i^{(1)}=f_1(x_i)=\hat y_i^{(0)} +f_1(x_i) y^i(1)=f1(xi)=y^i(0)+f1(xi)
y ^ i ( 2 ) = f 1 ( x i ) + f 2 ( x i ) = y ^ i ( 1 ) + f 2 ( x i ) \hat y_i^{(2)}=f_1(x_i) + f_2(x_i)=\hat y_i^{(1)} +f_2(x_i) y^i(2)=f1(xi)+f2(xi)=y^i(1)+f2(xi)
. . . ... ...
y ^ i ( t ) = ∑ k = 1 t f k ( x i ) = y ^ i ( t − 1 ) + f t ( x i ) \hat y_i^{(t)}=\sum_{k=1}^tf_k(x_i)=\hat y_i^{(t-1)} +f_t(x_i) y^i(t)=∑k=1tfk(xi)=y^i(t−1)+ft(xi)
从上式中,我们可以看出,每一步我们都是要训练一个新的基模型 f t ( x i ) f_t(x_i) ft(xi),那么我们的目标就是让训练的新模型使得误差最小,即目标函数为:
O b j ( t ) = ∑ i = 1 n l ( y i , y ^ i ) + ∑ i = 1 t Ω ( f i ) Obj^{(t)}=\sum_{i=1}^nl(y_i,\hat y_i) +\sum_{i=1}^t\Omega(f_i) Obj(t)=i=1∑nl(yi,y^i)+i=1∑tΩ(fi)
= ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) + c o n s t a n t =\sum_{i=1}^nl(y_i,\hat y_i^{(t-1)} +f_t(x_i))+\Omega(f_t)+constant =i=1∑nl(yi,y^i(t−1)+ft(xi))+Ω(ft)+constant
其中 Ω ( f t ) \Omega(f_t) Ω(ft)为模型复杂度,用来防止模型过拟合,平衡模型偏差和方差的。
由泰勒二阶展开式可知:
f ( x + Δ x ) ≈ f ( x ) + f ′ ( x ) Δ x + 1 2 f ′ ′ ( x ) Δ x 2 f(x+\Delta x)\approx f(x)+f'(x)\Delta x+\frac{1}{2}f''(x)\Delta x^2 f(x+Δx)≈f(x)+f′(x)Δx+21f′′
这篇关于XGBOOST(Extreme Gradient Boosting)算法原理详细总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





