本文主要是介绍(数据科学学习手札153)基于martin的高性能矢量切片地图服务构建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 简介
大家好我是费老师,在日常研发地图类应用的场景中,为了在地图上快速加载大量的矢量要素,且方便快捷的在前端处理矢量的样式,且矢量数据可以携带对应的若干属性字段,目前主流的做法是使用矢量切片(vector tiles)的方式将矢量数据发布为服务进行调用:
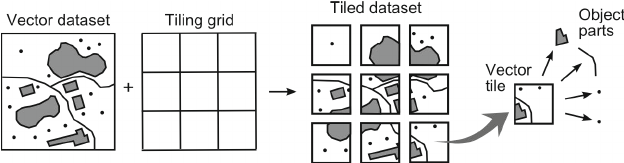
而可用于发布矢量切片服务的工具,主流的有geoserver、tippecanoe等,但是使用起来方式比较繁琐,且很容易遇到性能瓶颈。
除此之外,PostGIS中也提供了ST_AsMVT等函数可以直接通过书写SQL来生成矢量切片数据,但是需要额外进行服务化的开发封装,较为繁琐。
而我在最近的工作中,接触到由maplibre开源的高性能矢量切片服务器martin( https://github.com/maplibre/martin ),它基于Rust进行开发,官方宣传其性能快到疯狂(Blazing fast),而在我实际的使用体验中也确实如此,在今天的文章中我就将为大家分享有关martin发布矢量切片地图服务的常用知识😉。

2 基于martin+PostGIS发布矢量切片服务
martin可在windows、linux、mac等主流系统上运行,其最经典的用法是配合PostGIS,下面我们以linux系统为例,介绍martin的部署使用方法:
2.1 martin的安装#
martin提供了多种多样的安装方式,其中我体验下来比较简单稳定的安装方式是基于cargo,这是Rust的包管理器(因为martin基于Rust开发,这也是其超高性能的原因之一),martin可以直接当作Rust包进行安装。因此我们首先需要安装cargo:
apt-get update
apt-get install cargo
cargo完成安装后,为了在加速其国内下载速度,我们可以使用由字节跳动维护的镜像源( RsProxy ):
mkdir ~/.cargo
vim ~/.cargo/config# 在vim中粘贴下列内容后保存退出
[source.crates-io]
replace-with = 'rsproxy'
[source.rsproxy]
registry = "https://rsproxy.cn/crates.io-index"
[source.rsproxy-sparse]
registry = "sparse+https://rsproxy.cn/index/"
[registries.rsproxy]
index = "https://rsproxy.cn/crates.io-index"
[net]
git-fetch-with-cli = true
接着逐一执行下列命令即可完成martin及其必要依赖的安装:
# 安装必要依赖以防martin安装失败
apt-get install pkg-config
apt-get install libssl-dev
cargo install martin
2.2 准备演示用数据#
接下来我们利用geopandas来读入及生成一些示例用PostGIS数据库表,完整的代码及示例数据可以在文章开头的仓库中找到:
import random
import geopandas as gpd
from shapely import Point
from sqlalchemy import create_engineengine = create_engine('postgresql://postgres:mypassword@127.0.0.1:5432/gis_demo')# 读取示测试矢量数据1(数据来自阿里DataV地图选择器)
demo_gdf1 = gpd.read_file('中华人民共和国.json')[['adcode', 'name', 'geometry']]# 生成示例矢量数据2
demo_gdf2 = gpd.GeoDataFrame({'id': range(100000),'geometry': [Point(random.normalvariate(0, 20), random.normalvariate(0, 20)) for i in range(100000)]},crs='EPSG:4326'
)# 推送至数据库
demo_gdf1.to_postgis(name='demo_gdf1', con=engine, if_exists='replace')
demo_gdf2.to_postgis(name='demo_gdf2', con=engine, if_exists='replace')
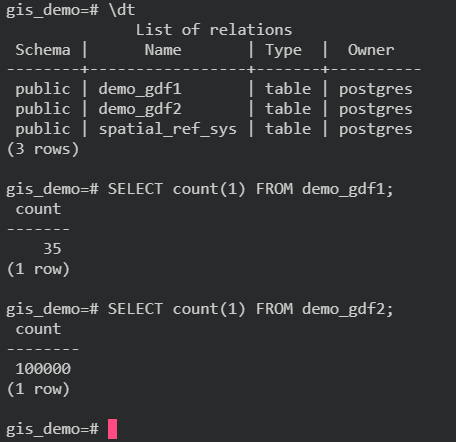
通过上面的Python代码,我们将两张带有矢量数据且坐标参考系为WGS84的数据表demo_gdf1、demo_gdf2分别推送至演示用PostGIS数据库中:
接下来我们就可以愉快的使用martin来发布矢量切片服务了~
2.3 使用martin发布矢量切片地图服务#
martin的基础使用超级简单,只需要在启动martin服务时设置好目标PostGIS数据库的连接参数字符串,它就可以自动发现数据库中具有合法坐标系(默认为EPSG:4326)的所有矢量表,并自动发布为相应的地图服务,以我们的示例数据库为例,参考下列命令:
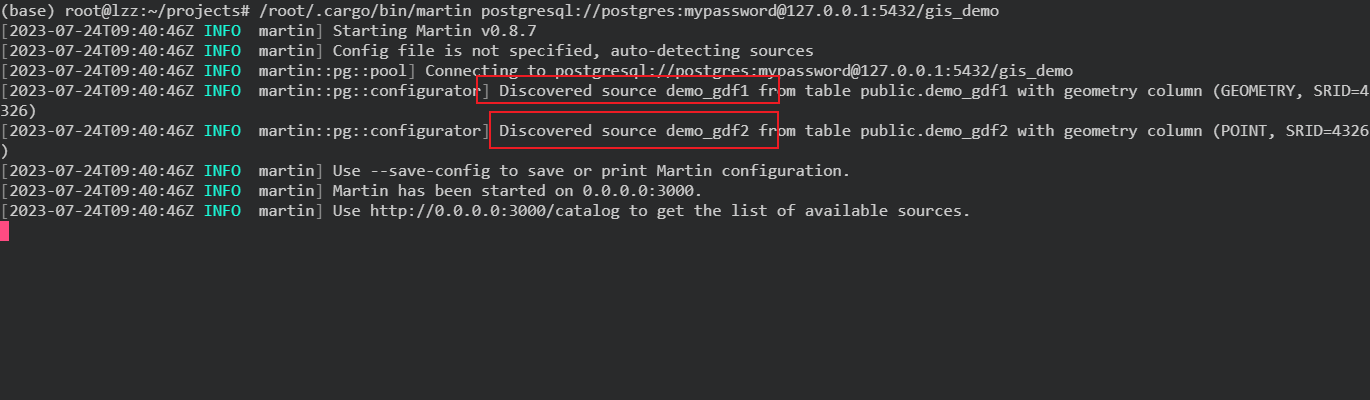
/root/.cargo/bin/martin postgresql://postgres:mypassword@127.0.0.1:5432/gis_demo
从输出结果中可以看到示例数据库中的demo_gdf1、demo_gdf2表均被martin自动发现,我们的martin服务被正常启动:
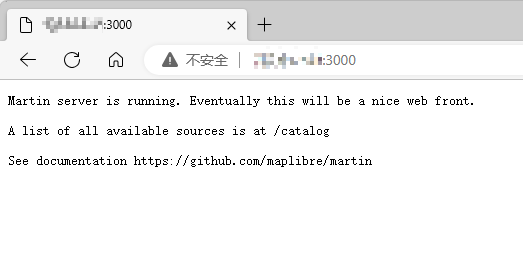
这时直接访问本机IP地址对应的3000端口,即可看到相应的提示信息:
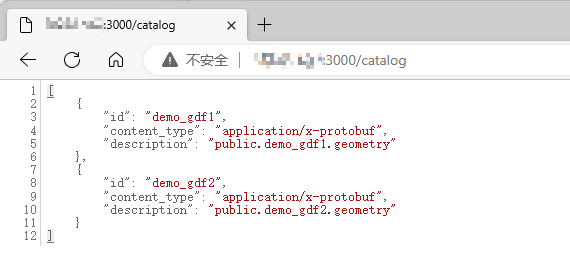
访问上面对应地址下的/catalog页面,可以看到被当前martin服务所架起的图层信息:
当以各个图层id作为路径进行访问时,就可以看到其对应地图服务的完整参数信息了,以demo_gdf1为例:

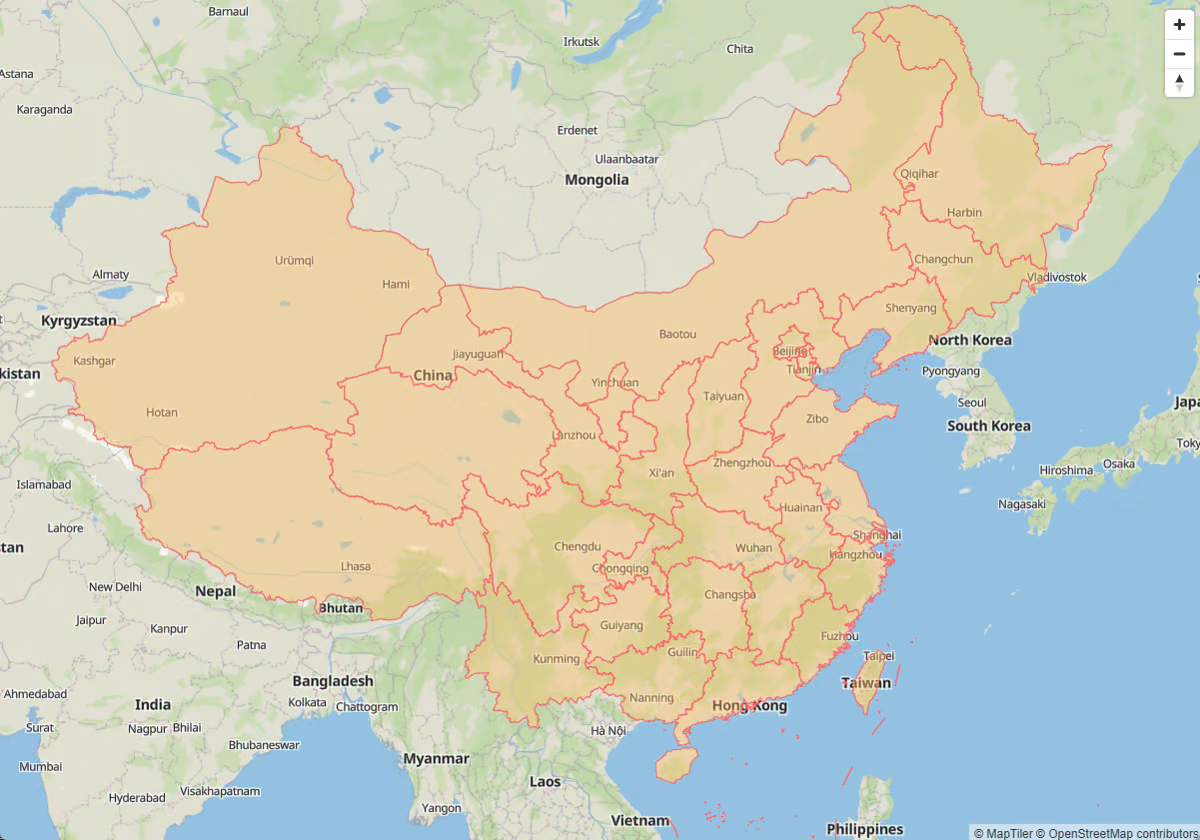
对mapbox、maplibre等地图框架了解的朋友,就知道上述信息可以直接用于向地图实例中添加相应的source和layer,下面是一个简单的基于maplibre的地图示例,要素加载速度非常之快,可以说唯一限制要素加载速度上限的瓶颈是带宽😎:

除此之外,martin还有相当多的额外功能,譬如基于PostGIS自定义运算函数、基于nginx实现切片缓存等,更多martin使用相关内容请移步官网https://maplibre.org/martin/。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
这篇关于(数据科学学习手札153)基于martin的高性能矢量切片地图服务构建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




