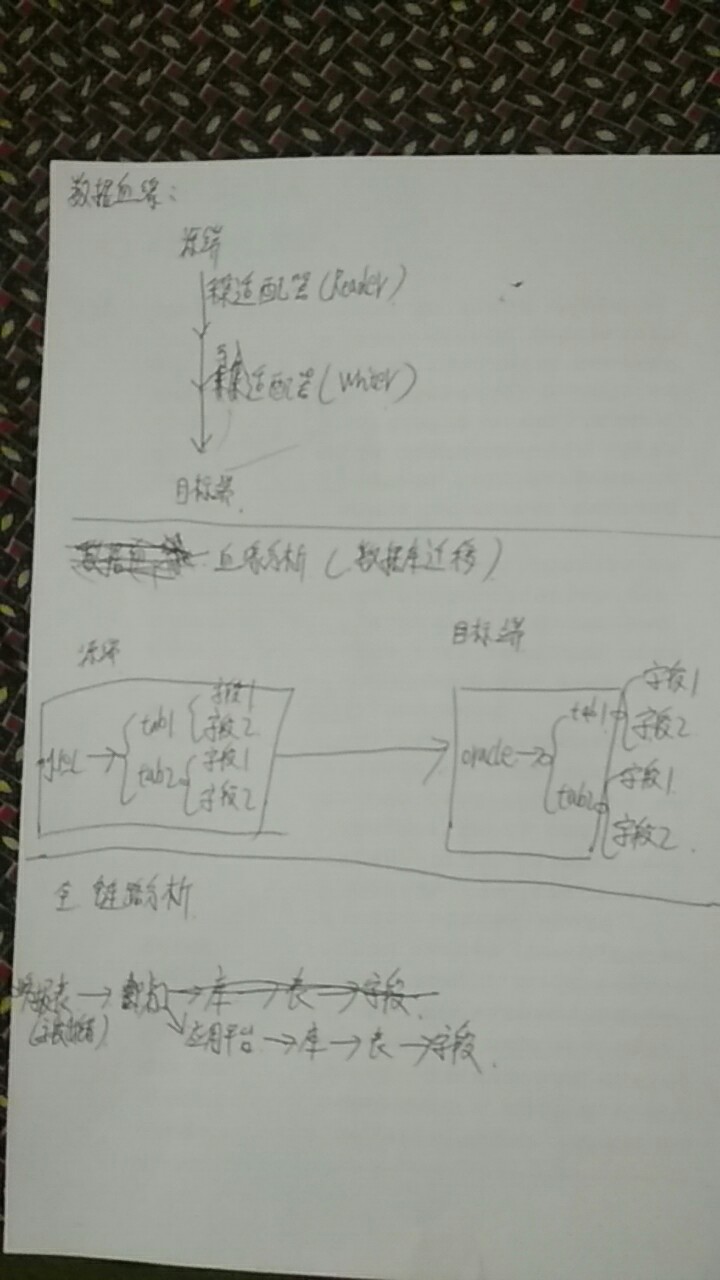
血缘专题

数据仓库系列19:数据血缘分析在数据仓库中有什么应用?
你是否曾经在复杂的数据仓库中迷失方向,不知道某个数据是从哪里来的,又会流向何方?或者在处理数据质量问题时,无法快速定位根源?如果是这样,那么数据血缘分析将会成为你的得力助手,帮助你在数据的海洋中找到明确的航向。 目录 引言:数据血缘分析的魔力什么是数据血缘分析?数据血缘的核心概念 数据血缘分析在数据仓库中的应用1. 数据质量管理实际应用案例 2. 影响分析实际应用案例 3. 合规性和审计

主动元数据平台详解(下):BIG 十一问,详解定位、对接、血缘保鲜等问题
在上一篇文章中,我们围绕“算子级血缘解析技术”,全面介绍了 Aloudata BIG 主动元数据平台的核心能力及优势,帮助企业加速实现数据管理的“自治理”,推动企业的数智化运营进程。 本篇文章,我们盘点和整理了十一个同客户交流过程中遇到的「Aloudata BIG 平台如何对接、应用」等方面的疑难杂题,以帮助您从落地视角,更深入地了解 Aloudata BIG 平台。 从客户调研反馈来看
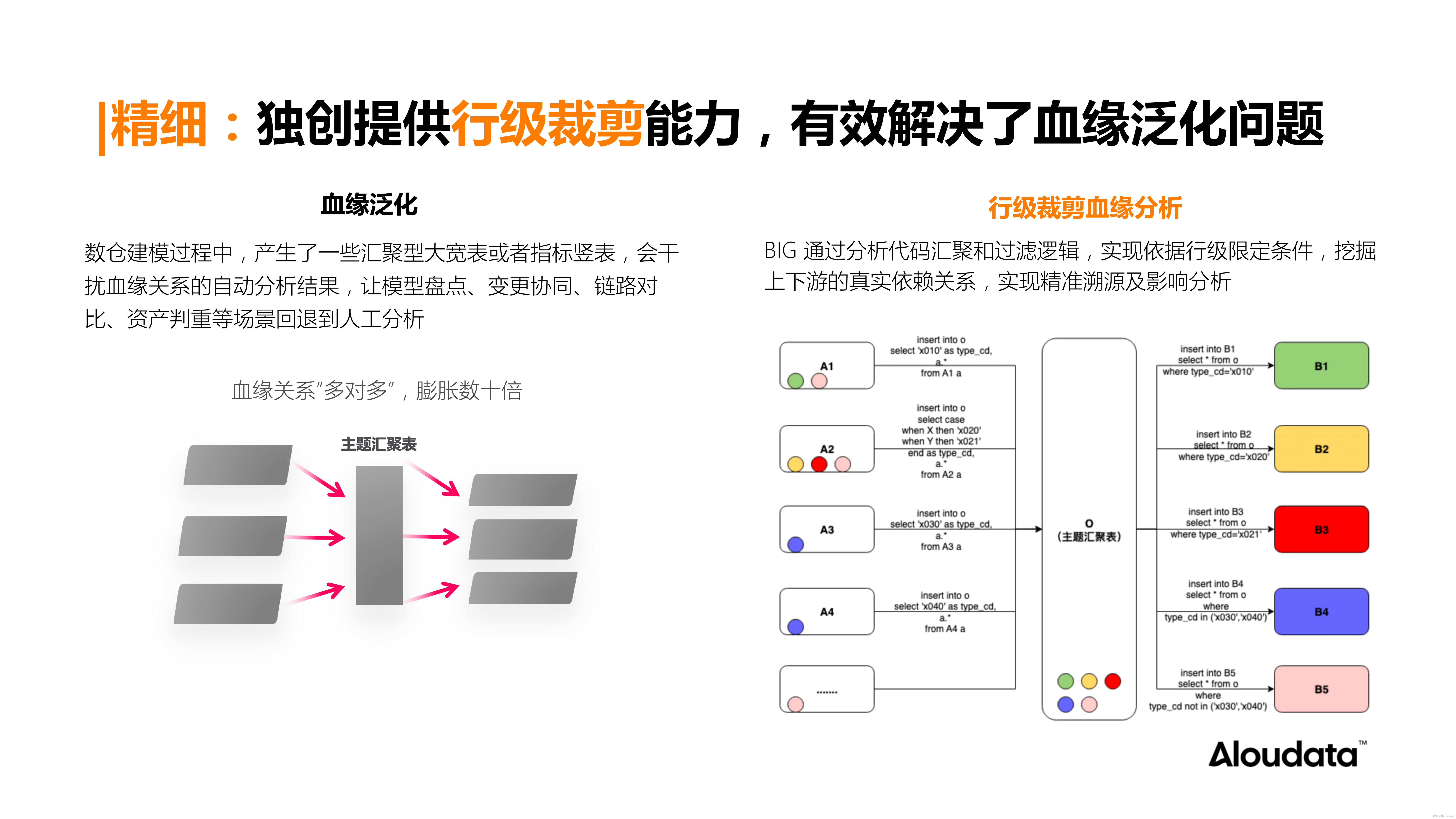
主动元数据平台详解(上):算子级血缘,创新数据管理新范式
01、数据血缘成为数据管理的“关键基建” 随着企业从传统的数字化管理迈向更为先进的数智化运营,数据已成为企业决策和运营的核心驱动力。在这个过程中,找数、用数已经成为企业实现精细化运营、智能化决策的重要环节。因此,实现更高效、全面、精准地管理数据,确保数据的完整性、可用性和准确性,对于推动企业数智化运营、提升整体业务效率、提升商业竞争力具有至关重要的意义。 然而,数据规模快速增长、数据资产日益增
使用Druid的sql parser做一个表数据血缘分析工具
版权 前言 大数据场景下,每天可能都要在离线集群,运行大量的任务来支持业务、运营的分析查询。任务越来越多的时候,就会有越来越多的依赖关系,每一个任务都需要等需要的input表生产出来后,再去生产自己的output表。最开始的时候,依赖关系自然是可以通过管理员来管理,随着任务量的加大,就需要一个分析工具来解析任务的inputs、outs,并且自行依赖上生产inputs表的那些任务。本文就介绍一个使

Atlas 血缘分析-hive/spark
Apache Atlas部署安装 这里需要注意,需要从官网下载Atlas的源码,不要从git上分支去checkout,因为从分支checkout出来的代码,无法正常运行,这里小编使用针对Atlas-2.3.0源码进行编译. mvn clean -DskipTests package -Pdist 部署前置条件 Elastic7.xHBase2.xKafla-2.xzookeeper-3.

HIVE数仓数据血缘分析工具-SQL解析
一、数仓经常会碰到的几类问题: 1、两个数据报表进行对比,结果差异很大,需要人工核对分析指标的维度信息,比如从头分析数据指标从哪里来,处理条件是什么,最后才能分析出问题原因。 2、基础数据表因某种原因需要修改字段,需要评估其对数仓的影响,费时费力,然后在做方案。 二、问题分析: 数据源长途跋涉,经过大量的处理和组件来传递,呈现在业务用户面前,对数据进行回溯其实很难。元数据回溯在有效决策、策略制定
构建高效可靠的数据血缘技术架构-文字解说
摘要 在日益快速增长的大数据领域,了解和管理数据的来源、流向以及变化成为了一项重要任务。数据血缘分析可以帮助企业更好地了解数据的历史记录和变化过程,提高数据质量和决策的准确性。构建高效可靠的数据血缘技术架构,有助于以下几点: 提高数据质量:通过了解数据的来源、流向和变化过程,可以更好地监控和管理数据质量,减少数据错误和冗余,从而提高数据的准确性和可靠性。 支
关于Hive重写LineageLogger获取血缘问题
Lineagelogger类是hive2.x加入的,但是我们如果自己改造的话需要注意如下问题:(如果将代码迁移到1.x应该直接可用 1.x代码中是直接做了add的操作,并没有做判断才进行加入) org.apache.hadoop.hive.ql.optimizer.Optimizer 类 第79行 这里由于只有如下几种类型才会加入 generator ,后续才能正常注入字段级血缘,所以 如果这里

元数据管理atlas导入hive和hbase元数据以及生成血缘
本文主要讲解导入hive和hbase元数据遇到的坑,以及hive生成列血缘遇到的问题和解决方式。 Atlas版本0.8.4 Hive版本1.2.1 HBase版本1.3.1 1.安装和集成 略略略 服务名称 子服务 HDP-001 HDP-002 HDP-003 HDP-004 HDP-005 HDP-006 HDP-007 HDP-008 HDFS NameN
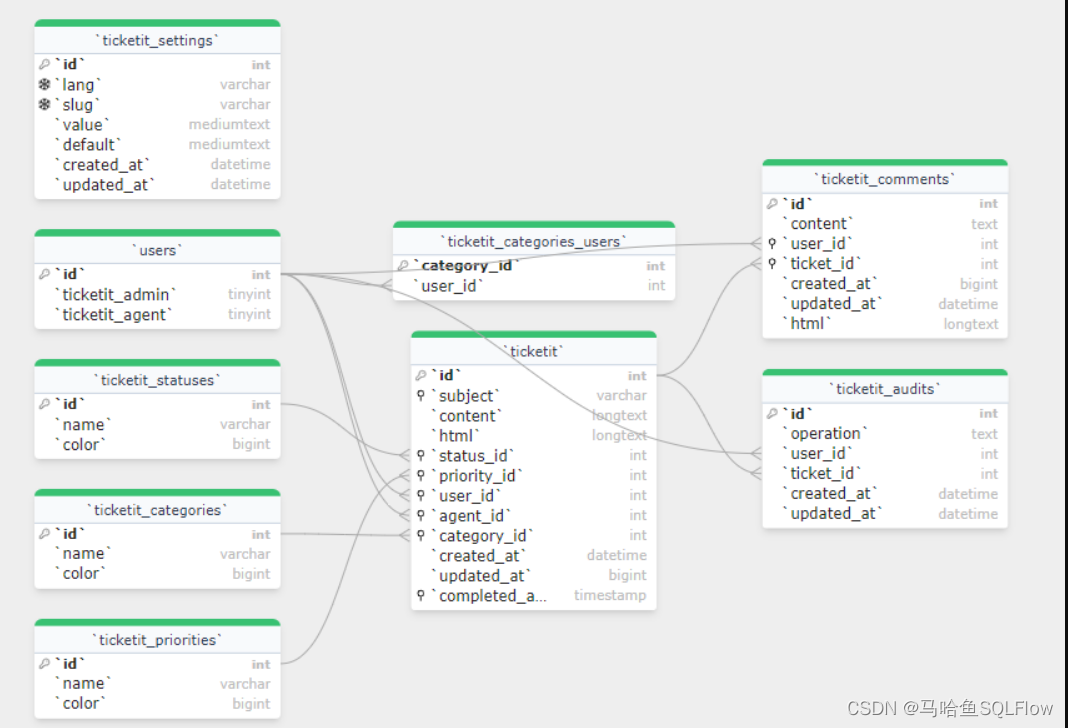
数据血缘分析工具SQLFLow自动画出数据库的 ER 模型
马哈鱼数据血缘分析器通过分析你所提供的 SQL 脚本,或者连接到数据库,可以自动画出数据库的 ER 模型,可视化表和字段的关系,帮助你迅速了解数据库的设计模型,进行高效的团队沟通。 马哈鱼通过两种途径来为你自动可视化 ER 模型。 一、SQL 脚本 你只需要提供创建数据库的 SQL 脚本,马哈鱼数据血缘分析工具可以自动分析这些 SQL,然后把 SQL 脚本转化为可视化的 ER 模型。为了创建


命令行绘制 大数据 数据血缘图
前提 你的sql都是在 *.sql这种文件中. 此方法没有针对 hive -e "..." 这种写道 *.sh中的情况. 我下面用hive sql 为例. 1 python3安装sqllineage 数据血缘绘制工具 pip3 install sqllineage 2 把你的sql放到同一个文件中 find /opt/my-hive-sql/ -name *.sql |xargs -

Spark入门篇——RDD的血缘
目录 RDD的血缘 概述 划分依赖的背景 划分以来的依据 窄依赖 宽依赖 join的依赖 宽依赖 窄依赖 依赖与Stage的划分 Stage的类别 依赖与容错 转换算子中间发生失败 DAG的生成 总结 RDD的血缘 概述 RDD可以从本地集合并行化、从外部文件系统、其他RDD转化得到,能从其他RDD通过Transformation创建新的RDD的原因

字节跳动DataLeap数据血缘实践
数据血缘是帮助用户找数据、理解数据以及使数据发挥价值的基础能力。本文将聚焦数据血缘存储和血缘导出,分享在存储和导出数据血缘的模型设计以及优化,并介绍字节跳动在数据血缘建设过程中所遇到的挑战和技术实现以及数据血缘的具体用例,具体包括数据血缘模型、数据血缘优化、数据血缘用例、未来展望四个部分。本文介绍的数据血缘能力和实践,目前大部分已通过火山引擎DataLeap对外提供服务,欢迎大家点击阅读原文体验
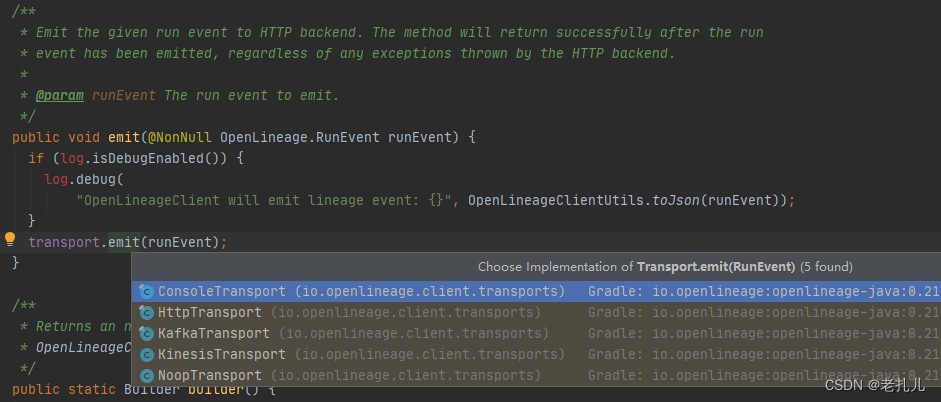
SparkListener血缘——Openlineage插件实现思路
文章目录 一、SparkListener1.1 源码剖析1.2 Listener 提供的方法 二、OpenLineage 的SparkListener插件实现2.1 初始化参数2.2 类加载信息2.3 触发执行2.4 逻辑计划解析2.5 获取元数据 三、Visitor的具体实现思路(后续)四、总结 一、SparkListener 1.1 源码剖析 Spark listene