本文主要是介绍元数据管理atlas导入hive和hbase元数据以及生成血缘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要讲解导入hive和hbase元数据遇到的坑,以及hive生成列血缘遇到的问题和解决方式。
Atlas版本0.8.4
Hive版本1.2.1
HBase版本1.3.1
1.安装和集成
略略略
| 服务名称 | 子服务 | HDP-001 | HDP-002 | HDP-003 | HDP-004 | HDP-005 | HDP-006 | HDP-007 | HDP-008 |
| HDFS | NameNode | √ |
|
|
|
|
|
|
|
| DataNode |
| √ | √ | √ | √ | √ | √ | √ | |
| SecondaryNameNode |
|
| √ |
|
|
|
|
| |
| Yarn | ResourceManager | √ |
|
|
|
|
|
|
|
| NodeManager |
| √ | √ | √ | √ | √ | √ | √ | |
| JobHistoryServer | √ |
|
|
|
|
|
|
| |
| Zookeeper | QuorumPeerMain |
|
|
|
|
| √ | √ | √ |
| Hive | RunJar | √ |
|
|
|
|
|
|
|
| Hbase | HMaster | √ |
|
|
|
|
|
|
|
| HRegionServer |
| √ | √ | √ | √ | √ | √ | √ | |
| Solr | Jar |
|
|
|
|
| √ | √ | √ |
| Kafka | Kafka |
|
|
|
|
| √ | √ | √ |
| MySQL | MySQL | √ |
|
|
|
|
|
|
|
| Atlas | atlas | √ |
|
|
|
|
|
|
|
2.导入Hive元数据
1.进入/opt/module/atlas/conf/目录,修改配置文件atlas-application.properties
gw@HDP-001:/data/module/apache-atlas-0.8.4/conf$ vim atlas-application.properties#添加如下配置######### Hive Hook Configs #######atlas.hook.hive.synchronous=falseatlas.hook.hive.numRetries=3atlas.hook.hive.queueSize=10000atlas.cluster.name=primary2、将atlas-application.properties配置文件加入到atlas-plugin-classloader-1.0.0.jar中
gw@HDP-001:/data/module/apache-atlas-0.8.4$ cd hook/hivegw@HDP-001:/data/module/apache-atlas-0.8.4/hook/hive$ zip -u atlas-plugin-classloader-0.8.4.jar /data/module/apache-atlas-0.8.4/conf/atlas-application.propertiesgw@HDP-001:/data/module/apache-atlas-0.8.4/hook/hive$ cp /data/module/apache-atlas-0.8.4/conf/atlas-application.properties /data/module/hive/conf/3、在/data/module/hive/conf/hive-site.xml文件中设置Atlas hook
gw@HDP-001:/data/module/hive/conf$ vim hive-site.xml<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook</value></property>4.追加hive插件相关jar包
gw@HDP-001:/data/module/hive/conf$ vim hive-env.shexport HIVE_AUX_JARS_PATH=/data/module/apache-atlas-0.8.4/hook/hive/atlas-plugin-classloader-0.8.4.jar,/data/module/apache-atlas-0.8.4/hook/hive/hive-bridge-shim-0.8.4.jar5、导入Hive元数据
gw@HDP-001:/data/module/apache-atlas-0.8.4$ bin/import-hive.sh输入用户admin,密码admin
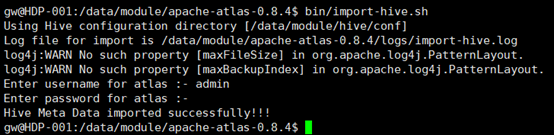
3.导入HBase元数据
1、进入/opt/module/atlas/conf/目录,修改配置文件atlas-application.properties
gw@HDP-001:/data/module/apache-atlas-0.8.4/conf$ vim atlas-application.properties#添加如下配置######### HBase Hook Configs #######atlas.hook.hbase.synchronous=falseatlas.hook.hbase.numRetries=3atlas.hook.hbase.queueSize=10000atlas.cluster.name=primary2、将atlas-application.properties配置文件加入到atlas-plugin-classloader-1.0.0.jar中
gw@HDP-001:/data/module/apache-atlas-0.8.4$ cd hook/hbasegw@HDP-001:/data/module/apache-atlas-0.8.4/hook/hbase$ zip -u atlas-plugin-classloader-0.8.4.jar /data/module/apache-atlas-0.8.4/conf/atlas-application.propertiesgw@HDP-001:/data/module/apache-atlas-0.8.4/hook/hbase$ cp /data/module/apache-atlas-0.8.4/conf/atlas-application.properties /data/module/hbase-1.3.1/conf/3、在/data/module/hbase-1.3.1/conf/hbase-site.xml文件中设置Atlas hook
gw@HDP-001:/data/module/hbase-1.3.1/conf$ vim hbase-site.xml<property><name>hbase.coprocessor.master.classes</name><value>org.apache.atlas.hbase.hook.HBaseAtlasCoprocessor</value></property>4、在HBase类路径中链接Atlas hook jars
gw@HDP-001:/data/module/apache-atlas-0.8.4$ ln -s /data/module/apache-atlas-0.8.4/hook/hbase/* /data/module/hbase-1.3.1/lib/5、导入HBase元数据
gw@HDP-001:/data/module/apache-atlas-0.8.4$ hook-bin/import-hbase.sh
注意:此处有个bug,导入HBase元数据报错,如下,经过查找原因发现是编译的时候没有将jersey- multipart.jar包下载下来,手动去maven仓库下载jersey-multipart-1.19.3.jar,拷贝到HBASE_HOME/lib目录下

导入成功,能看到kafka topic有数据写入:
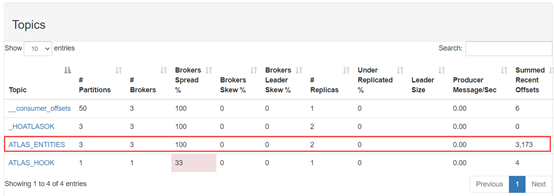
4.界面查看
4.1查询Hive库
1、查询Hive库,类型选择hive_db

属性包含qualifiedName, name, description, owner, clusterName, location, parameters, ownerName

2.查询Hive表,类型选择hive_table

属性包含:qualifiedName, name, description, owner, db, createTime, lastAccessTime, comment, retention, sd, partitionKeys, columns, aliases, parameters, viewOriginalText, viewExpandedText, tableType, temporary

3.查询hive表的列,类型选择hive_column

4.查询hive表的存储描述,类型选择hive_storagedesc

5.查询hive进程,类型选择hive_process

6.查看表级血缘关系
选择一个表,点击Lineage,显示血缘关系图

点击Audits,可显示表修改的时间和详情

点击Schema,可以看到表字段信息

7.查看列级血缘关系
官网笔记:Column level lineage works with Hive version 1.2.1 after the patch for HIVE-13112 is applied to Hive source
列级血缘需要打补丁才能在hive 1.2.1上使用,下面开始尝试打补丁-编译,下载HIVE-13112.01.patch和apache-hive-1.2.1-src.tar.gz源码包。
gw@HDP-001:/data/software$ tar xf apache-hive-1.2.1-src.tar.gzgw@HDP-001:/data/software$ cd apache-hive-1.2.1-src#上传HIVE-13112.01.patch到/data/software/apache-hive-1.2.1-srcgw@HDP-001:/data/software/apache-hive-1.2.1-src$ patch -p1 < HIVE-13112.01.patchcan't find file to patch at input line 5Perhaps you used the wrong -p or --strip option?The text leading up to this was:--------------------------|diff --git ql/src/java/org/apache/hadoop/hive/ql/exec/DDLTask.java ql/src/java/org/apache/hadoop/hive/ql/exec/DDLTask.java|index 6fca9f7..0fe09aa 100644|--- ql/src/java/org/apache/hadoop/hive/ql/exec/DDLTask.java|+++ ql/src/java/org/apache/hadoop/hive/ql/exec/DDLTask.java--------------------------File to patch:Skip this patch? [y] ySkipping patch.3 out of 3 hunks ignored#使用patch打补丁报错,下面使用-p0参数gw@HDP-001:/data/software/apache-hive-1.2.1-src$ patch -p0 < HIVE-13112.01.patchpatching file ql/src/java/org/apache/hadoop/hive/ql/exec/DDLTask.javaHunk #1 succeeded at 93 with fuzz 1.Hunk #2 succeeded at 4134 (offset 219 lines).patching file ql/src/java/org/apache/hadoop/hive/ql/parse/SemanticAnalyzer.javaHunk #1 succeeded at 6671 (offset -225 lines).Hunk #2 FAILED at 11302.1 out of 2 hunks FAILED -- saving rejects to file ql/src/java/org/apache/hadoop/hive/ql/parse/SemanticAnalyzer.java.rejpatching file ql/src/java/org/apache/hadoop/hive/ql/plan/CreateTableDesc.javaHunk #1 succeeded at 79 with fuzz 2 (offset -8 lines).Hunk #2 succeeded at 104 (offset -8 lines).Hunk #3 FAILED at 611.1 out of 3 hunks FAILED -- saving rejects to file ql/src/java/org/apache/hadoop/hive/ql/plan/CreateTableDesc.java.rej
#显示第3步还是报错,尝试根据HIVE-13112.01.patch文件内容手动修改java文件,将+号内容添加到指定件中,如:

#修改完成后,开始编译hive源码
gw@HDP-001:/data/software/apache-hive-1.2.1-src$ mvn clean package -Phadoop-2 -DskipTests –Pdist

#编译完成后,会在packaging/target/目录下产生以下几个文件

#备份已安装好的hive/lib目录,将新编译的lib文件包拷贝并替换到已安装好的hive目录中
gw@HDP-001:/data/module/hive$ cp -rp lib/ lib_bakgw@HDP-001:/data/software/apache-hive-1.2.1-src/packaging/target$ cp -rp apache-hive-1.2.1-bin/apache-hive-1.2.1-bin/bin /data/module/hive/lib演示列级血缘关系,hive cli里操作:create table t1 (id int, name string);create table t2 as select id,name from t1;查看t2的id列血缘:
4.2查询HBase库
1.查询hbase命名空间,类型选择hbases_namespace

属性包含:qualifiedName, name, description, owner, clusterName, parameters, createTime, modifiedTime

2.查询hbase表,类型选择hbase_table

属性包含:qualifiedName, name, description, owner, namespace, column_families, uri, parameters, createtime, modifiedtime, maxfilesize, isReadOnly, isCompactionEnabled, isNormalizationEnabled, ReplicaPerRegion, Durability

3.查看hbase列族,类型选择hbase_column_family

这篇关于元数据管理atlas导入hive和hbase元数据以及生成血缘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





